Design For Operations [DFO] – Problems And Solution Frame
patterns & practices team maintains Design for Operations [DFO] project on codeplex. The goal of the project focuses on:
“Developing tools and guidance to help enable the development of highly manageable applications on the Windows platform.”
This post summarize my understanding of the project’s problems and solutions frame. Most of the content is direct copy paste from more than 300 pages Manageability Guidance document found here and few interpretations of mine.
Problems Frame
Active players and their concerns
- End User.
- Why it is not working?
- Why it works so slow?
- Why I am not allowed to do this operation?
- Operator.
- How do I configure this?
- Why it failed without alerts?
- Where all alerts are sent?
- How do I roll back the version?
- What should I do when I se this alert?
- Developer.
- How come end users do not understand exception message? – it is simple call stuck dump!
- What do I do with this “Unspecified error” thing?
- What component throws this exception?
- Here is the patch – just drop it to fix the problem.
Operations Challenges
- How do I know what is the source of the incident? For example, “It is IIS authentication”.
- How do I get detailed information regarding the incident? For example, “SPN is not configured for IIS Application account”.
- How do I recognizes the trends that usually lead to incident? “Yesterday we had 10% CPU utilization and today it is 20% - it must mean something”.
Solution Frame
Representing Applications as Managed Entities
A managed entity is any logical part of an application that a system administrator needs to configure, monitor, and create reports about while managing that application or service. Examples of managed entities are a Web service, a database, an Exchange routing group, an Active Directory site, a computer, a server role, a network device, a hardware component, or a subnet.
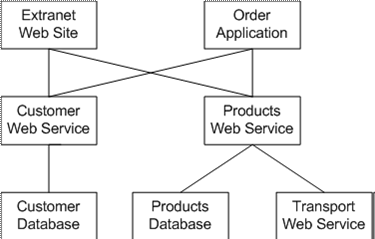
Model Comprehensive Management Models
Creating a comprehensive management model consists of modeling in a variety of different areas to provide a total system view, including the following:
- Configuration modeling. This involves encapsulating all the settings that control the behavior or functionality of an application or system component.
- Task modeling. This involves cataloging the complete list of tasks that administrators have to perform to administer and manage a software system or application.
- Instrumentation modeling. This involves capturing the instrumentation used to record the operations of a system or application. Instrumentation provides information to the operations team to increase understanding about how the application functions, and to diagnose problems with an application.
- Health modeling. This involves defining what it means for a system or application to be healthy (operating normally) or unhealthy (operating in a degraded condition or not working at all). A health model represents logically the parts of an application or service the operations team is responsible for keeping operational.
- Performance modeling. This involves capturing the expected baseline performance of an application. Performance counters can then be used to report and expose performance on an ongoing basis, and a monitoring tool can compare this performance to the expected performance.
Building Effective Health Models
An application is considered healthy if it is operating within a series of defined parameters. A number of factors may result in a change in application health, including the following:
- Change in application configuration
- An application update
- A change in an external dependency
- A hardware change
- A network change
- Bad input to the application
- Scalability problems
- Operator error
- Change in deployment
- Malicious attack
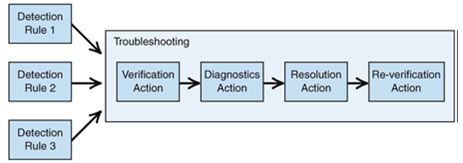
Steps to handle the problem
- Detect a problem.
- Verify that the problem still exists.
- Diagnose the cause(s) of the problem.
- Resolve the problem.
- Verify that the problem was resolved.
- [My addition] Log the incident and convert it into Knowledge Base gem.
Conclusion
There are few key terms mentioned above - "Modeling", "Design", "Building", "Maintain", "Testing". To me it is absolutely clear that Design For Operations is no different from Security Development Lifecycle or Performance Development Lifecycle. "Operations" is just another important non-functional requirement that needs to be taken throughout the whole development lifecycle to be successfully implemented and deployed in production. It had to be called Operations Development Lifecycle.
My related posts
- Use Sysinternals DebugView To Diagnose The Application
- ASP.NET Health Monitoring Means Logging And Auditing
- Security Engineering Big Rocks
- Threat Modeling Big Chunks
- T-Shooting Kerberos
- Who Access My File?
- Chain Of Responsibility Design Pattern – Focus On Security, Performance, And Operations
- Identify ASP.NET, Web Services, And WCF Performance Issues By Examining IIS Logs
- Use Performance Counters Templates To Streamline Performance Analysis
Comments
- Anonymous
February 14, 2008
Alik Levin is here. Does the question sound rhetoric to you? Do you think the answer is “Yes” - Anonymous
February 10, 2009
Does the data professional need to know about Patterns and Practices? Well, if you're on the development