Azure AI Immersive Reader
An Azure Applied AI Service that embeds text reading and comprehension capabilities into your applications.
31 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPP%3C/text%3E%3C/svg%3E)
I am writing code in hiveQL using databricks community edition.
I have loaded the csv dataset files into dbfs, and created hive external table and tried loading table with data from uploaded dbfs file.
CREATE EXTERNAL TABLE IF NOT EXISTS data_table(
Id STRING,
Sponsor STRING,
Status STRING,
Start_Date STRING,
Completion_Date STRING,
Type STRING,
Submission STRING,
Conditions ARRAY<STRING>,
Interventions STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
LOCATION '/FileStore/tables/CT21/clinicaltrial_2021-1.csv'
TBLPROPERTIES("skip.header.line.count"="2");
result was OK.
But when I queried
select * from data_table
It throws an exception:
Error in SQL statement: IOException: Path: /FileStore/tables/clinicaltrial_2021/mesh.csv is a directory, which is not supported by the record reader when mapreduce.input.fileinputformat.input.dir.recursive is false.
When I checked dbfs directory:
There exists a new directory mesh.csv created by dbfs with many subdirectories with same mesh.csv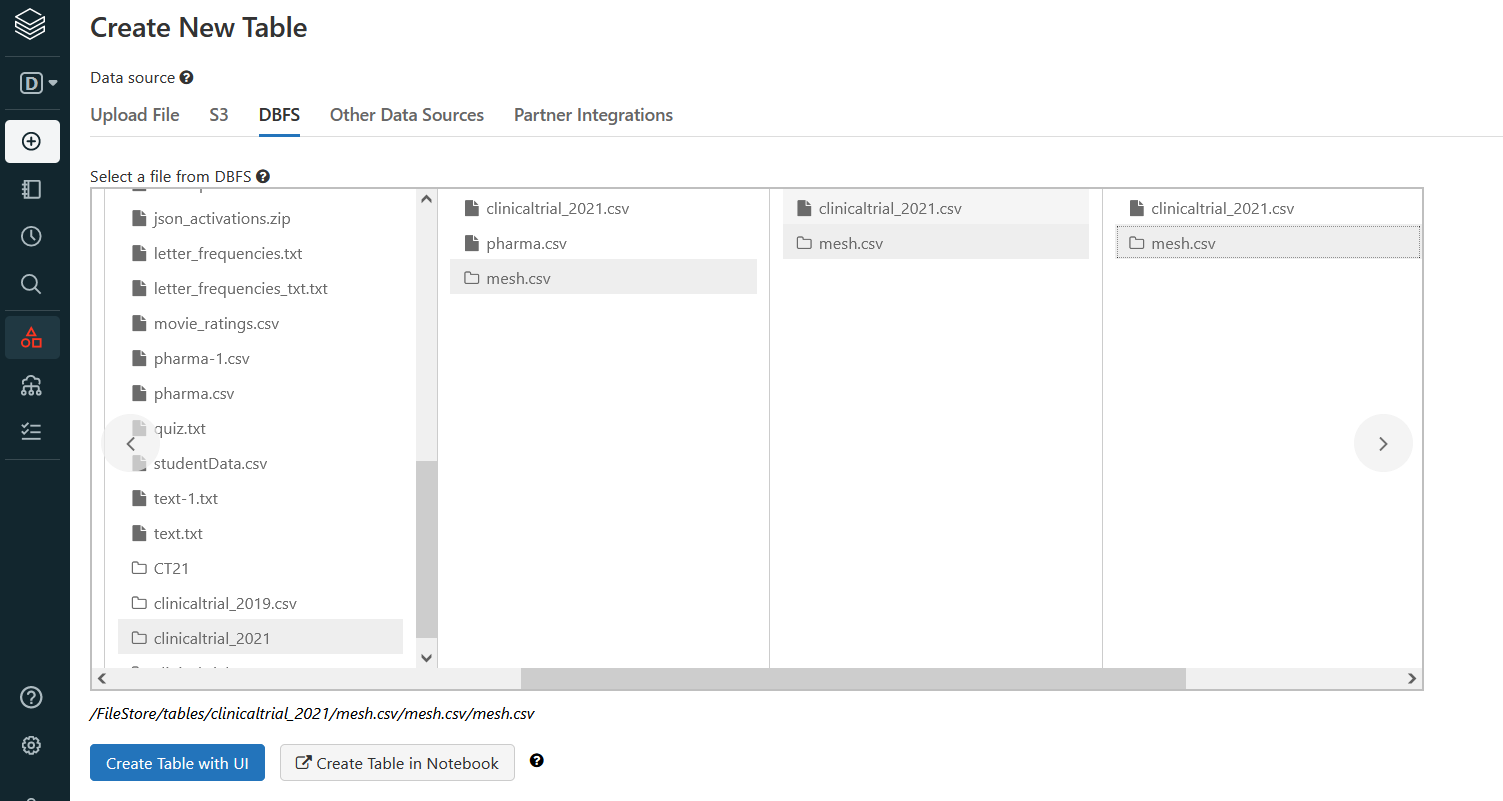
Any help is highly appreciated.

Hello @prathyush paruchuri ,
Thanks for the question and using MS Q&A platform.
Could you please share the code snippet which you are trying to run?
Hello @prathyush paruchuri ,
Just checking in if you have had a chance to see the previous response. We need the following information to understand/investigate this issue further.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPP%3C/text%3E%3C/svg%3E)
Hello @PRADEEPCHEEKATLA
I didn't able to check my email in a while. I have resolved the aforementioned error using the command
SET mapreduce.input.fileinputformat.input.dir.recursive=True.
Thank you very much for your response.
Hello @prathyush paruchuri ,
Glad to know that your issue has been resolved. And thanks for sharing the solution, which might be beneficial to other community members reading this thread.