Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,212 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBY%3C/text%3E%3C/svg%3E)
how to access and use an environment variable from spark config in synapse pipeline activity
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGG%3C/text%3E%3C/svg%3E)
@Brunda Yelakala (INFOSYS LIMITED) - Just checking in to see if the below answer helped. If this answers your query, do click "Accept the answer” for the same, which might be beneficial to other community members reading this thread. And, if you have any further query do let us know.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESG%3C/text%3E%3C/svg%3E)
Hi Brunda Yelakala (INFOSYS LIMITED),
Thanks for reaching out to Microsoft Q&A.
You can read custom config values in a spark notebook as shown below.
Step1: Add your key-value pairs inside the config.txt file:
Copy
spark.executorEnv.environmentName ppe
Step2: You can upload a config file to your spark pool.
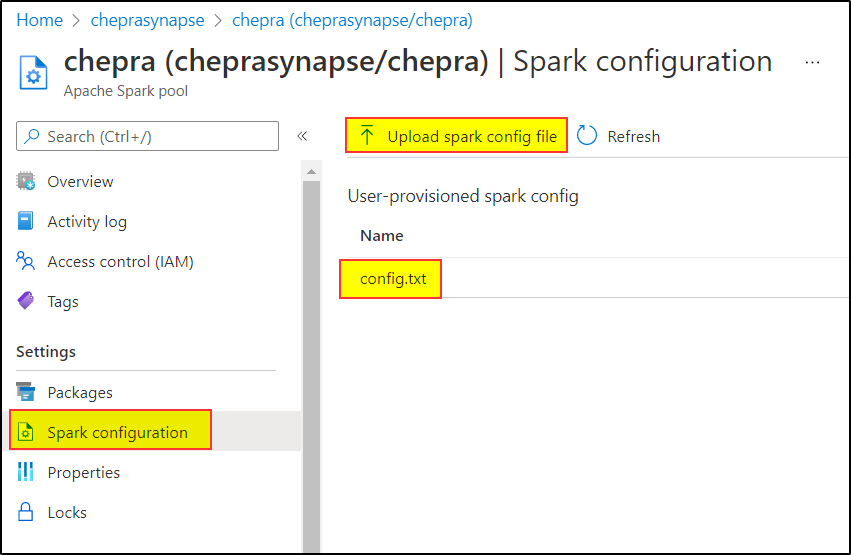
Step3: Which you are then able to access inside your notebooks:
Copy
envName: str = spark.sparkContext.environment.get('environmentName', 'get')
Please let us know if it helps
Please do not forget to "Accept the answer” and “up-vote” wherever the information provided helps you, this can be beneficial to other community members.
@Brunda Yelakala (INFOSYS LIMITED) - Following up to see if the above answer helped. If this answers your query, do click "Accept the answer” for the same, which might be beneficial to other community members reading this thread. And, if you have any further query do let us know.
Hi, thank you for the response. My question is about accessing config from pipeline activity other than notebook., please let me know if there is a way.
Hi @Brunda Yelakala (INFOSYS LIMITED)
Thanks for the question and using MS Q&A platform.
To access a Spark configuration from a Synapse pipeline and use an environment variable, you can add the configuration in the "Advanced" section of the Spark Job Definition object in your pipeline. Here are the steps to do this:
When you run your pipeline, the Spark Job Definition object will inherit the Spark Config options you specified in the "Advanced" section.
For more details, refer to Quickstart: Transform data using Apache Spark job definition.
Hope this helps. Do let us know if you have any further queries.
If this answers your query, do click Accept Answer and Yes for was this answer helpful. And, if you have any further query do let us know.
@Brunda Yelakala (INFOSYS LIMITED) - Following up to see if the above answer helped. If this answers your query, do click "Accept the answer” for the same, which might be beneficial to other community members reading this thread. And, if you have any further query do let us know.