A list of metrics for evaluating LLM-generated content
Evaluation methods measure how well our system is performing. Manual evaluation (human review) of each summary would be time-consuming, costly and would not be scalable, so it is usually complemented by automatic evaluation. Many automatic evaluation methods attempt to measure the same qualities of text that human evaluators would consider. Those qualities include fluency, coherence, relevance, factual consistency, and fairness. Similarity in content or style to a reference text can also be an important quality of generated text.
The following diagram includes many of the metrics used to evaluate LLM-generated content, and how they can be categorized.
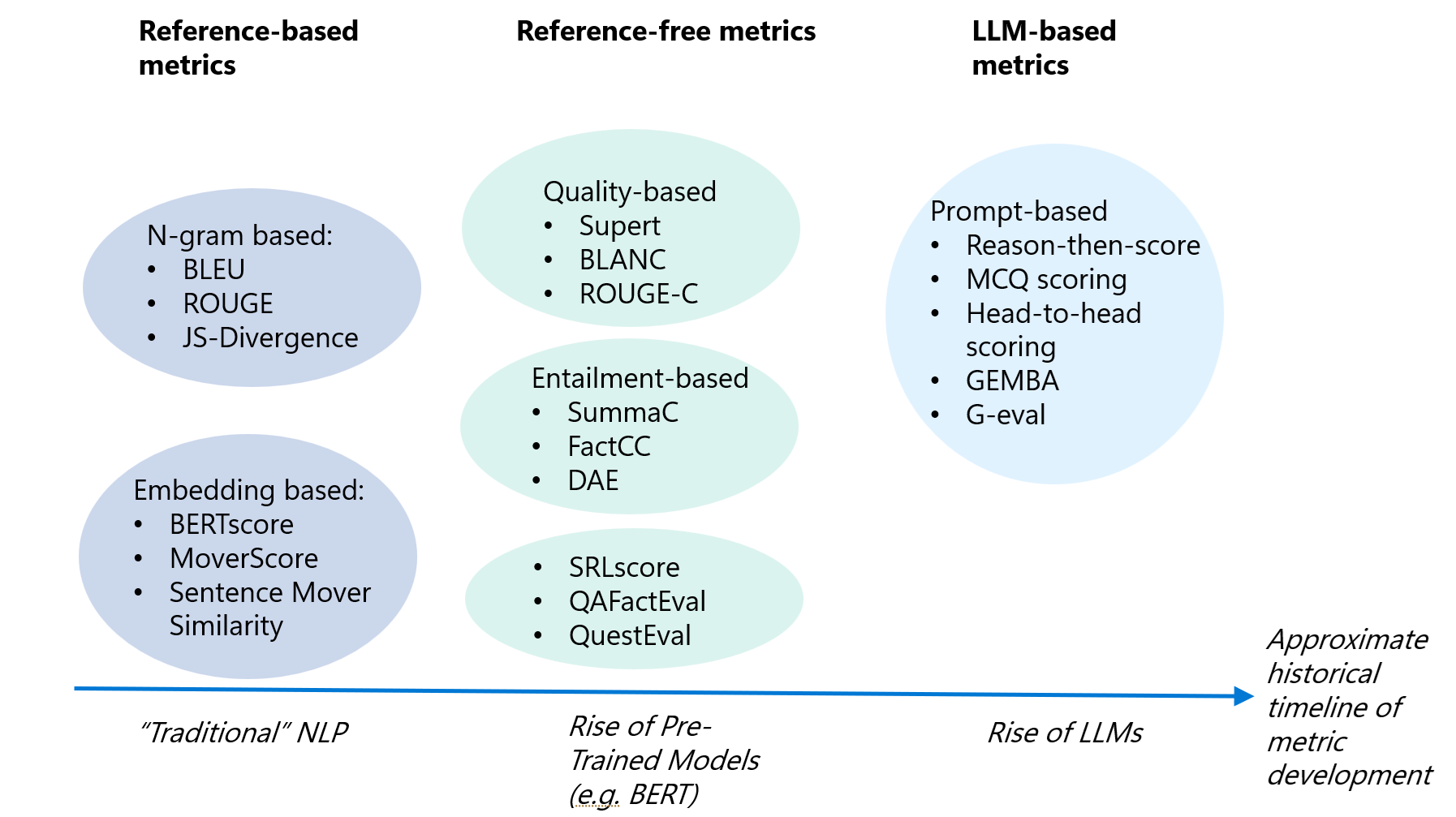
Figure 1: Evaluation metrics for LLM content, and how they can be categorized. The timeline shows at what point in the history of AI the metrics were developed
Reference-based Metrics
Reference-based metrics are used to compare generated text to a reference, the human annotated ground truth text. Many of these metrics were developed for traditional NLP tasks before LLMs were developed but remain applicable to LLM-generated text.
N-gram based metrics
Metrics BLEU (Bilingual Evaluation Understudy), ROUGE (Recall-Oriented Understudy for Gisting Evaluation), and JS divergence (JS2) are overlap-based metrics that measure the similarity of the output text and the reference text using n-grams.
BLEU Score
The BLEU (bilingual evaluation understudy) score evaluates the quality of machine-translated text from one natural language to another. Therefore, it’s typically used for machine-translation tasks, however, it’s also being used in other tasks such as text generation, paraphrase generation, and text summarization. The basic idea involves computing the precision, which is the fraction of candidate words in the reference translation. Scores are calculated for individual translated segments—generally sentences—by comparing them with a set of good quality reference translations. Those scores are then averaged over the whole corpus to reach an estimate of the translation's overall quality. Punctuation or grammatical correctness is not taken into account when scoring.
Few human translations will attain a perfect BLEU score, since a perfect score would indicate that the candidate is identical to one of the reference translations. For this reason, it is not necessary to attain a perfect score. Given that there are more opportunities to match with the addition of multiple reference translations, we encourage having one or more reference translations that will be useful for maximizing the BLEU score.
$$P = {m \over w_t}$$ m: Number of candidate words in reference. *wt: Total number of words in candidate.
Typically, the above computation considers individual words or unigrams of candidate that occur in target. However, for more accurate evaluations of a match, one could compute bi-grams or even trigrams and average the score obtained from various n-grams to compute the overall BLEU score.
ROUGE
As opposed to the BLEU score, the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) evaluation metric measures the recall. It’s typically used for evaluating the quality of generated text and in machine translation tasks. However, since it measures recall, it's used in summarization tasks. It’s more important to evaluate the number of words the model can recall in these types of tasks.
The most popular evaluation metrics from the ROUGE class are ROUGE-N and ROUGE-L:
Rouge-N: measures the number of matching 'n-grams' between a reference (a) and test (b) strings. $$Precision= {\text{number of n-grams found in both a and b} \over \text{number of n-grams in b}}$$ $$Recall= {\text{number of n-grams found in both a and b} \over \text{number of n-grams in a}}$$ Rouge-L: measures the longest common subsequence (LCS) between a reference (a) and test (b) string. $$Precision= {LCS(a,b) \over \text{number of uni-grams in b}}$$ $$Recall= {LCS(a,b) \over \text{number of uni-grams in a}}$$ For both Rouge-N and Rouge-L: $$F1={2 \times\text{precision} \over recall}$$
Text Similarity metrics
Text similarity metrics evaluators focus on computing similarity by comparing the overlap of word or word sequences between text elements. They’re useful for producing a similarity score for predicted output from an LLM and reference ground truth text. These metrics also give an indication as to how well the model is performing for each respective task.
Levenshtein Similarity Ratio
The Levenshtein Similarity Ratio is a string metric for measuring the similarity between two sequences. This measure is based on Levenshtein Distance. Informally, the Levenshtein Distance between two strings is the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one string into the other. The Levenshtein Similarity Ratio can be calculated using Levenshtein Distance value and the total length of both sequences in the following definitions:
Levenshtein Similarity Ratio (Simple Ratio):
$$Lev.ratio(a, b) = {(|a|+|b|)-Lev.dist(a,b) \over |a|+|b|}$$
where |a| and |b| are the lengths of a and b.
A few different methods are derived from Simple Levenshtein Similarity Ratio:
- Partial Ratio: Calculates the similarity by taking the shortest string, and compares it against the sub-strings of the same length in the longer string.
- Token-sort Ratio: Calculates the similarity by first splitting the strings into individual words or tokens, sorts the tokens alphabetically, and then recombines them into a new string. This new string is then compared using the simple ratio method.
- Token-set Ratio: Calculates the similarity by first splitting the strings into individual words or tokens, and then matches the intersection and union of the token sets between the two strings.
Semantic Similarity metrics
BERTScore, MoverScore, and Sentence Mover Similarity (SMS) metrics all rely on contextualized embeddings to measure the similarity between two texts. While these metrics are relatively simple, fast, and inexpensive to compute compared to LLM-based metrics, studies have shown that they can have poor correlation with human evaluators, lack of interpretability, inherent bias, poor adaptability to a wider variety of tasks and inability to capture subtle nuances in language.
The semantic similarity between two sentences refers to how closely related their meanings are. To do that, each string is first represented as a feature vector that captures its semantics/meanings. One commonly used approach is generating embeddings of the strings (for example, using an LLM) and then using cosine similarity to measure the similarity between the two embedding vectors. More specifically, given an embedding vector (A) representing a target string, and an embedding vector (B) representing a reference one, the cosine similarity is computed as follows:
$$ \text{cosine similarity} = {A \cdot B \over ||A|| ||B||}$$
As shown above, this metric measures the cosine of the angle between two non-zero vectors and ranges from -1 to 1. 1 means the two vectors are identical and -1 means they are dissimilar.
Reference-free Metrics
Reference-free (context-based) metrics produce a score for the generated text and do not rely on ground truth. Evaluation is based on the context or source document. Many of these metrics were developed in response to the challenge of creating ground truth data. These methods tend to be newer than reference-based techniques, reflecting the growing demand for scalable text evaluation as PTMs became increasingly powerful. These include quality-based, entailment-based, factuality-based, question-answering (QA) and question-generation (QG) based metrics.
Quality-based metrics for summarization. These methods detect if the summary contains pertinent information. SUPERT quality measures the similarity of a summary with a BERT-based pseudo-reference, and BLANC quality measures the difference in accuracy of two reconstructions of masked-tokens. ROUGE-C is a modification of ROUGE without the need for references and uses the source text as the context for comparison.
Entailment-based metrics. Entailment-based metrics are based on the Natural Language Inference (NLI) task, where for a given text (premise), it determines whether the output text (hypothesis) entails, contradicts or undermines the premise [24]. This can help to detect factual inconsistency.The SummaC (Summary Consistency) benchmark, FactCC, and DAE (Dependency Arc Entailment) metrics serve as an approach to detect factual inconsistencies with the source text. Entailment-based metrics are designed as a classification task with labels “consistent” or “inconsistent”.
Factuality, QA and QG-based metrics. Factuality-based metrics like SRLScore (Semantic Role Labeling) and QAFactEval evaluate whether generated text contains incorrect information that does not hold true to the source text. QA-based, like QuestEval, and QG-based metrics are used as another approach to measure factual consistency and relevance.
Reference-free metrics have shown improved correlations to human evaluators compared to reference-based metrics, but there are limitations to using reference-free metrics as the single measure of progress on a task. Some limitations include bias towards their underlying models’ outputs and bias against higher-quality text.
LLM-based Evaluators
LLM’s remarkable abilities have led to their emerging use as not only to generate text, but also evaluators of text. These evaluators offer scalability and explainability.
Prompt-based evaluators
LLM-based evaluators prompt an LLM to be the judge of some text. The judgement can be based on (i) the text alone (reference-free), where the LLM is judging qualities like fluency, and coherence; (ii) the generated text, the original text, and potentially a topic or question (reference-free), where the LLM is judging qualities like consistency, and relevancy (iii) a comparison between the generated text and the ground truth (reference-based), where the LLM is judging quality, and similarity. Some frameworks for these evaluation prompts include Reason-then-Score (RTS), Multiple Choice Question Scoring (MCQ), Head-to-head scoring (H2H), and G-Eval (see the page on Evaluating the performance of LLM summarization prompts with G-Eval). GEMBA is a metric for assessing translation quality.
LLM-evaluation is an emerging area of research and has not yet been systematically studied. Already, researchers have identified issues with reliability in LLM evaluators such as positional bias, verbosity bias, self-enhancement bias, limited mathematical and reasoning capabilities, and issues with LLM success at assigning numerical scores. Strategies that have been proposed to mitigate positional bias include Multiple Evidence Calibration (MEC), Balanced Position Calibration (BPC), and Human In The Loop Calibration (HITLC).
Example of a prompt-based evaluator
We can take output produced by the model and prompt the model to determine the quality of the completions generated. The following steps are typically required to use this evaluation method:
- Generating output predictions from a given test set.
- Prompt the model to focus on assessing the quality of output-given reference text and sufficient context (for example, criteria for evaluation).
- Feed the prompt into the model and analyze results.
The model should be able to provide a score given sufficient prompting and context. While GPT-4 has yielded fairly good results with this method of evaluation, a human in the loop is still required to verify the output generated by the model. The model may not perform as well in domain-specific tasks or situations that involve applying specific methods to evaluate output. Therefore, the behavior of the model should be studied closely depending on the nature of the dataset. Keep in mind that performing LLM-based evaluation requires its own prompt engineering. Below is a sample prompt template used in an NL2Python application.
You are an AI-based evaluator. Given an input (starts with --INPUT) that consists or a user prompt (denoted by STATEMENT)
and the two completions (labelled EXPECTED and GENERATED), please do the following:
1- Parse user prompt (STATEMENT) and EXPECTED output to understand task and expected outcome.
2- Check GENERATED code for syntax errors and key variables/functions.
3- Compare GENERATED code to EXPECTED output for similarities/differences, including the use of appropriate Python functions and syntax.
4- Perform a static analysis of the GENERATED code to check for potential functional issues, such as incorrect data types, uninitialized variables,
and improper use of functions.
5- Evaluate the GENERATED code based on other criteria such as readability, efficiency, and adherence to best programming practices.
6- Use the results of steps 2-5 to assign a score to the GENERATED code between 1 to 5, with a higher score indicating better quality.
The score can be based on a weighted combination of the different criteria.
7- Come up an explanation for the score assigned to the GENERATED code. This should also mention if the code is valid or not
When the above is done, please generate an ANSWER that includes outputs:
--ANSWER
EXPLANATION:
SCORE:
Below are two example:
# Example 1
--INPUT
STATEMENT = create a cube
EXPECTED = makeCube()
GENERATED = makeCube(n='cube1')
--ANSWER
SCORE: 4
EXPLANATION: Both completions are valid for creating a cubes . However, the GENERATED one differs by including the cube name (n=cube1), which is not necessary.
# Example 2
--INPUT
STATEMENT = make cube1 red
EXPECTED = changeColor(color=(1, 0, 0), objects=["cube1"])
GENERATED = makeItRed(n='cube1')
--ANSWER
SCORE: 0
EXPLANATION: There is no function in the API called makeItRed. Therefore, this is a made-up function.
Now please process the example blow
--INPUT
STATEMENT = {prompt}
EXPECTED = {expected_output}
GENERATED = {completion}
--ANSWER
The output of an LLM evaluator is usually a score (e.g. 0-1) and optionally an explanation which is something we don't necessarily get with traditional metrics.
LLM embedding-base metrics
Recently, the embedding models from LLMs, such as GPT3’s text-embedding-ada-002 has also been used for embedding-based metrics that calculate semantic similarity.
Metrics for LLM-generated code
The following metrics apply when an LLM is used to generate code.
Functional Correctness
Functional correctness evaluates the accuracy of NL-to-code generation tasks when the LLMs is tasked with generating code for a specific task in natural language. In this context, functional correctness evaluation is used to assess whether the generated code produces the desired output for a given input.
For example, To use functional correctness evaluation, we can define a set of test cases that cover different inputs and their expected outputs. For instance, we can define the following test cases:
Input: 0
Expected Output: 1
Input: 1
Expected Output: 1
Input: 2
Expected Output: 2
Input: 5
Expected Output: 120
Input: 10
Expected Output: 3628800
We can then use the LLMs-generated code to calculate the factorial of each input and compare the generated output to the expected output. If the generated output matches the expected output for each input, we consider the test case to have passed and conclude that the LLMs is functionally correct for that task.
The limitation of functional correctness evaluation is that sometimes it is cost prohibitive to set up an execution environment for implementing generated code. Additionally, functional correctness evaluation does not take into account the following important factors of the generated code:
- Readability
- Maintainability
- Efficiency
Moreover, it is difficult to define a comprehensive set of test cases that cover all possible inputs and edge cases for a given task. This difficulty can limit the effectiveness of functional correctness evaluation.
Rule-based Metrics
For domain-specific applications and experiments, it might be useful to implement rule-based metrics. For instance, assuming we ask the model to generate multiple completions for a given task. We might be interested in selecting output that maximizes the probability of certain keywords being present in the prompt. Additionally, there are situations in which the entire prompt might not be useful – only key entities might be of use. Creating a model that performs entity extraction on generated output can be used to evaluate the quality of the predicted output as well. Given many possibilities, it is good practice to think of custom, rule-based metrics that are tailored to domain-specific tasks. Here we provide examples of some widely used rule-based evaluation metrics for both NL2Code and NL2NL use cases:
- Syntax correctness: This metric measures whether the generated code conforms to the syntax rules of the programming language being used. This metric can be evaluated using a set of rules that check for common syntax errors. Some examples of common syntax errors are missing semicolons, incorrect variable names, or incorrect function calls.
- Format check: Another metric that can be used to evaluate NL2Code models is the format of the generated code. This metric measures whether the generated code follows a consistent and readable format. It can be evaluated using a set of rules that check for common formatting issues, such as indentation, line breaks, and whitespace.
- Language check: A language check metric evaluates whether the generated text or code is written understandably and consistent with the user's input. This check can be evaluated using a set of rules that check for common language issues, such as incorrect word choice or grammar.
- Keyword presence: This metric measures whether the generated text includes the keywords or key phrases that were used in the natural language input. It can be evaluated using a set of rules. These rules check for the presence of specific keywords or key phrases that are relevant to the task being performed.
Automatic Test Generation
We can also use LLMs for Automatic Test Generation, where an LLM generates a diverse range of test cases, including different input types, contexts, and difficulty levels:
- Generated test cases: The LLM being evaluated is tasked with solving the generated test cases.
- Predefined metrics: An LLM-based evaluation system then measures the model’s performance using predefined metrics, such as relevance and fluency.
- Comparison and ranking: The results are compared to a baseline or other LLMs, offering insights into the relative strengths and weaknesses of the models.
Metrics for RAG pattern
The Retrieval-Augmented Generation (RAG) pattern is a popular method for improving the performance of LLMs. The pattern involves retrieving relevant information from a knowledge base and then using a generation model to generate the final output. Both the retrieval and generation models can be LLMs. The following metrics from the RAGAS implementation (RAGAS is an Evaluation framework for your Retrieval Augmented Generation pipelines - see below) require the retrieved context per query, and can be used to evaluate the performance of the retrieval model and the generation model:
Generation-related metrics:
Faithfulness: Measures the factual consistency of the generated answer against the given context. If any claims are made in the answer that cannot be deduced from context, then these will be penalized . This is done using a two-step paradigm that includes creation of statements from the generated answer followed by verifying each of these statements against the context (inferencing). It is calculated from answer and retrieved context. The answer is scaled to (0,1) range where 1 is the best.
Answer Relevancy: Refers to the degree to which a response directly addresses and is appropriate for a given question or context. This does not take the factuality of the answer into consideration but rather penalizes the presence of redundant information or incomplete answers given a question. It is calculated from question and answer.
Retrieval related metrics:
Context Relevancy: Measures how relevant retrieved contexts are to the question. Ideally, the context should only contain information necessary to answer the question. The presence of redundant information in the context is penalized. Conveys quality of the retrieval pipeline. It is calculated from question and retrieved context.
Context Recall: Measures the recall of the retrieved context using the annotated answer as ground truth. An annotated answer is taken as proxy for ground truth context. It is calculated from ground truth and retrieved context.
Implementations
Azure Machine Learning prompt flow: Nine built-in evaluation methods available, including classification metrics.
OpenAI Evals: Evals is a framework for evaluating LLMs and LLM systems, and an open-source registry of benchmarks (github.com).
RAGAS: Metrics specific for RAG