How to burn down estimates in t-shirt sizes
Some people estimate their user stories is t-shirt sizes, i.e. each story is either small, medium or large. But how do you create a burn-down chart for these estimates in order to estimate when you will be done? I guess a very common way is to assign some kind of number to each size. But what number? I know that one person used 1-2-3 (i.e.S=1, M=2, L=3). Let's assume that you are completing tasks in more or less random order, and random size (but more big tasks than small tasks) then the burn-down might look like this after 10 iterations.
 From this burn-down we can see that we will need slightly less than 21 iterations to complete all user stories if the trend is correct. But what if the size difference is wrong? What if a medium is three times as big as a small user story and large is five times the size of a small story?
From this burn-down we can see that we will need slightly less than 21 iterations to complete all user stories if the trend is correct. But what if the size difference is wrong? What if a medium is three times as big as a small user story and large is five times the size of a small story?
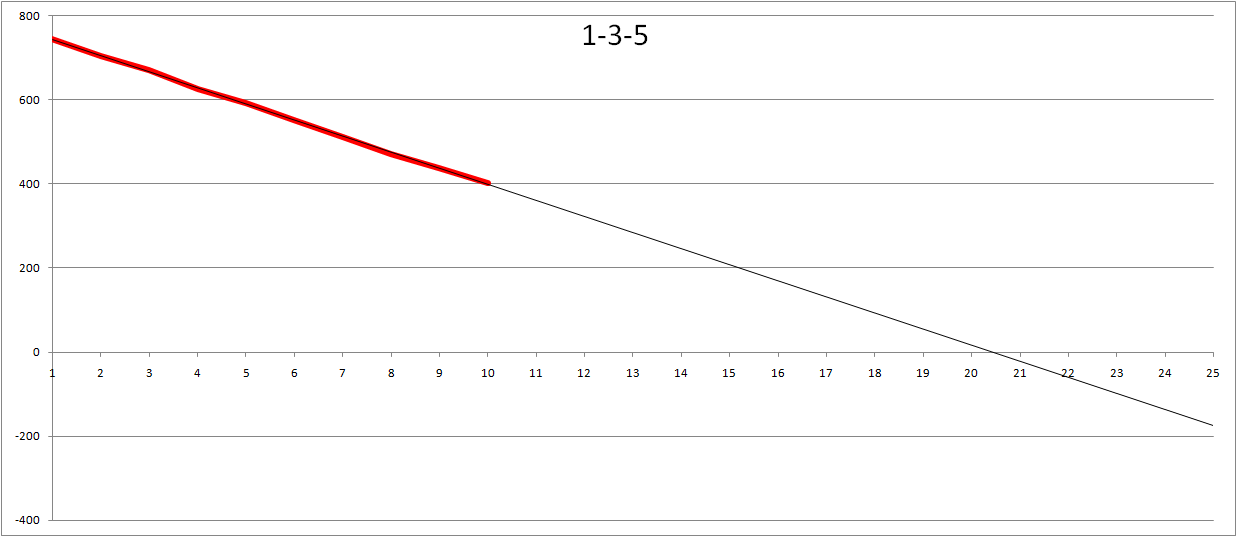
This is the same question another Microsoft developer got when showing some co-workers how burn-downs could be used to estimate project completion. So this person took the actual data he had and changed the values to 1-3-5. Interestingly enough the result was almost the same. I did the same thing on my random data and the estimated number of iterations needed is about the same as you can see here.
{kind=link}
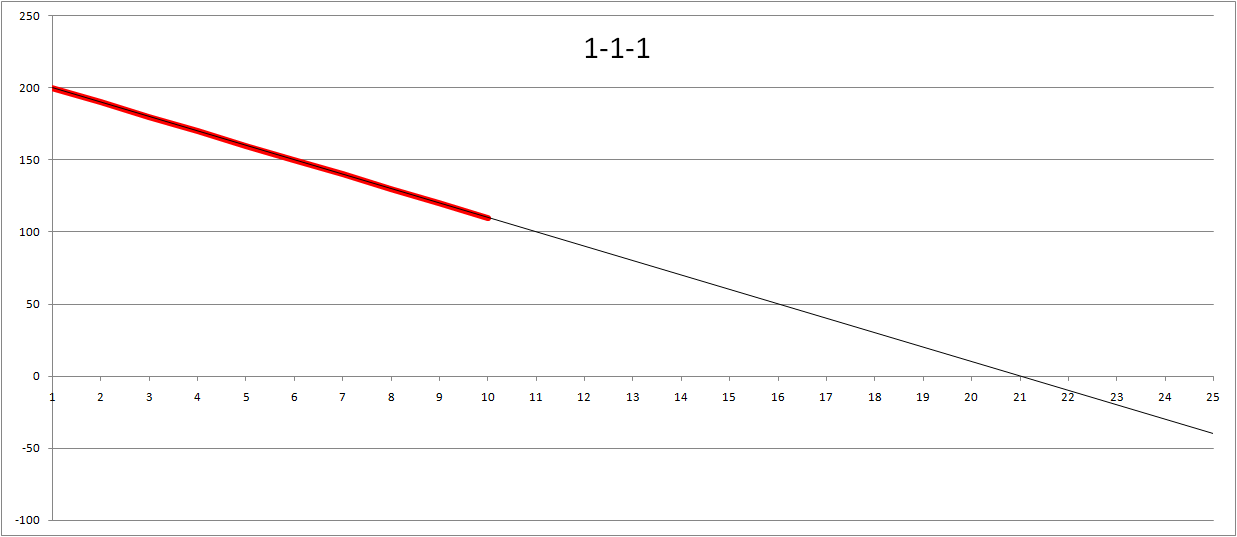
So this made that developer think... Maybe the values representing t-shirt sizes does not matter all that much so he gave all sizes the same value; one. I.e. the burn-down basically represented the number of remaining user stories. Funny enough it turned out that the estimated number of iterations needed to complete them all was again very close the the first estimate. Using my random data you can see that it would take exactly 21 iterations to complete all user stories.
{kind=link}
Back to that developer that inspired me to write this. He finished the project and it turns out that the actual number of iterations needed to complete all stories was also very close to all estimates made when half the stories were completed. If I remember correctly they turned out be all be within 5% of the final number. And being 5% wrong on estimates is way better than most people I know when trying to estimate in hours, days or weeks instead of looking at the velocity of the team.
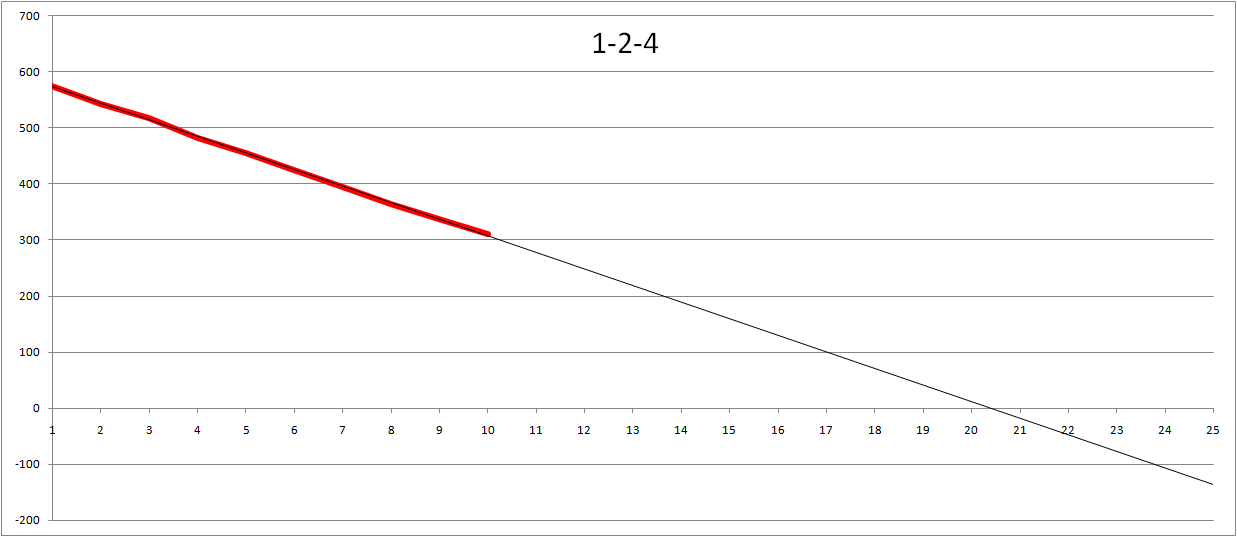
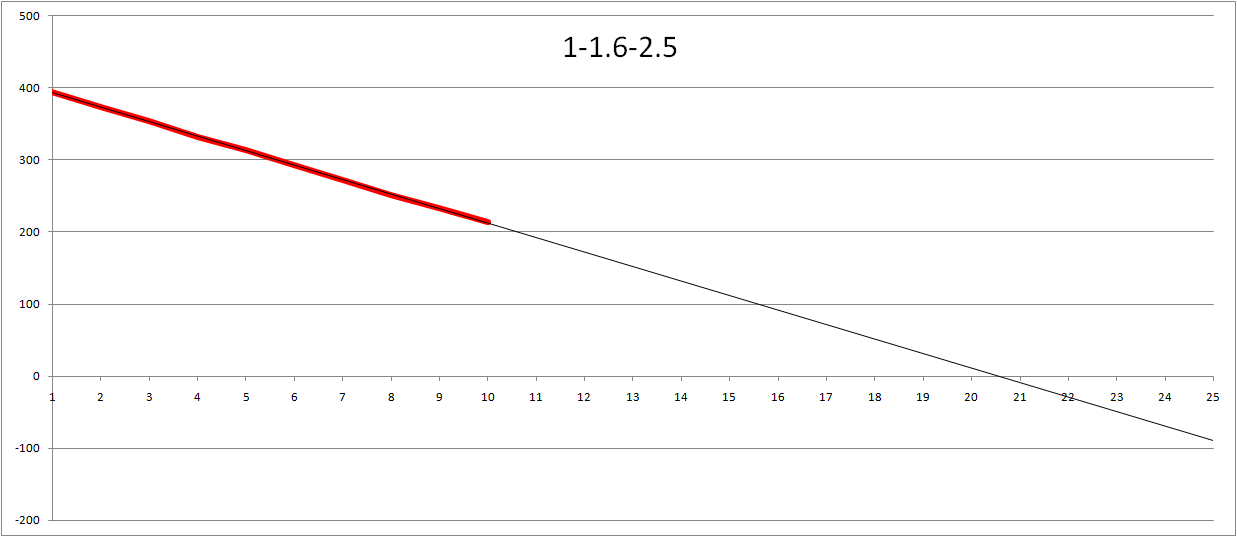
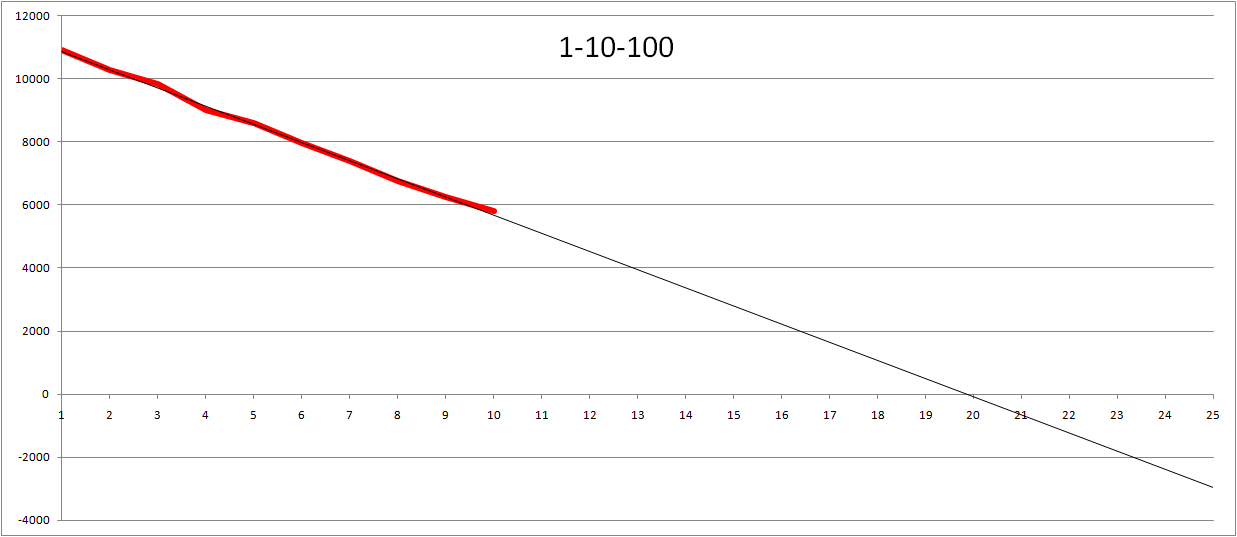
Since I had the data I could not resist making a few more tweaks to the graph. Not surprisingly using 1-2-4 is very similar to 1-2-3. Same for using preferred numbers (my data using start of R5 series (1-1.6-2.5)). Made me think... What about values in totally different ballparks so I used 1-10-100 (i.e. Large being 100 times bigger than a small task). Interestingly enough the estimated number of iterations turned out to be slightly less than 20 in the burn-down. And reversing the values (using 5-3-1, i.e. small is biggest task) gives us an estimate of just over 22 iterations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
So is it safe to draw the conclusion that size of tasks does not really matter in your burn-downs? Is it safe to say that the number of user stories is enough? In my opinion; yes. Yes in theory you may complete only big or small tasks in the beginning saving the other type for last which would make your early estimates wrong if you do not take size in to account. But I don't think teams typically work in this way. There will be a mix of small and big tasks in each iteration. I would compare this to quick-sort. Quick-sort is pretty bad for the worst case scenario but pretty decent on average. I would say the same goes for using burn-downs where you ignore the size of user stories. And the benefit is that you do not have to spend time doing estimates. Just focus on completing those user stories delivering value to your customer because having no sizes is probably good enough.
Comments
Anonymous
October 19, 2009
I guess you guys were lucky when it came to the distribution of variability. What if L sometimes is 2 and sometimes 5 on the 1-2-3 scale? That is IMO the big problem with estimating since software development often is a discovery process - you have to be dealing with pretty predictable stories for your numbers to work. Or be very good at designing the work (splitting stories), but then you have to do plenty of work up front if you want to be able to make predictions for 21 iterations. I am not saying your approach won't work, but I often find the real world to be a little more unoredictable than in your example.Anonymous
October 20, 2009
@Joakim: Well, I don't think that "we were lucky". I totally agree that using L=3 is probably wrong in most cases and that the actual size in most cases is something else. I would personally use "1-1-1" since it statistically is just as good as any other representation for the t-shirt sizes. That is how I interpret the data and I guess you're saying the same thing. Since it is virtually impossible to get the size "right" - don't do it because assuming everything is of the same size is going to be good enough (and is much faster than trying to make an estimate). But there are one reason to make t-shirt sizes I guess, and that is that you probably want to have small and medium things in your sprint so you want to split the large ones as they are getting close to being implemented. I agree that it is unlikely that you will have 21 iteration worth of perfectly broken down stories when you start as my graphs represent. But actually, if you use the brun down bar chart (that grows downwards) you will get the same kind of results when predicting the number of iterations needed. I'll try to make an example and post it here.