SQL Server
A family of Microsoft relational database management and analysis systems for e-commerce, line-of-business, and data warehousing solutions.
14,490 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
I have a table with
CREATE TABLE dbo.NOT_UNIQUE ( ID INT NULL , COL1 INT NULL, COL2 CHAR(10) NULL );
But why the rowsize is 33?? byte?
int should be 4byte, CHAR(10) 10 bytes,,,, and including the uniqueidentifier hidden column 4byte.... 22 byte only.

Hi @sakuraime ,
Any update for this thread? Did the reply from TiborKaraszi could help you? If the response helped, do "Accept Answer".
Best regards,
Cathy
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ETH%3C/text%3E%3C/svg%3E)
OK, good. You now posted a different table from your first post, since I now see that your table has a clustered index.
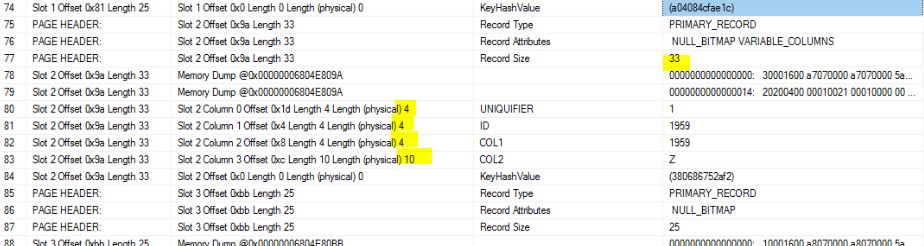
Half of the rows has a length of 25. That is explained by my earlier answer. Each of them are the first numerical value for ID. Note that the uniquifier isn't populated for the "first row"; it is only populated when you have duplicates for the clustered index key.
Then you have a duplicate of ID. That second row has a length of 33. The uniquifier is 4 bytes. 25 + 4 = 29. 4 more bytes to explain.
A row where the uniquifier exists is handled like a row with at least one variable size column. That means that you have 2 bytes specifying the number of variable length column. And then also 2 bytes for each var size column, for the column offset . In your case you have 1 var size column. I.e., 2 + 2 = 4.
Mystery explained. See for instance this for more info: https://aboutsqlserver.com/2013/10/15/sql-server-storage-engine-data-pages-and-data-rows/
thank you
2 bytes in beginning of row (tag A and tag B).
2 byte specifying length of the fix portion of the row.
2 bytes specifying number of columns.
1 byte being the NULL bitmap.
how the above reflect in DBCC page results ?
That information is not presented in a decoded way by DBCC PAGE. You can read the hex-dump (Memory Dump) and decode that information yourself. Also, print option 3 to DBCC PAGE can give you a bit more info, since it decodes each row. But I couldn't find anything that show those overhead columns explicitly.
Please post a full repro. The output you post is not for the CREATE TABLE you posted. The CREATE TABLE you posted is a heap, and a heap doesn't have a uniquifier.
For the CREATE TABLE you posted, I get the length 25. The data is 4+4+10 = 18. So we have a row overhead of 7 bytes (25-18). The row overhead is:
2 bytes in beginning of row (tag A and tag B).
2 byte specifying length of the fix portion of the row.
2 bytes specifying number of columns.
1 byte being the NULL bitmap.
As you see, above lines up exactly, 4+4+10 + 2+2+2+1 = 25. Below is T-SQL code I used (in a database named TSQL). For an answer corresponding to your example, please post a repro, with the correct DDL and DML commands (as I do below):
CREATE TABLE dbo.NOT_UNIQUE ( ID INT NULL , COL1 INT NULL, COL2 CHAR(10) NULL );
insert into NOT_UNIQUE values(1, 1, '1')
insert into NOT_UNIQUE values(1, 1, '1')
insert into NOT_UNIQUE values(2, 2, '2')
--Get the page no
SELECT --*
allocated_page_file_id
,allocated_page_page_id
,object_id
,partition_id
,allocation_unit_type_desc
,page_type
,page_type_desc
,index_id
FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('NOT_UNIQUE'), null, null, 'DETAILED');
DBCC TRACEON(3604)
DBCC PAGE(TSQL, 1, 872, 1) WITH TABLERESULTS
CREATE TABLE dbo.NOT_UNIQUE ( ID INT NULL , COL1 INT NULL, COL2 CHAR(10) NULL );
CREATE TABLE dbo.Number (
N INT CONSTRAINT Number_PK PRIMARY KEY CLUSTERED(N)
);
GO
WITH
L0 AS(SELECT 1 AS C UNION ALL SELECT 1 AS O), -- 2 rows
L1 AS(SELECT 1 AS C FROM L0 AS A CROSS JOIN L0 AS B), -- 4 rows
L2 AS(SELECT 1 AS C FROM L1 AS A CROSS JOIN L1 AS B), -- 16 rows
L3 AS(SELECT 1 AS C FROM L2 AS A CROSS JOIN L2 AS B), -- 256 rows
L4 AS(SELECT 1 AS C FROM L3 AS A CROSS JOIN L3 AS B), -- 65,536 rows
L5 AS(SELECT 1 AS C FROM L4 AS A CROSS JOIN L4 AS B), -- 4,294,967,296 rows
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS N FROM L5)
INSERT INTO dbo.Number SELECT TOP (10000) N FROM Nums ORDER BY N;
GO
INSERT INTO NOT_UNIQUE SELECT TOP (5000) N, N, 'Z' FROM dbo.Number;
GO 2
CREATE CLUSTERED INDEX IX_CLUSTERED ON dbo.NOT_UNIQUE ( ID );