Azure Data Architecture Guide – Blog #9: Extract, transform, load (ETL)
This is our ninth and final blog entry exploring the Azure Data Architecture Guide. The previous entries for this blog series are:
- Azure Data Architecture Guide – Blog #1: Introduction
- Azure Data Architecture Guide – Blog #2: On-demand big data analytics
- Azure Data Architecture Guide – Blog #3: Advanced analytics and deep learning
- Azure Data Architecture Guide – Blog #4: Hybrid data architecture
- Azure Data Architecture Guide – Blog #5: Clickstream analysis
- Azure Data Architecture Guide – Blog #6: Business intelligence
- Azure Data Architecture Guide – Blog #7: Intelligent applications
- Azure Data Architecture Guide – Blog #8: Data warehousing
Like all the previous posts in this series, we'll work from a technology implementation seen directly in our customer engagements. The example can help lead you to the ADAG content to make the right technology choices for your business.
Extract, transform, load (ETL)
In this example, the web application logs and custom telemetry are captured with Application Insights, sent to Azure Storage blobs, and then the ETL pipeline is created, scheduled, and managed using Azure Data Factory. The SSIS packages are deployed to Azure--with the Azure-SSIS integration runtime (IR) in Azure Data Factory--to apply data transformation as a step in the ETL pipeline, before loading the transformed data into Azure SQL Database.
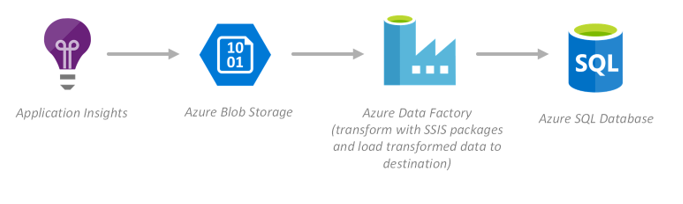
Highlighted services
- Application Insights
- Azure Storage blobs
- Azure Data Factory
- Azure-SSIS integration runtime
- Azure SQL Database
Related ADAG articles
- Traditional RDBMS workloads
- Technology choices
Please peruse ADAG to find a clear path for you to architect your data solution on Azure:
![]()
Azure CAT Guidance
"Hands-on solutions, with our heads in the Cloud!"