Fast copy in Dataflows Gen2
This article describes the fast copy feature in Dataflows Gen2 for Data Factory in Microsoft Fabric. Dataflows help with ingesting and transforming data. With the introduction of dataflow scale out with SQL DW compute, you can transform your data at scale. However, your data needs to be ingested first. With the introduction of fast copy, you can ingest terabytes of data with the easy experience of dataflows, but with the scalable back-end of the pipeline Copy Activity.
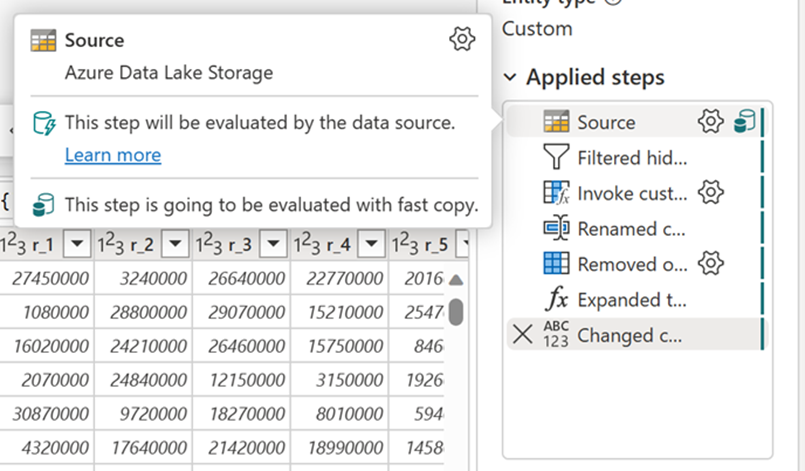
After enabling this capability, Dataflows automatically switch the back-end when data size exceeds a particular threshold, without needing to change anything during authoring of the dataflows. After the refresh of a dataflow, you can check in the refresh history to see if fast copy was used during the run by looking at the Engine type that appears there.
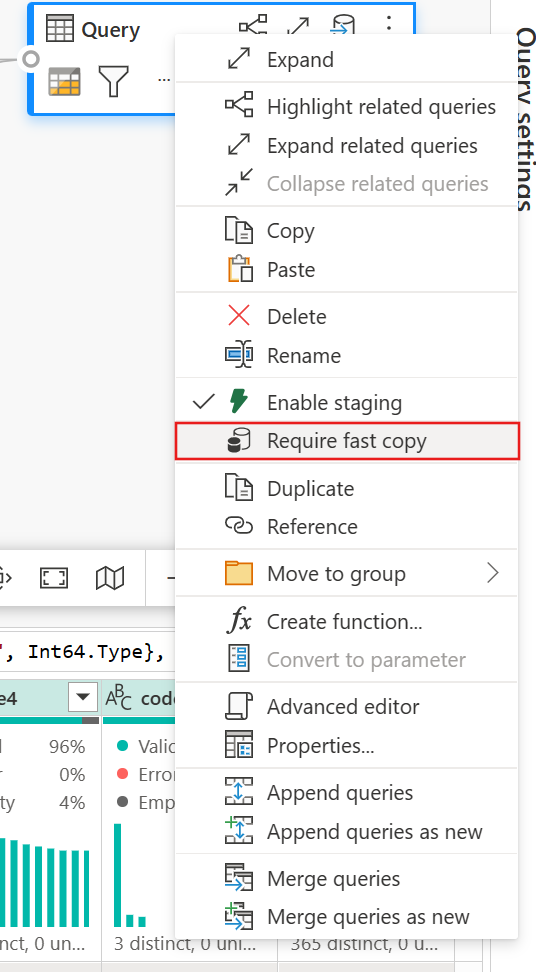
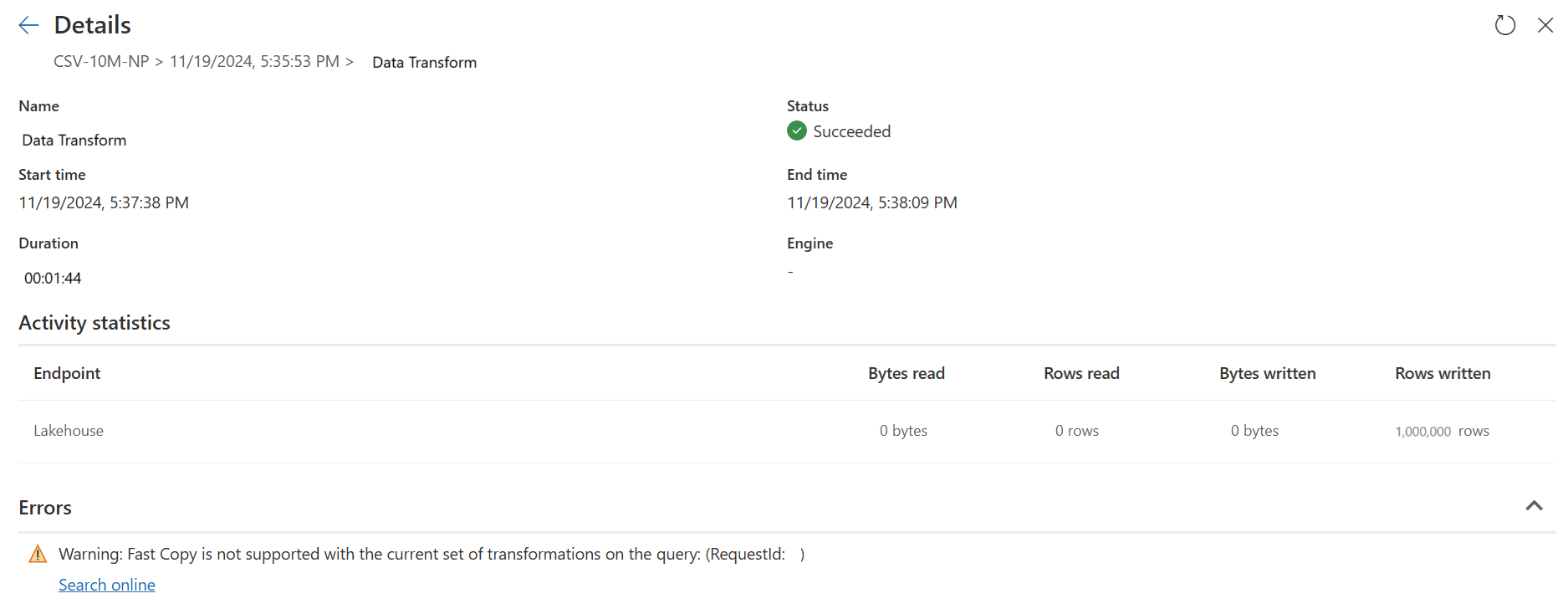
With the Require fast copy option enabled, the dataflow refresh is canceled if fast copy isn't used. This helps you avoid waiting for a refresh timeout to continue. This behavior can also be helpful in a debugging session to test the dataflow behavior with your data while reducing wait time. Using the fast copy indicators in the query steps pane, you can easily check if your query can run with fast copy.
Prerequisites
- You must have a Fabric capacity.
- For file data, files are in .csv or parquet format of at least 100 MB, and stored in an Azure Data Lake Storage (ADLS) Gen2 or a Blob storage account.
- For database including Azure SQL DB and PostgreSQL, 5 million rows or more of data in the data source.
Note
You can bypass the threshold to force Fast Copy by selecting "Require fast copy" setting.
Connector support
Fast copy is currently supported for the following Dataflow Gen2 connectors:
- ADLS Gen2
- Blob storage
- Azure SQL DB
- Lakehouse
- PostgreSQL
- On premise SQL Server
- Warehouse
- Oracle
- Snowflake
The copy activity only supports a few transformations when connecting to a file source:
- Combine files
- Select columns
- Change data types
- Rename a column
- Remove a column
You can still apply other transformations by splitting the ingestion and transformation steps into separate queries. The first query actually retrieves the data and the second query references its results so that DW compute can be used. For SQL sources, any transformation that's part of the native query is supported.
When you directly load the query to an output destination, only Lakehouse destinations are supported currently. If you want to use another output destination, you can stage the query first and reference it later.
How to use fast copy
Navigate to the appropriate Fabric endpoint.
Navigate to a premium workspace and create a dataflow Gen2.
On the Home tab of the new dataflow, select Options:
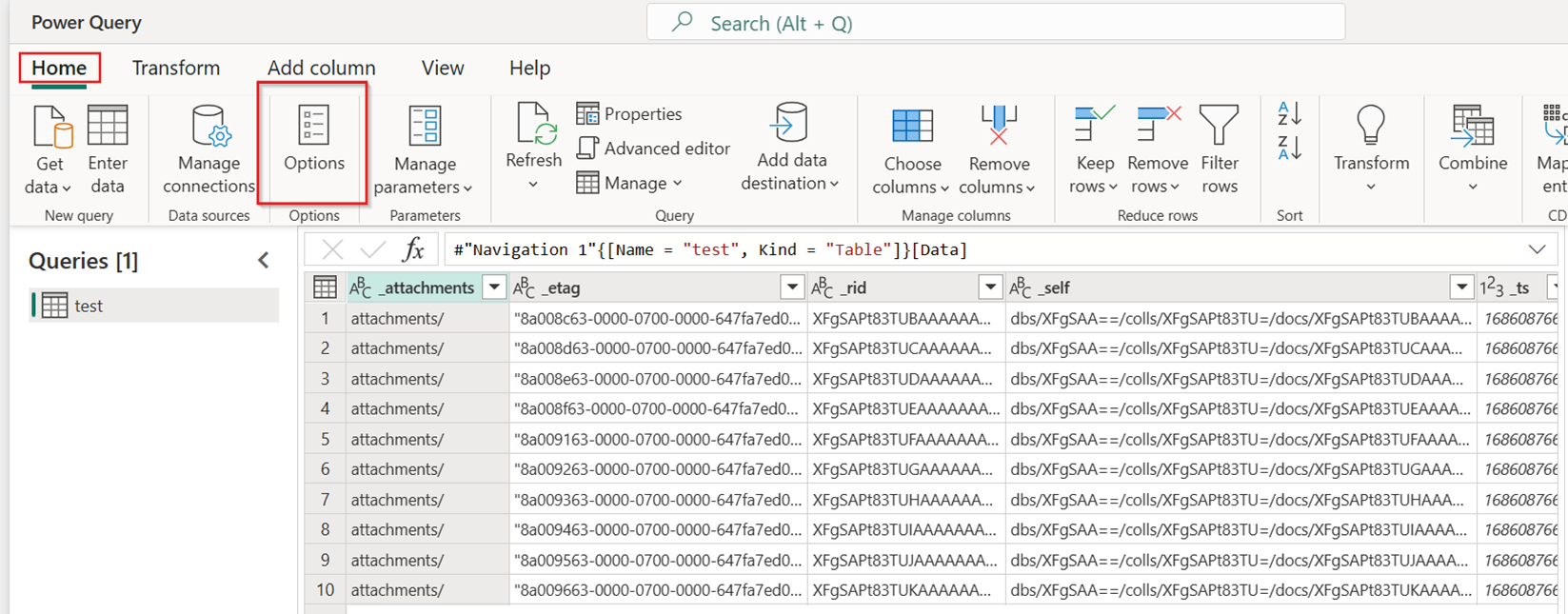
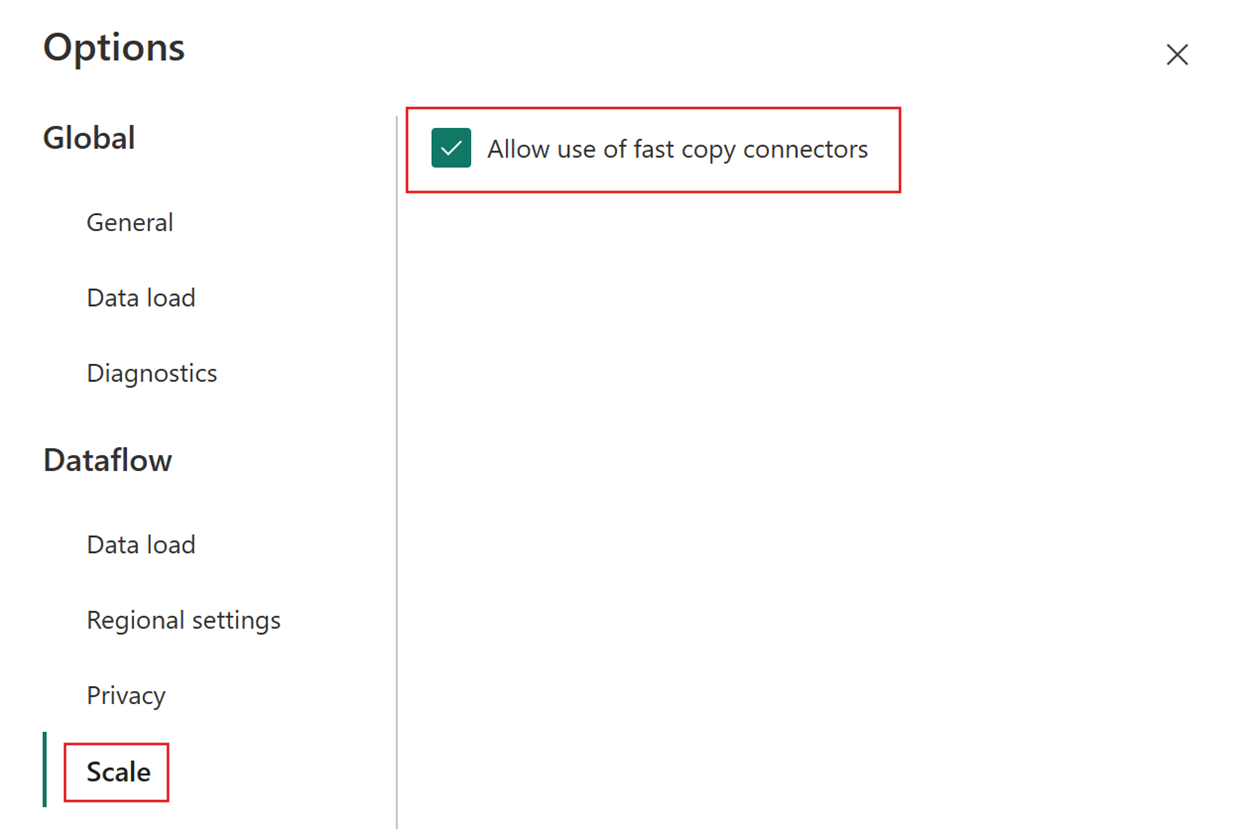
Then choose the Scale tab on the Options dialog and select the Allow use of fast copy connectors checkbox to turn on fast copy. Then close the Options dialog.
Select Get data and then choose the ADLS Gen2 source, and fill in the details for your container.
Use the Combine file functionality.
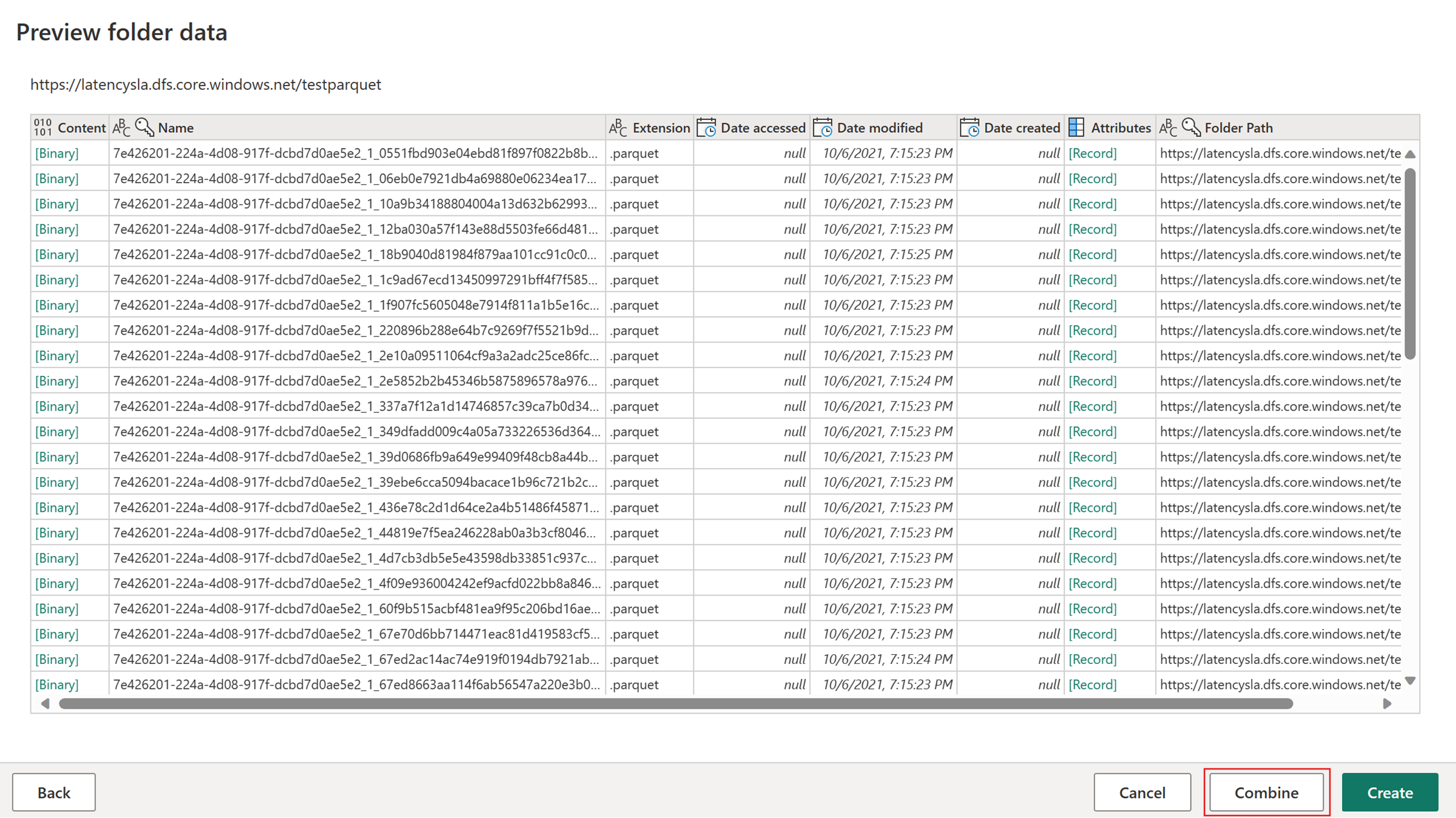
To ensure fast copy, only apply transformations listed in the Connector support section of this article. If you need to apply more transformations, stage the data first, and reference the query later. Make other transformations on the referenced query.
(Optional) You can set the Require fast copy option for the query by right-clicking on it to select and enable that option.
(Optional) Currently, you can only configure a Lakehouse as the output destination. For any other destination, stage the query and reference it later in another query where you can output to any source.
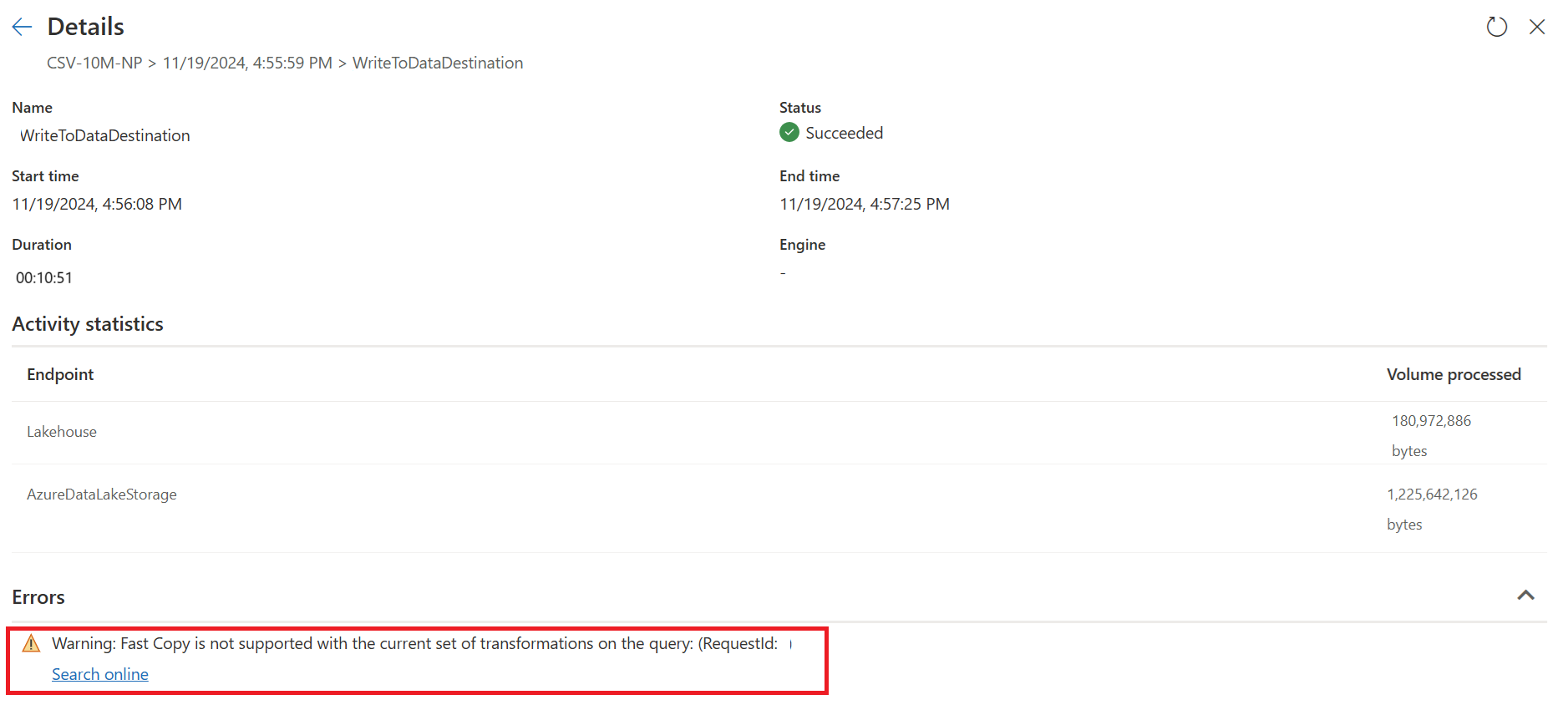
Check the fast copy indicators to see if your query can run with fast copy. If so, the Engine type shows CopyActivity.

Publish the dataflow.
Check after refresh completed to confirm fast copy was used.

How to split your query to leverage fast copy
For optimal performance when processing large volumes of data with Dataflow Gen2, use the Fast Copy feature to first ingest data into staging, then transform it at scale with SQL DW compute. This approach significantly enhances end-to-end performance.
To implement this, Fast Copy indicators can guide you to split query into two parts: data ingestion to staging and large-scale transformation with SQL DW compute. You're encouraged to push as much of the evaluation of a query to Fast Copy that can be used to ingest your data. When Fast Copy indicators tell that the rest steps can't be executed by Fast Copy, you can split the rest of the query with staging enabled.
Step diagnostics indicators
| Indicator | Icon | Description |
|---|---|---|
| This step is going to be evaluated with fast copy | 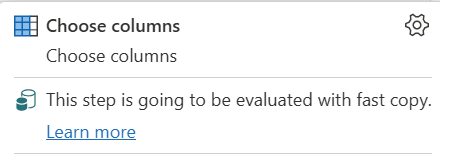
|
The Fast Copy indicator tells you that the query up to this step supports fast copy. |
| This step is not supported by fast copy | 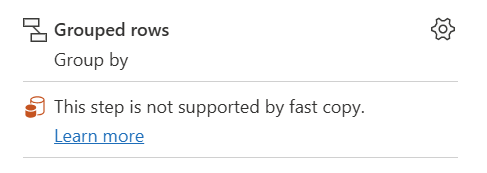
|
The Fast Copy indicator shows that this step doesn't support Fast Copy. |
| One or more steps in your query are not supported by fast query | 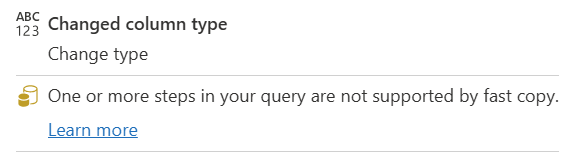
|
The Fast Copy indicator shows that some steps in this query support Fast Copy, while others don't. To optimize, split the query: yellow steps (potentially supported by Fast Copy) and red steps (not supported). |
Step-by-step guidance
After completing your data transformation logic in Dataflow Gen2, the Fast Copy indicator evaluates each step to determine how many steps can leverage Fast Copy for better performance.
In the example below, the last step shows red, indicating that the step with Group By isn't supported by Fast Copy. However, all previous steps showing yellow can be potentially supported by Fast Copy.
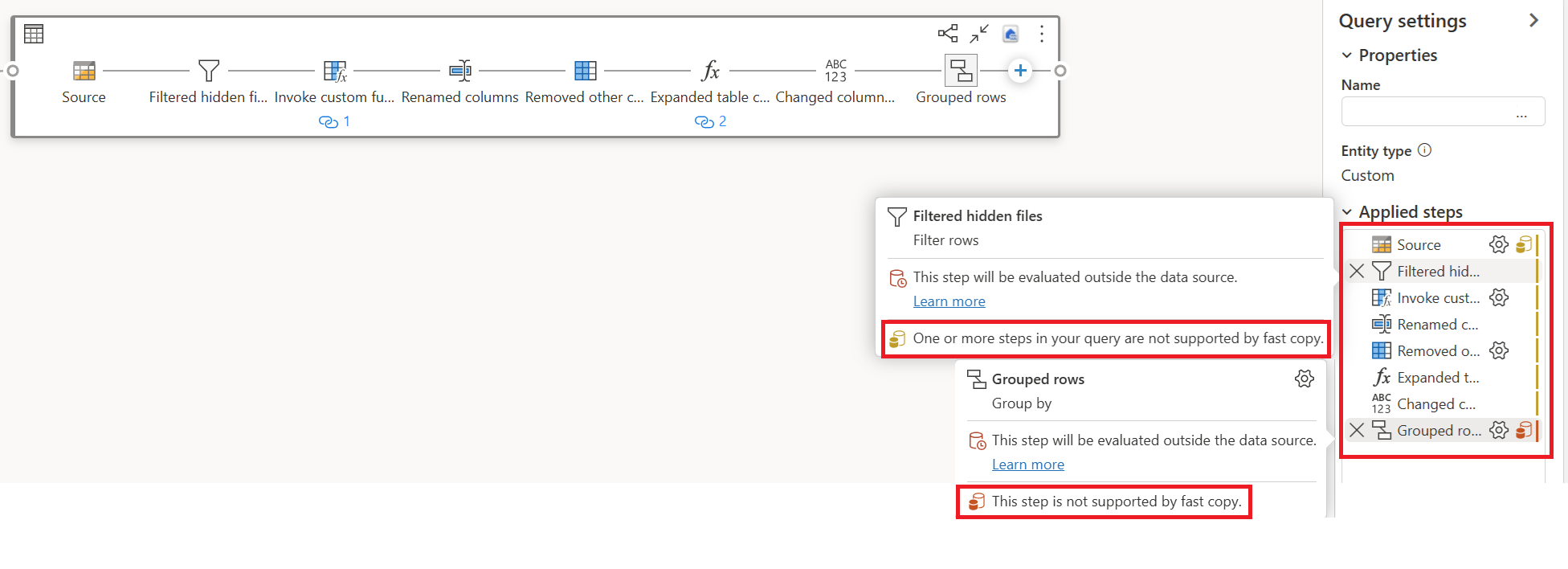
At this moment, if you directly publish and run your Dataflow Gen2, it will not use the Fast Copy engine to load your data as the picture below:
To use the Fast Copy engine and improve the performance of your Dataflow Gen2, you can split your query into two parts: data ingestion to staging and large-scale transformation with SQL DW compute, as following:
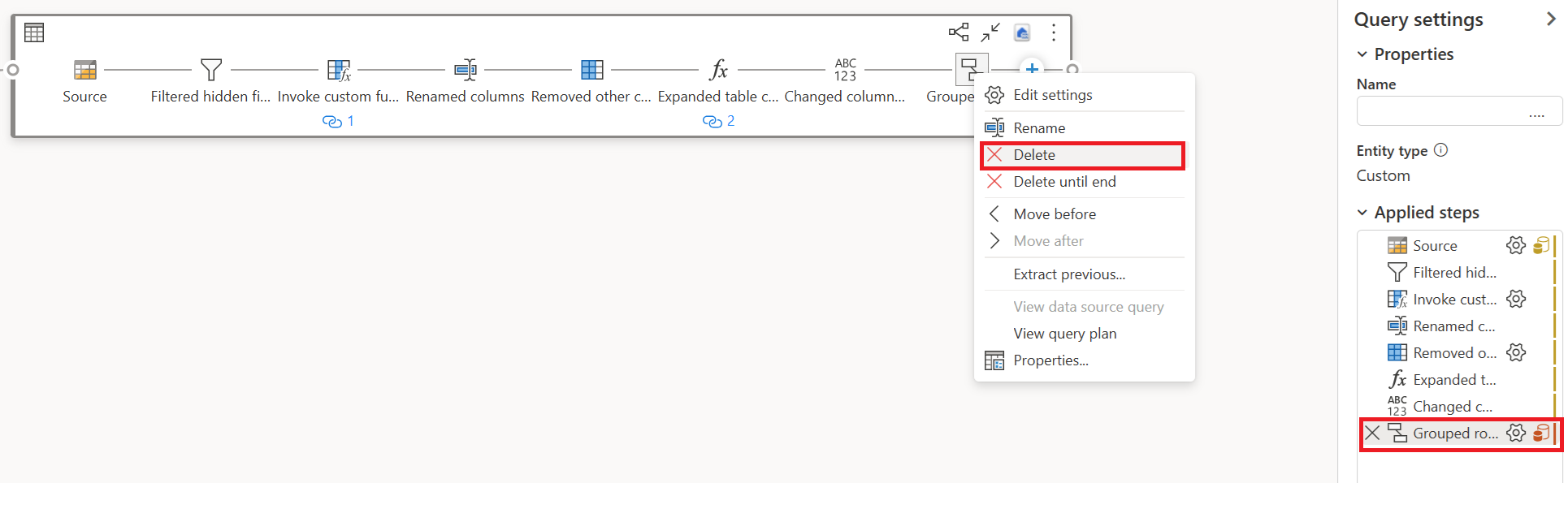
Remove the transformations (showing red) that aren't supported by Fast Copy, along with the destination (if defined).
The Fast Copy indicator now shows green for the remaining steps, meaning your first query can leverage Fast Copy for better performance.
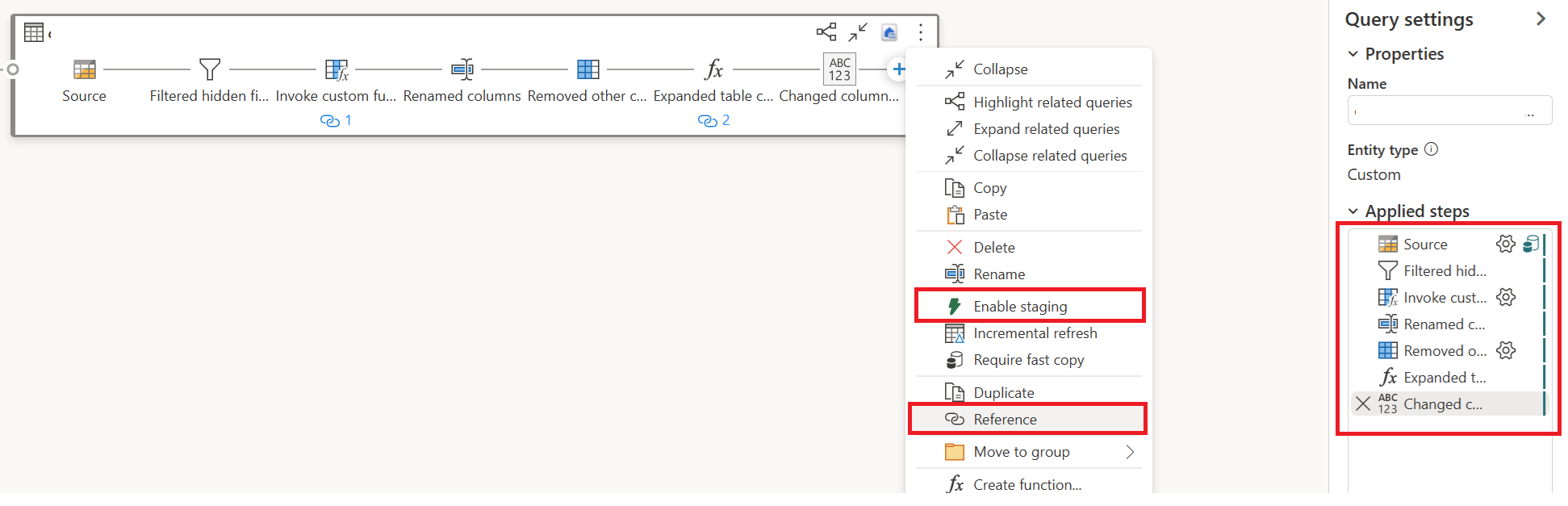
Select Action for your first query, then choose Enable Staging and Reference.
In a new referenced query, readd the "Group By" transformation and the destination (if applicable).
Publish and refresh your Dataflow Gen2. You'll now see two queries in your Dataflow Gen2, and the overall duration is largely reduced.
The first query ingests data into staging using Fast Copy.
The second query performs large-scale transformations using SQL DW compute.
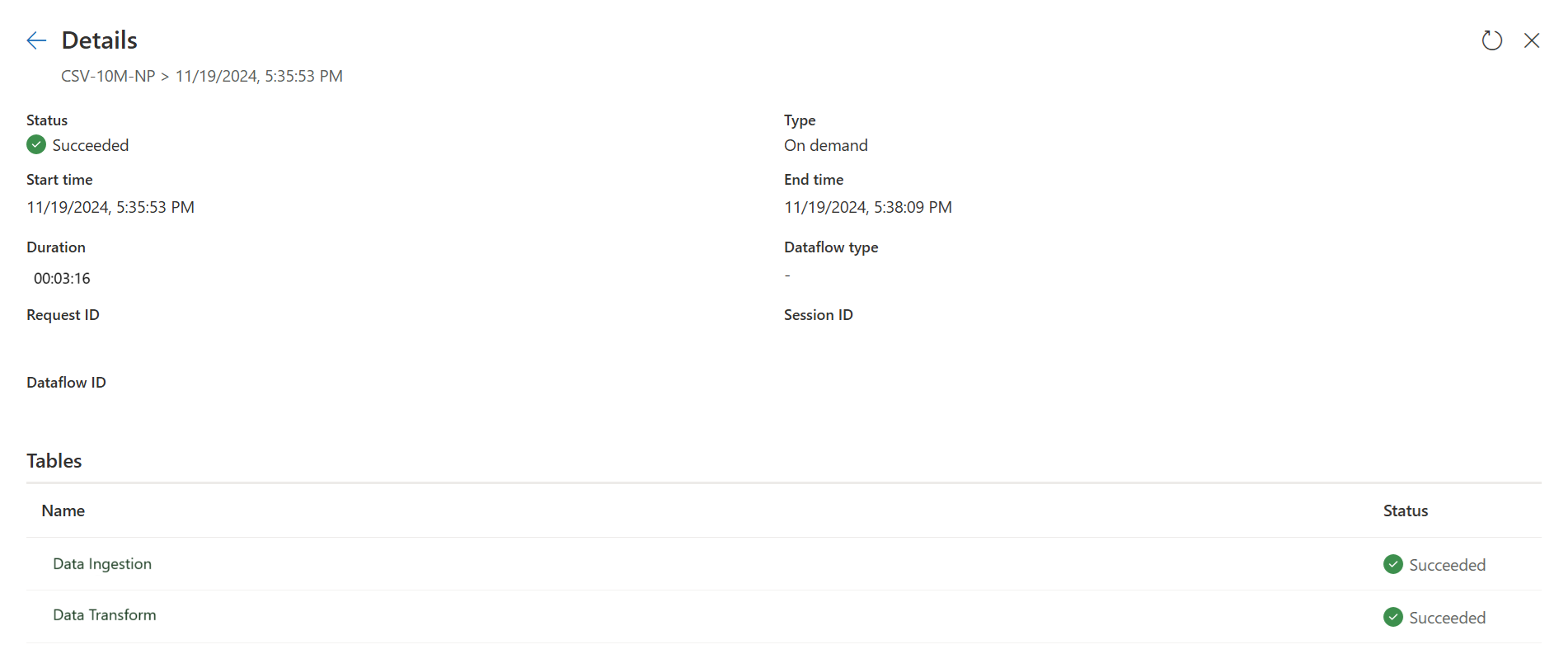
The first query:
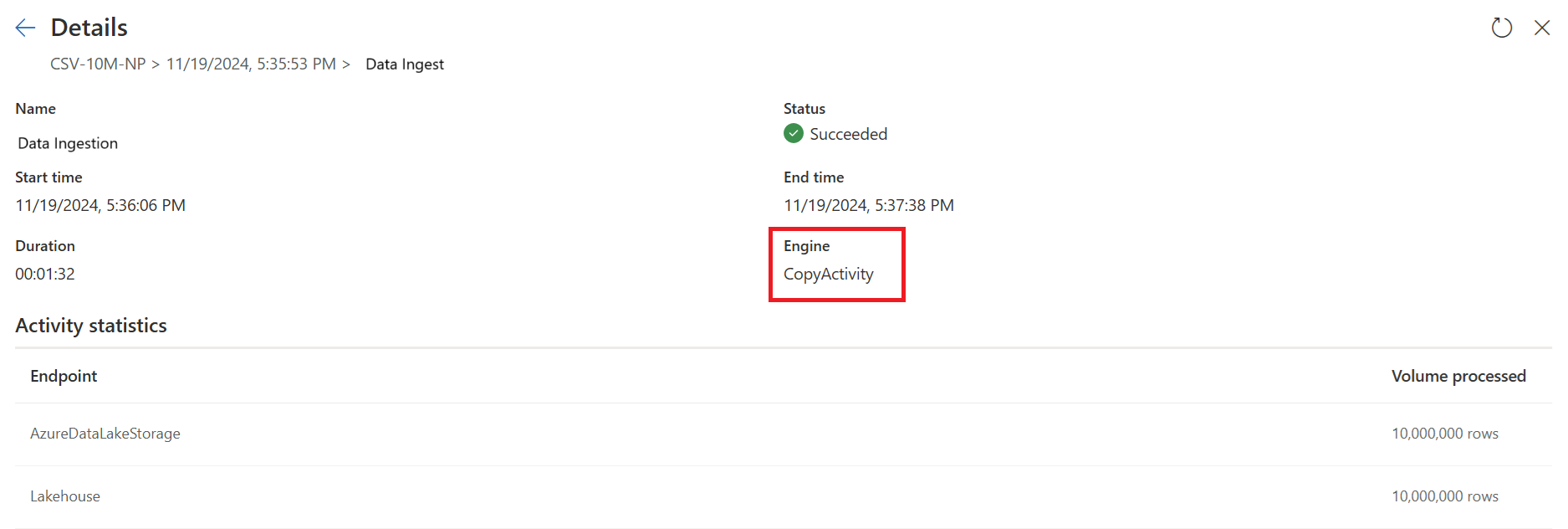
The second query:
Known limitations
- An on-premises data gateway version 3000.214.2 or newer is needed to support Fast Copy.
- The VNet gateway isn't supported.
- Writing data into an existing table in Lakehouse isn't supported.
- Fixed schema isn't supported.