Kubernetes architecture is based on two layers: The control plane and one or more nodes in node pools. This article describes and compares how Amazon Elastic Kubernetes Service (Amazon EKS) and Azure Kubernetes Service (AKS) manage agent or worker nodes.
Note
This article is part of a series of articles that helps professionals who are familiar with Amazon EKS to understand Azure Kubernetes Service (AKS).
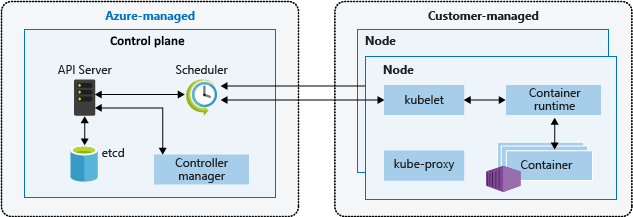
In both Amazon EKS and AKS, the cloud platform provides and manages the control plane layer, and the customer manages the node layer. The following diagram shows the relationship between the control plane and nodes in AKS Kubernetes architecture.
Amazon EKS managed node groups
Amazon EKS managed node groups automate the provisioning and lifecycle management of Amazon Elastic Compute Cloud (EC2) worker nodes for Amazon EKS clusters. Amazon Web Services (AWS) users can use the eksctl command-line utility to create, update, or terminate nodes for their EKS clusters. Node updates and terminations automatically cordon and drain nodes to ensure that applications remain available.
Every managed node is provisioned as part of an Amazon EC2 Auto Scaling group that Amazon EKS operates and controls. The Kubernetes cluster autoscaler automatically adjusts the number of worker nodes in a cluster when pods fail or are rescheduled onto other nodes. Each node group can be configured to run across multiple Availability Zones within a region.
For more information about Amazon EKS managed nodes, see Creating a managed node group and Updating a managed node group.
You can also run Kubernetes pods on AWS Fargate. Fargate provides on-demand, right-sized compute capacity for containers. For more information on how to use Fargate with Amazon EKS, see AWS Fargate.
Karpenter
Karpenter is an open-source project designed to enhance node lifecycle management within Kubernetes clusters. It automates provisioning and deprovisioning of nodes based on the specific scheduling needs of pods, allowing efficient scaling and cost optimization. Its main functions are:
- Monitor pods that the Kubernetes scheduler cannot schedule due to resource constraints.
- Evaluate the scheduling requirements (resource requests, node selectors, affinities, tolerations, etc.) of the unschedulable pods.
- Provision new nodes that meet the requirements of those pods.
- Remove nodes when they are no longer needed.
With Karpenter, you define NodePools with constraints on node provisioning like taints, labels, requirements (instance types, zones, etc.), and limits on total provisioned resources. When deploying workloads, you specify various scheduling constraints in the pod specifications like resource requests/limits, node selectors, node/pod affinities, tolerations, and topology spread constraints. Karpenter then provisions right sized nodes based on these specifications.
Before the launch of Karpenter, Amazon EKS users relied primarily on Amazon EC2 Auto Scaling groups and the Kubernetes Cluster Autoscaler (CAS) to dynamically adjust the compute capacity of their clusters. You don't need to create dozens of node groups to achieve the flexibility and diversity you get with Karpenter. Unlike the Kubernetes Cluster Autoscaler, Karpenter is not as tightly coupled to Kubernetes versions and doesn’t require you to jump between AWS and Kubernetes APIs.
Karpenter consolidates instance orchestration responsibilities within a single system, which is simpler, more stable and cluster-aware. Karpenter was designed to overcome some of the challenges presented by Cluster Autoscaler by providing simplified ways to:
- Provision nodes based on workload requirements.
- Create diverse node configurations by instance type, using flexible NodePool options. Instead of managing many specific custom node groups, Karpenter could let you manage diverse workload capacity with a single, flexible NodePool.
- Achieve improved pod scheduling at scale by quickly launching nodes and scheduling pods.
For information and documentation on using Karpenter, visit the karpenter.sh site.
Karpenter brings scaling management closer to Kubernetes native APIs than do Auto Scaling Groups (ASGs) and Managed Node Groups (MNGs). ASGs and MNGs are AWS-native abstractions where scaling is triggered based on AWS level metrics, such as EC2 CPU load. Cluster Autoscaler bridges the Kubernetes abstractions into AWS abstractions, but loses some flexibility because of that, such as scheduling for a specific availability zone.
Karpenter removes a layer of AWS abstraction to bring some of the flexibility directly into Kubernetes. Karpenter is best used for clusters with workloads that encounter periods of high, spiky demand or have diverse compute requirements. MNGs and ASGs are good for clusters running workloads that tend to be more static and consistent. You can use a mix of dynamically and statically managed nodes, depending on your requirements.
Kata Containers
Kata Containers is an open-source project that provides a secure container runtime which combines the lightweight nature of containers with the security benefits of virtual machines. It addresses the need for stronger workload isolation and security by booting each container with a different guest operating system, unlike traditional containers that share the same Linux Kernel among workloads. Kata Containers run containers in an OCI-compliant virtual machine, providing strict isolation between containers on the same host machine. Kata Containers provide the following features:
- Enhanced workload isolation: Each container runs in its own lightweight VM, ensuring isolation at the hardware level.
- Improved security: The use of VM technology provides an additional layer of security, reducing the risk of container breakouts.
- Compatibility with industry standards: Kata Containers integrate with industry-standard tools such as the OCI container format and Kubernetes CRI interface.
- Support for multiple architectures and hypervisors: Kata Containers support AMD64 and ARM architectures and can be used with hypervisors like Cloud-Hypervisor and Firecracker.
- Easy deployment and management: Kata Containers abstract away the complexity of orchestrating workloads by leveraging the Kubernetes orchestration system.
AWS customers can set up and run Kata Containers on AWS by configuring an Amazon Elastic Kubernetes Service (EKS) cluster to use Firecracker, an open source virtualization technology developed by Amazon to create and manage secure, multi-tenant container and function-based services. Firecracker enables customers to deploy workloads in lightweight virtual machines, called microVMs, which provide enhanced security and workload isolation over traditional virtual machines, while enabling the speed and resource efficiency of containers. Enabling Kata Containers on AWS EKS requires a series of manual steps described in Enhancing Kubernetes workload isolation and security using Kata Containers.
Dedicated Hosts
Running Containers on Amazon EC2 Dedicated Hosts with AWS EKS
When using Amazon Elastic Kubernetes Service (EKS) to deploy and run containers, it is possible to run them on Amazon EC2 dedicated hosts. However, it is important to note that this feature is only available for self-managed node groups. This means that customers need to manually create a launch template, Auto Scaling Groups, and register them with the EKS cluster. The creation process for these resources is the same as for general EC2 auto scaling.
For more detailed information on running containers on EC2 dedicated hosts with AWS EKS, please refer to the following documentation:
- Amazon EKS nodes
- Dedicated Hosts - Dedicated Hosts restrictions
- Work with Dedicated Hosts - Allocate Dedicated Hosts
- Work with Dedicated Hosts - Purchase Dedicated Host Reservations
- Work with Dedicated Hosts - Auto-placement
AKS nodes and node pools
Creating an AKS cluster automatically creates and configures a control plane, which provides core Kubernetes services and application workload orchestration. The Azure platform provides the AKS control plane at no cost as a managed Azure resource. The control plane and its resources exist only in the region where you created the cluster.
The nodes, also called agent nodes or worker nodes, host the workloads and applications. In AKS, customers fully manage and pay for the agent nodes attached to the AKS cluster.
To run applications and supporting services, an AKS cluster needs at least one node: An Azure virtual machine (VM) to run the Kubernetes node components and container runtime. Every AKS cluster must contain at least one system node pool with at least one node.
AKS groups nodes of the same configuration into node pools of VMs that run AKS workloads. System node pools serve the primary purpose of hosting critical system pods such as CoreDNS. User node pools serve the primary purpose of hosting workload pods. If you want to have only one node pool in your AKS cluster, for example in a development environment, you can schedule application pods on the system node pool.
You can also create multiple user node pools to segregate different workloads on different nodes to avoid the noisy neighbor problem, or to support applications with different compute or storage demands.
Every agent node of a system or user node pool is a VM provisioned as part of Azure Virtual Machine Scale Sets and managed by the AKS cluster. For more information, see Nodes and node pools.
You can define the initial number and size for worker nodes when you create an AKS cluster, or when you add new nodes and node pools to an existing AKS cluster. If you don't specify a VM size, the default size is Standard_D2s_v3 for Windows node pools and Standard_DS2_v2 for Linux node pools.
Important
To provide better latency for intra-node calls and communications with platform services, select a VM series that supports Accelerated Networking.
Node pool creation
You can add a node pool to a new or existing AKS cluster by using the Azure portal, Azure CLI, the AKS REST API, or infrastructure as code (IaC) tools such as Bicep, Azure Resource Manager templates, or Terraform. For more information on how to add node pools to an existing AKS cluster, see Create and manage multiple node pools for a cluster in Azure Kubernetes Service (AKS).
When you create a new node pool, the associated virtual machine scale set is created in the node resource group, an Azure resource group that contains all the infrastructure resources for the AKS cluster. These resources include the Kubernetes nodes, virtual networking resources, managed identities, and storage.
By default, the node resource group has a name like MC_<resourcegroupname>_<clustername>_<location>. AKS automatically deletes the node resource group when deleting a cluster, so you should use this resource group only for resources that share the cluster's lifecycle.
Add a node pool
The following code example uses the Azure CLI az aks nodepool add command to add a node pool named mynodepool with three nodes to an existing AKS cluster called myAKSCluster in the myResourceGroup resource group.
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--node-vm-size Standard_D8ds_v4 \
--name mynodepool \
--node-count 3
Spot node pools
A spot node pool is a node pool backed by a spot virtual machine scale set. Using spot virtual machines for nodes with your AKS cluster takes advantage of unutilized Azure capacity at a significant cost savings. The amount of available unutilized capacity varies based on many factors, including node size, region, and time of day.
When deploying a spot node pool, Azure allocates the spot nodes if there's capacity available. But there's no service-level agreement (SLA) for the spot nodes. A spot scale set that backs the spot node pool is deployed in a single fault domain and offers no high-availability guarantees. When Azure needs the capacity back, the Azure infrastructure evicts spot nodes, and you get at most a 30-second notice before eviction. Be aware that a spot node pool can't be the cluster's default node pool. A spot node pool can be used only for a secondary pool.
Spot nodes are for workloads that can handle interruptions, early terminations, or evictions. For example, batch processing jobs, development and testing environments, and large compute workloads are good candidates for scheduling on a spot node pool. For more details, see the spot instance's limitations.
The following az aks nodepool add command adds a spot node pool to an existing cluster with autoscaling enabled.
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name myspotnodepool \
--node-vm-size Standard_D8ds_v4 \
--priority Spot \
--eviction-policy Delete \
--spot-max-price -1 \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--no-wait
For more information on spot node pools, see Add a spot node pool to an Azure Kubernetes Service (AKS) cluster.
Ephemeral OS disks
By default, Azure automatically replicates the VM operating system (OS) disk to Azure Storage to avoid data loss if the VM needs to be relocated to another host. But because containers aren't designed to persist local state, keeping the OS disk in storage offers limited value for AKS. There are some drawbacks, such as slower node provisioning and higher read/write latency.
By contrast, ephemeral OS disks are stored only on the host machine, like a temporary disk, and provide lower read/write latency and faster node scaling and cluster upgrades. Like a temporary disk, an ephemeral OS disk is included in the VM price, so you incur no extra storage costs.
Important
If you don't explicitly request managed disks for the OS, AKS defaults to an ephemeral OS if possible for a given node pool configuration.
To use ephemeral OS, the OS disk must fit in the VM cache. Azure VM documentation shows VM cache size in parentheses next to IO throughput as cache size in gibibytes (GiB).
For example, the AKS default Standard_DS2_v2 VM size with the default 100-GB OS disk size supports ephemeral OS, but has only 86 GB of cache size. This configuration defaults to managed disk if you don't explicitly specify otherwise. If you explicitly request ephemeral OS for this size, you get a validation error.
If you request the same Standard_DS2_v2 VM with a 60-GB OS disk, you get ephemeral OS by default. The requested 60-GB OS size is smaller than the maximum 86-GB cache size.
Standard_D8s_v3 with a 100-GB OS disk supports ephemeral OS and has 200 GB of cache space. If a user doesn't specify the OS disk type, a node pool gets ephemeral OS by default.
The following az aks nodepool add command shows how to add a new node pool to an existing cluster with an ephemeral OS disk. The --node-osdisk-type parameter sets the OS disk type to Ephemeral, and the --node-osdisk-size parameter defines the OS disk size.
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name mynewnodepool \
--node-vm-size Standard_D8ds_v4 \
--node-osdisk-type Ephemeral \
--node-osdisk-size 48
For more information about ephemeral OS disks, see Ephemeral OS.
Virtual Machines Node Pools in Azure Kubernetes Service (AKS)
Every managed node group in EKS is backed by an Amazon EC2 Auto Scaling group, which is managed by Amazon EKS. This integration allows EKS to automatically handle the provisioning and scaling of EC2 instances within the node group. While Auto Scaling groups can be configured to support multiple EC2 instance types, they do not provide the ability to specify how many nodes to create or scale for each instance type. Instead, EKS manages the scaling of the node group based on the desired configuration and policies defined by the user. This ensures a simplified and automated management process for the node group while providing flexibility in selecting the EC2 instance types that suit your workload requirements. However, AWS customers can launch self-managed Amazon Linux nodes with eksctl or the AWS Management Console.
With Virtual Machines node pools, Azure Kubernetes Service (AKS) manages the provisioning and bootstrapping of each agent node. For Virtual Machine Scale Sets node pools, AKS manages the model of the Virtual Machine Scale Sets and uses it to achieve consistency across all agent nodes in the node pool. Instead, Virtual Machines node pools enable you to orchestrate your cluster with virtual machines that best fit your individual workloads and specify how many nodes to create or scale for each virtual machine size.
A node pool consists of a set of virtual machines, with different sizes (SKUs) designated to support different types of workloads. These virtual machine sizes, referred to as SKUs, are categorized into different families that are optimized for specific purposes. For more information on VM SKUs, see the VM SKUs overview.
To enable scaling of multiple virtual machine sizes, the Virtual Machines node pool type uses a ScaleProfile that configures how the node pool scales, specifically the desired list of virtual machine size and count. A ManualScaleProfile is a scale profile that specifies the desired virtual machine size and count. Only one virtual machine size is allowed in a ManualScaleProfile. You need to create a separate ManualScaleProfile for each virtual machine size in your node pool.
When you create a new Virtual Machines node pool, you need at least one ManualScaleProfile in the ScaleProfile. Multiple manual scale profiles can be created for a single Virtual Machines node pool.
Advantages of Virtual Machines node pools include:
- Flexibility: Node specifications can be updated to suit your workloads and needs.
- Fine-tuned control: Single node-level controls allow specifying and mixing nodes of different specs to improve consistency.
- Efficiency: You can reduce the node footprint for your cluster, simplifying your operational requirements.
Virtual Machines node pools provide a better experience for dynamic workloads and high availability requirements. They allow you to set up multiple virtual machines of the same family in one node pool, with your workload automatically scheduled on the available resources you configure.
The following table compares Virtual Machines node pools with standard Scale Set node pools.
| Node pool type | Capabilities |
|---|---|
| Virtual Machines node pool | You can add, remove, or update nodes in a node pool. Virtual machine types can be any virtual machine of the same family type (e.g., D-series, A-Series, etc.). |
| Virtual Machine Scale Set based node pool | You can add or remove nodes of the same size and type in a node pool. If you add a new virtual machine size to the cluster, you need to create a new node pool. |
Virtual machine node pools have the following limitations:
- Cluster autoscaler is not supported.
- InfiniBand is not available.
- Windows node pools are not supported.
- This feature is not available in the Azure portal. Use Azure CLI or REST APIs to perform CRUD operations or manage the pool.
- Node pool snapshot is not supported.
- All VM sizes selected in a node pool must be from the same virtual machine family. For example, you cannot mix an N-Series virtual machine type with a D-Series virtual machine type in the same node pool.
- Virtual Machines node pools allow up to five different virtual machine sizes per node pool.
Virtual nodes
You can use virtual nodes to quickly scale out application workloads in an AKS cluster. Virtual nodes give you quick pod provisioning, and you only pay per second for execution time. You don't need to wait for the cluster autoscaler to deploy new worker nodes to run more pod replicas. Virtual nodes are supported only with Linux pods and nodes. The virtual nodes add-on for AKS is based on the open-source Virtual Kubelet project.
Virtual node functionality depends on Azure Container Instances. For more information about virtual nodes, see Create and configure an Azure Kubernetes Services (AKS) cluster to use virtual nodes.
Taints, labels, and tags
When you create a node pool, you can add Kubernetes taints and labels, and Azure tags, to that node pool. When you add a taint, label, or tag, all nodes within that node pool get that taint, label, or tag.
To create a node pool with a taint, you can use the az aks nodepool add command with the --node-taints parameter. To label the nodes in a node pool, you can use the --labels parameter and specify a list of labels, as shown in the following code:
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name mynodepool \
--node-vm-size Standard_NC6 \
--node-taints sku=gpu:NoSchedule \
--labels dept=IT costcenter=9999
For more information, see Specify a taint, label, or tag for a node pool.
Reserved system labels
Amazon EKS adds automated Kubernetes labels to all nodes in a managed node group like eks.amazonaws.com/capacityType, which specifies the capacity type. AKS also automatically adds system labels to agent nodes.
The following prefixes are reserved for AKS use and can't be used for any node:
kubernetes.azure.com/kubernetes.io/
For other reserved prefixes, see Kubernetes well-known labels, annotations, and taints.
The following table lists labels that are reserved for AKS use and can't be used for any node. In the table, the Virtual node usage column specifies whether the label is supported on virtual nodes.
In the Virtual node usage column:
- N/A means the property doesn't apply to virtual nodes because it would require modifying the host.
- Same means the expected values are the same for a virtual node pool as for a standard node pool.
- Virtual replaces VM SKU values, because virtual node pods don't expose any underlying VM.
- Virtual node version refers to the current version of the virtual Kubelet-ACI connector release.
- Virtual node subnet name is the subnet that deploys virtual node pods into Azure Container Instances.
- Virtual node virtual network is the virtual network that contains the virtual node subnet.
| Label | Value | Example, options | Virtual node usage |
|---|---|---|---|
kubernetes.azure.com/agentpool |
<agent pool name> |
nodepool1 |
Same |
kubernetes.io/arch |
amd64 |
runtime.GOARCH |
N/A |
kubernetes.io/os |
<OS Type> |
Linux or Windows |
Linux |
node.kubernetes.io/instance-type |
<VM size> |
Standard_NC6 |
Virtual |
topology.kubernetes.io/region |
<Azure region> |
westus2 |
Same |
topology.kubernetes.io/zone |
<Azure zone> |
0 |
Same |
kubernetes.azure.com/cluster |
<MC_RgName> |
MC_aks_myAKSCluster_westus2 |
Same |
kubernetes.azure.com/mode |
<mode> |
User or System |
User |
kubernetes.azure.com/role |
agent |
Agent |
Same |
kubernetes.azure.com/scalesetpriority |
<scale set priority> |
Spot or Regular |
N/A |
kubernetes.io/hostname |
<hostname> |
aks-nodepool-00000000-vmss000000 |
Same |
kubernetes.azure.com/storageprofile |
<OS disk storage profile> |
Managed |
N/A |
kubernetes.azure.com/storagetier |
<OS disk storage tier> |
Premium_LRS |
N/A |
kubernetes.azure.com/instance-sku |
<SKU family> |
Standard_N |
Virtual |
kubernetes.azure.com/node-image-version |
<VHD version> |
AKSUbuntu-1804-2020.03.05 |
Virtual node version |
kubernetes.azure.com/subnet |
<nodepool subnet name> |
subnetName |
Virtual node subnet name |
kubernetes.azure.com/vnet |
<nodepool virtual network name> |
vnetName |
Virtual node virtual network |
kubernetes.azure.com/ppg |
<nodepool ppg name> |
ppgName |
N/A |
kubernetes.azure.com/encrypted-set |
<nodepool encrypted-set name> |
encrypted-set-name |
N/A |
kubernetes.azure.com/accelerator |
<accelerator> |
Nvidia |
N/A |
kubernetes.azure.com/fips_enabled |
<fips enabled> |
True |
N/A |
kubernetes.azure.com/os-sku |
<os/sku> |
See Create or update OS SKU | Linux SKU |
Windows node pools
AKS supports creating and using Windows Server container node pools through the Azure container network interface (CNI) network plugin. To plan the required subnet ranges and network considerations, see Configure Azure CNI networking.
The following az aks nodepool add command adds a node pool that runs Windows Server containers.
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name mywindowsnodepool \
--node-vm-size Standard_D8ds_v4 \
--os-type Windows \
--node-count 1
The preceding command uses the default subnet in the AKS cluster virtual network. For more information about how to build an AKS cluster with a Windows node pool, see Create a Windows Server container in AKS.
Node pool considerations
The following considerations and limitations apply when you create and manage node pools and multiple node pools:
- Quotas, VM size restrictions, and region availability apply to AKS node pools.
- System pools must contain at least one node. You can delete a system node pool if you have another system node pool to take its place in the AKS cluster. User node pools can contain zero or more nodes.
- You can't change the VM size of a node pool after you create it.
- For multiple node pools, the AKS cluster must use the Standard SKU load balancers. Basic SKU load balancers don't support multiple node pools.
- All cluster node pools must be in the same virtual network, and all subnets assigned to any node pool must be in the same virtual network.
- If you create multiple node pools at cluster creation time, the Kubernetes versions for all node pools must match the control plane version. You can update versions after the cluster has been provisioned by using per-node-pool operations.
Node pool scaling
As your application workload changes, you might need to change the number of nodes in a node pool. You can scale the number of nodes up or down manually by using the az aks nodepool scale command. The following example scales the number of nodes in mynodepool to five:
az aks nodepool scale \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name mynodepool \
--node-count 5
Scale node pools automatically by using the cluster autoscaler
AKS supports scaling node pools automatically with the cluster autoscaler. You enable this feature on each node pool, and define a minimum and a maximum number of nodes.
The following az aks nodepool add command adds a new node pool called mynodepool to an existing cluster. The --enable-cluster-autoscaler parameter enables the cluster autoscaler on the new node pool, and the --min-count and --max-count parameters specify the minimum and maximum number of nodes in the pool.
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name mynewnodepool \
--node-vm-size Standard_D8ds_v4 \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 5
The following az aks nodepool update command updates the minimum number of nodes from one to three for the mynewnodepool node pool.
az aks nodepool update \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name mynewnodepool \
--update-cluster-autoscaler \
--min-count 1 \
--max-count 3
You can disable the cluster autoscaler with az aks nodepool update by passing the --disable-cluster-autoscaler parameter.
az aks nodepool update \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name mynodepool \
--disable-cluster-autoscaler
To reenable the cluster autoscaler on an existing cluster, use az aks nodepool update, specifying the --enable-cluster-autoscaler, --min-count, and --max-count parameters.
For more information about how to use the cluster autoscaler for individual node pools, see Automatically scale a cluster to meet application demands on Azure Kubernetes Service (AKS).
Pod Sandboxing
AKS customers can easily setup and run Kata Containers on AKS in a fully managed way. This is made possible through the use of Pod Sandboxing, a feature that creates an isolation boundary between the container application and the shared kernel and compute resources of the container host.
AKS includes a mechanism called Pod Sandboxing that provides an isolation boundary between the container application and the shared kernel and compute resources of the container host, like CPU, memory, and networking. Pod Sandboxing complements other security measures or data protection controls to help tenant workloads secure sensitive information and meet regulatory, industry, or governance compliance requirements, like Payment Card Industry Data Security Standard (PCI DSS), International Organization for Standardization (ISO) 27001, and Health Insurance Portability and Accountability Act (HIPAA).
By deploying applications on separate clusters or node pools, you can strongly isolate the tenant workloads of different teams or customers. Using multiple clusters and node pools might be suitable for the isolation requirements of many organizations and SaaS solutions, but there are scenarios in which a single cluster with shared VM node pools is more efficient. For example, you might use a single cluster when you run untrusted and trusted pods on the same node or colocate DaemonSets and privileged containers on the same node for faster local communication and functional grouping. Pod Sandboxing can help you strongly isolate tenant applications on the same cluster nodes without needing to run these workloads in separate clusters or node pools. Other methods require that you recompile your code or cause other compatibility problems, but Pod Sandboxing in AKS can run any container unmodified inside an enhanced security VM boundary.
Pod Sandboxing on AKS is based on Kata Containers that run on the Azure Linux container host for AKS stack to provide hardware-enforced isolation. Kata Containers on AKS are built on a security-hardened Azure hypervisor. It achieves isolation per pod via a nested, lightweight Kata VM that utilizes resources from a parent VM node. In this model, each Kata pod gets its own kernel in a nested Kata guest VM. Use this model to place many Kata containers in a single guest VM while continuing to run containers in the parent VM. This model provides a strong isolation boundary in a shared AKS cluster.
For more information, see:
Azure Dedicated Host
Azure Dedicated Host is a service that provides physical servers that are dedicated to a single Azure subscription and provide hardware isolation at the physical-server level. You can provision these dedicated hosts within a region, availability zone, and fault domain, and you can place VMs directly into the provisioned hosts.
There are several benefits to using Azure Dedicated Host with AKS, including:
- Hardware isolation ensures that no other VMs are placed on the dedicated hosts, which provides an extra layer of isolation for tenant workloads. Dedicated hosts are deployed in the same datacenters and share the same network and underlying storage infrastructure as other non-isolated hosts.
- Azure Dedicated Host provides control over maintenance events that the Azure platform initiates. You can choose a maintenance window to reduce the impact on services and help ensure the availability and privacy of tenant workloads.
Azure Dedicated Host can help SaaS providers ensure tenant applications meet regulatory, industry, and governance compliance requirements for securing sensitive information. For more information, see Add Azure Dedicated Host to an AKS cluster.
Karpenter
Karpenter is an open-source node-lifecycle management project built for Kubernetes. Adding Karpenter to a Kubernetes cluster can improve the efficiency and cost of running workloads on that cluster. Karpenter watches for pods that the Kubernetes scheduler marks as unschedulable. It also dynamically provisions and manages nodes that can meet the pod requirements.
Karpenter provides fine-grained control over node provisioning and workload placement in a managed cluster. This control improves multitenancy by optimizing resource allocation, ensuring isolation between each tenant's applications, and reducing operational costs. When you build a multitenant solution on AKS, Karpenter provides useful capabilities to help you manage diverse application requirements to support different tenants. For example, you might need some tenants' applications to run on GPU-optimized node pools and others to run on memory-optimized node pools. If your application requires low latency for storage, you can use Karpenter to indicate that a pod requires a node that runs in a specific availability zone so that you can colocate your storage and application tier.
AKS enables node autoprovisioning on AKS clusters via Karpenter. Most users should use the node autoprovisioning mode to enable Karpenter as a managed addon. For more information, see Node autoprovisioning. If you need more advanced customization, you can choose to self-host Karpenter. For more information, see the AKS Karpenter provider.
Confidential VMs
Confidential computing is a security measure aimed at protecting data while in use through software or hardware-assisted isolation and encryption. This technology adds an extra layer of security to traditional approaches, safeguarding data at rest and in transit.
AWS platform supports confidential computing through Nitro Enclaves, which are available on EC2 instances as well as on Amazon Elastic Kubernetes Service (EKS). For more information, see this article on Amazon documentation. Additionally, Amazon EC2 instances support AMD SEV-SNP. This GitHub repository provides artifacts to build and deploy an Amazon Machine Image (AMI) for EKS with AMD SEV-SNP support.
On the other hand, Azure provides customers with confidential VMs to meet strict isolation, privacy, and security requirements within an AKS cluster. These confidential VMs utilize a hardware-based trusted execution environment. Specifically, Azure confidential VMs utilize AMD Secure Encrypted Virtualization - Secure Nested Paging (SEV-SNP) technology, which denies hypervisor and other host-management code access to VM memory and state. This adds an additional layer of defense and protection against operator access. For further details, you can refer to the documentation on using confidential VMs in an AKS cluster and the overview of confidential VMs in Azure.
Federal Information Process Standards (FIPS)
FIPS 140-3 is a US government standard that defines minimum security requirements for cryptographic modules in information technology products and systems. By enabling FIPS compliance for AKS node pools, you can enhance the isolation, privacy, and security of your tenant workloads. FIPS compliance ensures the use of validated cryptographic modules for encryption, hashing, and other security-related operations. With FIPS-enabled AKS node pools, you can meet regulatory and industry compliance requirements by employing robust cryptographic algorithms and mechanisms. Azure provides documentation on how to enable FIPS for AKS node pools, which enables you to strengthen the security posture of your multitenant AKS environments. For more information, see Enable FIPS for AKS node pools.
Host-based encryption
In EKS, your architecture might have utilized the following features to enhance data security:
- Amazon EBS Encryption: You can encrypt data at rest on Amazon Elastic Block Store (EBS) volumes that are attached to your EKS worker nodes.
- AWS Key Management Service (KMS): You can use AWS KMS to manage encryption keys and enforce the encryption of your data at rest. If you enable secrets encryption, you can encrypt Kubernetes secrets using your own AWS KMS key. For more information, see Encrypt Kubernetes secrets with AWS KMS on existing clusters.
- Amazon S3 Server-Side Encryption: If your EKS applications interact with Amazon S3, you can enable server-side encryption for your S3 buckets to protect data at rest.
Host-based encryption on AKS further strengthens tenant workload isolation, privacy, and security. When you enable host-based encryption, AKS encrypts data at rest on the underlying host machines, which helps ensure that sensitive tenant information is protected from unauthorized access. Temporary disks and ephemeral OS disks are encrypted at rest with platform-managed keys when you enable end-to-end encryption.
In AKS, OS and data disks use server-side encryption with platform-managed keys by default. The caches for these disks are encrypted at rest with platform-managed keys. You can specify your own key encryption key to encrypt the data protection key by using envelope encryption, also known as wrapping. The cache for the OS and data disks are also encrypted via the BYOK that you specify.
Host-based encryption adds a layer of security for multitenant environments. Each tenant's data in the OS and data disk caches is encrypted at rest with either customer-managed or platform-managed keys, depending on the selected disk encryption type. For more information, see:
- Host-based encryption on AKS
- BYOK with Azure disks in AKS
- Server-side encryption of Azure Disk Storage
Updates and upgrades
Azure periodically updates its VM hosting platform to improve reliability, performance, and security. These updates range from patching software components in the hosting environment to upgrading networking components or decommissioning hardware. For more information about how Azure updates VMs, see Maintenance for virtual machines in Azure.
VM hosting infrastructure updates don't usually affect hosted VMs, such as agent nodes of existing AKS clusters. For updates that affect hosted VMs, Azure minimizes the cases that require reboots by pausing the VM while updating the host, or live-migrating the VM to an already updated host.
If an update requires a reboot, Azure provides notification and a time window so you can start the update when it works for you. The self-maintenance window for host machines is typically 35 days, unless the update is urgent.
You can use Planned Maintenance to update VMs, and manage planned maintenance notifications with Azure CLI, PowerShell, or the Azure portal. Planned Maintenance detects if you're using Cluster Auto-Upgrade, and schedules upgrades during your maintenance window automatically. For more information about Planned Maintenance, see the az aks maintenanceconfiguration command and Use Planned Maintenance to schedule maintenance windows for your Azure Kubernetes Service (AKS) cluster.
Kubernetes upgrades
Part of the AKS cluster lifecycle is periodically upgrading to the latest Kubernetes version. It's important to apply upgrades to get the latest security releases and features. To upgrade the Kubernetes version of existing node pool VMs, you must cordon and drain nodes and replace them with new nodes that are based on an updated Kubernetes disk image.
By default, AKS configures upgrades to surge with one extra node. A default value of one for the max-surge settings minimizes workload disruption by creating an extra node to replace older-versioned nodes before cordoning or draining existing applications. You can customize the max-surge value per node pool to allow for a tradeoff between upgrade speed and upgrade disruption. Increasing the max-surge value completes the upgrade process faster, but a large value for max-surge might cause disruptions during the upgrade process.
For example, a max-surge value of 100% provides the fastest possible upgrade process by doubling the node count, but also causes all nodes in the node pool to be drained simultaneously. You might want to use this high value for testing, but for production node pools, a max-surge setting of 33% is better.
AKS accepts both integer and percentage values for max-surge. An integer such as 5 indicates five extra nodes to surge. Percent values for max-surge can be a minimum of 1% and a maximum of 100%, rounded up to the nearest node count. A value of 50% indicates a surge value of half the current node count in the pool.
During an upgrade, the max-surge value can be a minimum of 1 and a maximum value equal to the number of nodes in the node pool. You can set larger values, but the maximum number of nodes used for max-surge won't be higher than the number of nodes in the pool.
Important
For upgrade operations, node surges need enough subscription quota for the requested max-surge count. For example, a cluster that has five node pools, each with four nodes, has a total of 20 nodes. If each node pool has a max-surge value of 50%, you need additional compute and IP quota of 10 nodes, or two nodes times five pools, to complete the upgrade.
If you use Azure Container Networking Interface (CNI), also make sure you have enough IPs in the subnet to meet CNI requirements for AKS.
Upgrade node pools
To see available upgrades, use az aks get-upgrades.
az aks get-upgrades --resource-group <myResourceGroup> --name <myAKSCluster>
To see the status of node pools, use az aks nodepool list.
az aks nodepool list -g <myResourceGroup> --cluster-name <myAKSCluster>
The following command uses az aks nodepool upgrade to upgrade a single node pool.
az aks nodepool upgrade \
--resource-group <myResourceGroup> \
--cluster-name <myAKSCluster> \
--name <mynodepool> \
--kubernetes-version <KUBERNETES_VERSION>
For more information about how to upgrade the Kubernetes version for a cluster control plane and node pools, see:
- Azure Kubernetes Service (AKS) node image upgrade
- Upgrade a cluster control plane with multiple node pools
Upgrade considerations
Note these best practices and considerations for upgrading the Kubernetes version in an AKS cluster.
It's best to upgrade all node pools in an AKS cluster to the same Kubernetes version. The default behavior of
az aks upgradeupgrades all node pools and the control plane.Manually upgrade, or set an auto-upgrade channel on your cluster. If you use Planned Maintenance to patch VMs, auto-upgrades also start during your specified maintenance window. For more information, see Upgrade an Azure Kubernetes Service (AKS) cluster.
The
az aks upgradecommand with the--control-plane-onlyflag upgrades only the cluster control plane and doesn't change any of the associated node pools in the cluster. To upgrade individual node pools, specify the target node pool and Kubernetes version in theaz aks nodepool upgradecommand.An AKS cluster upgrade triggers a cordon and drain of your nodes. If you have low compute quota available, the upgrade could fail. For more information about increasing your quota, see Increase regional vCPU quotas.
Configure the
max-surgeparameter based on your needs, using an integer or a percentage value. For production node pools, use amax-surgesetting of 33%. For more information, see Customize node surge upgrade.When you upgrade an AKS cluster that uses CNI networking, make sure the subnet has enough available private IP addresses for the extra nodes the
max-surgesettings create. For more information, see Configure Azure CNI networking in Azure Kubernetes Service (AKS).If your cluster node pools span multiple Availability Zones within a region, the upgrade process can temporarily cause an unbalanced zone configuration. For more information, see Special considerations for node pools that span multiple Availability Zones.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
- Paolo Salvatori | Principal System Engineer
Other contributors:
- Laura Nicolas | Senior Software Engineer
- Chad Kittel | Principal Software Engineer
- Ed Price | Senior Content Program Manager
- Theano Petersen | Technical Writer
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
- AKS for Amazon EKS professionals
- Kubernetes identity and access management
- Kubernetes monitoring and logging
- Secure network access to Kubernetes
- Storage options for a Kubernetes cluster
- Cost management for Kubernetes
- Cluster governance
- Azure Kubernetes Service (AKS) solution journey
- Azure Kubernetes Services (AKS) day-2 operations guide
- Choose a Kubernetes at the edge compute option
- GitOps for Azure Kubernetes Service
Related resources
- AKS cluster best practices
- Create a Private AKS cluster with a Public DNS Zone
- Create a private Azure Kubernetes Service cluster using Terraform and Azure DevOps
- Create a public or private Azure Kubernetes Service cluster with Azure NAT Gateway and Azure Application Gateway
- Use Private Endpoints with a Private AKS Cluster
- Create an Azure Kubernetes Service cluster with the Application Gateway Ingress Controller
- Introduction to Kubernetes
- Introduction to Kubernetes on Azure
- Implement Azure Kubernetes Service (AKS)
- Develop and deploy applications on Kubernetes
- Optimize compute costs on Azure Kubernetes Service (AKS)