Parallel File Systems for HPC Storage on Azure
UPDATE: We now have a comprehensive eBook with even more information and resources on this topic! Click here to learn about our "Parallel Virtual File Systems on Microsoft Azure" eBook!
Authored by Tony Wu (AzureCAT) and Tycen Hopkins. Edited by RoAnn Corbisier. Reviewed by Larry Brader, Xavier Pillons, Ed Price, Alan Stephenson, Elizabeth Kim, Dave Fellows, Dan Lepow, Neil Mackenzie, Karl Podesta, Mike Kiernan, Steve Roach, Karlheinz Pischke, and Shweta Gupta.
Overview
The high-performance I/O requirements and massive scalability needs of high performance computing (HPC) introduces unique challenges for data storage and access. This document aims to give a high-level overview of how parallel file systems (PFS) can improve the I/O performance of Azure-based HPC solutions, and how to deploy parallel file systems using Azure Resource Manager.
HPC storage on Azure
HPC is used to solve complex problems, such as geological simulations or genome analysis, that are not practical or cost effective to handle with traditional computing techniques. It does this through a combination of parallel processing and massive scalability to perform large and complicated computing tasks quickly, efficiently, and reliably.
In Azure HPC clusters, compute nodes are virtual machines that can be spun up, as needed, to perform whatever jobs the cluster has been assigned. These nodes spread computation tasks across the cluster to achieve the high performance parallel processing needed to solve the complex problems HPC is applied to.
Compute nodes need to perform read/write operations on shared working storage while executing jobs. The way nodes access this storage falls on a continuum between these two scenarios:
· One set of data to many compute nodes
· Many sets of data to many compute nodes
One set of data to many compute nodes
In this scenario, there is a single data source on the network that all the compute nodes access for working data. While structurally simple, any I/O operations are limited by the I/O capacity of the storage location. 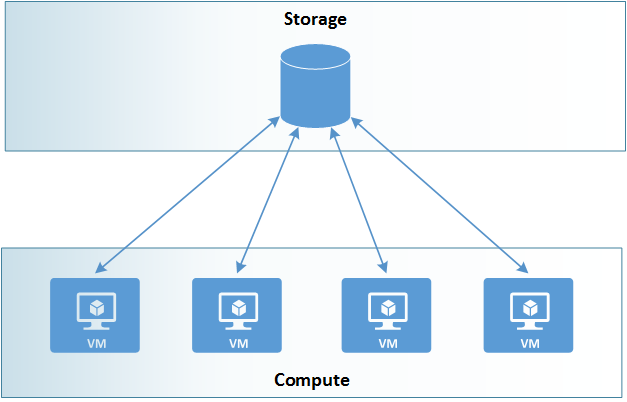
Example of one set of data to many compute nodes scenario
Many sets of data to many compute nodes
In this scenario, there are several different data sources, and compute nodes access whichever is relevant to their particular task. While this approach can improve overall I/O performance, it adds a considerable amount of effort in managing and tracking files, and does not completely eliminate the threat of a single storage location causing I/O bottlenecks if one storage location has a file frequently accessed by multiple compute nodes. 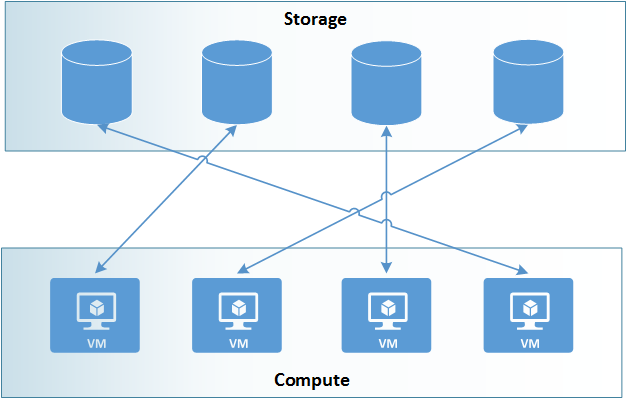
Example of many sets of data to many compute nodes
Limits of NFS
Network file system (NFS) is commonly used to provide access to shared storage locations. With NFS a server VM shares out its local file system, which in the case of Azure is stored on one or more virtual hard disks (VHD) hosted in Azure Storage. Clients can then mount the server's shared files and access the shared location directly.
NFS has the advantage of being easy to setup and maintain, and is supported on both Linux and Windows operating systems. Multiple NFS servers can be used to spread storage across a network, but individual files are only accessible through a single server.
In HPC scenarios, the file server can often serve as a bottleneck, throttling overall performance. Currently the maximum per VM disk capacity is 80,000 IOPS and 2 Gbps of throughput. Attempts to access uncached data from a single NFS server at rates higher than this will result in throttling.
In a scenario where dozens of clients are attempting to work on data stored on a single NFS server, these limits can easily be reached, causing your entire application's performance to suffer. The closer to a pure one-to-many scenario your HPC application uses, the sooner you will run up against these limitations.
Parallel file systems on Azure
Parallel file systems distribute block level storage across multiple networked storage nodes. File data is spread amongst these nodes, meaning file data is spread among multiple storage devices. This pools any individual storage I/O requests across multiple storage nodes that are accessible through a common namespace.
Multiple storage devices and multiple paths to data are utilized to provide a high degree of parallelism, reducing bottlenecks imposed by accessing only a single node at a time. However, parallel I/O can be difficult to coordinate and optimize if working directly at the level of API or POSIX I/O Interface. By introducing intermediate data access and coordination layers, parallel file systems provide application developers a high-level interface between the application layer and the I/O layer. 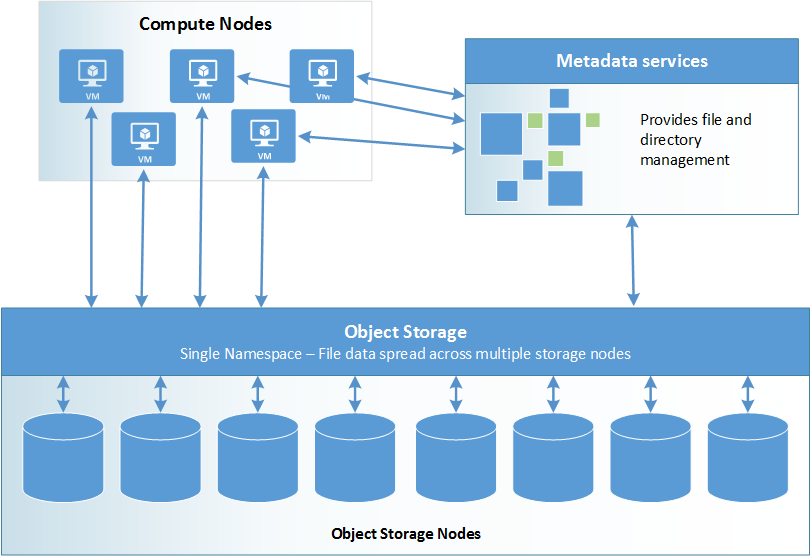
Parallel file system architecture: compute nodes look up file information via metadata services, then perform I/O tasks against object storage
Parallel file systems are broken up into two main pieces:
- Metadata services Metadata services store namespace metadata, such as filenames, directories, access permissions, and file layout. Depending on the particular parallel file system, metadata services are provided either through a separate server cluster or as an integrated part of the overall storage node distribution.
- Object storage Object storage contains actual file data. Clients pull the location of files and directories from the metadata services, then access file storage directly.
The advantages of distributed storage and superior I/O performance makes parallel file systems preferable to NFS in most HPC scenarios, particularly when it comes to shared working storage space.
Azure-supported parallel file systems
There are many different parallel file system implementations to choose from. The following examples are both compatible with Azure, and have example Resource Manager templates that will make deploying them much simpler.
Lustre
Lustre is currently the most widely used parallel file system in HPC solutions. Lustre file systems can scale to tens of thousands of client nodes, tens of petabytes of storage, and over a terabyte per second of I/O throughput. Lustre is popular in industries such as meteorology, simulation, oil and gas, life science, rich media, and finance.
Lustre uses centralized metadata and management servers, and requires at least one VM for each of those, in addition to the VMs assigned as object storage nodes.
Azure Resource Manager templates are available to easily deploy Lustre file systems:
- Azure VM Scale Set as clients of Intel Lustre – This template creates a set of Intel Lustre 2.7 clients using Azure VM Scale Sets and Azure gallery OpenLogic CentOS 6.6 or 7.0 images and mounts an existing Intel Lustre file system.
- Intel Lustre clients using a CentOS gallery image – This template creates multiple Intel Lustre 2.7 client virtual machines using Azure gallery OpenLogic CentOS 6.6 or 7.0 images and mounts an existing Intel Lustre file system.
- Lustre HPC client and server nodes – This template creates Lustre client and server node VMs and related infrastructure such as VNETs.
See also
BeeGFS
BeeGFS is another parallel file system designed for scalable I/O-intensive data storage. BeeGFS is ideal for high data throughput, ease of setup, and manageability.
Unlike Lustre, BeeGFS metadata is managed at a directory level, and that metadata gets distributed among metadata servers providing comparable parallelism to object storage.
An Azure Resource Manager template is available to deploy BeeGFS storage:
- BeeGFS on CentOS 7.2 – This template deploys a BeeGFS cluster with metadata and storage nodes.
See also
GlusterFS
GlusterFS, developed by Red Hat, also provides a scalable parallel file system specially optimized for cloud storage and media streaming. It does not have separate metadata servers, as metadata is integrated into file storage.
GlusterFS also has Azure Resource Manager templates available:
- Drupal 8 VM Scale Set (with GlusterFS and MySQL) – This template deploys an Azure Virtual Machine Scale Set behind a load balancer/NAT with each VM running Drupal (Apache / PHP). All the nodes share the created GlusterFS file storage and MySQL database.
- N-Node GlusterFS on CentOS 6.5 – This template deploys a 2, 4, 6, or 8 node Gluster file system with 2 replicas on CentOS 6.5.
Related article
See also
- GlusterFS documentation
- Installing GlusterFS - a Quick Start Guide
- Setting up Red Hat Gluster storage in Microsoft Azure
Next steps
- Download the Parallel Virtual File Systems eBook
- Batch and HPC solutions in the Azure cloud
- High-Performance Premium Storage and unmanaged and managed Azure VM Disks
- Big Compute in Azure: Technical resources for batch and high-performance computing
Comments
- Anonymous
March 22, 2017
Thank you Ed, Thank you Tony Wu.- Anonymous
March 28, 2017
You're very welcome, Recep! I'm glad this was helpful!
- Anonymous
- Anonymous
March 28, 2017
UPDATE: Fixed a missing link - https://docs.microsoft.com/en-us/azure/storage/storage-premium-storage - Anonymous
March 31, 2017
UPDATE: In the GlusterFS section, I added a link to a new How-To Guide from Rakesh: https://blogs.msdn.microsoft.com/azurecat/2017/03/31/implementing-glusterfs-on-azure-hpc-scalable-parallel-file-system/ - Anonymous
August 14, 2018
UPDATE: We now have a comprehensive eBook with even more information and resources on this topic! Click here to learn about our "Parallel Virtual File Systems on Microsoft Azure" eBook: https://blogs.msdn.microsoft.com/azurecat/2018/06/11/azurecat-ebook-parallel-virtual-file-systems-on-microsoft-azure/