Copy data from and to Salesforce using Azure Data Factory or Azure Synapse Analytics (legacy)
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use Copy Activity in Azure Data Factory and Azure Synapse pipelines to copy data from and to Salesforce. It builds on the Copy Activity overview article that presents a general overview of the copy activity.
Important
The new Salesforce connector provides improved native Salesforce support. If you are using the legacy Salesforce connector in your solution, you are recommended to upgrade your Salesforce connector at your earliest convenience. Refer to this section for details on the difference between the legacy and latest version.
Supported capabilities
This Salesforce connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/sink) | ① ② |
| Lookup activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
For a list of data stores that are supported as sources or sinks, see the Supported data stores table.
Specifically, this Salesforce connector supports:
- Salesforce Developer, Professional, Enterprise, or Unlimited editions.
- Copying data from and to Salesforce production, sandbox, and custom domain.
Note
This function supports copy of any schema from the above mentioned Salesforce environments, including the Nonprofit Success Pack (NPSP).
The Salesforce connector is built on top of the Salesforce REST/Bulk API. When copying data from Salesforce, the connector automatically chooses between REST and Bulk APIs based on the data size - when the result set is large, Bulk API is used for better performance; You can explicitly set the API version used to read/write data via apiVersion property in linked service. When copying data to Salesforce, the connector uses BULK API v1.
Note
The connector no longer sets default version for Salesforce API. For backward compatibility, if a default API version was set before, it keeps working. The default value is 45.0 for source, and 40.0 for sink.
Prerequisites
API permission must be enabled in Salesforce.
Salesforce request limits
Salesforce has limits for both total API requests and concurrent API requests. Note the following points:
- If the number of concurrent requests exceeds the limit, throttling occurs and you see random failures.
- If the total number of requests exceeds the limit, the Salesforce account is blocked for 24 hours.
You might also receive the "REQUEST_LIMIT_EXCEEDED" error message in both scenarios. For more information, see the "API request limits" section in Salesforce developer limits.
Get started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Create a linked service to Salesforce using UI
Use the following steps to create a linked service to Salesforce in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for Salesforce and select the Salesforce connector.
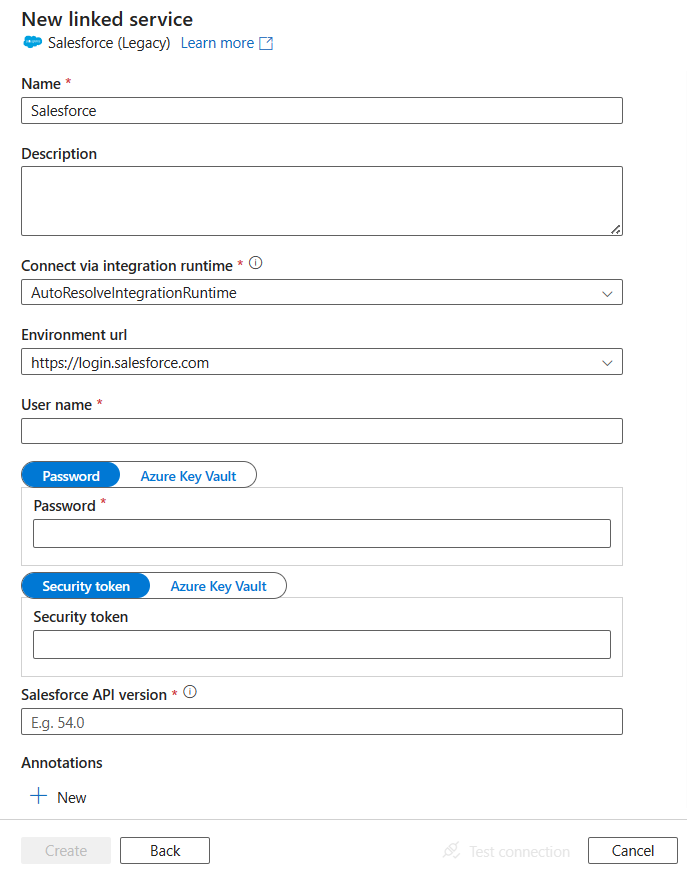
Configure the service details, test the connection, and create the new linked service.
Connector configuration details
The following sections provide details about properties that are used to define entities specific to the Salesforce connector.
Linked service properties
The following properties are supported for the Salesforce linked service.
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to Salesforce. | Yes |
| environmentUrl | Specify the URL of the Salesforce instance. - Default is "https://login.salesforce.com". - To copy data from sandbox, specify "https://test.salesforce.com". - To copy data from custom domain, specify, for example, "https://[domain].my.salesforce.com". |
No |
| username | Specify a user name for the user account. | Yes |
| password | Specify a password for the user account. Mark this field as a SecureString to store it securely, or reference a secret stored in Azure Key Vault. |
Yes |
| securityToken | Specify a security token for the user account. To learn about security tokens in general, see Security and the API. The security token can be skipped only if you add the Integration Runtime's IP to the trusted IP address list on Salesforce. When using Azure IR, refer to Azure Integration Runtime IP addresses. For instructions on how to get and reset a security token, see Get a security token. Mark this field as a SecureString to store it securely, or reference a secret stored in Azure Key Vault. |
No |
| apiVersion | Specify the Salesforce REST/Bulk API version to use, e.g. 52.0. |
No |
| connectVia | The integration runtime to be used to connect to the data store. If not specified, it uses the default Azure Integration Runtime. | No |
Example: Store credentials
{
"name": "SalesforceLinkedService",
"properties": {
"type": "Salesforce",
"typeProperties": {
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"securityToken": {
"type": "SecureString",
"value": "<security token>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: Store credentials in Key Vault
{
"name": "SalesforceLinkedService",
"properties": {
"type": "Salesforce",
"typeProperties": {
"username": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of password in AKV>",
"store":{
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
}
},
"securityToken": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of security token in AKV>",
"store":{
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: Store credentials in Key Vault, as well as environmentUrl and username
Note that by doing so, you will no longer be able to use the UI to edit settings. The Specify dynamic contents in JSON format checkbox will be checked, and you will have to edit this configuration entirely by hand. The advantage is you can derive ALL configuration settings from the Key Vault instead of parameterizing anything here.
{
"name": "SalesforceLinkedService",
"properties": {
"type": "Salesforce",
"typeProperties": {
"environmentUrl": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of environment URL in AKV>",
"store": {
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
},
},
"username": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of username in AKV>",
"store": {
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
},
},
"password": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of password in AKV>",
"store":{
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
}
},
"securityToken": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of security token in AKV>",
"store":{
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
For a full list of sections and properties available for defining datasets, see the Datasets article. This section provides a list of properties supported by the Salesforce dataset.
To copy data from and to Salesforce, set the type property of the dataset to SalesforceObject. The following properties are supported.
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to SalesforceObject. | Yes |
| objectApiName | The Salesforce object name to retrieve data from. | No for source, Yes for sink |
Important
The "__c" part of API Name is needed for any custom object.
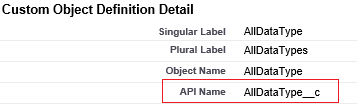
Example:
{
"name": "SalesforceDataset",
"properties": {
"type": "SalesforceObject",
"typeProperties": {
"objectApiName": "MyTable__c"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Salesforce linked service name>",
"type": "LinkedServiceReference"
}
}
}
Note
For backward compatibility: When you copy data from Salesforce, if you use the previous "RelationalTable" type dataset, it keeps working while you see a suggestion to switch to the new "SalesforceObject" type.
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to RelationalTable. | Yes |
| tableName | Name of the table in Salesforce. | No (if "query" in the activity source is specified) |
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by Salesforce source and sink.
Salesforce as a source type
To copy data from Salesforce, set the source type in the copy activity to SalesforceSource. The following properties are supported in the copy activity source section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to SalesforceSource. | Yes |
| query | Use the custom query to read data. You can use Salesforce Object Query Language (SOQL) query or SQL-92 query. See more tips in query tips section. If query is not specified, all the data of the Salesforce object specified in "objectApiName" in dataset will be retrieved. | No (if "objectApiName" in the dataset is specified) |
| readBehavior | Indicates whether to query the existing records, or query all records including the deleted ones. If not specified, the default behavior is the former. Allowed values: query (default), queryAll. |
No |
Important
The "__c" part of API Name is needed for any custom object.
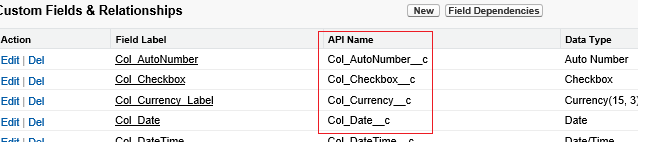
Example:
"activities":[
{
"name": "CopyFromSalesforce",
"type": "Copy",
"inputs": [
{
"referenceName": "<Salesforce input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SalesforceSource",
"query": "SELECT Col_Currency__c, Col_Date__c, Col_Email__c FROM AllDataType__c"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Note
For backward compatibility: When you copy data from Salesforce, if you use the previous "RelationalSource" type copy, the source keeps working while you see a suggestion to switch to the new "SalesforceSource" type.
Note
Salesforce source doesn't support proxy settings in the self-hosted integration runtime, but sink does.
Salesforce as a sink type
To copy data to Salesforce, set the sink type in the copy activity to SalesforceSink. The following properties are supported in the copy activity sink section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity sink must be set to SalesforceSink. | Yes |
| writeBehavior | The write behavior for the operation. Allowed values are Insert and Upsert. |
No (default is Insert) |
| externalIdFieldName | The name of the external ID field for the upsert operation. The specified field must be defined as "External ID Field" in the Salesforce object. It can't have NULL values in the corresponding input data. | Yes for "Upsert" |
| writeBatchSize | The row count of data written to Salesforce in each batch. | No (default is 5,000) |
| ignoreNullValues | Indicates whether to ignore NULL values from input data during a write operation. Allowed values are true and false. - True: Leave the data in the destination object unchanged when you do an upsert or update operation. Insert a defined default value when you do an insert operation. - False: Update the data in the destination object to NULL when you do an upsert or update operation. Insert a NULL value when you do an insert operation. |
No (default is false) |
| maxConcurrentConnections | The upper limit of concurrent connections established to the data store during the activity run. Specify a value only when you want to limit concurrent connections. | No |
Example: Salesforce sink in a copy activity
"activities":[
{
"name": "CopyToSalesforce",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Salesforce output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SalesforceSink",
"writeBehavior": "Upsert",
"externalIdFieldName": "CustomerId__c",
"writeBatchSize": 10000,
"ignoreNullValues": true
}
}
}
]
Query tips
Retrieve data from a Salesforce report
You can retrieve data from Salesforce reports by specifying a query as {call "<report name>"}. An example is "query": "{call \"TestReport\"}".
Retrieve deleted records from the Salesforce Recycle Bin
To query the soft deleted records from the Salesforce Recycle Bin, you can specify readBehavior as queryAll.
Difference between SOQL and SQL query syntax
When copying data from Salesforce, you can use either SOQL query or SQL query. Note that these two have different syntax and functionality support, do not mix it. You are suggested to use the SOQL query, which is natively supported by Salesforce. The following table lists the main differences:
| Syntax | SOQL Mode | SQL Mode |
|---|---|---|
| Column selection | Need to enumerate the fields to be copied in the query, e.g. SELECT field1, filed2 FROM objectname |
SELECT * is supported in addition to column selection. |
| Quotation marks | Filed/object names cannot be quoted. | Field/object names can be quoted, e.g. SELECT "id" FROM "Account" |
| Datetime format | Refer to details here and samples in next section. | Refer to details here and samples in next section. |
| Boolean values | Represented as False and True, e.g. SELECT … WHERE IsDeleted=True. |
Represented as 0 or 1, e.g. SELECT … WHERE IsDeleted=1. |
| Column renaming | Not supported. | Supported, e.g.: SELECT a AS b FROM …. |
| Relationship | Supported, e.g. Account_vod__r.nvs_Country__c. |
Not supported. |
Retrieve data by using a where clause on the DateTime column
When you specify the SOQL or SQL query, pay attention to the DateTime format difference. For example:
- SOQL sample:
SELECT Id, Name, BillingCity FROM Account WHERE LastModifiedDate >= @{formatDateTime(pipeline().parameters.StartTime,'yyyy-MM-ddTHH:mm:ssZ')} AND LastModifiedDate < @{formatDateTime(pipeline().parameters.EndTime,'yyyy-MM-ddTHH:mm:ssZ')} - SQL sample:
SELECT * FROM Account WHERE LastModifiedDate >= {ts'@{formatDateTime(pipeline().parameters.StartTime,'yyyy-MM-dd HH:mm:ss')}'} AND LastModifiedDate < {ts'@{formatDateTime(pipeline().parameters.EndTime,'yyyy-MM-dd HH:mm:ss')}'}
Error of MALFORMED_QUERY: Truncated
If you hit error of "MALFORMED_QUERY: Truncated", normally it's due to you have JunctionIdList type column in data and Salesforce has limitation on supporting such data with large number of rows. To mitigate, try to exclude JunctionIdList column or limit the number of rows to copy (you can partition to multiple copy activity runs).
Data type mapping for Salesforce
When you copy data from Salesforce, the following mappings are used from Salesforce data types to interim data types within the service internally. To learn about how the copy activity maps the source schema and data type to the sink, see Schema and data type mappings.
| Salesforce data type | Service interim data type |
|---|---|
| Auto Number | String |
| Checkbox | Boolean |
| Currency | Decimal |
| Date | DateTime |
| Date/Time | DateTime |
| String | |
| ID | String |
| Lookup Relationship | String |
| Multi-Select Picklist | String |
| Number | Decimal |
| Percent | Decimal |
| Phone | String |
| Picklist | String |
| Text | String |
| Text Area | String |
| Text Area (Long) | String |
| Text Area (Rich) | String |
| Text (Encrypted) | String |
| URL | String |
Note
Salesforce Number type is mapping to Decimal type in Azure Data Factory and Azure Synapse pipelines as a service interim data type. Decimal type honors the defined precision and scale. For data whose decimal places exceeds the defined scale, its value will be rounded off in preview data and copy. To avoid getting such precision loss in Azure Data Factory and Azure Synapse pipelines, consider increasing the decimal places to a reasonably large value in Custom Field Definition Edit page of Salesforce.
Lookup activity properties
To learn details about the properties, check Lookup activity.
Next steps
For a list of data stores supported as sources and sinks by the copy activity, see Supported data stores.