Operationalize Databricks Workloads with Azure Data Factory
About the authors:
Faraz Rasheed has been in the Advanced Analytics & AI space for over a dozen years and has led many innovative and bleeding edge initiatives with his customers.
Alp Kaya focuses on the Azure Data Platform and works closely with customers to solution and ultimately onboard them on to Azure.
Please reach out to us if you have any questions about the article. You can reach Faraz & Alp at:
Hope you enjoy the article.
Overview
We are working with several customers who have adopted Azure Databricks as a platform for their Analytics, Data Engineering or Machine Learning requirements. Azure Databricks is a great tool for these use cases and we are seeing accelerated adoption in the field. This article is about operationalizing or productionizing Azure Databricks workloads with Azure Data Factory. The Databricks team has done a superb job of enhancing open source Spark but has left the scheduling & orchestration type activities to a best of breed technology such as Azure Data Factory. So, in this blog, we will look at integrating Azure Data Factory with Azure Databricks and other Azure Data Services to achieve a production deployment.
In this article, we will achieve the following objectives:
- Step by steps instructions on how to operationalize a Databricks notebook (we will use the ML model that predicts survival of Titanic but this operationalization can be applied for other use cases such as Analytics or Data Engineering)
- Scheduling the Databricks notebook to run on a schedule & orchestrate data movement between Azure Storage & Azure SQL database. Specifically in one Databricks notebook that:
- reads data from Azure SQL DB & writes results back to Azure Storage
- and then Azure Data Factory reads results from previous step (i.e. Azure Storage) and then writes results Azure SQL Database
Architecture
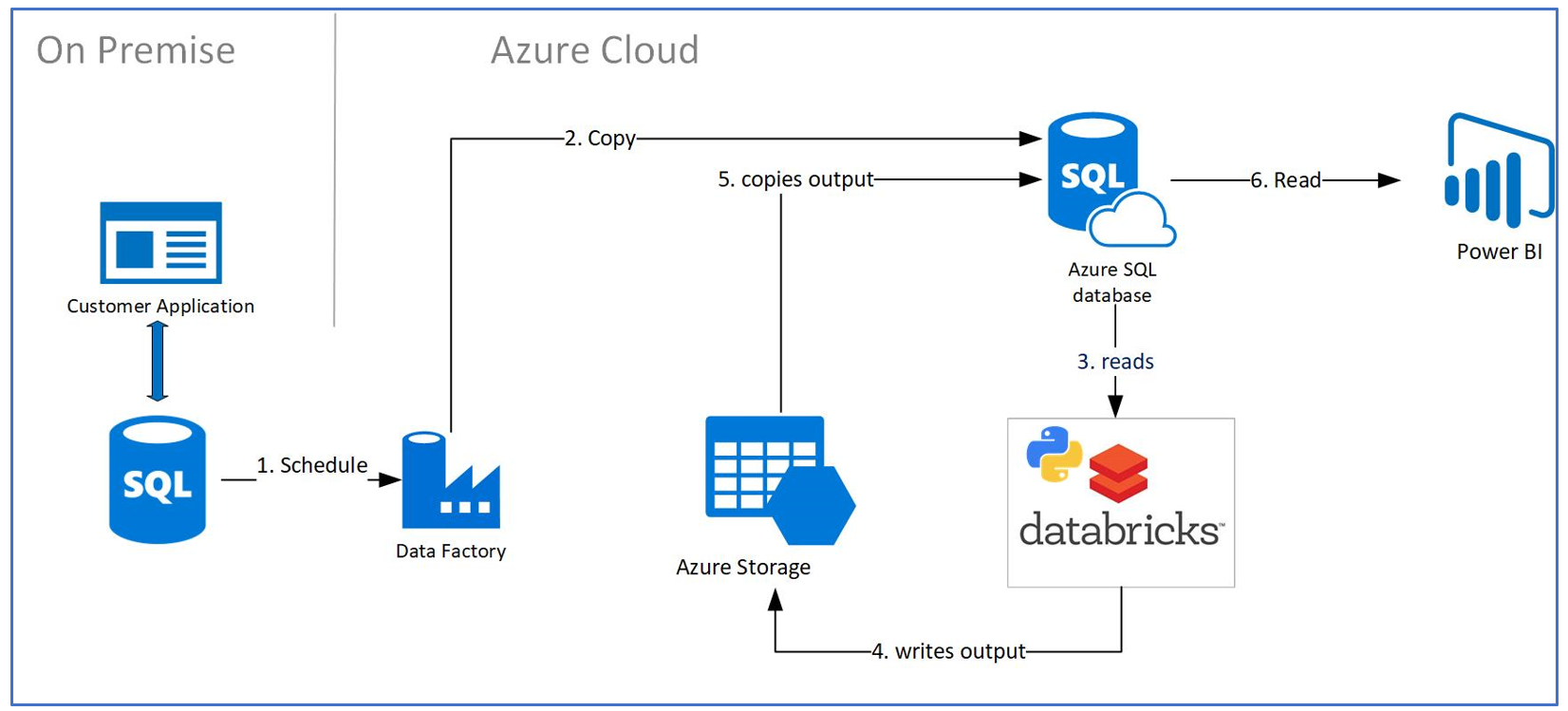
Before getting started, let’s do a quick overview of the customer architecture and scenario along with relevant requirements.
Customer Scenario Overview
Customer has an on premise application where application is constantly making inserts and changes to an on premise SQL Server database. The requirement is to migrate this data into Azure, apply Machine Learning on it with Databricks, and then write the results/outputs to an Azure SQL Database. One of the reasons of moving the data from on premise to Azure is to leverage the Azure Data Services such as Databricks and Azure SQL but also to not interfere with the functioning of the SQL Server OLTP on premise application. The above is a batch process expected to run nightly. At the end of the process, the outputs will be visualized on PowerBI.
Architecture Components Overview
- Azure Databricks: Python development environment for training and scheduled scoring of ML models
- Azure Data Factory: is a browser based tool that is an orchestration platform for building and scheduling Azure Databricks Notebooks (in our particular case - scoring pipeline)
- Azure Storage: File storage services to hold model training data and model predictions before being pushed to Azure SQL DB
- Azure SQL DB: Database platform used to store data for model predictions and to be the serving layer for PowerBI.
- PowerBI will connect to Azure SQL DB in order visualize the ML models and other KPIs
Let’s see how we can in 5 steps productionize the above architecture with Azure Data Factory
Step 1 Create Azure Data Factory and Azure Databricks
From the Azure Portal, create a new Azure Data Factory Resource and Azure Databricks: 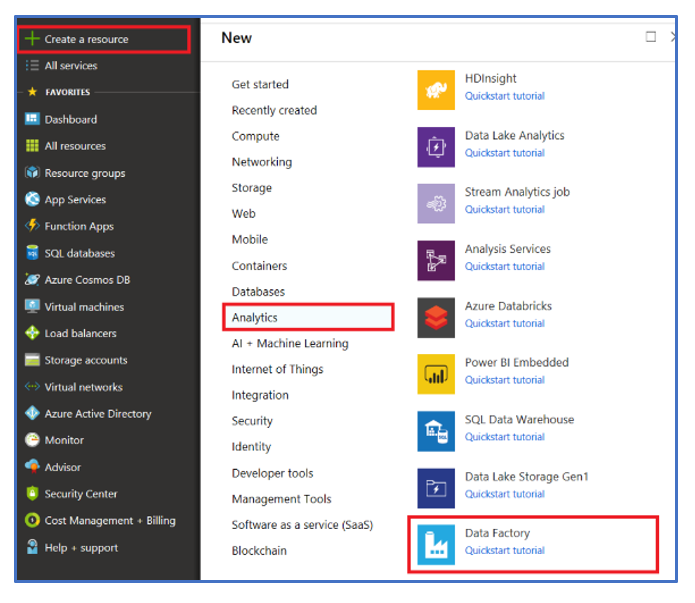
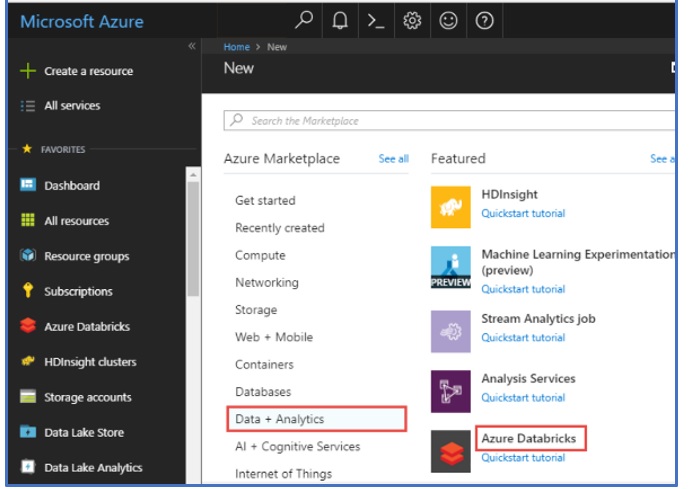
Step 2 Create a Databricks notebook
Our Databricks notebook will be scheduled to run on nightly basis and loads data from Azure SQL DB, creates new predictions by a pre-trained machine learning model and stores the results back to Azure storage account as a csv file. A sample from the Databricks notebook (shown below) demonstrates the Azure SQL connectivity from the Azure Databricks Notebook via a jdbc connection. Please note – the full notebook can be found in the Git repository here. 

Step 3 Create Data Factory Pipeline
Azure Data Factory orchestrates production workflows, schedule and provide workflow management and monitoring services. In our case, we use Azure Data Factory to automate our production job running our scoring Databricks notebook to generate new predictions and loading these to our SQL DB table.
- After setting up Azure Data Factory, create a pipeline and add Azure Databricks Notebook object and a Copy Data object to the pane as shown below
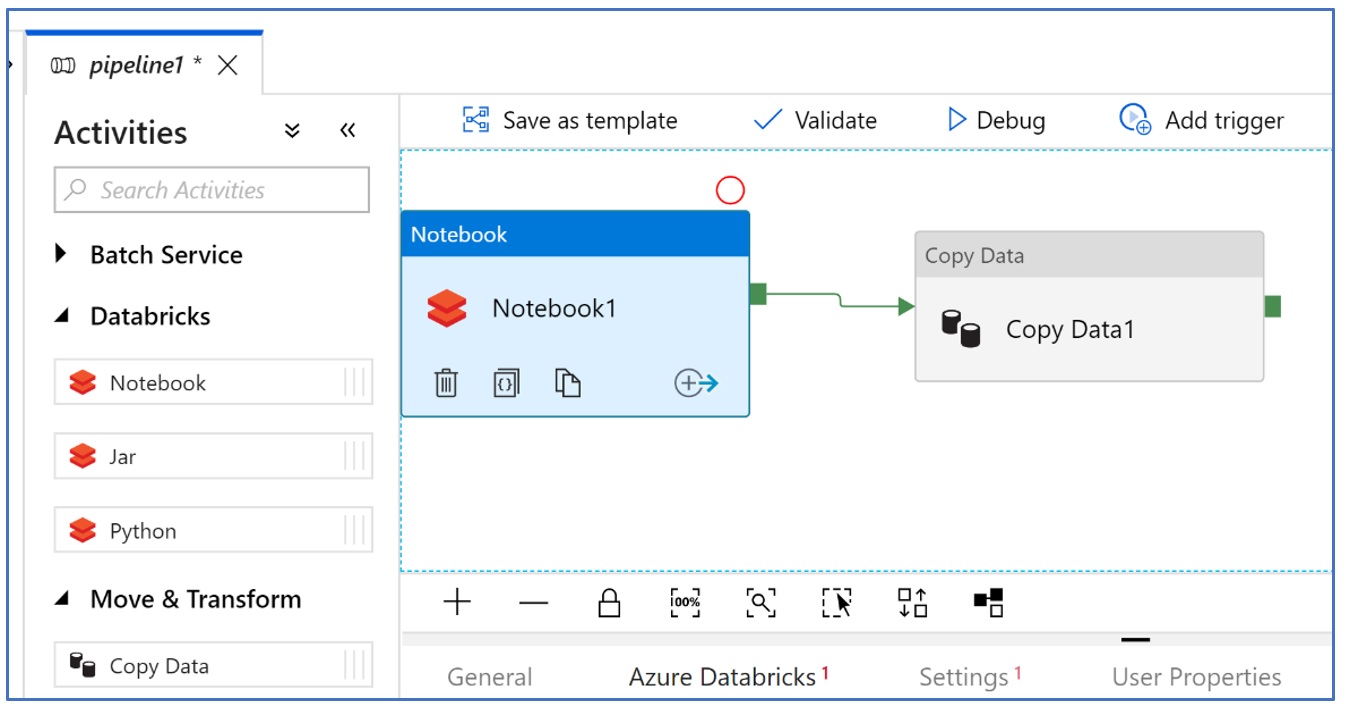
- Configure the Databricks Notebook object to connect with your Azure Databricks workspace and select the target notebook to run on schedule

Step 4 Configure the Copy Data Object
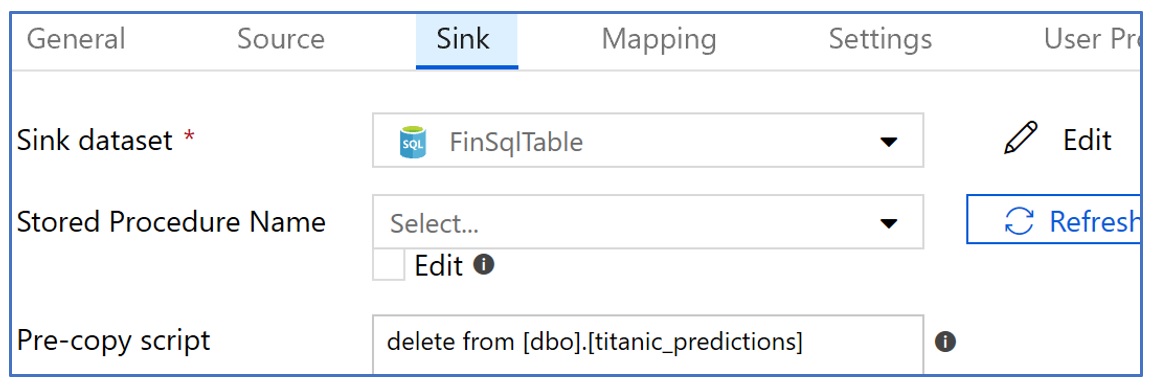
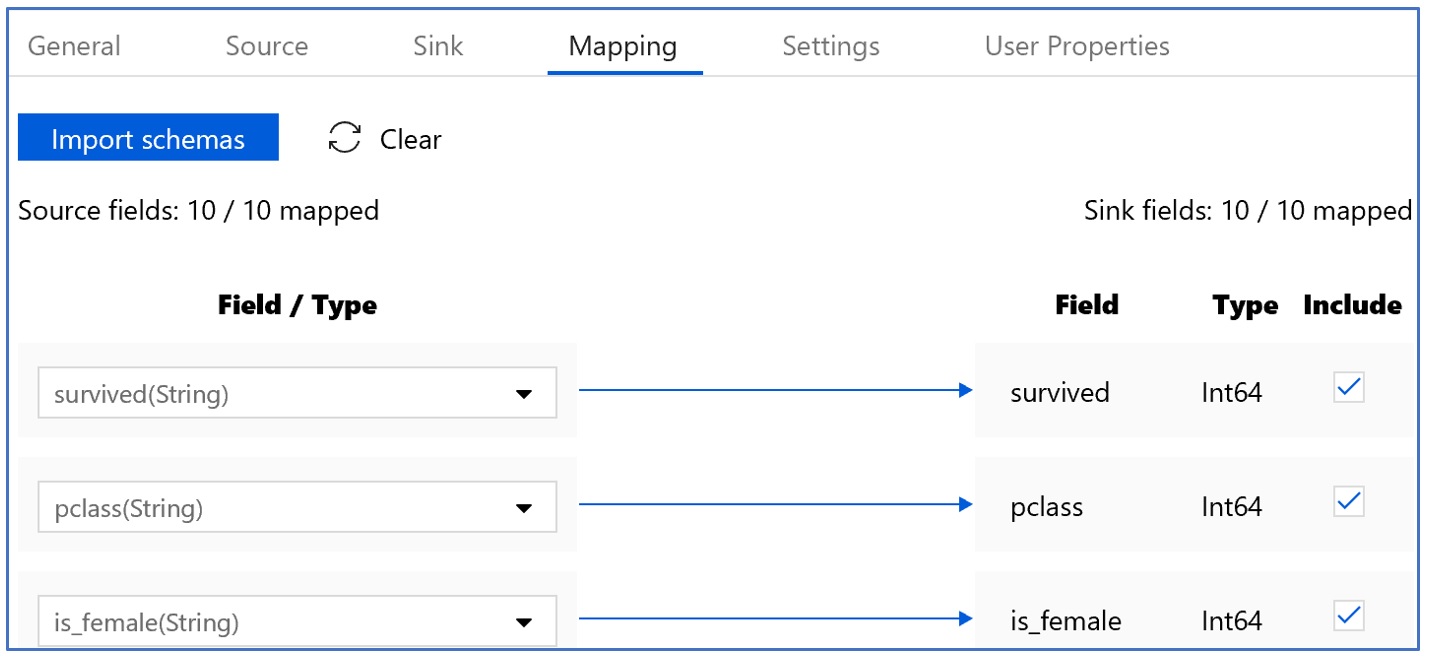
Copy Activity is also very straight forward. We pick our blob storage dataset as source, our SQL DB dataset as sink and define the field/column mapping for the two sources. Please note that we defined a pre-copy script in our SQL DB sink to delete the existing records in our target table. Since we already defined schema is both of our datasets, schema mapping in copy activity is also very straight forward. Such schema mapping becomes very handy when your source and sink datasets do not have matching or same number of columns.
- Configure the Source file with your azure blob storage

- Configure the Sink (or the destination). In this case it will be Azure SQL database
- Configure the Mapping tab in order to map source columns to destination columns as shown below:
Step 5 Publishing and Scheduling the Pipeline & Monitoring
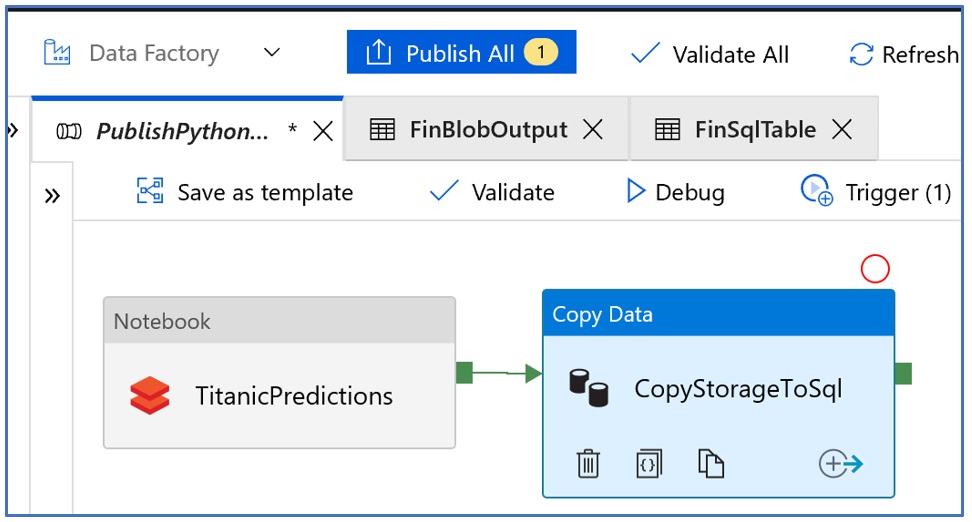
With Azure Data Factory, we don’t ‘save’ our work but rather ‘publish’ our pipeline and validate its completeness with the ‘Validate’ link
- Publish the Pipeline
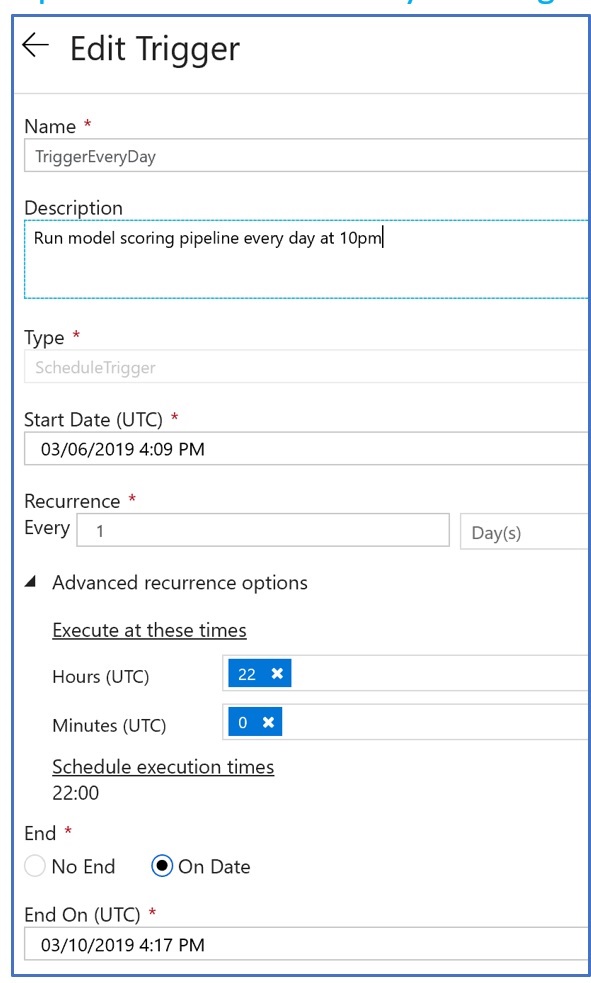
2. Pipelines are scheduled by creating a ‘Trigger’ and setting up scheduling properties
3. Monitor the Pipeline
One of the more powerful features of Azure Data Factory is its monitoring and management capabilities. It lets you monitor pipeline runs, their status (running, succeeded and failed) and to even drill down into the status of individual activities within pipeline.
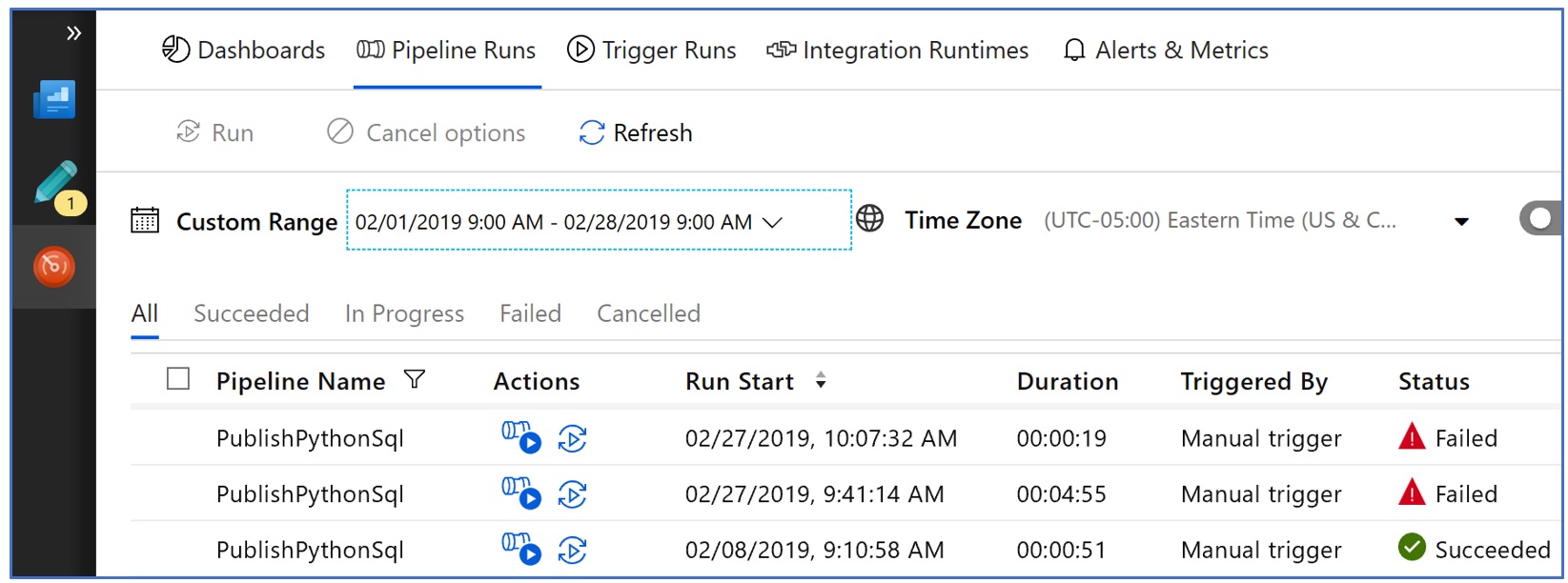
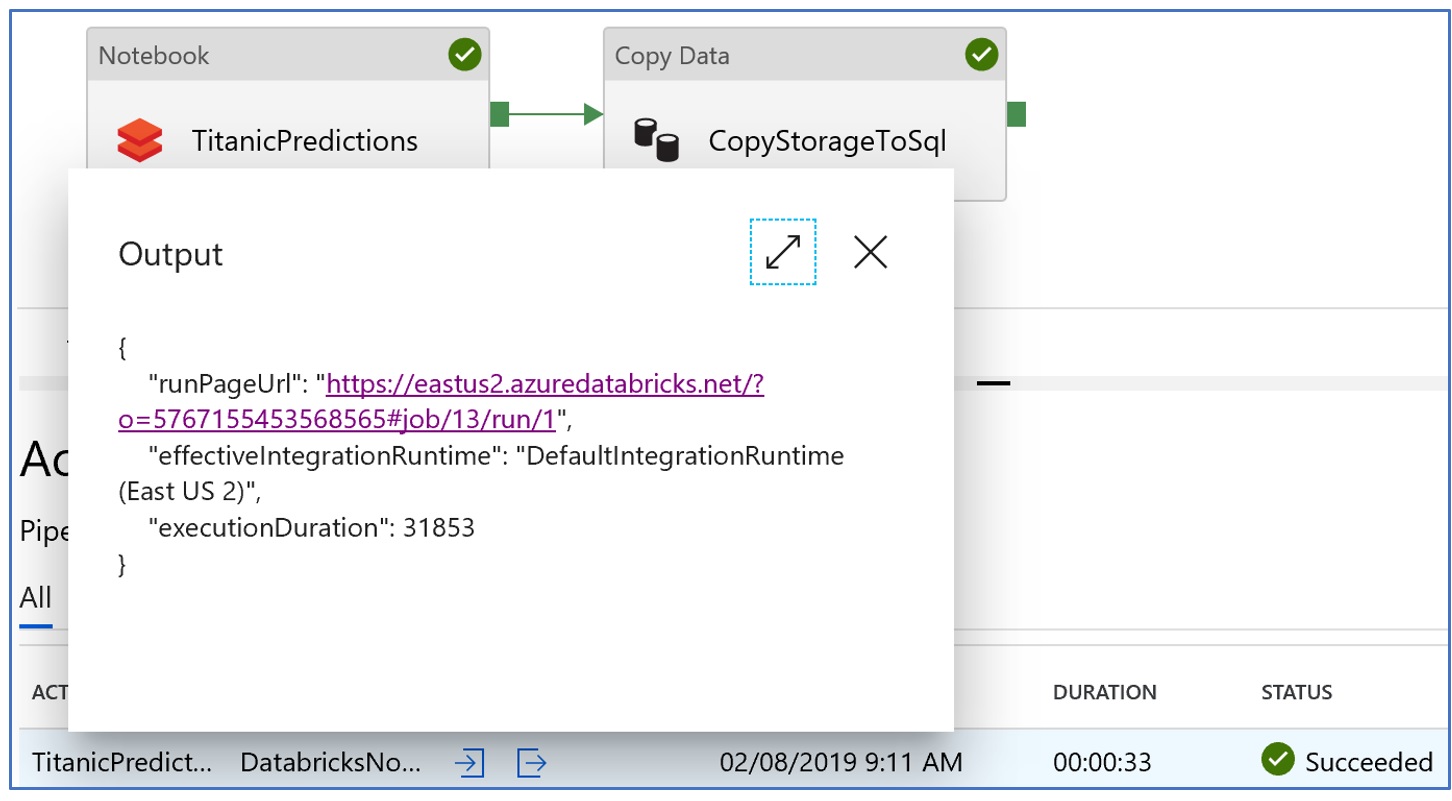
In case of an activity failure, we can drill down and in case of our Databricks notebook activity, we can even open the exact instance of Databricks notebook with cell status and error messages right within the notebook as shown below:
Lessons Learned:
- We write our predictions first to Azure storage as a csv file which is then loaded to the Azure SQL DB database using Azure data factory. This helps ensure that issues like connection failures, incomplete writes and efficient data load is handled by a mature orchestration tool like Data Factory. This decoupling also adds other benefits like writing to multiple destinations and triggering another job not discussed in this blog
- Azure Databricks provides a built-in key-vault service called secret scopes to manage sensitive information like username and passwords without exposing these to code. Checkout our github page for details on how to set these up
- For SQL connectivity, we found JayDeBeApi works well with Databricks. The underlying VM running Databricks code uses UNIX, hence the ODBC connectors do not really work well.
- While Azure machine learning (see full contents here) provides a streamlined way of registering, packaging and deploying models, the architecture used in this blog with Azure data factory as an orchestration tool works very well for batch deployment scenario and is consistent with non-machine learning use cases.