La scalabilità ed il partizionamento in entità (Parte 2)
Proseguendo la “riflessione” sull’utilizzo del partizionamento in entità come tecnica di scalabilità iniziato nel precedente post , voglio qui aggiungere alcuni esempi tratti da applicazioni su cui ho lavorato in passato in alcuni clienti, con lo scopo di chiarire ulteriormente le condizioni di applicabilità di questa tecnica.
Un buon esempio può essere fatto con alcune tipica funzionalità presente nei siti di commercio elettronico: la gestione del carrello e dei clienti. In questo caso l’esigenza è quella di creare una entità che rappresenti lo stato degli elementi che il cliente utilizzatore del sito seleziona a partire dal catalogo per confermare il successivo acquisto e le informazioni relativa al cliente stesso. Possiamo identificare semplificando e trascurando la successiva attività di pagamento due elementi-entità fondamentali: il cliente e le sue informazioni e per l’appunto il carrello. Generalmente il carrello viene pensato per essere associato alla sessione del browser a meno di non averlo annullato o di aver acquistato mentre ovviamente le informazioni del cliente sopravvivono alla sessione.
Entrambe le entità possono essere ricondotte ad una chiave che le identifica univocamente in modo estremamente semplice: il cliente attraverso l’utilizzo dello userid selezionato alla registrazione, il carrello con un GUID generato al momento dell’inserimento del primo elemento nello stesso durante una sessione.
L’ architettura del sito viene sempre implementata attraverso la classica distribuzione su tre livelli logici ed in questo caso lo strato di accesso ai dati che permette l’accesso alle due entità, utilizza le chiavi anche per la determinazione della partizione in cui le entità sono fisicamente inserite. Nel caso della gestione delle informazioni del cliente si può, ad esempio, utilizzare un database di catalogo per determinare l’associazione tra la stringa di connessione al database che contiene effettivamente i dati del cliente e lo userid del cliente stesso. Questo ovviamente prevede che lo stesso strato di accesso ai dati in fase di memorizzazione dei dati dell’utente, assegni un database ai dati del cliente con una logica predeterminata (genericamente in modo statico) e registri l’associazione userid , stringa di connessione del database contenitore nel database di catalogo. L'assegnazione viene fatta staticamente e successivamente, sulla base dei dati di utilizzo, si strutturano procedure di ridistribuzione dei dati tra gli storage. Di solito si cerca di accorpare su una macchina i dati degli utenti che generano maggior traffico, con i dati degli utenti a minor traffico in modo da massimizzare le risorse Hw.
Il catalogo così ottenuto, che indichiamo come catalogo entità clienti, può essere a sua volta partizionato oppure, replicato in più copie sfruttando i meccanismi di replica offerti dai principali database o con altre tecniche e bilanciato staticamente rispetto alle richieste di accesso.
Implementato in questo modo il partizionamento avremo uno strato di accesso ai dati che determina la posizione del cliente e la stringa di connessione da utilizzare, sfruttando le informazioni del catalogo, offrendo un accesso trasparente ai chiamanti. In questo modo la logica di business richiede una operazione su una specifica entità cliente fornendo lo userid e lo strato di dati determina dinamicamente la partizione corretta e vi accede in modo trasparente al chiamante.
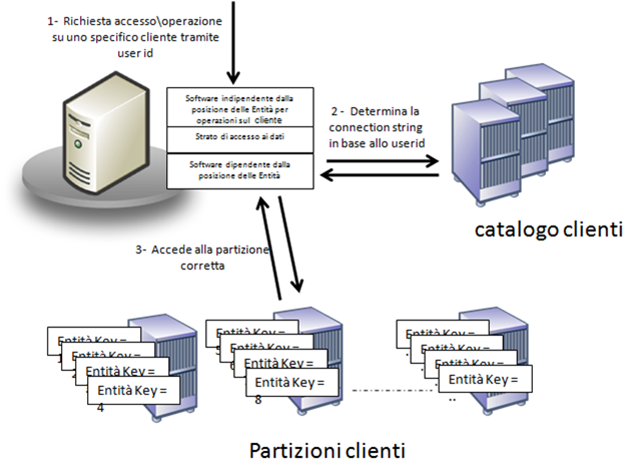
Nel caso del carrello la gestione del partizionamento viene genericamente gestita o con un catalogo dove le sessioni vengono aggiunte in modo statico alle diverse macchine o con un algoritmo che permette di calcolare l’id della macchina a partire dalla chiave univoca del carrello stesso (genericamente un guid) che viene assegnato al carrello al momento della sua creazione. Il guid del catalogo vene associato alla sessione o inserito in un cookie del browser e così estratto nuovamente ad ogni richiesta ed associato al cliente in fase di autenticazione dello stesso. Il carrello, infatti, viene genericamente conceso anche all’utente anonimo.
Sulle macchine database che gestiscono i carrelli vengono poi eseguiti dei Job periodici o altri tipi di tecniche che permettono di cancellare i carrelli scaduti, in modo del tutto simile a quanto avviene per le sessioni condivise tra le macchine di front-end.
Ovviamente questo è un esempio di come sia possibile applicare il partizionamento delle entità in questo tipo di scenario, stiamo volutamente trascurando alcuni aspetti di sicurezza e transazionalità della soluzione per semplificarla e mettere in evidenza l’utilizzo della tecnica.
Non è sempre necessario anche in scenari Internet che da subito la nostra applicazione debba rispondere ad un elevato numero di utenti ricorrendo effettivamente a partizionamento eccessivi o la presenza di cataloghi replicati. Pensare l’architettura in questa modalità , però, ci permette in qualunque momento di poter rapidamente rispondere all’eventuale incremento di traffico sul nostro sito di commercio elettronico, potendo aggiungere facilmente risorse hw e potendo sfruttarne a pieno le potenizlità con semplicità, senza riscritture di codice, agendo essenzialmente in modo configurativo.
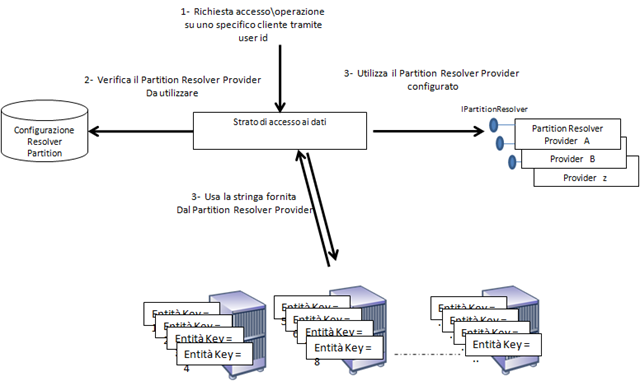
Per poter rendere ancora più flessibile l’utilizzo del partizionamento di entità, è possibile ripensare al pattern utilizzato dal partition resolver di ASP.NET 2.0 ed implementare lo stesso tipo di concetto nel nostro strato di accesso ai dati, cosa che consiglio sempre di fare. In questo modo si può separare l’elemento che determina la stringa di connessione della partizione per l’entità richiesta e renderlo un provider. Questo permette di poter di base fare un’implementazione banale che legge, ad esempio, da web.config la stringa di connessione in modo statico e in caso necessità di partizionamento, agire configurativamente e sostituire il risolutore della stringa di connessione, con in grado di consentire l’utilizzo, ad esempio, di un catalogo o un altro algoritmo di risoluzione del partizionamento.
Per poter implementare un comportamento come quello illustrato è possibile applicare una derivazione del pattern strategy o del provider model di ASP.NET. Ad esempio, si può stabilire un’interfaccia che il provider del partition resolver deve implementare:
interface IPartitionResolver {
string GetConnectionString(string Key);
}
e lo strato di accesso ai dati alla nostra entità aggancerà a runtime il provider stabilito attraverso una configurazione specifica nel web.config .
L’utilizzo di tecniche di incremento della scalabiltà come queste non è sempre semplice da applicare, non può essere esteso a qualunque tipo di situazione ed impone un notevole numero di vincoli in particolare negli aspetti collegate alle attività che comportano l’interazione tra diverse entità in una singola transazione. Per transazione intendo la classica definizione del termine con la garanzia delle caratteristiche rappresentate dall' acronimo ACID. Le entità , infatti, possono essere potenzialmente su macchine database differenti e l’utilizzo di transazioi distribuite non è di certo consigliabile assolutamente non pratico in applicazioni di grandi dimensioni, proprio perchè poco compatibile con la scalabilità. Ma su questi aspetti continuero a “rifettere ad alta voce” in un succesivo post.
Comments
- Anonymous
December 28, 2007
PingBack from http://blogs.msdn.com/giuseppeguerrasio/archive/2007/06/11/la-scalabilit-ed-il-partizionamento-in-entit.aspx