Build advanced retrieval-augmented generation systems
This article explores retrieval-augmented generation (RAG) in depth. We describe the work and considerations that are required for developers to create a production-ready RAG solution.
To learn about two options for building a "chat over your data" application, one of the top use cases for generative AI in businesses, see Augment LLMs with RAG or fine-tuning.
The following diagram depicts the steps or phases of RAG:
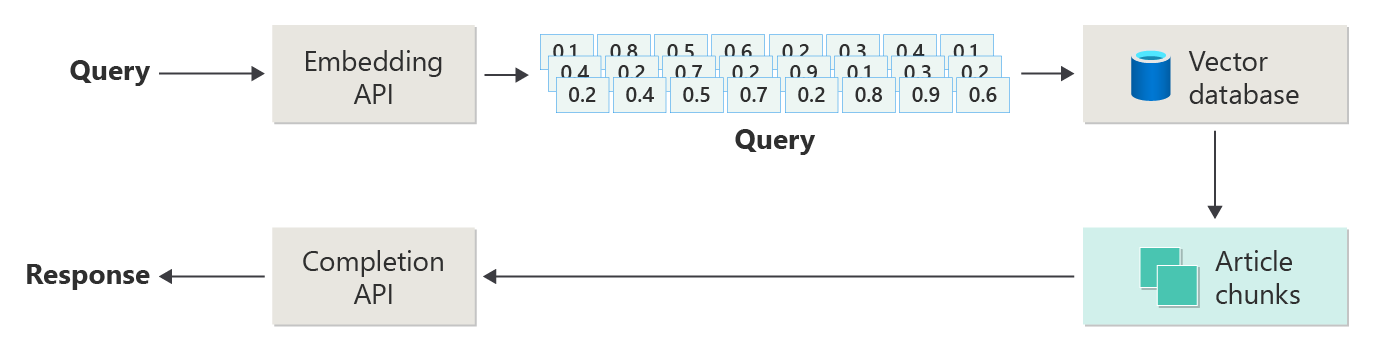
This depiction is called naive RAG. It's a useful way to initially understand the mechanisms, roles, and responsibilities that are required to implement a RAG-based chat system.
But a real-world implementation has many more preprocessing and post-processing steps to prepare the articles, queries, and responses for use. The following diagram is a more realistic depiction of a RAG, sometimes called advanced RAG:

This article provides a conceptual framework for understanding the preprocessing and post-processing phases in a real-world RAG-based chat system:
- Ingestion phase
- Inference pipeline phase
- Evaluation phase
Ingestion
Ingestion is primarily about storing your organization's documents so that they can be easily retrieved to answer a user's question. The challenge is ensuring that the portions of the documents that best match the user's query are located and used during inference. Matching is accomplished primarily through vectorized embeddings and a cosine similarity search. However, matching is facilitated by understanding the nature of the content (for example, patterns and form) and the data organization strategy (the structure of the data when it's stored in the vector database).
For ingestion, developers need to consider the following steps:
- Content preprocessing and extraction
- Chunking strategy
- Chunking organization
- Update strategy
Content preprocessing and extraction
Clean and accurate content is one of the best ways to improve the overall quality of a RAG-based chat system. To get clean, accurate content, start by analyzing the shape and form of the documents to be indexed. Do the documents conform to specified content patterns like documentation? If not, what types of questions might the documents answer?
At a minimum, create steps in the ingestion pipeline to:
- Standardize text formats
- Handle special characters
- Remove unrelated, outdated content
- Account for versioned content
- Account for content experience (tabs, images, tables)
- Extract metadata
Some of this information (like metadata, for example) might be useful if it's kept with the document in the vector database to use during the retrieval and evaluation process in the inference pipeline. It also can be combined with the text chunk to persuade the chunk's vector embedding.
Chunking strategy
As a developer, you must decide how to break up a larger document into smaller chunks. Chunking can improve the relevance of the supplemental content that's sent to the LLM to accurately answer user queries. Also consider how to use the chunks after retrieval. System designers should research common industry techniques, and do some experimentation. You can even test your strategy in a limited capacity in your organization.
Developers must consider:
- Chunk size optimization: Determine the ideal chunk size, and how to designate a chunk. By section? By paragraph? By sentence?
- Overlapping and sliding window chunks: Determine whether to divide the content into discrete chunks, or will the chunks overlap? You can even do both, in a sliding window design.
- Small2Big: When chunking is done at a granular level like a single sentence, is the content organized so that it's easy to find the neighboring sentences or the paragraph that contains the sentence? Retrieving this information and supplying it to the LLM might provide it with more context to answer user queries. For more information, see the next section.
Chunking organization
In a RAG system, strategically organizing your data in the vector database is a key to efficient retrieval of relevant information to augment the generation process. Here are the types of indexing and retrieval strategies you might consider:
- Hierarchical indexes: This approach involves creating multiple layers of indexes. A top-level index (a summary index) quickly narrows down the search space to a subset of potentially relevant chunks. A second-level index (a chunks index) provides more detailed pointers to the actual data. This method can significantly speed up the retrieval process because it reduces the number of entries to scan in the detailed index by first filtering through the summary index.
- Specialized indexes: Depending on the nature of the data and the relationships between chunks, you might use specialized indexes like graph-based or relational databases:
- Graph-based indexes are useful when the chunks have interconnected information or relationships that can enhance retrieval, such as citation networks or knowledge graphs.
- Relational databases can be effective if the chunks are structured in a tabular format. Use SQL queries to filter and retrieve data based on specific attributes or relationships.
- Hybrid indexes: A hybrid approach combines multiple indexing methods to apply their strengths to your overall strategy. For example, you might use a hierarchical index for initial filtering and a graph-based index to dynamically explore relationships between chunks during retrieval.
Alignment optimization
To enhance the relevance and accuracy of the retrieved chunks, align them closely with the question or query types they answer. One strategy is to generate and insert a hypothetical question for each chunk that represents the question the chunk is best suited to answer. This helps in several ways:
- Improved matching: During retrieval, the system can compare the incoming query with these hypothetical questions to find the best match to improve the relevance of chunks that are fetched.
- Training data for machine learning models: These pairings of questions and chunks can be training data to improve the machine learning models that are the underlying components of the RAG system. The RAG system learns which types of questions are best answered by each chunk.
- Direct query handling: If a real user query closely matches a hypothetical question, the system can quickly retrieve and use the corresponding chunk and speed up the response time.
Each chunk's hypothetical question acts like a label that guides the retrieval algorithm, so it's more focused and contextually aware. This kind of optimization is useful when the chunks cover a wide range of information topics or types.
Update strategies
If your organization indexes documents that are frequently updated, it's essential to maintain an updated corpus to ensure that the retriever component can access the most current information. The retriever component is the logic in the system that runs the query against the vector database, and then returns results. Here are some strategies for updating the vector database in these types of systems:
Incremental updates:
- Regular intervals: Schedule updates at regular intervals (for example, daily or weekly) depending on the frequency of document changes. This method ensures that the database is periodically refreshed on a known schedule.
- Trigger-based updates: Implement a system in which an update triggers reindexing. For example, any modification or addition of a document automatically initiates reindexing in the affected sections.
Partial updates:
- Selective reindexing: Instead of reindexing an entire database, update only the changed corpus parts. This approach can be more efficient than full reindexing, especially for large datasets.
- Delta encoding: Store only the differences between the existing documents and their updated versions. This approach reduces the data processing load by avoiding the need to process unchanged data.
Versioning:
- Snapshotting: Maintain document corpus versions at different points in time. This technique provides a backup mechanism and allows the system to revert to or refer to previous versions.
- Document version control: Use a version control system to systematically track document changes for maintaining the change history and simplifying the update process.
Real-time updates:
- Stream processing: When information timeliness is critical, use stream processing technologies for real-time vector database updates as changes are made to the document.
- Live querying: Instead of relying solely on preindexed vectors, use a live data query approach for up-to-date responses, possibly combining live data with cached results for efficiency.
Optimization techniques:
Batch processing: Batch processing accumulates changes to apply less frequently to optimize resources and reduce overhead.
Hybrid approaches: Combine various strategies:
- Use incremental updates for minor changes.
- Use full reindexing for major updates.
- Document structural changes that are made to the corpus.
Choosing the right update strategy or the right combination depends on specific requirements, including:
- Document corpus size
- Update frequency
- Real-time data needs
- Resource availability
Evaluate these factors based on the needs of the specific application. Each approach has trade-offs in complexity, cost, and update latency.
Inference pipeline
Your articles are chunked, vectorized, and stored in a vector database. Now, turn your focus to resolving completion challenges.
To get the most accurate and efficient completions, you must account for many factors:
- Is the user's query written in a way to get the results the user is looking for?
- Does the user's query violate any of the organization's policies?
- How do you rewrite the user's query to improve the chances of finding the closest matches in the vector database?
- How do you evaluate query results to ensure that the article chunks align to the query?
- How do you evaluate and modify query results before you pass them into the LLM to ensure that the most relevant details are included in the completion?
- How do you evaluate the LLM's response to ensure that the LLM's completion answers the user's original query?
- How do you ensure that the LLM's response complies with the organization's policies?
The entire inference pipeline runs in real time. There isn't one right way to design your preprocessing and post-processing steps. You likely will choose a combination of programming logic and other LLM calls. One of the most important considerations is the trade-off between building the most accurate and compliant pipeline possible and the cost and latency required to make it happen.
Let's identify specific strategies in each stage of the inference pipeline.
Query preprocessing steps
Query preprocessing occurs immediately after the user submits their query:

The goal of these steps is to make sure that the user asks questions that are within the scope of your system and to prepare the user's query to increase the likelihood that it locates the best possible article chunks by using the cosine similarity or "nearest neighbor" search.
Policy check: This step involves logic that identifies, removes, flags, or rejects certain content. Some examples include removing personal data, removing expletives, and identifying "jailbreak" attempts. Jailbreaking refers to user attempts to circumvent or manipulate the built-in safety, ethical, or operational guidelines of the model.
Query rewriting: This step might be anything from expanding acronyms and removing slang to rephrasing the question to ask it more abstractly to extract high-level concepts and principles (step-back prompting).
A variation on step-back prompting is Hypothetical Document Embeddings (HyDE). HyDE uses the LLM to answer the user's question, creates an embedding for that response (the hypothetical document embedding), and then uses the embedding to run a search against the vector database.
Subqueries
The subqueries processing step is based on the original query. If the original query is long and complex, it can be useful to programmatically break it into several smaller queries, and then combine all the responses.
For example, a question about scientific discoveries in physics might be: "Who made more significant contributions to modern physics, Albert Einstein or Niels Bohr?"
Breaking down complex queries into subqueries make them more manageable:
- Subquery 1: "What are the key contributions of Albert Einstein to modern physics?"
- Subquery 2: "What are the key contributions of Niels Bohr to modern physics?"
The results of these subqueries detail the major theories and discoveries by each physicist. For example:
- For Einstein, contributions might include the theory of relativity, the photoelectric effect, and E=mc^2.
- For Bohr, contributions might include Bohr's model of the hydrogen atom, Bohr's work on quantum mechanics, and Bohr's principle of complementarity.
When these contributions are outlined, they can be assessed to determine more subqueries. For example:
- Subquery 3: "How have Einstein's theories impacted the development of modern physics?"
- Subquery 4: "How have Bohr's theories impacted the development of modern physics?"
These subqueries explore each scientist's influence on physics, such as:
- How Einstein's theories led to advancements in cosmology and quantum theory
- How Bohr's work contributed to understanding atomic structure and quantum mechanics
Combining the results of these subqueries can help the language model form a more comprehensive response about who made more significant contributions to modern physics based on their theoretical advancements. This method simplifies the original complex query by accessing more specific, answerable components, and then synthesizing those findings into a coherent answer.
Query router
Your organization might choose to divide its corpus of content into multiple vector stores or into entire retrieval systems. In that scenario, you can use a query router. A query router selects the most appropriate database or index to provide the best answers to a specific query.
A query router typically works at a point after the user formulates the query, but before it sends the query to retrieval systems.
Here's a simplified workflow for a query router:
- Query analysis: The LLM or another component analyzes the incoming query to understand its content, context, and the type of information that is likely needed.
- Index selection: Based on the analysis, the query router selects one or more indexes from potentially several available indexes. Each index might be optimized for different types of data or queries. For example, some indexes might be more suited to factual queries. Other indexes might excel in providing opinions or subjective content.
- Query dispatch: The query is dispatched to the selected index.
- Results aggregation: Responses from the selected indexes are retrieved and possibly aggregated or further processed to form a comprehensive answer.
- Answer generation: The final step involves generating a coherent response based on the retrieved information, possibly integrating or synthesizing content from multiple sources.
Your organization might use multiple retrieval engines or indexes for the following use cases:
- Data type specialization: Some indexes might specialize in news articles, others in academic papers, and yet others in general web content or specific databases like for medical or legal information.
- Query type optimization: Certain indexes might be optimized for quick factual lookups (for example, dates or events). Others might be better to use for complex reasoning tasks or for queries that require a deep domain knowledge.
- Algorithmic differences: Different retrieval algorithms might be used in different engines, such as vector-based similarity searches, traditional keyword-based searches, or more advanced semantic understanding models.
Imagine a RAG-based system that's used in a medical advisory context. The system has access to multiple indexes:
- A medical research paper index optimized for detailed and technical explanations
- A clinical case study index that provides real-world examples of symptoms and treatments
- A general health information index for basic queries and public health information
If a user asks a technical question about the biochemical effects of a new drug, the query router might prioritize the medical research paper index due to its depth and technical focus. For a question about typical symptoms of a common illness, however, the general health index might be chosen for its broad and easily understandable content.
Post-retrieval processing steps
Post-retrieval processing occurs after the retriever component retrieves relevant content chunks from the vector database:

With candidate content chunks retrieved, the next step is to validate the article chunk usefulness when augmenting the LLM prompt before preparing the prompt to be presented to the LLM.
Here are some prompt aspects to consider:
- Including too much supplement information might result in ignoring the most important information.
- Including irrelevant information might negatively influence the answer.
Another consideration is the needle in a haystack problem, a term that refers to a known quirk of some LLMs in which the content at the beginning and end of a prompt have greater weight to the LLM than the content in the middle.
Finally, consider the LLM's maximum context window length and the number of tokens required to complete extraordinarily long prompts (especially for queries at scale).
To deal with these issues, a post-retrieval processing pipeline might include the following steps:
- Filtering results: In this step, ensure that the article chunks that are returned by the vector database are relevant to the query. If they aren't, the result is ignored when the LLM prompt is composed.
- Re-ranking: Rank the article chunks that are retrieved from the vector store to ensure that relevant details are near the edges (the beginning and the end) of the prompt.
- Prompt compression: Use a small, inexpensive model to compress and summarize multiple article chunks into a single compressed prompt before sending the prompt to the LLM.
Post-completion processing steps
Post-completion processing occurs after the user's query and all content chunks are sent to the LLM:

Accuracy validation occurs after the LLM's prompt completion. A post-completion processing pipeline might include the following steps:
- Fact check: The intent is to identify specific claims made in the article that are presented as facts, and then to check those facts for accuracy. If the fact check step fails, it might be appropriate to requery the LLM in hopes of getting a better answer or to return an error message to the user.
- Policy check: The last line of defense to ensure that answers don't contain harmful content, whether for the user or for the organization.
Evaluation
Evaluating the results of a nondeterministic system isn't as simple as running the unit tests or integration tests most developers are familiar with. You need to consider several factors:
- Are users satisfied with the results they're getting?
- Are users getting accurate responses to their questions?
- How do you capture user feedback? Do you have any policies in place that limit what data you can collect about user data?
- For diagnosis of unsatisfactory responses, do you have visibility into all the work that went into answering the question? Do you keep a log of each stage in the inference pipeline of inputs and outputs so that you can perform root cause analysis?
- How can you make changes to the system without regression or degradation of results?
Capturing and acting on feedback from users
As described earlier, you might need to work with your organization's privacy team to design feedback capture mechanisms, telemetry, and logging for forensics and root cause analysis of a query session.
The next step is to develop an assessment pipeline. An assessment pipeline helps with the complexity and time-intensive nature of analyzing verbatim feedback and the root causes of the responses provided by an AI system. This analysis is crucial because it involves investigating every response to understand how the AI query produced the results, checking the appropriateness of the content chunks that are used from documentation, and the strategies employed in dividing up these documents.
It also involves considering any extra preprocessing or post-processing steps that might enhance the results. This detailed examination often uncovers content gaps, particularly when no suitable documentation exists for response to a user's query.
Building an assessment pipeline becomes essential to manage the scale of these tasks effectively. An efficient pipeline uses custom tooling to evaluate metrics that approximate the quality of answers provided by AI. This system streamlines the process of determining why a specific answer was given to a user's question, which documents were used to generate that answer, and the effectiveness of the inference pipeline that processes the queries.
Golden dataset
One strategy to evaluate the results of a nondeterministic system like a RAG chat system is to use a golden dataset. A golden dataset is a curated set of questions and approved answers, metadata (like topic and type of question), references to source documents that can serve as ground truth for answers, and even variations (different phrasings to capture the diversity of how users might ask the same questions).
A golden dataset represents the "best case scenario." Developers can evaluate the system to see how well it performs, and then do regression tests when they implement new features or updates.
Assessing harm
Harms modeling is a methodology aimed at foreseeing potential harms, spotting deficiencies in a product that might pose risks to individuals, and developing proactive strategies to mitigate such risks.
A tool designed for assessing the impact of technology, particularly AI systems, would feature several key components based on the principles of harms modeling as outlined in the provided resources.
Key features of a harms evaluation tool might include:
Stakeholder identification: The tool might help users identify and categorize various stakeholders that are affected by the technology, including direct users, indirectly affected parties, and other entities, like future generations or nonhuman factors, such as environmental concerns.
Harm categories and descriptions: The tool might include a comprehensive list of potential harms, such as privacy loss, emotional distress, or economic exploitation. The tool might guide the user through various scenarios, illustrate how the technology might cause these harms, and help evaluate both intended and unintended consequences.
Severity and probability assessments: The tool might help users assess the severity and probability of each identified harm. The user can prioritize issues to address first. Examples include qualitative assessments supported by data where available.
Mitigation strategies: The tool can suggest potential mitigation strategies after it identifies and evaluates harms. Examples include changes to the system design, adding safeguards, and alternative technological solutions that minimize identified risks.
Feedback mechanisms: The tool should incorporate mechanisms for gathering feedback from stakeholders so that the harms evaluation process is dynamic and responsive to new information and perspectives.
Documentation and reporting: For transparency and accountability, the tool might facilitate detailed reports that document the harms assessment process, findings, and potential risk mitigation actions taken.
These features can help you identify and mitigate risks, but they also help you design more ethical and responsible AI systems by considering a broad spectrum of impacts from the start.
For more information, see these articles:
Testing and verifying the safeguards
This article outlines several processes that are aimed at mitigating the possibility of a RAG-based chat system being exploited or compromised. Red-teaming plays a crucial role in ensuring that the mitigations are effective. Red-teaming involves simulating the actions of a potential adversary to uncover potential weaknesses or vulnerabilities in the application. This approach is especially vital in addressing the significant risk of jailbreaking.
Developers need to rigorously assess RAG-based chat system safeguards under various guideline scenarios to effectively test and verify them. This approach not only ensures robustness, but also helps you fine-tune the system’s responses to strictly adhere to defined ethical standards and operational procedures.
Final considerations for application design
Here's a short list of things to consider and other takeaways from this article that might affect your application design decisions:
- Acknowledge the nondeterministic nature of generative AI in your design. Plan for variability in outputs and set up mechanisms to ensure consistency and relevance in responses.
- Assess the benefits of preprocessing user prompts against the potential increase in latency and costs. Simplifying or modifying prompts before submission might improve response quality, but it might add complexity and time to the response cycle.
- To enhance performance, investigate strategies for parallelizing LLM requests. This approach might reduce latency, but it requires careful management to avoid increased complexity and potential cost implications.
If you want to start experimenting with building a generative AI solution immediately, we recommend that you take a look at Get started with chat by using your own data sample for Python. The tutorial is also available for .NET, Java, and JavaScript.