Azure Data Architecture Guide – Blog #4: Hybrid data architecture
In this fourth blog entry, we'll continue to explore the Azure Data Architecture Guide. The entries for this blog series are:
- Azure Data Architecture Guide – Blog #1: Introduction
- Azure Data Architecture Guide – Blog #2: On-demand big data analytics
- Azure Data Architecture Guide – Blog #3: Advanced analytics and deep learning
- Azure Data Architecture Guide – Blog #4: Hybrid data architecture - This one
- Azure Data Architecture Guide – Blog #5: Clickstream analysis
- Azure Data Architecture Guide – Blog #6: Business intelligence
Like the previous post, we'll work from a technology implementation seen directly in our customer engagements. The example can help lead you to the ADAG content to make the right technology choices for your business.
Hybrid data architecture
When you need hybrid on-premises and cloud options, nothing comes close to Azure. Use Azure Stack to deliver Azure services from your own datacenter, using the same tools in both environments for unmatched consistency, allowing you to deploy your data solution to the location that best meets your needs. Use ExpressRoute for a private, dedicated and high speed connection that extends your on-premises network into Azure. See this example hybrid reference architecture.
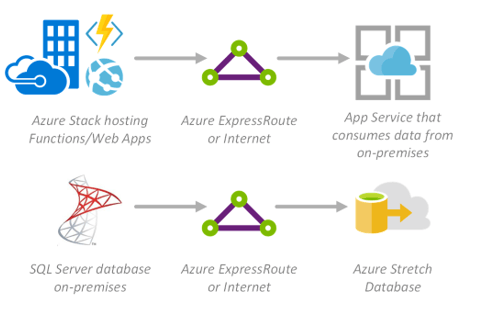
Highlighted services
Related ADAG articles
- Traditional RDBMS workloads
- Cross-cutting concerns
- Technology choices
Please peruse ADAG to find a clear path for you to architect your data solution on Azure:
![]()
Azure CAT Guidance
"Hands-on solutions, with our heads in the Cloud!"
Comments
- Anonymous
November 30, 2018
Since i saw the same mistake at blog 6, here as well, all the links under: Highlighted services are not working.- Anonymous
December 06, 2018
Thanks again, Ralf!
- Anonymous