Choosing the right Kubernetes object for deploying workloads in Azure - Part 3
This material has been added to a full eBook, Kubernetes Objects on Microsoft Azure.
Introduction
The last two posts covered how to get a Kubernetes cluster working locally or in Azure. Both clusters can be accessed via their dashboards. It is easy to switch between the two dashboards by switching contexts. This post will cover how to switch context. There will be UI differences in the dashboards, between a single-node cluster and a multi-node cluster, depending on the versions of the clusters. This post will cover all the menu options that are available with Kubernetes version 1.6.6, and I will explain what each option does.
Switching context between a local cluster and an Azure cluster
The last two posts covered using kubectl (the Kubernetes command-line tool) to interact with local (command: cluster-info) as well as a cloud-based cluster (commands: cluster-info & proxy). kubectl uses context to identify a cluster. Think of it as a variant of the good old DB connectionstring to Kubernetes cluster.
Kubectl issues commands against a specific cluster using this context. Use the command in Figure 1 to view which contexts are available to run commands against.
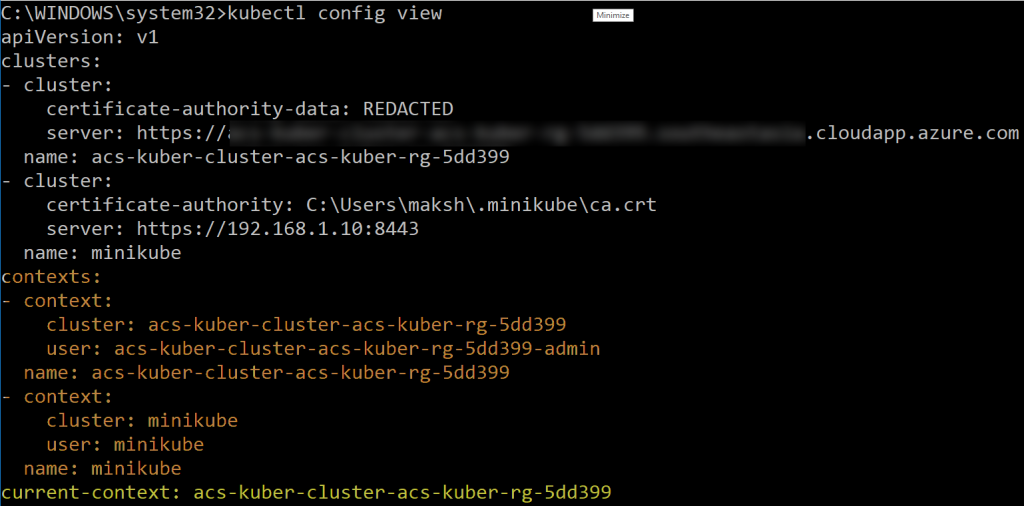
Figure 1. Viewing which contexts are available.
The kubectl config view command lists clusters, configs, and shows the current config.
Use the command kubectl config use-context <name-of-context> to switch between contexts (see Figure 2).

Figure 2. Switching between contexts.
Once you are connected to a specific context, issue further commands against that context/cluster. For example, see Figure 3. 
Figure 3. The cluster-info command.
Dashboard
After switching to the appropriate context, use either the kubectl proxy or minikube dashboard command to navigate to the dashboard. The dashboard has menu options on the left-hand side. These options are categorized across the following five categories:
- Cluster
- Namespace
- Workloads
- Discovery and Load Balancing
- Config and Storage
- Config Maps
- Persistent Volume Claims
- Secrets
Going forward, these categories might change.
Cluster
This category lists the following options:
- Namespaces
- Nodes
- Persistent Volume
- Storage Classes
- Roles (V1.7.0 only)
The sections below cover each option in more detail.
Namespaces
A Namespace is a virtual cluster within a physical cluster. Physical cluster resources can be distributed across multiple namespaces using policies and resource quotas. Each namespace is totally isolated from other namespace. Namespaces are a great solution for running multitenant applications. They can also be used to isolate multiple areas within an application or microservice. Each application or microservice can be deployed and access controlled within namespaces. Each Kubernetes cluster has at least 2 built-in namespaces. These are default and kube-system. It is possible to create custom namespaces as well. However, each time any operation/command is issued on any component inside a custom namespace, it needs to be qualified with a namespace. This can add a little bit of inconvenience when operating a large number of custom namespaces. This situation can be remedied by creating users and credentials that are unique to the namespaces.
Nodes
Nodes are hosts within the Kubernetes cluster. They can be physical or virtual servers. They are the ones that actually keep the Kubernetes cluster up and running. Each node runs multiple components, such as kubelet and kube proxy. Nodes plays an important role in cluster capacity planning, high-availability, security, problem detection and resolution, monitoring, and so on. Nodes are managed by master, which is a collection of components, such as API Server, scheduler, controller manager, and so on. Master itself can run on 1 of the nodes and should be distributed across nodes for redundancy. During capacity planning, use an odd number of nodes (3,5,7...) to be able to form a quorum and to have higher redundancy and reliability. Depending upon which workload that will run on the Kubernetes cluster, it is a good idea to have multiple node types. These node types can potentially be (but not restricted to) CPU, memory, or IOPS intensive. Node types can be labelled so that when it is time to run a containerized workload, you can easily identify and select a suitable node type to run this workload on.
Persistent Volume
While nodes represent the compute capacity of a Kubernetes cluster, persistent volume represents its storage capacity. Kubernetes is a container orchestrator; the reason for orchestration is the very transient nature of containers and cluster nodes. Containers can become unresponsive or simply die. Kubernetes will simply spin up a new container (or pod—coming up shortly). Similarly, a node in a cluster might crash, bringing down along with it any container that may be running on it. A cluster can be a very hostile place to be in with Kubernetes managing many things behind a curtain. What this entails is that any hope for keeping data on a storage of either a container (or pod—again, coming up shortly) or a node is going to subject to the risk of data loss. This is where persistent volumes play an important role. There are non-persistent volumes, such as emptyDir (for intra-pod) or HostPath (for intra-node) communication. Persistent volumes are resources that need to be provisioned separately from the Kubernetes cluster. Kubernetes will use them but not manage them. They need to be managed by the cluster administrator. In Azure, you can use Azure Disk or Azure File Storage as persistent volume with a Kubernetes cluster.
Storage Classes
Storage Classes provide the flexibility to have multiple persistent and other volume options to choose from for a Kubernetes cluster. It makes it possible to use multiple storage solutions from various vendors, including Azure, AWS, GCP, and so on. Containers request storage from a cluster via a volume claim, which is a declarative claim for a specific type of volume access mode, capacity, and so on. The Kubernetes cluster evaluates this claim request and then assigns a volume from its storage class.
Roles
This a is new feature from Kubernetes v1.6.0. Prior to v1.6.0, Kubernetes used ABAC (attribute-based access control). Roles enable role-based access (RBAC) to cluster resources. Roles can be used to access permission to either namespace scope resources or cluster scope resources (including multiple namespaces). They provide address authorization concerns accessing API Server, which provides core services to manage Kubernetes services that use RESTful API endpoints. Roles and users are associated using RoleBinding.
Workloads
Workloads includes the following options:
- Daemon Sets
- Deployments
- Jobs
- Pods
- Replica Sets
- Replication Controllers
- Stateful Sets
Next I will take a closer look at each below.
Daemon sets
Have you ever heard of gods killing daemons, only to find them appear again? DaemonSets are exactly that; they never die! DaemonSets play a versatile role in a Kubernetes cluster. A DaemonSet is a pod that runs on every node. In case that pod crashes, Kubernetes will try to bring that pod automatically. Similarly, any new node that gets added to cluster, automatically gets this pod. This functionality is very useful in scenarios where every node needs to be monitored for a potential problem, which is what the node-problem-detector component does. It is deployed as a DaemonSet. DaemonSets also allow you to scale a container using the nodeSelector node in their template. This node instructs Kubernetes to run a container on a qualifying node. So when any new node gets added in the cluster and qualifies for the nodeSelector criteria (typically via labelling), it automatically runs a container specified in the DaemonSet template. Another use-case is to label a set of nodes with a particular hardware configuration that is dedicated with persistent storage to run stateful workloads as a DaemonSet on those labelled nodes. It's also possible to use the .spec.updateStrategy.type node in the DaemonSet template for rolling updates.
Deployments
Deployments are a Kubernetes resource that ensure the reliable rollout of an application. While it is possible to create an individual pod without using Deployment, that process isn't sustainable. Pods created without using Deployment lack the mechanism to recreate themselves without any manual intervention. This is where a Deployment helps. In case a pod crashes, Deployment ensures that another one is automatically created. This is possible because Deployments create ReplicaSets, which in turn keeps pods alive. Deployments use a declarative syntax that is used to define replicas, which instruct Kubernetes to ensure the many instances of a pod are always running. They are also a useful feature to trigger a version upgrade.
Jobs
Jobs are ideal for tasks that run and achieve a goal, and then stop. They are a Kubernetes resource that creates one or more pods and ensures that they run until they succeed. They can be customized with restart policies, completions, and parallelism. Jobs internally ensure that only the optimum number of pods are created to execute parallel operations. By design, when a job completes its execution, it and its pods are kept for telemetry purposes. If any of the logging information is not needed, a job and its related pod should be manually deleted. Cron jobs are a special type of jobs that run on schedule either as a single instance or repeatedly on a schedule.
Pods
A pod is a basic building block. It encapsulates a single container or multiple containers. Along with container(s), it also includes storage, an IP address, and a configuration option to manage each container. Storage inside a pod is shared between containers and is mounted as a volume on all the containers inside it. All the containers inside a pod can communicate by using either localhost or inter-process communication. Pods can be created as a Kubernetes resource. However, they lack self-healing capabilities. Pods are usually created using controllers (DaemonSets, Deployment, StatefulSets). Pods simplify deployment, scaling, and replication.
Replica Sets
Replica sets are used to manage a group of pods. They ensure that a specific number of pods are always running. So, if a pod crashes, a replica set will bring that up again automatically. While that functionality is very useful, there are not may use-case scenarios. Pods are often version updated, and in those cases, the expectation is to update the pod and ensure that a specific number of pods is kept running at all times. So, you are recommended to use replica sets along with higher-level controllers, such as Deployment. Just like Deployment, they can also be used along with horizontal pod autoscalers (HPA). ReplicaSets enable set-based label selectors. This type of selection facilitates grouping a set of pods together and making that entire set available for an operation defined in ReplicaSet.
Replication Controllers
ReplicationControllers are the predecessors to ReplicaSets. Unlike ReplicaSets, they operate on name equality. The official recommendation going forward is to use ReplicaSets.
Stateful Sets
While ReplicaSet or ReplicationControllers help ensure that a specific number of pods are always running, they simply spin up a new pod instance when a pod crashes. Along with that crash, any data that is written to the pod volume disappears as well. A new pod gets its own new volume. In some workloads, this is a prohibitive behavior. Examples of such workloads are distributed databases, stateful applications. StatefulSets are solutions to problems associated with data loss in case of pod crash. Unlike regular pods, StatefulSets use persistent storage volume. They can be configured to mount this persistent storage volume. So even if a pod crashes, data is preserved on persistent data storage. StatefulSets also have a unique and stable hostname that is queryable via DNS. They ensure that pods are named (such as pod-1, pod-2, and so on) and a new pod instance (such as pod-2) is not created until pod-1 is created and is healthy.
Discovery and Load Balancing
It lists the following options:
- Ingresses
- Services
Ingresses
Ingress is a layer 7 HTTP load balancer. These are Kubernetes resources that exposes a service to the outside world. It provides externally visible URLs to service, load balance traffic with SSL termination. This is useful in scenarios where rolling out such services is not possible or is expensive. They can also be used to define network routes between namespaces and pods, in conjunction with network policies. They are managed via Ingress controllers. It is possible to use them for limiting requests, URL redirects, and access control.
Services
Service is a layer 3 TCP load balancer. They are a way to expose an application functionality to users or other services. They encompass one or more pods. Services can be internal or external. Internal services are accessed only by other services or jobs in a cluster. An external service is marked by the presence of either NodePort or load balancer.
Config and Storage
This last section contains the following options:
- Config Maps
- Persistent Volume Claims
- Secrets
Config Maps
ConfigMap helps keep image configuration options separate from containers/pods. It lists configuration options as a key-value pair. This configuration information is exposed as an environment variable. While creating pods, a pod template can read the values for ConfigMap and can provision a pod. Likewise, it can be used to provision volume as well.
Persistent Volume Claims
Persistent volume claims are storage specifications. Containers claim their storage needs expressed by persistent storage claims. They typically specify the following:
- Capacity – Expressed in Gibibytes (GiB).
- Access mode – Determines a container's rights on volume when mounted. It can take one of the options between ReadOnlyMany, ReadWriteOnce, and ReadWriteMany.
- Reclaim policy – Determines what happens with storage when a claim is deleted.
Secrets
While ConfigMap provides an easy configuration separation, it stores a key-value pair as plain-text, which is not a very ideal solution in cases of sensitive information (such as passwords, keys, and so on). This is where a Secret comes in handy. Secrets are scoped at namespaces. So their access is restricted to users for that namespace. Secrets can be mounted as a volume in pod to be able to consume information. Note that they are stored in etcd (data store used by Kubernetes to store its state) as plain-text. Ensure that access to etcd is restricted.
My next post will cover setting up a SQL Server and ASP.Net Core web application using concepts discussed in this post.
Comments
- Anonymous
October 31, 2017
Continue on to Part 4 of this series: https://blogs.msdn.microsoft.com/azurecat/2017/10/24/choosing-the-right-kubernetes-object-for-deploying-workloads-in-azure-part-4/Return to Part 2 of this series: https://blogs.msdn.microsoft.com/azurecat/2017/10/24/choosing-the-right-kubernetes-object-for-deploying-workloads-in-azure-part-2/Return to the Overview article for this series: https://blogs.msdn.microsoft.com/azurecat/2017/10/24/choosing-the-right-kubernetes-object-for-deploying-workloads-in-azure/ - Anonymous
January 22, 2018
This material has been added to a full eBook, Kubernetes Objects on Microsoft Azure: https://azure.microsoft.com/en-us/resources/kubernetes-objects-on-microsoft-azure/en-us/