Scaling Out vs Scaling Up
Go Forth and Multiply
One of the often-cited design principles in Exchange 2013 deployments is the notion that architects should “scale out, not scale up”. So what does this mean, and why are we pushing this? First, lets look at what we mean when we use these terms.
Scaling Up
“Scaling Up” is where we add more resources to a server. Let’s say our fictional company, Tailspin Toys, is half way through the design of their shiny new Exchange 2013 environment. They have 5,000 mailboxes and the calculator (you are using the calculator, aren’t you?) tells us we can house 1250 mailboxes per server, giving us 4 servers in our DAG. In this example, each server has 96GB RAM and 10 cores. Tailspin then acquires Contoso, and we get a requirement that we need to migrate in another 5,000 users (for the sake of this example, we will assume that Contoso have the exact same Message Profile as Tailspin, so our numbers are the same). In the past, we would have to add more resources to the server to take on the extra pressure this load would add: more RAM, more disk and more cores. Logic would dictate that this is a perfectly reasonable course of action to take, and, to some extent, it is. However, as we shall see further on, this is certainly far from the best course of action with Exchange 2013.
Scaling Out
“Scaling Out” is where we add more servers. So, with our example above, rather than increasing the cores to, say, 16 and the RAM to 146GB, we simply add more servers of the same spec. The math’s is nice and easy here; we add another 4 nodes to our DAG to make it an 8 node DAG.
The Cons
We hear a few common criticisms against this principle. Now, it’s clear that this will cost you more in licenses. There will be 4 more Exchange 2013 Enterprise licenses needed and 4 more Windows Server licenses (assuming you are on physical servers and not virtual boxes on Windows Server 2012 R2 Datacenter Edition).
However, the second point is one we hear a lot and it’s a common misconception about larger DAG sizes. To take advantage of the benefits of a larger DAG, it does not mean more copies of your database. Our Preferred Architecture is for you to have four copies of your database. Two in each datacenter and one set as a lagged copy. It seems the thinking goes that if I have four servers with four copies, then having eight means I need eight copies for them all to be highly available. This is completely wrong, and even with a DAG at it’s maximum capacity of sixteen nodes, we still have four copies of the database. The most important thing about making them highly-available (in addition to the other benefits of a larger DAG) is the way the database copies are spread out across the nodes. Let me repeat that, it is database-copy placement that counts.
The final common complaint against this is also about money. It will cost you another X dollars to buy more servers when it would only cost Y dollars to add more resources. Yes, it will cost a bit more. However, I think it’s fair to say that, for most companies, Email is a mission critical service, with lots of LOB applications relying on it to keep the show on the road and thousands of users relying on it for mail and calendaring. Quite frankly, it’s worth spending money on.
The Pros
To quote Ross Smith IV, “failure happens”. Your servers will die at some point, and when they do, there are really two things we don’t want to happen: firstly, we don’t want to bring your DAG down by losing quorum. So, the more nodes you can lose, the better. Yes, with 2012 R2 we have Dynamic Quorum, but that really only comes into it’s own when nodes drop in a sequential fashion and the cluster has time to jiggle things around. Second, in the event of a *over, we absolutely do not want our other nodes to have so much load put on them that keel over and die. The more nodes you have to spread the load, the better.
The other benefit is increased CAFÉ servers. Scaling Out means you add another 4 CAFÉ servers to your CAS array. The more nodes you have to spread the CAS load, in peacetime and in battle conditions, the better.
So, lets look at a few scenarios where our hardware fails and see the impact on load during node failure. Below we can see a four, eight and sixteen node DAG and how the DB’s are balanced during a single server failure, a quadruple server failure and, finally, a site failure.
4 Node DAG, 4 HA Copies (One lag)

Failing Server 1 gives you 14 active on Server 2 and Server 3 and Server 4 stay with their normal load. Hardly seems fair.
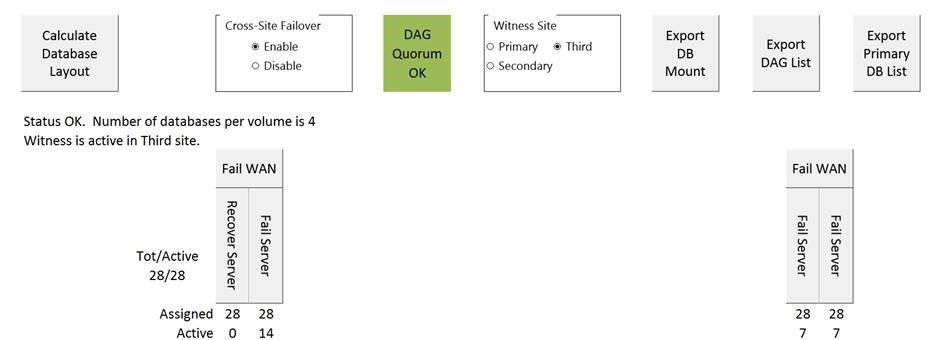
8 Node DAG, 4 HA Copies (One lag)

Failing Server 1 gives you a small increase in load on servers in DC1
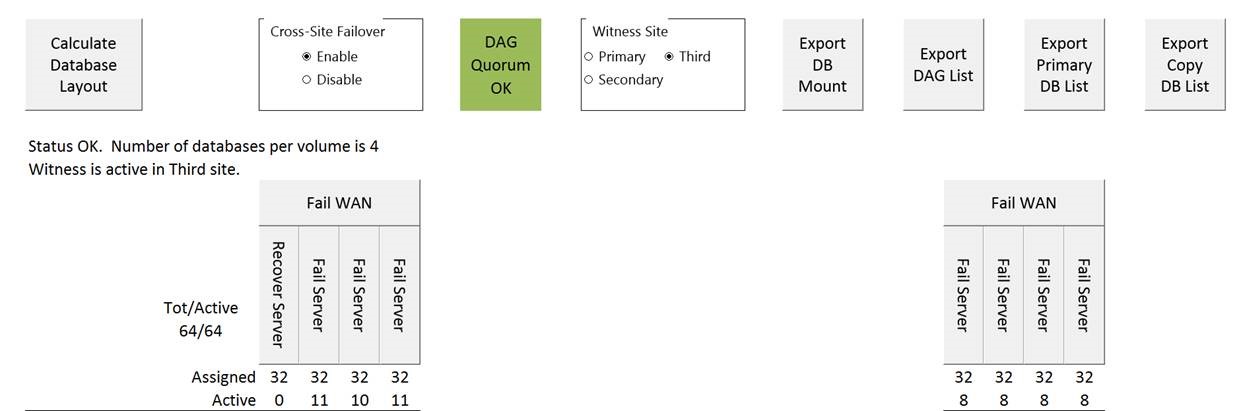
Failing Servers 1 and 2 gives you, again, a smaller increase in load - spread over DC1 and DC2:
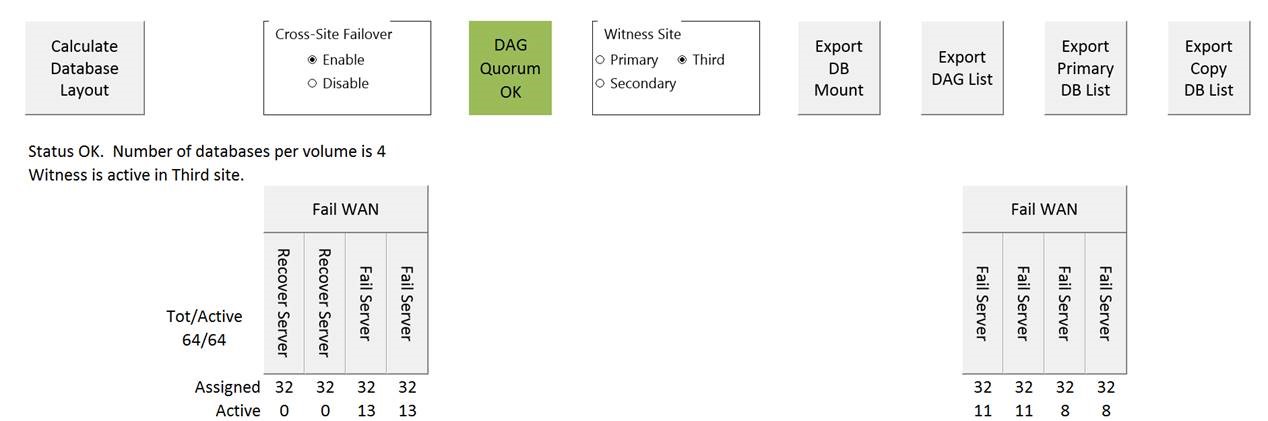
16 node DAG, 4 HA Copies (One lag)

Failing Server 1 gives you 8 DB’s per server in DC1:

So a much, much better distribution of the load based on server failures.
Failing 4 servers in DC1 gives you this spread of DB’s:
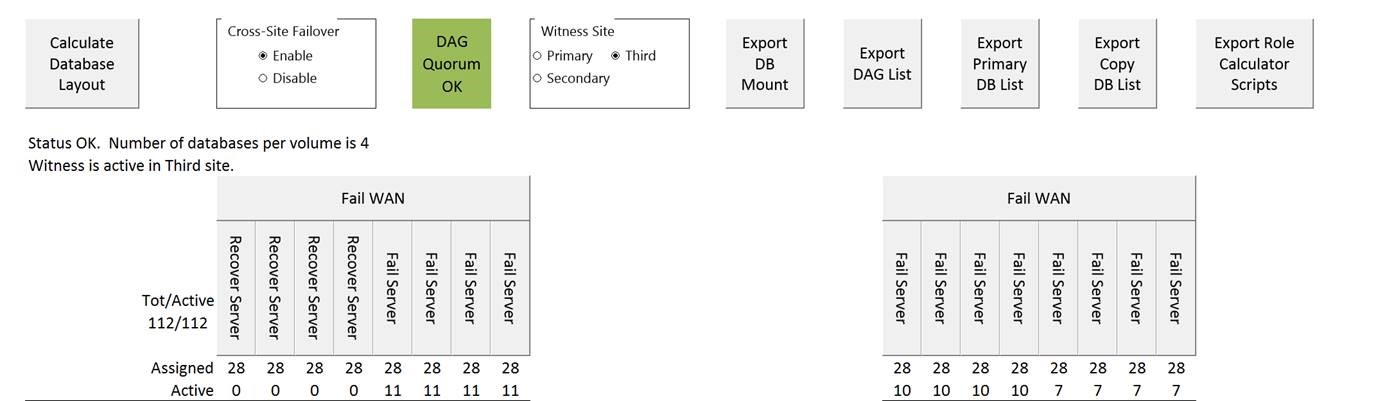
Failing over the entire WAN gives you:

Real World
All of this information is good, and hopefully you will take it all on board before starting out with your Exchange 2013 design and deployment. But sometimes, as Premier Field Engineers, we are assigned to a customer who has already completed the design phase and has a POC in. One of the best things about being a Dedicated Support Engineer is that you get to aid them in their design, supplying the kind of information that will help them avoid problem scenarios before they spend all their cash.
One recent customer had a POC in with a 4 node DAG, spec’d to house around 5000 users. The company has 160,000 mailboxes, and their thinking was that they would use a DAG as a unit of scale (which it is), and every 5000 users they would put in a new DAG. For those of you not blessed with a brain for maths, that means 32 DAG’s in their environment. So, what was their thinking and why did we change it? Well, their thinking was that if “something” happened which would take the configuration of the DAG out, the outage would be limited to 5000 users, as opposed to, say, 10,000 (8 node DAG) or 20,000 (16 node DAG). They weren’t sure what that event may be, but better safe than sorry. Think about this for a minute. We are actually making the DAG “weaker”, because we are reducing the amount of servers that can fail before the DAG keels over. Less servers means less redundancy. On top of that, we are creating a huge overhead from a management perspective, because we now have to manage 32 DAG’s instead of 16 or even 8. Imagine a site switchover scenario. Would you rather complete the steps 32 times or 8 times? We supplied the customer with enough information that they felt comfortable in increasing the number of nodes in the DAG.
Another recent example comes from an internal discussion with another PFE, also dedicated to their customer. Their customer wanted to use a server with 60 cores and 192GB RAM. This was a classic case of “Scaling Up”. They had plugged into the calculator the below:

{kind=link}
The environment was a 25,000 seat estate, and they wanted to use 16 servers. Management had said that they had no budget to buy more servers, so they wanted to populate all 4 sockets. You are now all well versed in what is “wrong” with this approach. Technically, there is nothing “wrong” with this design, per se. But, as we have discussed, this is not the right approach. This is going against all of our guidance and thinking. Moreover, customers need to understand that Exchange is not designed to run on this type of hardware. We do no testing on servers with this many cores. I cannot share what servers we use in the worlds’ largest Exchange deployment, Office 365, but I can tell you that we practice what we preach and have no servers with anywhere near that amount of cores. This trailblazing customer would be doing something that we have never done ourselves, so we cannot advise them what will happen. We know that we start to see strange behaviour with .NET memory allocation when the amount of cores starts climbing, and the Product Group have been involved in CritSits (Severity A cases) where the Root Cause has been put down to the high number of cores in the server. Far better to increase the amount of servers - as we have seen - populating only 2 sockets (or even 4 sockets with fewer cores), and work within our comfort zone. No one should want to be bobbing up and down in unchartered waters alone when it comes to a mission critical application like your Email system.
Conclusion
We know things will fail. When we design an Exchange environment to deal with these failures, we need to make sure we get the best out of the design. As you can see, the more nodes in your DAG, the more nodes you can lose while a) still maintaining quorum and b) keeping the load lighter on the nodes that pick up the slack. On top of that, you get the added bonus of extra CAFÉ servers in the array. They say size isn’t everything, but when it comes to DAG’s I would respectfully disagree!
Adrian Moore
Senior Premier Field Engineer
References
Exchange 2013 Server Role Requirements Calculator
Concerning Trends Discovered During Several Critical Escalations
Comments
- Anonymous
February 17, 2015
Thanks