vCore purchasing model - Azure SQL Database
Applies to: ![]() Azure SQL Database
Azure SQL Database
This article reviews the vCore purchasing model for Azure SQL Database.
Overview
A virtual core (vCore) represents a logical CPU and offers you the option to choose the physical characteristics of the hardware (for example, the number of cores, the memory, and the storage size). The vCore-based purchasing model gives you flexibility, control, transparency of individual resource consumption, and a straightforward way to translate on-premises workload requirements to the cloud. This model optimizes price, and allows you to choose compute, memory, and storage resources based on your workload needs.
In the vCore-based purchasing model, your costs depend on the choice and usage of:
- Service tier
- Hardware configuration
- Compute resources (the number of vCores and the amount of memory)
- Reserved database storage
- Actual backup storage
Important
Compute resources, I/O, and data and log storage are charged per database or elastic pool. Backup storage is charged per each database. For pricing details, see the Azure SQL Database pricing page.
Compare vCore and DTU purchasing models
The vCore purchasing model used by Azure SQL Database provides several benefits over the DTU-based purchasing model:
- Higher compute, memory, I/O, and storage limits.
- Choice of hardware configuration to better match compute and memory requirements of the workload.
- Pricing discounts for Azure Hybrid Benefit (AHB).
- Greater transparency in the hardware details that power the compute, that facilitates planning for migrations from on-premises deployments.
- Reserved instance pricing is only available for vCore purchasing model.
- Higher scaling granularity with multiple compute sizes available.
For help with choosing between the vCore and DTU purchasing models, see the differences between the vCore and DTU-based purchasing models.
Compute
The vCore-based purchasing model has a provisioned compute tier and a serverless compute tier. In the provisioned compute tier, the compute cost reflects the total compute capacity continuously provisioned for the application independent of workload activity. Choose the resource allocation that best suits your business needs based on vCore and memory requirements, then scale resources up and down as needed by your workload. In the serverless compute tier for Azure SQL Database, compute resources are autoscaled based on workload capacity and billed for the amount of compute used, per second.
To summarize:
- While the provisioned compute tier provides a specific amount of compute resources that are continuously provisioned independent of workload activity, the serverless compute tier autoscales compute resources based on workload activity.
- While the provisioned compute tier bills for the amount of compute provisioned at a fixed price per hour, the serverless compute tier bills for the amount of compute used, per second.
Regardless of the compute tier, three additional high availability secondary replicas are automatically allocated in the Business Critical service tier to provide high resiliency to failures and fast failovers. These additional replicas make the cost approximately 2.7 times higher than it is in the General Purpose service tier. Likewise, the higher storage cost per GB in the Business Critical service tier reflects the higher IO limits and lower latency of the local SSD storage.
In Hyperscale, customers control the number of additional high availability replicas from 0 to 4 to get the level of resiliency required by their applications while controlling costs.
For more information on compute in Azure SQL Database, see Compute resources (CPU and memory).
Resource limits
For vCore resource limits, review the available Hardware configurations, then review the resource limits for:
Data and log storage
The following factors affect the amount of storage used for data and log files, and apply to General Purpose and Business Critical tiers.
- Each compute size supports a configurable maximum data size, with a default of 32 GB.
- When you configure maximum data size, an extra 30 percent of billable storage is automatically added for the log file.
- In the General Purpose service tier,
tempdbuses local SSD storage, and this storage cost is included in the vCore price. - In the Business Critical service tier,
tempdbshares local SSD storage with data and log files, andtempdbstorage cost is included in the vCore price. - In the General Purpose and Business Critical tiers, you're charged for the maximum storage size configured for a database or elastic pool.
- For SQL Database, you can select any maximum data size between 1 GB and the supported storage size maximum, in 1-GB increments.
The following storage considerations apply to Hyperscale:
- Maximum data storage size is set to 128 TB and isn't configurable.
- You're charged only for the allocated data storage, not for maximum data storage.
- You aren't charged for log storage.
tempdbuses local SSD storage, and its cost is included in the vCore price. To monitor the current allocated and used data storage size in SQL Database, use the allocated_data_storage and storage Azure Monitor metrics respectively.
To monitor the current allocated and used storage size of individual data and log files in a database by using T-SQL, use the sys.database_files view and the FILEPROPERTY(... , 'SpaceUsed') function.
Tip
Under some circumstances, you might need to shrink a database to reclaim unused space. For more information, see Manage file space in Azure SQL Database.
Backup storage
Storage for database backups is allocated to support the point-in-time restore (PITR) and long-term retention (LTR) capabilities of SQL Database. This storage is separate from data and log file storage, and is billed separately.
- PITR: In General Purpose and Business Critical tiers, individual database backups are copied to Azure storage automatically. The storage size increases dynamically as new backups are created. The storage is used by full, differential, and transaction log backups. The storage consumption depends on the rate of change of the database and the retention period configured for backups. You can configure a separate retention period for each database between 1 and 35 days for SQL Database. A backup storage amount equal to the configured maximum data size is provided at no extra charge.
- LTR: You also can configure long-term retention of full backups for up to 10 years. If you set up an LTR policy, these backups are stored in Azure Blob storage automatically, but you can control how often the backups are copied. To meet different compliance requirements, you can select different retention periods for weekly, monthly, and/or yearly backups. The configuration you choose determines how much storage is used for LTR backups. For more information, see Long-term backup retention.
For backup storage in Hyperscale, see Automated backups for Hyperscale databases.
Service tiers
Service tier options in the vCore purchasing model include General Purpose, Business Critical, and Hyperscale. The service tier generally determines storage type and performance, high availability and disaster recovery options, and the availability of certain features such as In-Memory OLTP.
| Use case | General Purpose | Business Critical | Hyperscale |
|---|---|---|---|
| Best for | Most business workloads. Offers budget-oriented, balanced, and scalable compute and storage options. | Offers business applications the highest resilience to failures by using several high availability secondary replicas, and provides the highest I/O performance. | The widest variety of workloads, including those workloads with highly scalable storage and read-scale requirements. Offers higher resilience to failures by allowing configuration of more than one high availability secondary replica. |
| Compute size | 2 to 128 vCores | 2 to 128 vCores | 2 to 128 vCores |
| Storage type | Premium remote storage (per instance) | Super-fast local SSD storage (per instance) | Decoupled storage with local SSD cache (per compute replica) |
| Storage size | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 128 TB |
| IOPS | 320 IOPS per vCore with 16,000 maximum IOPS | 4,000 IOPS per vCore with 327,680 maximum IOPS | 327,680 IOPS with max local SSD Hyperscale is a multi-tiered architecture with caching at multiple levels. Effective IOPS depend on the workload. |
| Memory/vCore | 5.1 GB | 5.1 GB | 5.1 GB or 10.2 GB |
| Backups | A choice of geo-redundant, zone-redundant, or locally redundant backup storage, 1-35 day retention (default 7 days) Long term retention available up to 10 years |
A choice of geo-redundant, zone-redundant, or locally redundant backup storage, 1-35 day retention (default 7 days) Long term retention available up to 10 years |
A choice of locally redundant (LRS), zone-redundant (ZRS), or geo-redundant (GRS) storage 1-35 days (7 days by default) retention, with up to 10 years of long-term retention available |
| Availability | One replica, no read-scale replicas, zone-redundant high availability (HA) |
Three replicas, one read-scale replica, zone-redundant high availability (HA) |
zone-redundant high availability (HA) |
| Pricing/billing | vCore, reserved storage, and backup storage are charged. IOPS aren't charged. |
vCore, reserved storage, and backup storage are charged. IOPS aren't charged. |
vCore for each replica and used storage are charged. IOPS aren't charged. |
| Discount models | Reserved instances Azure Hybrid Benefit (not available on dev/test subscriptions) Enterprise and Pay-As-You-Go Dev/Test offer subscriptions |
Reserved instances Azure Hybrid Benefit (not available on dev/test subscriptions) Enterprise and Pay-As-You-Go Dev/Test offer subscriptions |
Azure Hybrid Benefit (not available on dev/test subscriptions) 1 Enterprise and Pay-As-You-Go Dev/Test offer subscriptions |
| In-memory OLTP tables | No | Yes | No |
1 Simplified pricing for SQL Database Hyperscale coming soon. Review the Hyperscale pricing blog for details.
For greater details, review resource limits for logical server, single databases, and pooled databases.
Note
For more information on the Service Level Agreement (SLA), see SLA for Azure SQL Database
General Purpose
The architectural model for the General Purpose service tier is based on a separation of compute and storage. This architectural model relies on the high availability and reliability of Azure Blob storage that transparently replicates database files and guarantees no data loss if underlying infrastructure failure happens.
The following figure shows four nodes in standard architectural model with the separated compute and storage layers.
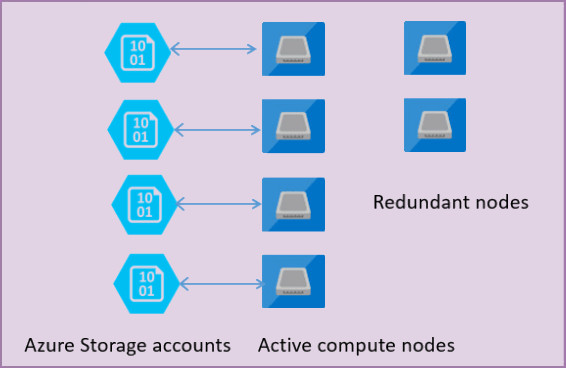
In the architectural model for the General Purpose service tier, there are two layers:
- A stateless compute layer that is running the
sqlservr.exeprocess and contains only transient and cached data (for example – plan cache, buffer pool, columnstore pool). This stateless node is operated by Azure Service Fabric that initializes process, controls health of the node, and performs failover to another place if necessary. - A stateful data layer with database files (.mdf/.ldf) that are stored in Azure Blob storage. Azure Blob storage guarantees that there's no data loss of any record that is placed in any database file. Azure Storage has built-in data availability/redundancy that ensures that every record in log file or page in data file is preserved even if the process crashes.
Whenever the database engine or operating system is upgraded, some part of underlying infrastructure fails, or if some critical issue is detected in the sqlservr.exe process, Azure Service Fabric moves the stateless process to another stateless compute node. There's a set of spare nodes that is waiting to run new compute service if a failover of the primary node happens in order to minimize failover time. Data in Azure storage layer isn't affected, and data/log files are attached to newly initialized process. This process guarantees 99.99% availability by default and 99.995% availability when zone redundancy is enabled. There might be some performance impacts to heavy workloads that are in-flight due to transition time and the fact the new node starts with cold cache.
When to choose this service tier
The General Purpose service tier is the default service tier in Azure SQL Database designed for most of generic workloads. If you need a fully managed database engine with a default SLA and storage latency between 5 ms and 10 ms, the General Purpose tier is the option for you.
Business Critical
The Business Critical service tier model is based on a cluster of database engine processes. This architectural model relies on a quorum of database engine nodes to minimize performance impacts to your workload, even during maintenance activities. Upgrades and patches of the underlying operating system, drivers, and the database engine occur transparently, with minimal down-time for end users.
In the Business Critical model, compute and storage is integrated on each node. Replication of data between database engine processes on each node of a four-node cluster achieves high availability, with each node using locally attached SSD as data storage. The following diagram shows how the Business Critical service tier organizes a cluster of database engine nodes in availability group replicas.

Both the database engine process and underlying .mdf/.ldf files are placed on the same node with locally attached SSD storage, providing low latency to your workload. High availability is implemented using technology similar to SQL Server Always On availability groups. Every database is a cluster of database nodes with one primary replica that is accessible for customer workloads, and three secondary replicas containing copies of data. The primary replica constantly pushes changes to the secondary replicas in order to ensure the data is available on secondary replicas if the primary fails for any reason. Failover is handled by the Service Fabric and the database engine – one secondary replica becomes the primary, and a new secondary replica is created to ensure there are enough nodes in the cluster. The workload is automatically redirected to the new primary replica.
In addition, the Business Critical cluster has a built-in Read Scale-Out capability that provides a free-of charge read-only replica used to run read-only queries (such as reports) that won't affect the performance of the workload on your primary replica.
When to choose this service tier
The Business Critical service tier is designed for applications that require low-latency responses from the underlying SSD storage (1-2 ms in average), faster recovery if the underlying infrastructure fails, or need to off-load reports, analytics, and read-only queries to the free of charge readable secondary replica of the primary database.
The key reasons why you should choose Business Critical service tier instead of General Purpose tier are:
- Low I/O latency requirements – workloads that need a consistently fast response from the storage layer (1-2 milliseconds in average) should use Business Critical tier.
- Workload with reporting and analytic queries where a single free-of-charge secondary read-only replica is sufficient.
- Higher resiliency and faster recovery from failures. In case there's system failure, the database on primary instance is disabled and one of the secondary replicas immediately becomes the new read-write primary database, ready to process queries.
- Advanced data corruption protection. Since the Business Critical tier uses databases replicas behind the scenes, the service uses automatic page repair available with mirroring and availability groups to help mitigate data corruption. If a replica can't read a page due to a data integrity issue, a fresh copy of the page is retrieved from another replica, replacing the unreadable page without data loss or customer downtime. This functionality is available in the General Purpose tier if the database has geo-secondary replica.
- Higher availability - The Business Critical tier in a multi-availability zone configuration provides resiliency to zonal failures and a higher availability SLA.
- Fast geo-recovery - When active geo-replication is configured, the Business Critical tier has a guaranteed Recovery Point Objective (RPO) of 5 seconds and Recovery Time Objective (RTO) of 30 seconds for 100% of deployed hours.
Hyperscale
The Hyperscale service tier is suitable for all workload types. Its cloud native architecture provides independently scalable compute and storage to support the widest variety of traditional and modern applications. Compute and storage resources in Hyperscale substantially exceed the resources available in the General Purpose and Business Critical tiers.
To learn more, review Hyperscale service tier for Azure SQL Database.
When to choose this service tier
The Hyperscale service tier removes many of the practical limits traditionally seen in cloud databases. Where most other databases are limited by the resources available in a single node, databases in the Hyperscale service tier have no such limits. With its flexible storage architecture, a Hyperscale database grows as needed - and you're billed only for the storage capacity you use.
Besides its advanced scaling capabilities, Hyperscale is a great option for any workload, not just for large databases. With Hyperscale, you can:
- Achieve high resiliency and fast failure recovery while controlling cost, by choosing the number of high availability replicas from 0 to 4.
- Improve high availability by enabling zone redundancy for compute and storage.
- Achieve low I/O latency (1-2 milliseconds on average) for the frequently accessed part of your database. For smaller databases, this might apply to the entire database.
- Implement a large variety of read scale-out scenarios with named replicas.
- Take advantage of fast scaling, without waiting for data to be copied to local storage on new nodes.
- Enjoy zero-impact continuous database backup and fast restore.
- Support business continuity requirements by using failover groups and geo-replication.
Hardware configuration
Common hardware configurations in the vCore model include standard-series (Gen5), Fsv2-series, and DC-series. Hyperscale also provides an option for premium-series and premium-series memory optimized hardware. Hardware configuration defines compute and memory limits and other characteristics that affect workload performance.
Certain hardware configurations such as standard-series (Gen5) can use more than one type of processor (CPU), as described in Compute resources (CPU and memory). While a given database or elastic pool tends to stay on the hardware with the same CPU type for a long time (commonly for multiple months), there are certain events that can cause a database or pool to be moved to hardware that uses a different CPU type.
A database or pool could be moved for a variety of scenarios, including but not limited to when:
- The service objective is changed
- The current infrastructure in a datacenter is approaching capacity limits
- The currently used hardware is being decommissioned due to its end of life
- Zone-redundant configuration is enabled, moving to a different hardware due to available capacity
For some workloads, a move to a different CPU type can change performance. SQL Database configures hardware with the goal to provide predictable workload performance even if CPU type changes, keeping performance changes within a narrow band. However, across the wide spectrum of customer workloads in SQL Database, and as new types of CPUs become available, it's occasionally possible to see more noticeable changes in performance, if a database or pool moves to a different CPU type.
Regardless of CPU type used, resource limits for a database or elastic pool (such as the number of cores, memory, max data IOPS, max log rate, and max concurrent workers) remain the same as long as the database stays on the same service objective.
Compute resources (CPU and memory)
The following table compares compute resources in different hardware configurations and compute tiers:
| Hardware configuration | CPU | Memory |
|---|---|---|
| Standard-series (Gen5) | Provisioned compute - Intel® E5-2673 v4 (Broadwell) 2.3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2.5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milan) processors - Provision up to 128 vCores (hyper-threaded) Serverless compute - Intel® E5-2673 v4 (Broadwell) 2.3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2.5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milan) processors - Autoscale up to 80 vCores (hyper-threaded) - The memory-to-vCore ratio dynamically adapts to memory and CPU usage based on workload demand and can be as high as 24 GB per vCore. For example, at a given point in time a workload might use and be billed for 240-GB memory and only 10 vCores. |
Provisioned compute - 5.1 GB per vCore - Provision up to 625 GB Serverless compute - Autoscale up to 24 GB per vCore - Autoscale up to 240 GB max |
| Fsv2-series | - Intel® 8168 (Skylake) processors - Featuring a sustained all core turbo clock speed of 3.4 GHz and a maximum single core turbo clock speed of 3.7 GHz. - Provision up to 72 vCores (hyper-threaded) |
- 1.9 GB per vCore - Provision up to 136 GB |
| DC-series | - Intel® Xeon® E-2288G processors - Featuring Intel Software Guard Extension (Intel SGX) - Provision up to 8 vCores (physical) |
4.5 GB per vCore |
* In the sys.dm_user_db_resource_governance dynamic management view, hardware generation for databases using Intel® SP-8160 (Skylake) processors appears as Gen6, hardware generation for databases using Intel® 8272CL (Cascade Lake) appears as Gen7, and hardware generation for databases using Intel® Xeon® Platinum 8370C (Ice Lake) or AMD® EPYC® 7763v (Milan) appear as Gen8. For a given compute size and hardware configuration, resource limits are the same regardless of CPU type (Intel Broadwell, Skylake, Ice Lake, Cascade Lake, or AMD Milan).
For more information, see resource limits for single databases and elastic pools.
For Hyperscale database compute resources and specification, see Hyperscale compute resources.
Standard-series (Gen5)
- Standard-series (Gen5) hardware provides balanced compute and memory resources, and is suitable for most database workloads.
Standard-series (Gen5) hardware is available in all public regions worldwide.
Hyperscale premium-series
- Premium-series hardware options use the latest CPU and memory technology from Intel and AMD. Premium-series provides a boost to compute performance relative to standard-series hardware.
- Premium-series option offers faster CPU performance compared to Standard-series and a higher number of maximum vCores.
- Premium-series memory optimized option offers double the amount of memory relative to Standard-series.
- Standard-series, premium-series, and premium-series memory optimized are available for Hyperscale elastic pools.
For more information, see the Hyperscale premium series blog announcement.
For regions available, see Hyperscale premium-series availability.
Fsv2-series
- Fsv2-series is a compute optimized hardware configuration delivering low CPU latency and high clock speed for the most CPU demanding workloads. Similar to Hyperscale premium-series hardware configurations, Fsv2-series is powered by the latest CPU and memory technology from Intel and AMD, allowing customers to take advantage of the latest hardware while using databases and elastic pools in the General Purpose service tier.
- Depending on the workload, Fsv2-series can deliver more CPU performance per vCore than other types of hardware. For example, the 72 vCore Fsv2 compute size can provide more CPU performance than 80 vCores on Standard-series (Gen5), at lower cost.
- Fsv2 provides less memory and
tempdbper vCore than other hardware, so workloads sensitive to those limits might perform better on standard-series (Gen5).
Fsv2-series in only supported in the General Purpose tier. For regions where Fsv2-series is available, see Fsv2-series availability.
DC-series
- DC-series hardware uses Intel processors with Software Guard Extensions (Intel SGX) technology.
- DC-series is required for Always Encrypted with secure enclaves workloads that require stronger security protection of hardware enclaves, compared to Virtualization-based Security (VBS) enclaves.
- DC-series is designed for workloads that process sensitive data and demand confidential query processing capabilities, provided by Always Encrypted with secure enclaves.
- DC-series hardware provides balanced compute and memory resources.
DC-series is only supported for Provisioned compute (Serverless isn't supported) and doesn't support zone redundancy. For regions where DC-series is available, see DC-series availability.
Azure offer types supported by DC-series
To create databases or elastic pools on DC-series hardware, the subscription must be a paid offer type including Pay-As-You-Go or Enterprise Agreement (EA). For a complete list of Azure offer types supported by DC-series, see current offers without spending limits.
Select hardware configuration
You can select hardware configuration for a database or elastic pool in SQL Database at the time of creation. You can also change hardware configuration of an existing database or elastic pool.
To select a hardware configuration when creating a SQL Database or pool
For detailed information, see Create a SQL Database.
On the Basics tab, select the Configure database link in the Compute + storage section, and then select the Change configuration link:

Select the desired hardware configuration:

To change hardware configuration of an existing SQL Database or pool
For a database, on the Overview page, select the Pricing tier link:

For a pool, on the Overview page, select Configure.
Follow the steps to change configuration, and select hardware configuration as described in the previous steps.
Hardware availability
For information on previous generation hardware, see Previous generation hardware availability.
Standard-series (Gen5)
Standard-series (Gen5) hardware is available in all public regions worldwide.
Hyperscale premium-series
Hyperscale service tier premium-series and premium-series memory optimized hardware is available for single databases and elastic pools in the following regions:
- Australia East **
- Australia Southeast
- Brazil South **,*
- Canada Central **
- Canada East
- East Asia
- Europe North **
- Europe West **
- France Central
- Germany West Central
- India Central
- India South
- Japan East **
- Japan West
- Southeast Asia **
- Switzerland North
- Sweden Central **,*
- UK South **
- UK West *
- US Central **
- US East **
- US East 2 **
- US North Central
- US South Central
- US West Central
- US West 1
- US West 2 **
- US West 3 **
* Premium-series memory optimized hardware is not currently available.
** Includes support for zone redundancy.
Fsv2-series
Fsv2-series is available in the following regions:
- Australia Central
- Australia Central 2
- Australia East
- Australia Southeast
- Brazil South
- Canada Central
- East Asia
- Europe North
- Europe West
- France Central
- India Central
- Korea Central
- Korea South
- South Africa North
- Southeast Asia
- UK South
- UK West
- US East
- US West 2
DC-series
DC-series is available in the following regions:
- Canada Central
- Europe West
- Europe North
- Southeast Asia
- UK South
- US West
- US East
If you need DC-series in a currently unsupported region, submit a support request. On the Basics page, provide the following:
- For Issue type, select Technical.
- Provide the desired subscription for the hardware. Select Next.
- For Service type, select SQL Database.
- For Resource, select General question.
- For Summary, provide the desired hardware availability and region.
- For Problem type, select Security, Private and Compliance.
- For Problem subtype, select Always Encrypted.

Previous generation hardware
Gen4
Gen4 hardware has been retired and isn't available for provisioning, upscaling, or downscaling. Migrate your database to a supported hardware generation for a wider range of vCore and storage scalability, accelerated networking, best IO performance, and minimal latency. Review hardware options for single databases and hardware options for elastic pools. For more information, see Support has ended for Gen 4 hardware on Azure SQL Database.