El almacenamiento en Hyper-V (v 1.1)
Introducción
Continuando con la serie de artículos que empecé con el articulo sobre como escoger un host equilibrado, los procesadores y la memoria, hoy os hablare del almacenamiento y la idea es cerrar esta serie con un articulo sobre redes.
En un entorno no virtualizado la carga del almacenamiento se distribuye entre la SAN y el almacenamiento local de los servidores, mientras que en un entorno virtualizado lo mas probable es que la SAN absorba prácticamente toda la carga.
Desgraciadamente la virtualización no siempre va acompañada de un análisis adecuado y gracias a la potencia de las tecnologías de hoy en día podemos tener la sensación de que la virtualización es un saco que lo aguanta todo, que no hay que tener cuidado, sin embargo mas tarde o mas temprano tendremos que poner la atención en diferentes elementos de nuestra plataforma si es que quieres que esta pueda seguir asumiendo carga y mantener el rendimiento dentro de unos parámetros aceptables.
La verdad es que con mucho considero el almacenamiento el aspecto mas complicado de la virtualización, la cantidad de elementos que intervienen es amplísima empezando por las cabinas en constante evolución gracias a un mercado súper-competitivo en el que como dice mi compañero David Cervigón cuyo conocimiento sobre estos temas es mas que envidiable “en el almacenamiento todo esta por hacer”.
En cuanto al almacenamiento en la virtualización existen dos corrientes de pensamiento básicas:
1) Estandarizar una configuración determinada, llenarla mientras aguante, escalar cuando sea necesario para mantener un rendimiento aceptable
Contras:
-Hay cargas que es complicado virtualizar de esta forma, especialmente las que hagan uso intensivo de disco.
-Las implicaciones terminan apareciendo desde el punto de vista de backups/recuperaciones, rendimiento no predecible, etc.
-Para mitigar en cierta forma el problema se puede terminar moviendo frecuentemente los discos de las VMs lo que al final es menos eficiente que pensar en ello desde el principio
-A medio o largo plazo se termina teniendo que replantearse el almacenamiento o comprar sistemas mas potentes que nos den margen durante mas tiempo
PROS:
-Es un sistema simple y rápido a primera vista
-Puede funcionar sin problemas en muchos entornos cuyas infraestructuras de almacenamiento están sobredimensionadas.
2) Estandarizar las configuraciones apropiadas para obtener desde el principio un rendimiento predecible y optimizado, lo que requiere conocer y analizar diferentes aspectos del almacenamiento
Contras:
- Requiere algo mas de tiempo y conocimientos para el análisis
-Puede suponer un mayor numero de volúmenes y espacio consumido al principio de los proyectos
PROS:
-Una vez realizado el trabajo inicial es fácil de mantener
-Evita problemas con el tiempo siendo una arquitectura predecible
-El rendimiento general es mejor y sostenible
Si me preguntarais por mi opinión personal os diría que en general soy partidario de la segunda opción,.
Dado que este tema es difícil de entender solo escuchando una sesión técnica cosa que hago muy a menudo, he decido escribir este post de forma que pueda servirme de apoyo al explicarlo y esperando que os sea de utilidad a todos los que terminéis aquí por alguna razón.
Aviso: Cada cabina es un mundo y el numero de combinaciones entre discos, arquitecturas, conectividad y parametrización es infinita así que todas las cifras que muestro en este articulo son para los sistemas específicos en los que he realizado las pruebas o de aquellos cuya información he visto reflejada en diferentes pruebas realizadas por Microsoft o los fabricantes, cada entorno insisto tendrá sus propias cifras. En este articulo hablaremos también de como averiguar las cifras actuales de tu entorno y como realizar mediciones del impacto de los cambios que hagas.
Que vamos a ver en este articulo:
- Conceptos generales sobre almacenamiento
- Patrones de uso
- El tipo de interface de disco
- El Disco
- Las LUNs y las cabinas
- El RAID y el tamaño de banda
- Formateando nuestros discos (GPT vs MBR, el “unit allocation size”)
- Evitando problemas de alineamiento
- Conoce tu hardware
- Aprende a probar el rendimiento del almacenamiento
- El almacenamiento en Hyper-V
- Haciendo las cosas bien: la importancia del análisis
- De físico a virtual
- Encriptación y compresión
- Arranque desde SAN
- ¿Que dispositivos de almacenamiento puedo usar con Hyper-V?
- MPIO
- Usando iSCSI
- Tipos de discos en las maquinas virtuales
- Todo lo que tienes que saber sobre CSV y otros tipos de discos en los hosts
- Diseñar los discos duros virtuales de las VM
- Los limites de Hyper-V para hosts y VMs
- ¿Necesitas aun mas rendimiento?
Conceptos generales sobre el almacenamiento
Para que podáis sacar el mayor partido del articulo tengo que asegurarme de que conocéis algunos conceptos fundamentales del almacenamiento que muchas veces son pasados por alto, conocerlos os será igual de útil en entornos físicos que virtuales incluso con diferentes fabricantes de virtualización.
Patrones de uso
Dentro de un servidor existen a parte del sistema operativo aquellos servicios responsabilidad del servidor.
Cada uno de estos servicios hace un uso diferente del disco duro, de esta forma no es lo mismo el uso de un disco duro de un servidor de base de datos de un ERP que de un servidor de ficheros.
En base a estos diferentes tipos de uso podemos hablar de unos patrones que están formados por los siguientes elementos:
Escritura/lectura: Por ejemplo un servidor de ficheros suele ser un 80% lectura contra un 20% escritura, mientras que un servidor web generalmente será un 100% lectura.
Secuencial/aleatorio: Un servidor de streaming de video será 100% secuencial y normalmente todos los servidores que muevan grandes volúmenes de datos en bloque tenderán a ser secuenciales y los datos se leerán o escribirán de seguido, por ejemplo una base de datos será en muchas ocasiones aleatoria pues los datos estarán muy dispersos.
Tamaño de la operación: Por ejemplo muchas veces un sistema determinado como por ejemplo Exchange o SQL Server suelen siempre leer del disco bloques del mismo tamaño por ejemplo dependiendo del producto 8KB,32KB o 64KB, mientras que un servidor de ficheros solicitara bloques de muy diferentes tamaños donde a lo mejor las solicitudes de bloques de 64KB suponen el 10% de las operaciones y las de 16KB el 4% y así.
A cada operación de lectura o escritura a realizar la llamamos IO, las IO por segundo serán las IOPS.
En este articulo vamos a ver muchos parámetros que afectan al rendimiento del almacenamiento el primer paso para tomar buenas decisiones es entender el patrón de uso de tus servidores lo que puedes empezar haciendo con el performance monitor y tantas otras herramientas.
La siguiente tabla muestra ejemplos de algunos patrones estándar:

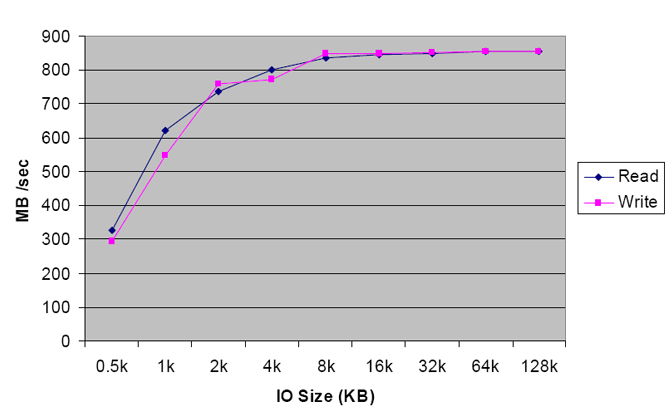
El tipo de interface
Es cierto que iSCSI esta creciendo mucho y creo que todos estamos muy contentos con iSCSI, solo tengo que decir que cuando vayamos a utilizar iSCSI tenemos que hacerlo de forma adecuada aislando y dimensionando adecuadamente las redes de iSCSI, utilizando Jumbo frames y otras optimizaciones que nos harán sacar el máximo partido de esta tecnología que nos aporta tanta flexibilidad.
Es muy común encontrarnos con fibra óptica (FC) que también es estupenda.
Para vuestro conocimiento aquí tenéis una tabla con el rendimiento teórico de diferentes tipos de arquitectura de almacenamiento.
Arquitectura |
Rendimiento (Máximo Teórico - Megabyte/sec) |
iSCSI (Gigabit Ethernet) |
125 MB/s |
Fibre Channel (2 GFC) |
212.5 MB/s |
SATA (SATA II) |
300 MB/s |
SCSI (U320) |
320 MB/s |
SAS |
375 MB/s |
Fibre Channel (4 GFC) |
425 MB/s |
Hoy en día empezamos también a ver interfaces de 10 Gigabit que usados para iSCSI o FCOE pueden dar rendimientos fantásticos como veis en el siguiente grafico:
El disco
Muchas SAN nos permiten elegir diferentes tipos de discos y luego poder crear diferentes grupos de discos con ellos.
Las ultimas cabinas de algunos fabricantes incluso son capaces de juntar en el mismo grupo diferentes tipos de discos y mover los bloques de datos a aquellos discos donde mejor estén, teniendo en cuenta la frecuencia de uso y patrón del mismo.
A la hora de escoger los discos estaremos impactando dos cosas principalmente; coste y rendimiento.
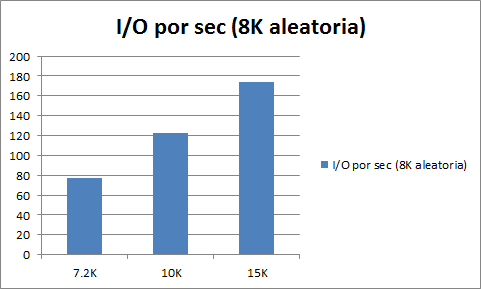
Un aspecto determinante a la hora de escoger el disco son las revoluciones del mismo (RPM), las velocidades mas comunes en entorno de servidores son 7200, 10000 y 15000RPM.
Las revoluciones tienen además otras connotaciones en los discos como podéis ver en las siguientes imágenes, esto implica por tanto que no solo los discos giran mas rápido sino que los platos son mas pequeños y las agujas se tienen que desplazar menos.
El siguiente grafico muestra el numero de operaciones en disco aleatorias de 8K que he obtenido en diferentes discos según sus revoluciones (en este grafico mas es mejor).
Si a alguno os intriga cuantas IOPS tiene un disco de estado solido (SSD) podríamos decir que hay quien las sitúa entorno a las 6000!!
El siguiente grafico os muestra la diferencia entre discos de 15K RPM y 10K RPM de tipo SCSI en el escenario concreto de lecturas secuenciales de bloques de 8K, añado también un disco SATA de 10K para que veáis también el impacto que tiene SATA vs SCSI. (En este grafico mayor latencia es peor mientras que mas lecturas por segundo es mejor).
Esto no significa que todos los discos tengan que ser de 15K por que son mejores, simplemente que debemos entender la diferencia y en ocasiones elegir que conviene mas.
Las LUNs y las cabinas
Una LUN (Logical Unit Number) es un disco virtual proporcionado por la SAN y que presentamos a uno o mas hosts.
Fijaros que digo “virtual” esto es así porque la LUN no tiene por que representar un disco físico conectado a la cabina, normalmente todas las cabinas reúnen grandes grupos de discos físicos incluso de diferente configuración y sobre estos generan estas unidades repartiendo los bloques que las componen entre los diferentes discos físicos, de esta forma se obtiene mejor rendimiento.
Algunas SAN aportan funcionalidades adicionales, como crear las LUN usando un modo que se llama “thin”, lo que hace que la unidad vaya ocupando espacio en la SAN a medida que se vaya usando, este tipo de LUNs están creciendo en popularidad, sin embargo os tengo que decir que dependiendo de la cabina esto puede suponer una pequeña penalización y os sugiero que establezcáis un baseline comparando el rendimiento de la misma carga con una LUN “thin” y otra normal de forma que conozcáis el impacto exacto en vuestro entorno a la hora de tomar vuestras decisiones.
Otra funcionalidad de algunas SAN muy interesante es la llamada deduplicación con la cual la SAN ahorra el espacio de los bloques que se encuentren almacenados en la SAN mas de una vez, como esto se realiza a nivel de bloque los ahorros pueden ser muy importantes ya que por ejemplo en un entorno VDI la mayor parte de los discos duros virtuales puede ser prácticamente igual. Una vez mas con esta funcionalidad recomiendo hablar con el fabricante para entender las buenas practicas que recomiende y tener especial cuidado con el impacto que esto tiene en la CPU y resto de recursos de nuestra cabina.
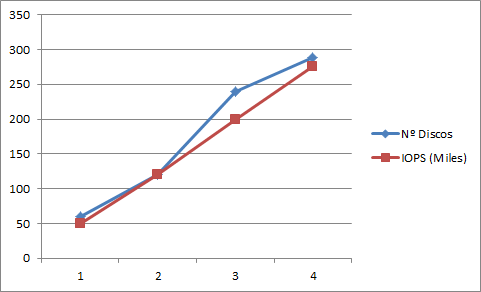
A medida que aumentamos discos en un grupo de discos de las SAN también aumentamos el numero de operaciones de entrada y salida (IOPS) que nos da la cabina.
El siguiente grafico muestra los datos para un fabricante determinado.
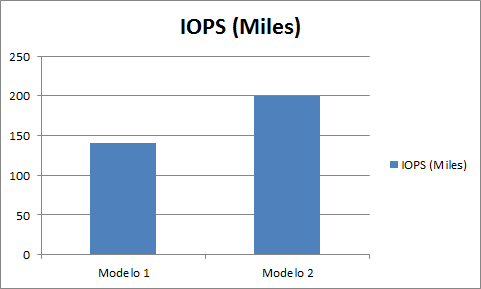
Las cabinas también avanzan a un ritmo tremendo así con cada versión y modelo los fabricantes añaden mas cache, mejores firmwares y elementos que aumentan el rendimiento, por eso elegir la cabina y comparar varias tiene mucha importancia.
El siguiente grafico muestra la diferencia entre dos cabinas del mismo fabricante pero de diferente gama, con discos con las mismas RPM e igual numero de discos (240)
El RAID
Otra aspecto a comentar es el nivel de RAID, como sabéis RAID tiene diferentes niveles, 0,1,2,3,4,5,6,5E, 6E, 0+1, 1+0, 30, 100, 50 y un buen numero mas de combinaciones y especificaciones propietarias, siendo los mas comunes de encontrar los raid 1 y 5 y limitando cada cabina que RAIDs puedes configurar.
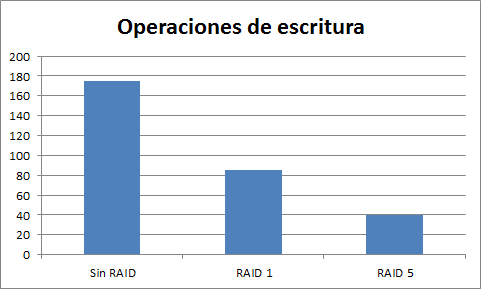
RAID 1: Los datos se escriben en dos discos, generalmente mejora lecturas dado que puedes leer de dos sitios pero degrada la escritura por la misma razón aunque el rendimiento de escrituras pequeñas es muy bueno.
Dado que por cada disco perdemos otro es un RAID muy caro

RAID 5: Buen rendimiento en lecturas pero malo en pequeñas escrituras, es mas barato por que pierdes menos discos que con RAID 1, en caso de fallo de un disco todo el rendimiento se ve afectado.

Fijaros en que puntualizo el aspecto de escrituras pequeñas dado que tiene mucha importancia de forma especial en discos que por ejemplo dediquéis a logs, en general las escrituras se ven perjudicadas por el RAID, el siguiente grafico muestra la penalización en discos de 15K RPM:
Los RAID tienen repercusiones tanto a nivel de tolerancia a fallos permitiendo al sistema sobrevivir a la perdida de algún disco que componga el RAID como a nivel de rendimiento, cada nivel tiene ventajas y desventajas, unos favorecen las lecturas otros las escrituras, unos las cargas secuenciales y otros las aleatorias incluso se puede hablar de impacto en CPU o diferencias según la cantidad de datos que se quieran mover en las operaciones.
Muchas cabinas implementan siempre cierto nivel de RAID a bajo nivel y normalmente esto no se puede elegir, por otra parte algunas cabinas ya no dejan elegir el nivel de RAID individual para las LUN, deciros que ese uso de cierto nivel de RAID a bajo nivel en muchas cabinas no esta reñido con que la LUN tenga además un nivel de RAID adicional.
Es cierto que las caches de las controladoras puede alterar estos rendimientos. En cualquier caso debéis hacer vuestras propias mediciones para entender las diferencias entre RAIDs que os da vuestra SAN.
Aunque todo es discutible, por norma general podríamos decir que RAID 1 es adecuado para los discos de sistema operativo y logs transaccionales mientras que RAID 5 o RAID 10 es mejor para discos de datos.
Hay mil recursos en internet para aquellos que tengáis dudas sobre RAID, yo de momento solo quiero que os quedéis con las diferencias de rendimiento entre cada uno.
Tamaño de banda
Cuando generas un RAID podríamos decir que los discos se parten en bandas o franjas, estas franjas tienen un tamaño y aunque no todas las cabinas permiten especificarlo este parámetro también tiene impacto en el rendimiento.
El siguiente grafico os muestra el impacto en el rendimiento del tamaño de franja con tres opciones de tamaño teniendo como base la prueba las lecturas aleatorias de bloques de 8K.
Como veis configurar apropiadamente el tamaño de franja nos proporciona un potencial beneficio en rendimiento nada desdeñable.
La gran pregunta es ¿como decido el tamaño de franja adecuado?, pues bien como con todo lo que tiene que ver con almacenamiento no hay una respuesta única.
Para tomar una decisión tendremos que entender esos patrones de uso de los que hablábamos al principio del articulo y buscar si los fabricantes de los sistemas que vayan a utilizar los discos nos han hecho alguna recomendación especifica, por ejemplo en el caso de Exchange 2010 el tamaño recomendado es de 256.
Un tamaño de banda pequeño suele favorecer la transferencia mientras que uno grande favorece que se puedan realizar múltiples operaciones en paralelo a lo largo de varios discos en la misma franja lo que beneficia a las bases de datos.
El tamaño de la banda tiene también un efecto multiplicador de IOPS una única IO que al llegar a la controladora de la cabina tenga que responderse con datos que estén en mas de una banda se convertirá en varias IOs vistas desde la SAN.
Las cabinas establecen normalmente un valor optimizado de forma general por el fabricante muchos clientes no se preocupan del tamaño de la franja hasta que no tienen que superar un problema de rendimiento, es algo a vuestra elección.
Formateando nuestros discos (GPT vs MBR y unit allocation size)
Cuando vamos a formatear un disco duro se nos pregunta si queremos hacerlo con un esquema de particionamiento GPT o con MBR.
MBR es él esquema estándar de toda la vida, nos permite 4 particiones primarias por volumen y un tamaño máximo de 2TB.
GPT podríamos decir que permite un tamaño casi ilimitado, pero que Windows limita a 256TB por partición con un máximo de 128 particiones.
GPT también añade algunas funcionalidades y otras restricciones (mas detalles en: https://msdn.microsoft.com/en-us/windows/hardware/gg463524 )
Yo por defecto aunque GPT tiene algunas ventajas os recomiendo usar MBR siempre salvo que necesitéis mas de 2TB y en ese caso mirar que no tengáis ninguna peculiaridad en los requisitos de vuestra configuración que os pueda dar algún problema.
El “unit allocation size” , cluster size o tamaño de bloque es otro de los parámetros que se nos pide a la hora de formatear un disco.
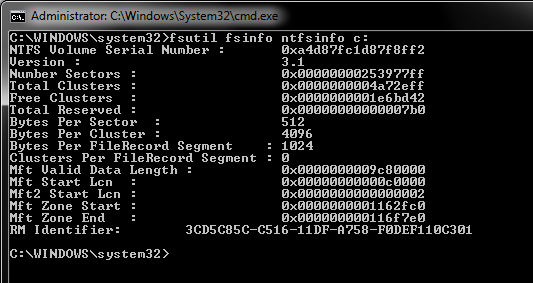
Este parámetro representa la menor cantidad de espacio en disco que un fichero puede consumir de forma contigua, el valor por defecto es 4096 bytes, por lo tanto cada vez que se accede al disco se producen tantas operaciones como bloques de este tamaño se tengan que leer para completar el volumen de datos pedidos.
Por ejemplo imaginar una carga como SQL Server donde podemos leer bloques de 64KB (65.536 bytes) si nuestra configuración de bloque es la configuración por defecto 4096 bytes, el sistema tendrá que usar muchas operaciones de 4096 bytes para completar los 64KB sin embargo si tuviéramos un tamaño de bloque de 64KB seria una sola operación.
Puedes saber el tamaño de bloque de un disco con el comando “fsinfo”
Modificar el tamaño de bloque según el patrón de uso puede tener un impacto que a veces no podemos dejar pasar por alto, el siguiente grafico os muestra como afecta el tamaño de bloque a la cantidad de MB por segundo que puede mover un servidor:
Por cierto como es lógico un tamaño de bloque muy grande repercute en menos espacio libre en disco.
Evitando problemas de alineamiento
Hasta ahora habéis visto en este articulo muchos parámetros relativos al almacenamiento, creo que todos los básicos al menos.
Ahora nos falta el que mas impacto puede tener y que se ve afectado por varios de los vistos hasta ahora, este otro aspecto es el que denominamos alineamiento.
Tratare de simplificar tanto como pueda al explicaros el problema de alineación.
Como hemos visto el sistema trata de escribir y leer en bloques de un tamaño ajustando este tamaño a las cargas reducimos las operaciones de disco necesarias para leer o escribir el volumen de datos que sea necesario, el asunto es que estos bloques de información son escritos físicamente en los bloques del disco (sectores) que aunque ya no siempre es así son de 512 bytes, si ambos elementos no están alineados, la lectura de un bloque en vez de producir una IO producirá varias a nivel físico.
Para alinear un disco es necesario que coincida el primer bloque con el comienzo de un sector, para conseguir esto se establece un “offset” o desplazamiento que es un espacio perdido (y algunas otras cosas) a partir del cual se empieza a escribir y que vale para alinear el disco.
Una correcta alineación de los discos puede suponer hasta un 30% de aumento de rendimiento.

Este articulo trata en el fondo de Hyper-V que siempre corre sobre Windows Server 2008 o superior, en Windows Server 2008 por defecto se emplea una alineación de 1024K.
Algunos sistemas podrían funcionar mejor con otros offsets, para averiguar si es tu caso consulta primero la información del fabricante de la cabina por si hace alguna recomendación.
Para saber cual es el offset de una unidad puedes usar WMI ( https://support.microsoft.com/kb/929491 )
Conoce tu hardware
Cabinas y controladoras tienen muchas veces parámetros que pueden mejorar sustancialmente el rendimiento.
Por ejemplo muchas controladoras incorporan caches que están configurados por defecto para un patrón de uso estándar, modificar este parámetro para adaptarlo al uso que preveas, puede traerte mejoras de rendimiento muy apreciables.
Aprende a probar el rendimiento de tus configuraciones de almacenamiento
La mejor forma de alcanzar las mejores combinaciones de parámetros es ser capaz de medir el rendimiento con cada combinación que quieras probar.
Una manera de hacerlo es con la herramienta IOMeter: https://sourceforge.net/projects/iometer/
Hay herramientas especificas para cargas como Exchange (Jet Stress) o SQL Server (SQL IO) que te permiten simular la presión de IO exacta de tus requisitos para estas cargas.
Es un proceso laborioso, si quieres sacarle partido resérvate el tiempo adecuado y prepárate una buena hoja de calculo para ir apuntando los resultados y las conclusiones de cada prueba
El almacenamiento en Hyper-V
Lo primero felicitarse si has llegado hasta aquí ahora si me he explicado adecuadamente tienes en la cabeza los conceptos que necesitas para entender el rendimiento del almacenamiento y por tanto podemos hablar ya de las peculiaridades de la virtualización con respecto a el.
Haciendo las cosas bien: La importancia del análisis
Has visto como para cada patrón de uso hay unos parámetros que benefician su rendimiento y otros que lo perjudican.
La virtualización ha venido de la mano de la estandarización en la parametrización del almacenamiento, mientras que hace años a la hora de poner un servidor de bases de datos en una gran empresa un DBA cualificado junto con un técnico de almacenamiento especializado en el fabricante de la cabina analizaban los mejores parámetros y se definían las LUNs adecuadas, RAIDs, tamaños de cluster, bandas, etc, etc. ahora generamos grandes LUNs en las cabinas todas con los mismos parámetros y colocamos encima decenas de discos duros virtuales.
Las cabinas son cada vez mas rápidas, los discos mejores, todo con mas cache y en general las cargas no tienen por que ser tan exigentes a nivel de IO, sin embargo cuando nos aproximamos a la capacidad en IOPS de la SAN, ponemos cada vez mas VMs o virtualizamos cargas importantes a nivel de IOPS nos podemos encontrar con problemas de rendimiento y entonces empiezan a surgir todas estas cosas de las que estamos hablando. ¿no es mejor hacerlo bien desde el principio?, es mas complicado pero también mas profesional y efectivo a medio y largo plazo.
Si hemos visto que para cada patrón de uso hay unas configuraciones mas optimizadas y convenientes, al hablar de virtualización la mejor configuración será aquella en la que la configuración de los volúmenes de los hosts venga dada por los patrones de uso de los discos duros virtuales que pongamos sobre ellos.
De físico a virtual, la importancia del almacenamiento
Es común convertir servidores de físicos a virtuales (P2V) y es curioso como al hacerlo nos olvidamos en muchas ocasiones de que estamos virtualizando servidores con varios discos con configuraciones que fueron optimizadas para la carga especifica del servidor.
Debemos de tener en cuenta estas configuraciones ya sea para reproducirlas al virtualizar o para obviarlas tendrás sus repercusiones
Si escogemos obviarlas y poner por ejemplo todo sobre la misma LUN, debemos asumir la posible perdida de rendimiento que habrá que sumar a la perdida de rendimiento que posiblemente obtendremos por virtualizar.
Encriptación y compresión de discos y Hyper-V
Los discos duros en el host sobre los que pongas los discos virtuales pueden ser encriptados con Bitlocker por supuesto perderas algo de rendimiento pero puede haber entornos en lo que no haya opción.
EFS esta soportado dentro de las VMs pero no en el host.
No se debe de ninguna forma usar compresión de discos en volúmenes usados para almacenar discos duros virtuales.
Arranque desde SAN
En ocasiones se decide que los host no tengan discos duros locales o que estos no sean usados para albergar el sistema operativo de los servidores, esto se consigue haciendo que el host arranque directamente desde la SAN.
Esta decisión normalmente se toma para salvaguardar el sistema operativo y sus configuraciones en la SAN o incluso para replicar esta configuración a otro CPD, hay que decir que esta configuración esta soportada para el host con iSCSI y FC.
Como opinión personal decir que estas configuraciones tienen sus requisitos y complejidad y que en general encuentro que Hyper-V no se beneficia de este sistema debido a que el host es un elemento altamente prescindible que incluso pude arrancar de VHD.
En cuanto a los ahorros de coste por arranque en SAN es algo que podríamos discutir también durante mucho tiempo especialmente por los requerimientos y el coste de cada elemento además de la complejidad añadida.
También es posible hacer que las VM arranquen desde SAN a través de iSCSI y PXE usando una tarjeta de red legacy y soluciones especificas de terceras partes como emBoot o Doubletake.
¿Que dispositivos de almacenamiento puedo usar con Hyper-V?
Cualquier hardware valido para Windows Server 2008 R2 es valido para Hyper-V R2 no hay un proceso especifico para Hyper-V debido a su arquitectura con lo cual te beneficias de poder usar una enorme cantidad de hardware, ¿quien saca un dispositivo de almacenamiento que no funcione con Windows Server?, no es algo muy comun…
MPIO
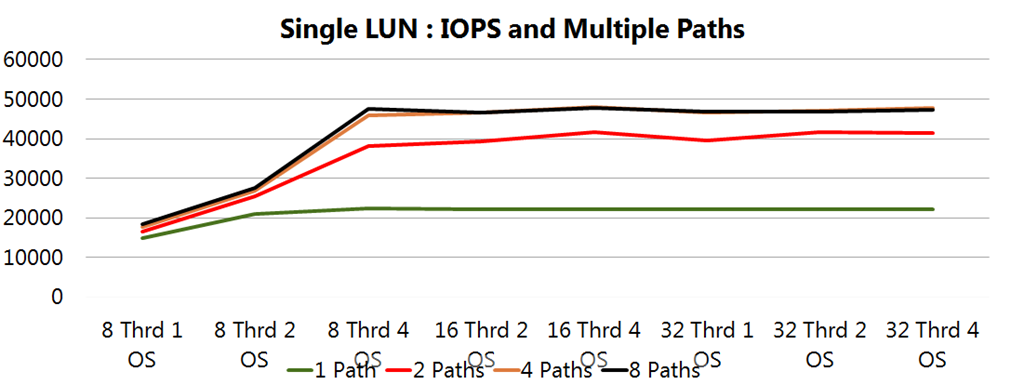
MPIO como sabéis os permite acceder por varios caminos al almacenamiento lo que aporta tolerancia a fallos y en algunos casos además mejoras en el rendimiento.
Se puede usar MPIO sin problemas en Hyper-V de hecho usarlo es nuestra recomendación, estudia las guías de configuración de tu fabricante para Windows server 2008 o 2008 R2 y sigue sus instrucciones.
Cuando uses iSCSI a través de tarjetas de red estándar no caigas en el error de configurar un teaming para tener MPIO en el acceso iSCSI, debes usar MPIO exactamente igual.
Haz pruebas con las diferentes configuraciones de MPIO (LB, HA, etc) entender como afectan al rendimiento y la alta disponibilidad en tu entorno te hará tomar las mejores decisiones.
El siguiente grafico te muestra como con ciertas configuraciones de MPIO se ganan IOPS al añadir caminos.
Usando iSCSI
Cuando vayas a usar iSCSI sigue las siguientes buenas practicas:
- Monta una red separada
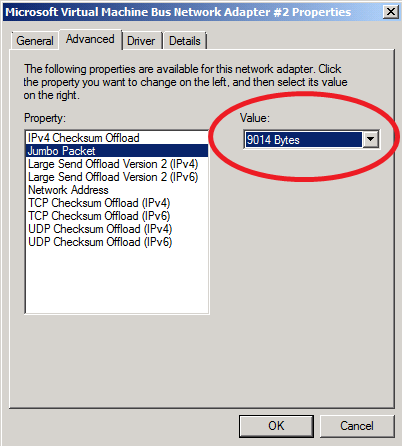
- Usa Jumbo frames y usa el tamaño de paquete a 9K como ves en la siguiente captura, reducirás la sobrecarga de usar jumbo frames hasta en un 84%
- En R2 los virtual switchs de Hyper-V soportan Jumbo Frames y las tarjetas de red virtuales también, eso si tienes que instalar los IC en las VM.
- Jumbo frames tiene que estar configurado en todos los elementos de la red por los que pase el paquete; tarjetas de red virtuales, virtual switchs, puntos de red, switchs fisicos, etc.
- Puedes probarlo con “ping –n 1 –l 8000 –f [otra IP dentro de la red iSCSI]”
- Dedica tarjetas de red específicamente a iSCSI
- Salvo en el caso de un guest cluster presenta siempre el almacenamiento iSCSI a los hosts y luego úsalo en las VMs como requieras con un VHD o directamente con passthrough (lo explico mas adelante)
Tipos de discos en las maquinas virtuales
A la hora de crear los discos duros de una maquina virtual tenemos que tomar varias decisiones, la primera es si crear el disco dentro de una controladora de disco virtual IDE o virtual SCSI, obviamente esto no tiene nada que ver con que por debajo el almacenamiento sea SCSI.
El disco de arranque de la VM siempre tiene que ser IDE, si conviertes una VM de VMWare que arranque desde SCSI SCVMM convertirá automáticamente todo para que funcione sobre IDE.
A partir de ese primer disco de arranque mi recomendación es que siempre crees una controladora virtual SCSI como mínimo en cada VM y el resto de discos los montes sobre esta controladora.
Si tienes una VM que requiere el máximo de rendimiento y tiene varios discos, puedes poner varias controladoras SCSI en la VM y balancear los discos entre ellas.
Con IC instalados en la VM el rendimiento de los discos es igual sean IDE o SCSI pero en las controladoras SCSI puedes añadir discos en caliente.
SCSI virtual requiere de los integration components y esta soportado en:
- Windows XP Prof x64
- Windows Server 2003, 2008 y 2008R2
- Windows Vista y Windows 7
- Suse Linux
Si una VM tiene muchos discos distribúyelos entre varias controladoras virtuales SCSI para un mejor rendimiento.
Los discos de una maquina virtual pueden ser de diferentes tipos y las maquinas virtuales estén o no estén en clúster pueden tener discos de diferentes tipos;
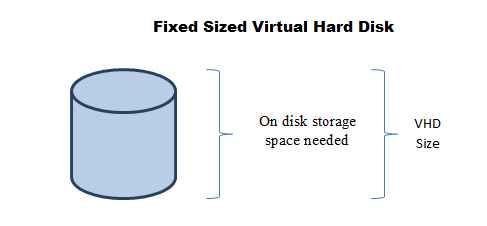
-VHD Fijos:
-Al crearlos reservan en el disco duro del host/cluster en el que se encuentren tanto espacio como configures
-En R2 el tiempo necesario para crear un disco VHD fijo se ha reducido mucho con respecto a la primera versión de Hyper-V
-Dan un muy buen rendimiento que puede llegar a suponer entre el 90 y 96% del rendimiento que experimentarías en físico con cualquier tipo de carga
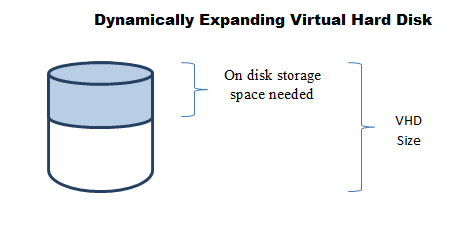
-VHD Dinámicos:
-Crecen en bloques de 2MB por defecto a medida que se van usando, cada vez que crece llena de ceros el bloque produciendo tanto el crecimiento como esta operación una serie de IOPS que pondrán en cola otras IOPS
-En RTM crecían en bloques de 512, el rendimiento era diferente y peor, al migrar VMs de RTM a R2 mantienes este tamaño de bloque.
-Algunos productos no están soportados cuando corren sobre discos dinámicos, por ejemplo Exchange.
-Se recupera el tamaño al compactarlos lo que requiere parar la VM o desmontar el disco, te recomiendo que antes de compactar el disco lo desfragmentes.
-El rendimiento de los discos duros es peor que el de los fijos, podemos decir que por ejemplo en escrituras aleatorias de 4K el rendimiento será de aproximadamente un 85% de lo que seria en una maquina física sobre un disco normal, sin embargo en escrituras secuenciales de 64K obtendrías hasta un 94% del nativo.
-Estos discos tienden a fragmentarse mas que los normales
-Los discos dinámicos son propensos a problemas de alineación
-Cuando se usan discos dinámicos especialmente si hay varios en la misma LUN hay que ser tremendamente cuidadoso con la monitorización del espacio libre en esa LUN, si no hay espacio libre suficiente, todas las VMs afectadas se pausaran.
-Estos discos en producción siendo usados por cargas que provoquen muchas IOPS suelen actuar de multiplicadores de IOPS en ocasiones incluso x4.
-VHD Diferenciales
-Otro tipo de discos que esta mas escondido son los discos diferenciales, la razón por la que están algo escondidos es en mi opinión por que son muy peligrosos si no se entienden bien y manejan con cuidado.
-En los discos diferenciales existe un disco al que denominamos padre o raíz que es de solo lectura, dependiendo de el hay un numero variable de discos virtuales fijos o dinámicos cada uno de los cuales solo contiene las diferencias con respecto al disco padre.
De esta forma imaginar que tenemos un disco padre en el que instalamos un Windows 7 y le hacemos un sysprep, luego generamos 10 diferenciales a partir de el e instalamos una actualización, cada uno de los diferenciales solo ocupara tanto como los bloques que haya modificado el proceso de sysprep al arrancar la maquina virtual y la instalación de la actualización.
Los ahorros en espacio son muy considerables pero la gestión es mas complicada y hay que analizar cuantos diferenciales puede tener un padre para no perder rendimiento.
Debemos de entender que el disco padre no debe modificarse bajo ningún concepto y que a nivel de rendimiento el disco padre soporta muchísimas lecturas por lo que hay que dimensionarlos adecuadamente, este tipo de sistemas se beneficia muchísimo de los discos de estado solido para ubicar el disco padre.
Puede haber una cadena de discos de este tipo, con R2 no se experimenta una perdida de rendimiento al encadenar discos diferenciales si bien considero que el reto administrativo si que se multiplica exponencialmente.
Estos tipos de discos son la base del funcionamiento las instantáneas de Hyper-V
-Passthrough
Por ultimo los discos passthrough en los cuales la VM accede al almacenamiento directamente sin existir un VHD atacando directamente el NTFS.
-El rendimiento es lo mas cercano que puede ser al rendimiento de un disco duro en una maquina física
-La VM accede directamente al hardware de forma no filtrada
-Los hosts no ven el disco, les aparece offline
-Passthrough se puede usar con VMs en cluster sin problemas
-Si paras la VM y pones el disco online en el host ves el contenido del disco de forma normal.
-No se pueden sacar instantáneas desde Hyper-V en maquinas con discos passthrough
-Normalmente desde el punto de vista de una VM un disco de este tipo puede dar aproximadamente entre un 93% y 98% del rendimiento que se obtendría del mismo disco usado por una maquina física.
-Usar estos discos es menos productivo y cómodo que los discos VHD fijos, úsalos cuando te sea estrictamente necesario, por recomendación de soporte de aquello que vayas a virtualizar o por que la pequeña diferencia de rendimiento contra un disco fijo te sea necesaria.
-Al añadir un disco passthrough a una VM seleccionas el disco físico (offline)
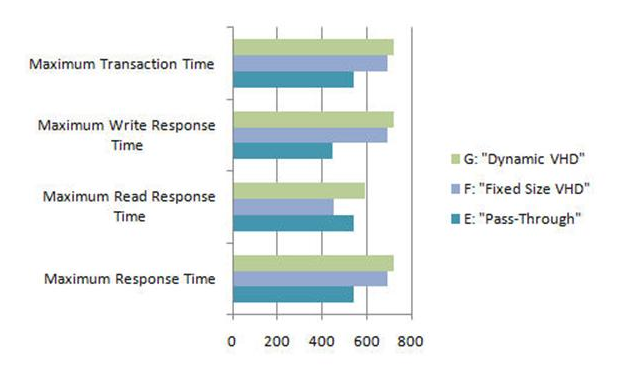
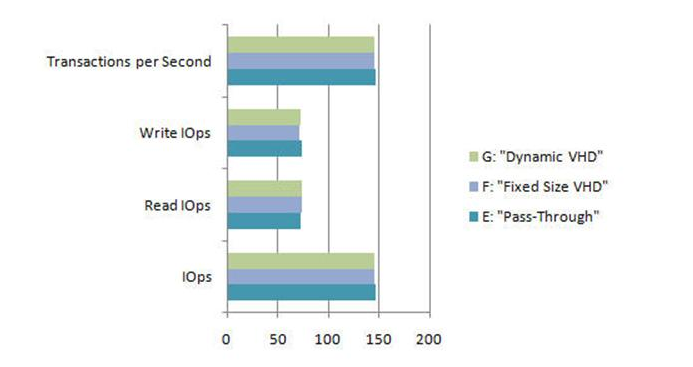
Los siguientes gráficos te muestra las diferencias de rendimiento entre los diferentes tipos de disco (menos es mejor):
Una vez mas no se trata por regla de coger el “mejor” tipo siempre dado que no existe un “mejor” tipo de disco para todo, en este articulo encontraras un punto llamado “Diseñar los discos duros virtuales de las VM ” donde os comentare mis recomendaciones para tomar la elección adecuada.
El formato VHD
VHD es un formato que Microsoft a “abierto” y su especificación esta disponible, otras plataformas ya lo usan activamente como formato para virtualizar.
Todo lo que tienes que saber sobre CSV y otros tipos de discos en los hosts
En un servidor que no forme parte de un cluster podremos tener discos duros locales o SAN en los que ubiquemos VHDs o que sean usados como passthrough por las VM, en cualquier caso los mismos consejos de todo el articulo son igualmente validos, alineamiento, patrón de uso, RAID y tamaño de bloque serán aspectos a tener en cuenta.
CSV (Cluster Shared Volumes) nos permite sobre una misma LUN tener discos virtuales de varias VMs en cluster pudiendo estar cada una de esas VMs corriendo en diferentes nodos.
Por tanto CSV nos da principalmente una ventaja de administración ya que no tendremos que estar solicitando continuamente LUNs en la SAN para cada VM.
CSV también ahorra espacio ya que en vez de tener que dejar espacio libre en cada LUN para los ficheros de las VMs, BINs, etc podemos tener cierto ahorro por la economía de escala que implica tener mas VMs sobre la misma LUN, sin embargo hay que tener mucho cuidado de mantener espacio libre en los CSV.
CSV también hace que las live migration sean mas rápidas por razones que explico mas tarde.
Finalmente como punto a favor CSV incorpora funcionalidades de resistencia ante fallos en el acceso a la SAN que pueden resultar interesantes y de las que hablo también mas adelante en este mismo articulo.
En el lado negativo hay que decir que CSV requiere que si quieres usar backups de las maquinas virtuales a nivel de hosts pienses en el backup cuidadosamente y evalúes si tu herramienta de backup soporta CSV y si tu cabina dispone de un proveedor de instantáneas hardware, en cualquier caso tal vez puedas evaluar nuestro producto de backups System Center Data Protection Manager 2010 (DPM) para simplificar y optimizar el proceso.
Otro aspecto a tener en cuenta es que cuando usas CSV si hay problemas de rendimiento es difícil aislar que VM lo provoca.
En general te recomendaría que las VMs cuyas IOPS las consideres mas criticas las aísles en sus propias LUNs.
En un servidor que es miembro de un cluster podemos tener varios tipos de discos compartidos (presentados a todos los nodos del cluster):
-Discos que son usados para albergar uno o mas VHD de una misma VM
-Discos CSV que pueden contener uno o mas VHD de una o mas VMs
-Discos que serán usados como passthrough por una VM
Estos tres tipos de discos pueden ser combinados de cualquier forma.
Una misma VM puede tener discos en diferentes tipos de disco de cluster, juntando discos VHD en CSV con discos VHD sobre LUNs dedicadas y además teniendo también algún disco passthrough.
En contra de lo que mucha gente opina CSV no es un requisito para Live Migration (mover maquinas virtuales de nodo en caliente sin perdida de servicio) cualquier tipo de almacenamiento en cluster es compatible con Live Migration.
Sin embargo hay que decir que debido a que al mover una VM cuyo almacenamiento este localizado sobre CSV no es necesario arbitrar reservas en la SAN ni cambiar propiedades una Live Migration sobre CSV tarda menos desde el punto de vista de normalidad dentro de la VM que sobre LUNs dedicadas.
Cuando se hace una live migration de una VM con LUNs dedicadas hay un momento en el que hay que cambiar la propiedad del disco en ese momento la VM no puede escribir en disco generándose colas dentro de la VM, este proceso dura unos segundos y si estamos usando VHD nos beneficiamos de la mecánica de cache que tiene este formato, sin embargo si usamos discos passthrough no tendremos esta cache, usando CSV este proceso es prácticamente imperceptible.
Si por ejemplo estamos en un geocluster el arbitraje de la propiedad del disco puede tardar algo mas, conviene hacer pruebas de estos tiempos para ver si las cargas se ven afectadas, por ejemplo SQL Server o Exchange son muy quisquillosos cuando no pueden escribir en disco por mas de unos segundos.
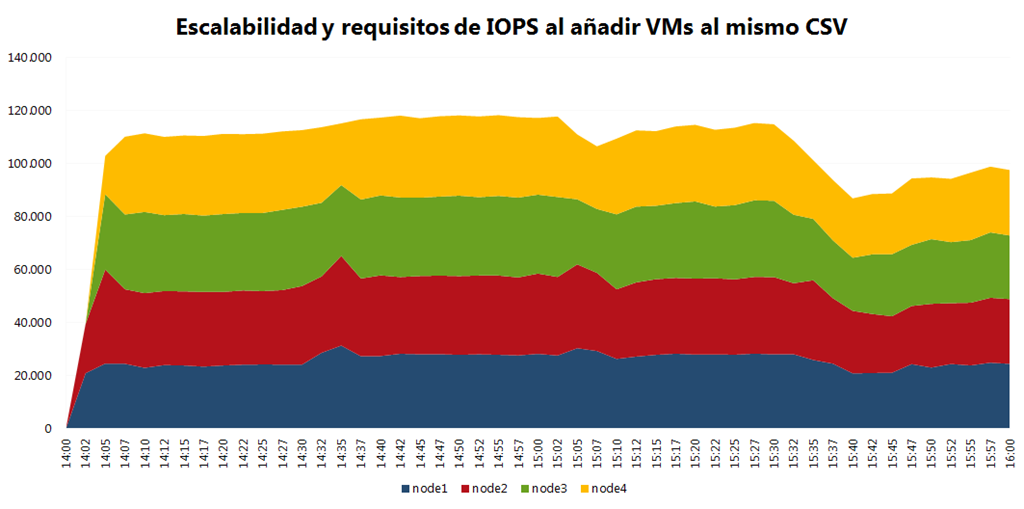
CSV no impone un limite a las IOPS que soporta, cuanto mas IOPS aporte la cabina mas tendrá el CSV, sin embargo se percibirá mejor rendimiento si repartimos las VMs entre varios hosts, dado que al final cada host solo tiene unas estructuras de acceso tanto físicas como lógicas a las LUNs y estas pueden suponer un cuello de botella.
A medida que añadimos mas y mas VMs al mismo CSV incrementamos el numero de IOPS que reclamamos de esa LUN a la vez que conservamos las mismas estructuras de acceso podemos entrar en un problema de contención, por eso debemos ser muy conscientes del aumento de requisito de IOPS.
En cuanto a CSV no debéis pensar en el como un saco que lo aguanta todo, es importante seguir algunas recomendaciones:
- Configura siempre una red especifica para CSV (explicado en este articulo mas adelante)
- En general depende de la cabina pero una posible recomendación es que para virtualización de servidores estandarices un numero de VHDs por CSV, 10-15 es un buen numero o estandariza un tamaño razonable 500GB es una buena cifra, esto te obligara a balancear la carga entre varios CSV.
- Para virtualización de escritorios puedes usar tamaños mayores para tus volúmenes CSV
- Especializa los CSV según sus configuraciones (ver el siguiente punto “Diseñar los discos duros virtuales de las VM”)
- Monitoriza adecuadamente los CSV (colas, espacio libre, eventos de CSV y cluster) SCOM es fantastico para esto pues los Management packs del hardware, la SAN, Windows Server, failover cluster, hyper-v y SCVMM te darán la visión completa e incluyen las reglas especificas para entender CSV.
- Cada volumen CSV tiene un nodo que actúa de owner del volumen, este nodo realiza algunas acciones especiales sobre los volúmenes y además es el nodo que en principio soportara la carga de redirección en caso de que se tenga que producir por esta razón es bueno mantener distribuidos entre los nodos del cluster el ownership de los volúmenes.
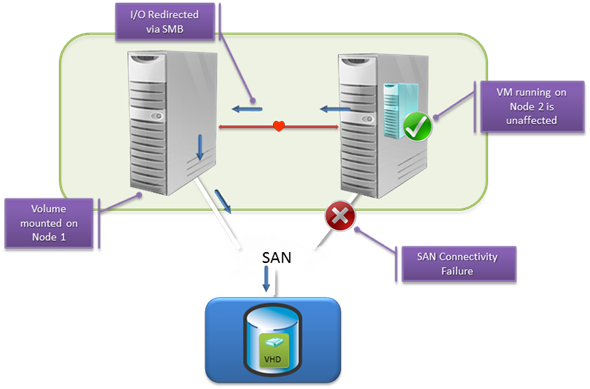
Como decía antes CSV nos da también funcionalidad de tolerancia a fallos supongamos el siguiente ejemplo:
- Un cluster de dos nodos A y B
- Las VM se encuentran sobre un CSV
- El nodo B pierde conexión con la SAN por todos los caminos
- Sin CSV las maquinas virtuales fallarían al no poder escribir en disco y arrancarían en el otro servidor a través del cluster
- Con CSV el nodo B accede a los discos a través de una conexión de red con el nodo A (la red que se use es configurable)
- Las VMs siguen funcionando con normalidad hasta que un administrador corrija la situación.
A este comportamiento lo llamamos redirección CSV y la primera vez que un administrador de Hyper-V lo escucha es normal que muestre cierta inquietud.
Para empezar si tienes SCOM, eres avisado a través de una alerta de que se ha producido esta redirección, si no tienes SCOM lo veras en la consola de cluster.
Durante la redirección podríamos decir que el rendimiento depende de la calidad de la red entre los nodos, pero incluso con una tarjeta dedicada de 1GB el rendimiento es suficiente para pasar por esta situación excepcional y de contingencia, por supuesto si es de mas mejor.
Si la red de CSV se cae en lo que se esta usando se usara automáticamente otra tarjeta de red si es posible.
Puedes configurar que red se usara por defecto para CSV usando powershell: https://technet.microsoft.com/es-es/library/ff182335(WS.10).aspx
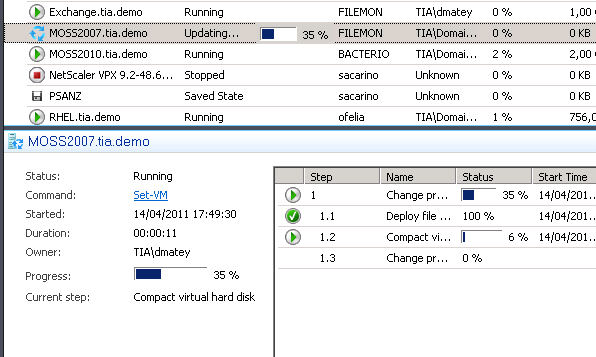
En las capturas a continuación puedes ver el proceso de fallo y como afecta a una VM con SQL Server con carga:
1) El volumen CSV funciona adecuadamente

2) Un nodo pierde conexión con la SAN por todos los caminos, el otro nodo coge la pertenencia del volumen si es que no la tiene ya y este nodo empieza a trabajar con el CSV en redirección

3) Vemos como la tarjeta de red dedicada a CSV aumenta drásticamente su uso unos 120Mbps, en otros casos he visto llegar a los 700Mbps de transferencia

4) SCOM detecta la situación y nos avisa primero desde el management pack del hardware en este caso HP

Y a continuación desde el Management pack de failover cluster

5) En todo momento podemos ver desde el host el rendimiento de CSV redirigido:

6) En lo que dure la redirección el rendimiento de IO cambiara dentro de la VM siendo en general menos sostenido pero usable

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
La redirección de CSV se produce por SMB2 lo que requiere que en los adaptadores de red que vayan a ser usados por CSV dejes activados el cliente para redes microsoft y el compartir impresoras y archivos.
{kind=link}
Los adaptadores de red usados por CSV de todos los nodos tienen que estar en la misma subnet
Durante el backup de un volumen CSV también se realiza una redirección, es importante que lo tengáis en cuenta pudiendo usar proveedores de instantánea Hardware para minimizar el tiempo de redirección, en caso de usar DPM incluso con el proveedor de instantáneas software se pueden realizar configuraciones adicionales que minimizan el impacto de la redirección durante los backups.
Indudablemente usar volúmenes CSV de un tamaño de 500Gb en contra de volúmenes de 2TB por ejemplo hace que el numero de VMs que entran en redirección ante la perdida de un volumen se ve reducido al igual que los tiempos de backup de todo el volumen.
Sin usar CSV puedes poner mas de un VHD en una LUN de cluster, pero tienes que asegurarte de no poner nunca VHDs de mas de una VM si lo haces a parte de no estar soportado conseguirás que al mover una VM afectes a la otra inevitablemente.
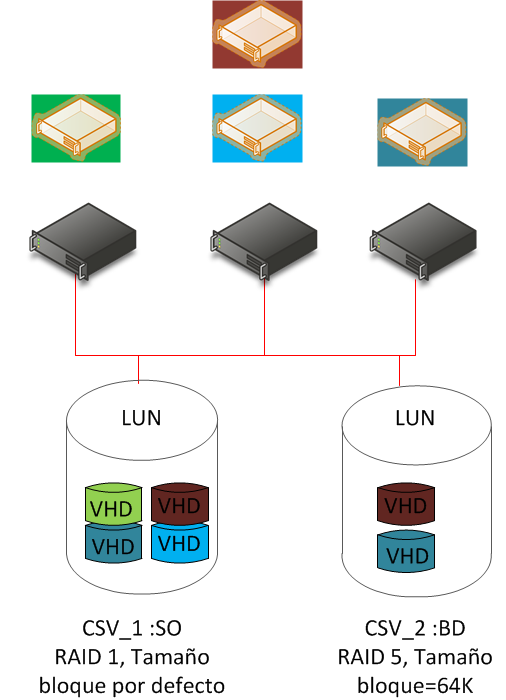
Diseñar los discos duros virtuales de las VM
En la primera parte de este articulo hemos hablado de los patrones de carga y de como los diferentes parámetros de configuración del almacenamiento afectaban al rendimiento.
La clave para un buen diseño del almacenamiento en la virtualización es mantener un alineamiento entre los requisitos de la carga en la VM, la configuración de los parámetros del disco virtual y los parámetros del disco en el host.
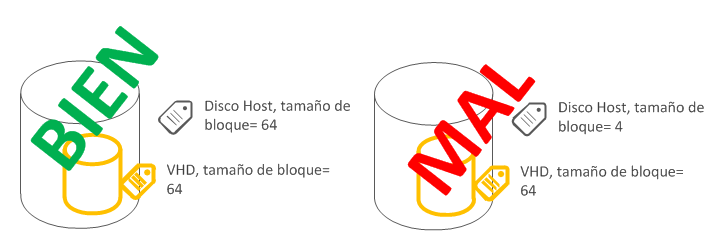{kind=link}
De esta forma un cluster tendrá que tener diferentes tipos de discos físicos según las cargas que deba soportar.
Podemos diferenciar claramente entre cuatro tipos de necesidades:
- Discos duros de sistemas operativos:
- Si la VM no es 2008 alinear manualmente antes de instalar, para ello puedes crear el VHD desde el host y luego usarlo para la VM
- Dejar el tamaño de cluster por defecto
- En producción siempre VHD fijos
- Sobre CSV siguiendo las buenas practicas que te he indicado en este articulo sobre CSV
- La LUN de este CSV debería ser RAID 1 preferiblemente
- En general discos SATA o bajas RPM son factibles
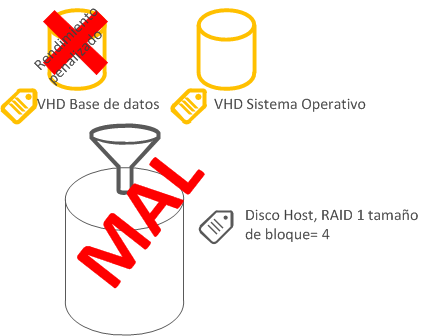
- Discos de logs transaccionales
- Sobre CSV de forma general, si el disco esta sometido a una carga que se considere especial usar una LUN dedicada o un disco passthrough como ultima opción solo si un disco VHD fijo sobre LUN dedicada no cumpliera con tus requisitos de IOPS
- En cualquier caso la LUN debería ser RAID 1 nunca RAID 5
- El tamaño de bloque tanto del disco duro virtual en caso de usarse como del disco sobre el que este podría ser de 32K o 64K
- Si la VM no es 2008 alinear manualmente antes de instalar, para ello puedes crear el VHD desde el host y luego usarlo para la VM
- Tener en cuenta el Nº de discos de este tipo que se situaran por CSV, en función de ello calcular las IOPS y tomar las decisiones de RPM y tamaño de banda de forma acorde
- Discos de bases de datos
- Sobre CSV de forma general, si el disco esta sometido a una carga que se considere especial usar una LUN dedicada o un disco passthrough como ultima opción solo si un disco VHD fijo sobre LUN dedicada no cumpliera con tus requisitos de IOPS
- En cualquier caso la LUN debería ser RAID 5 o 10
- El tamaño de bloque tanto del disco duro virtual en caso de usarse como del disco sobre el que este debería ser de 64K o ser evaluado de forma especifica pero siempre en sintonía
- Si la VM no es 2008 alinear manualmente antes de instalar, para ello puedes crear el VHD desde el host y luego usarlo para la VM
- Tener en cuenta el Nº de discos de este tipo que se situaran por CSV, en función de ello calcular las IOPS y tomar las decisiones de RPM y tamaño de banda de forma acorde
- Discos de ficheros
- Sobre CSV
- RAID 5
- Si la VM no es 2008 alinear manualmente antes de instalar, para ello puedes crear el VHD desde el host y luego usarlo para la VM
- En general el tamaño de bloque por defecto es valido debiendo ser el mismo para el disco físico que para el virtual
- En general discos SATA o bajas RPM son factibles
{kind=link}
{kind=link}
Los limites de Hyper-V para hosts y VMs
Cada maquina virtual en Hyper-V puede tener 4 discos duros IDE y 4 controladoras SCSI, cada una de ellas con hasta 256 discos duros.
El tamaño máximo de un VHD es de 2TB.
No hay limite a los volúmenes CSV o normales que puede tener un cluster o servidor, dependiendo el numero máximo de las limitaciones que tenga el hardware y los drivers, en general podemos decir que cada target de almacenamiento puede sostener unas 255 LUNs y Windows a su vez unos 255 Targets.
¿Necesitas aun mas rendimiento?
Si has agotado todo hasta aquí aun queda algo mas, hay mas parámetros de almacenamiento que se pueden tocar si bien deben de manejarse con cuidado y siempre probando el impacto que tienen.
Encontraras todos estos parámetros en la guía de tuning de Windows Server 2008: https://msdn.microsoft.com/en-us/windows/hardware/gg463392
En algunos casos si el sistema operativo de las VM es mas antiguo te conviene ver las guías de tuning de esos sistemas operativos por ejemplo en Windows Server 2003 modificar esta clave de registro: NTFSDisableLastAccessUpdate HKLM\System\CurrentControlSet\Control\FileSystem\ (REG_DWORD) puede suponer una reducción de IOPS aunque tiene otras connotaciones que debes entender.
Conclusiones
Muchas infraestructuras de virtualización funcionan sin haber nunca reparado nadie en aspectos como los que hemos hablado en este articulo pero también es cierto que muchas de ellas mas tarde o temprano empiezan a tener problemas de rendimiento.
Hacer bien las cosas desde el principio y ser conocedores en profundidad de aquellos aspectos en los que estamos involucrados nos hace mejores profesionales y a nuestros clientes o empresas les garantiza que sus plataformas de virtualización serán escalables y predecibles.
Un saludo a todos!
Comments
Anonymous
January 01, 2003
Gracias anonimo, problema solucionado :-)Anonymous
January 01, 2003
Te lo has currado. ¡¡Enhorabuena Daniel!!Anonymous
April 18, 2011
No se ven bien las fotos. Salu2 ;-)Anonymous
October 26, 2015
Excelente amigo tremenda ayuda.