Fat clients: Are they useful ?
In Cassandra's distributed architecture, every node acts as a coordinator for client queries. The client-side driver picks coordinator nodes based on the chosen load balancing policy and thus, distributed queries to all nodes. There is some discussion in the community on benefits of white-listing a subset of nodes as coordinators (aka "fat clients"). This design ensures that the non-coordinator nodes don't spend system resources (CPU to be precise) in doing the coordination functions (figuring out which replicas to select, distributing the queries to them, waiting for responses from them and answering back to clients) leading to better performance overall. There is an interesting talk from Cassandra Summit 2016 on this topic.
We decided to try this out and see how it helps things overall. Our heavy writes happen through Spark, and we use the Scala driver. Testing this setup required us to do the following:
Cassandra:
This is rather straightforward. You can add a setting "JOIN_RING=FALSE" in cassandra-env.sh on a node that isn't joined the ring, yet. If you run 2.1.13, you also need to disable auth in cassandra.yaml since there is a known issue. Once the node joins the cluster, you can verify that its acting purely as coordinator through "nodetool gossipinfo" as below:
/10.183.1.25
generation:1494524175
heartbeat:38808
LOAD:38658:221423.0
SCHEMA:14:744cfd95-9066-3f2f-a5e4-6f7c75426db6
DC:72:BatchAnalytics
RACK:12:RACBat2
RELEASE_VERSION:4:2.1.13.1131
INTERNAL_IP:6:10.183.1.25
RPC_ADDRESS:3:10.183.1.25
X_11_PADDING:38717:{"workload":"Cassandra","active":"true","health":0.935385733708455}
SEVERITY:38807:0.0
NET_VERSION:1:8
HOST_ID:2:8bb16daa-9e6f-4423-a151-ec80e43033d8
TOKENS: not present
The logs also print a friendly message that the node hasn't joined the ring yet. If you run "nodetool status" on regular nodes, the coordinator nodes don't show up.
Spark
We found out that in Scala + Java world, we must change both Scala and Java drivers for white listing to work properly. This is because coordinator nodes don't exist in system.peers and all drivers remove nodes that don't exist in system.peers, by design. The change is straightforward in both drivers, and we will share our changes soon.
Benchmarking
We ran a Spark job that does 20K writes / sec to our cluster. In regular mode, we need 40 nodes to handle this level of load for our latency requirements. Since we run real-time analytics workloads, we typically see 100K events processed in 20 seconds end-to-end. We were interested in seeing if we can reduce the number of nodes with this mode, and still meet our latency requirements. With prior experiments, we knew that a 20 node cluster does not meet our write latency requirements and puts high load / CPU on all nodes (it takes 30+ seconds for same number of input events).
Therefore, we created a 20 node cluster and ran the same load once with all 20 nodes in regular mode, and another time with 5 of them as coordinators. We found out the following.
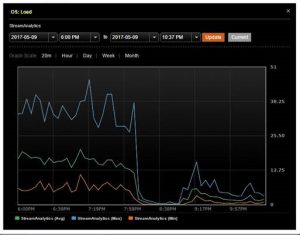
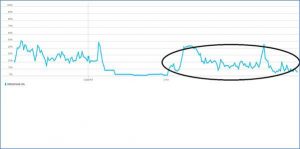
There is significant reduction in OS load on regular nodes (16 to 2, specifically). The coordinator nodes show higher load average (8), yet its better than when run in regular mode. The CPU also reduces by 10%. However, the write latency as perceived by the Spark job (or seen via Cassandra metrics) does not change.
Conclusion
This mode doesn't help us with latency improvement, so it doesn't help our specific app. We decided to not invest in this mode further. It appears that if your App can live with some degraded latency this mode lets you throw more traffic on same number of nodes, thus helping dollar costs.