Data Virtualization: Unlocking Data for AI and Machine Learning
This post is authored by Robert Alexander, Senior Software Engineer at Microsoft.
For reliability, accuracy and performance, both AI and machine learning heavily rely on large sets. Because the larger the pool of data, the better you can train the models. That's why it's critical for big data platforms to efficiently work with different data streams and systems, regardless of the structure of the data (or lack thereof), data velocity or volume.
However, that's easier said than done.
Today every big data platform faces these systemic challenges:
- Compute / Storage Overlap: Traditionally, compute and storage were never delineated. As data volumes grew, you had to invest in compute as well as storage.
- Non-Uniform Access of Data: Over the years, too much dependency on business operations and applications have led companies to acquire, ingest and store data in different physical systems like file systems, databases and data warehouses (e.g. SQL Server or Oracle), big data systems (e.g. Hadoop). This results in disparate systems, each with its own method of accessing data.
- Hardware-Bound Compute: You have your data in nice storage schema (e.g. SQL Server), but then you're hardware constrained to execute your query as it takes several hours to complete.
- Remote Data: Data is either dispersed across geo-locations, or uses different underlying technology stacks (e.g. SQL Server, Oracle, Hadoop, etc.), and is stored on premises or in the cloud. This requires raw data to be physically moved to get processed, thus increasing network I/O costs.
With the advent of AI and ML, beating these challenges has become a business imperative. Data virtualization is rooted on this premise.
What's Data Virtualization Anyway?
Data virtualization offers techniques to abstract the way we handle and access data. It allows you to manage and work with data across heterogenous streams and systems, regardless of their physical location or format. Data virtualization can be defined as a set of tools, techniques and methods that let you access and interact with data without worrying about its physical location and what compute is done on it.
For instance, say you have tons of data spread across disparate systems and want to query it all in a unified manner, but without moving the data around. That's when you would want to leverage data virtualization techniques.
In this post, we'll go over a few data virtualization techniques and illustrate how they make the handling of big data both efficient and easy.
Data Virtualization Architectures
Data virtualization can be illustrated using the lambda architecture implementation of the advanced analytics stack, on the Azure cloud:
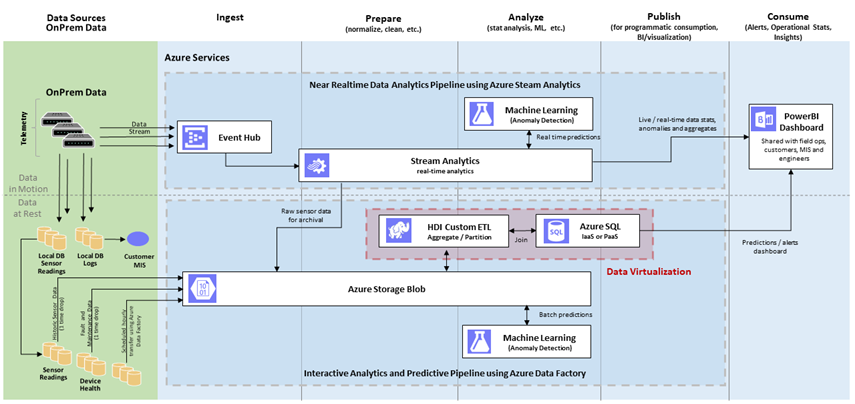
Figure 1: Lambda architecture implementation using Azure platform services
In big data processing platforms, tons of data are ingested per second, and this includes both data at rest and in motion. This big data is then collected in canonical data stores (e.g. Azure storage blob) and subsequently cleaned, partitioned, aggregated and prepared for downstream processing. Examples of downstream processing are machine learning, visualization, dashboard report generation, so forth.
This downstream processing is backed by SQL Server, and – based on the number of users – it can get overloaded when many queries are executed in parallel by competing services. To address such overload scenarios, data virtualization provides Query Scale-Out where a portion of the compute is offloaded to more powerful systems such as Hadoop clusters.
Another scenario, shown in Figure 1, involves ETL processes running in HDInsight (Hadoop) clusters. ETL transform may need access to referential data stored in SQL Server.
Data virtualization provides Hybrid Execution which allows you to query referential data from remote stores, such as on SQL Server.
Query Scale-out
What Is It?
Say you have a multi-tenant SQL Server running on a hardware constrained environment. You want to offload some of the compute to speed up queries. You also want to access the big data that won't fit in SQL Server. These are situations where Query Scale-Out can be used.
Query Scale-out uses PolyBase technology, which was introduced in SQL Server 2016. PolyBase allows you to execute a portion of the query remotely on a faster, higher capacity big data system, such as on Hadoop clusters.
The architecture for Query Scale-out is illustrated below.
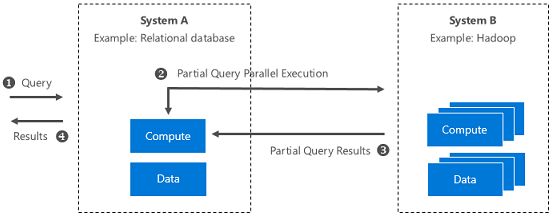
Figure 2: System-level illustration of Query Scale-Out
What Problems Does It Address?
- Compute / Storage Overlap: You can delineate compute from storage by running queries in external clusters. You can extends SQL Server storage by enabling access of data in HDFS.
- Hardware-Bound Compute: You can run parallel computations, leveraging faster systems.
- Remote Data: You can keep the data where it is, only return the processed result set.
Further explore and deploy Query Scale-out using the one-click automated demo at the solution gallery.
Hybrid Execution
What Is It?
Say you have ETL processes which run on your unstructured data and then store the data in blobs. You need to join this blob data with referential data stored in a relational database. How would you uniformly access data across these distinct data sources? These are the situations in which Hybrid Execution would be used.
Hybrid Execution allows you to "push" queries to a remote system, such as to SQL Server, and access the referential data.
The architecture for Hybrid Execution is illustrated below.
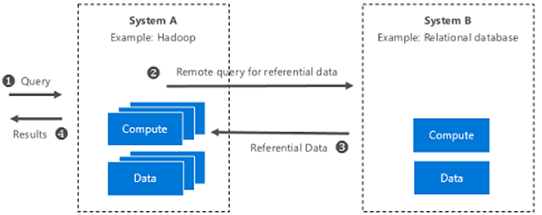
Figure 3: System-level illustration of Hybrid Execution
What Problems Does It Address?
- Non-Uniform Access of Data: You are no longer constrained by where and how data is stored.
- Remote Data: You can access reference data from external systems, for use in downstream apps.
Further explore and deploy Hybrid Execution using the one-click automated demo at the solution gallery.
Performance Benchmarks: What Optimization Gains Can You Expect?
You may be asking yourself whether it's worthwhile using these techniques.
Query Scale-Out makes sense when data already exists on Hadoop. Referring to Figure 1, you may not want to push all the data to HDInsight just to see the performance gain.
However, one can imagine a use case where lots of ETL processing happens in HDInsight clusters and the structured results are published to SQL Server for downstream consumption (for instance, by reporting tools). To give you an idea of the performance gains you can expect by using these techniques, here are some benchmark numbers based on the datasets used in our solution demo. These benchmarks were produced by varying the size of datasets and the size of HDInsight clusters.
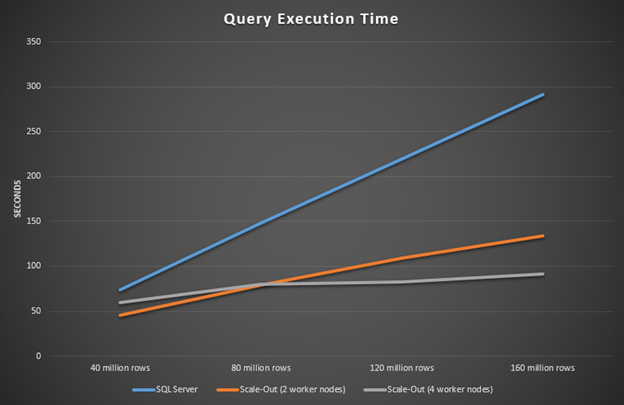
Figure 4: Query execution time with and without scaling
The x axis shows the number of rows in the table used for benchmarking. The y axis shows the number of seconds the query took to execute. Note the linear increase in execution time with SQL Server only (blue line) versus when HDInsight is used with SQL Server to scale out the query execution (orange and grey lines). Another interesting observation is the flattening out of execution time of a four versus a two-worker node HDInsight cluster (grey vs. orange line).
Of course, these results are specific to the simplified dataset and schema we provide with the solution demo. With much larger real-world datasets in SQL Server, which typically runs multiple queries competing for resources, more dramatic performance gains can be expected.
The next question to ask is when does it become cost effective to switch over to using Query Scale-Out? The below chart incorporates the pricing of resources used in this experiment. You can see a detailed pricing calculation here.
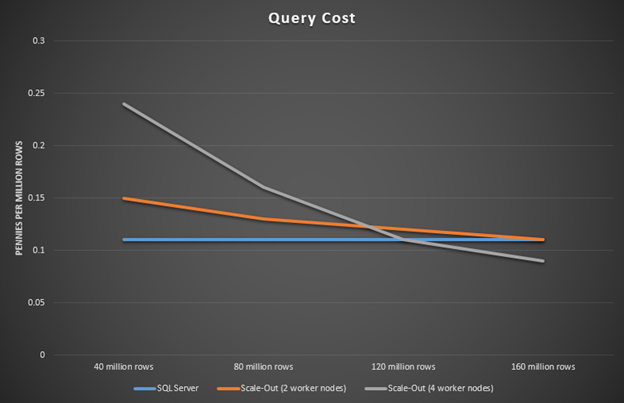
Figure 5: Query execution time with and without scaling (with pricing)
You can see that with 40 million rows it's cheapest to execute this query on SQL Server only. But by the time you are up to 160 million rows, Scale-Out becomes cheaper. This shows that as the number of rows increases, it could become cheaper to run with scaling out. You can use these types of benchmarks and calculations to help you deploy your resources with an optimal balance of performance and cost.
Try It Yourself, with One-Click Deployment
To try out the data virtualization techniques discussed in this blog post, deploy the solution demo in your Azure subscription today using the automated one-click deployment solution.
To gain a deeper understanding on how to implement data virtualization techniques, be sure to read our technical guide.
Robert