Planning your migration from Azure Data Factory
Microsoft Fabric is Microsoft’s data analytics SaaS product that brings together all of Microsoft’s market-leading analytics products into a single user experience. Fabric Data Factory provides workflow orchestration, data movement, data replication, and data transformation at scale with similar capabilities that are found in Azure Data Factory (ADF). If you have existing ADF investments that you’d like to modernize to Fabric Data Factory, this document is useful to help you understand migration considerations, strategies, and approaches.
Migrating from the Azure PaaS ETL/DI services ADF & Synapse pipelines and data flows can provide several important benefits:
- New integrated pipeline features including email and Teams activities enable easy routing of messages during pipeline execution.
- Built-in continuous integration and delivery (CI/CD) features (deployment pipelines) don't require external integration with Git repositories.
- Workspace integration with your OneLake data lake enables single-pane-of-glass easy analytics management.
- Refreshing your semantic data models is easy in Fabric with a fully integrated pipeline activity.
Microsoft Fabric is an integrated platform for both self-service and IT-managed enterprise data. With exponential growth in data volumes and complexity, Fabric customers demand enterprise solutions that scale, are secure, easy to manage, and accessible to all users across the largest of organizations.
In recent years, Microsoft invested significant efforts to deliver scalable cloud capabilities to Premium. To that end, Data Factory in Fabric instantly empowers a large ecosystem of data integration developers and data integration solutions that were built up over decades to apply the full set of features, and capabilities that go far beyond comparable functionality available in previous generations.
Naturally, customers are asking whether there's an opportunity to consolidate by hosting their data integration solutions within Fabric. Common questions include:
- Does all the functionality we depend on work in Fabric pipelines?
- What capabilities are available only in Fabric pipelines?
- How do we migrate existing pipelines to Fabric pipelines?
- What's Microsoft's roadmap for enterprise data ingestion?
Platform differences
When you migrate an entire ADF instance, there are many important differences to consider between ADF and Data Factory in Fabric, which becomes important as you migrate to Fabric. We explore several of those important differences in this section.
For a more detailed understanding of the functional mapping of features differences between Azure Data Factory and Fabric Data Factory, refer to Compare Data Factory in Fabric and Azure Data Factory.
Integration Runtimes
In ADF, integration runtimes (IRs) are configuration objects that represent compute that is used by ADF to complete your data processing. These configuration properties include Azure region for cloud compute and data flow Spark compute sizes. Other IR types include self-hosted IRs (SHIRs) for on-premises data connectivity, SSIS IRs for running SQL Server Integration Services packages, and Vnet-enabled cloud IRs.
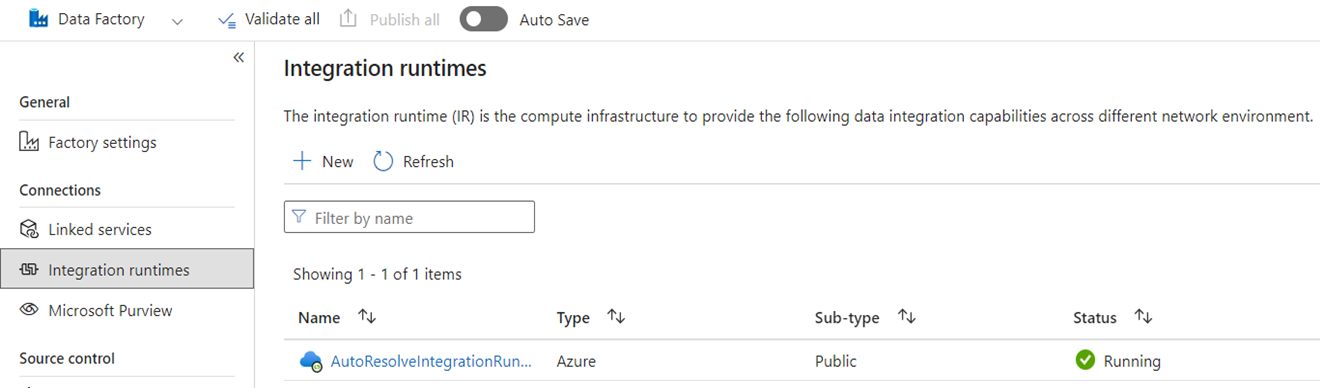
Microsoft Fabric is a software-as-a-service (SaaS) product whereas ADF is a platform-as-a-service (PaaS) product. What this distinction means in terms of integration runtimes is that you don't need to configure anything to use pipelines or dataflows in Fabric as the default is to use cloud-based compute in the region where your Fabric capacities are located. SSIS IRs don't exist in Fabric and for on-premises data connectivity you use a Fabric-specific component known as the on-premises Data Gateway (OPDG). And for virtual network based connectivity to secured networks, you use the Virtual Network Data Gateway in Fabric.
When migrating from ADF to Fabric, you don't need to migrate public network Azure (cloud) IRs. You need to recreate your SHIRs as OPDGs and virtual network enabled Azure IRs as Virtual Network Data Gateways.
Pipelines
Pipelines are the fundamental component of ADF, which is used for the primary workflow and orchestration of your ADF processes for data movement, data transformation, and process orchestration. Pipelines in Fabric Data Factory are nearly identical to ADF but with extra components that fit the SaaS model based on Power BI well. This similarity includes native activities for emails, Teams, and Semantic Model refreshes.
The JSON definition of pipelines in Fabric Data Factory differs slightly from ADF due to differences in the application model between the two products. Because of this difference, it isn't possible to copy/paste pipeline JSON, import/export pipelines, or point to an ADF Git repo.
When rebuilding your ADF pipelines as Fabric pipelines, you use essentially the same workflow models and skills that you used in ADF. The primary consideration has to do with Linked Services and Datasets which are concepts in ADF that don't exist in Fabric.
Linked Services
In ADF, Linked Services define the connectivity properties needed to connect to your data stores for data movement, data transformation, and data processing activities. In Fabric, you need to recreate these definitions as Connections that are properties for your activities like Copy and Dataflows.
Datasets
Datasets define the shape, location, and contents of your data in ADF but don't exist as entities in Fabric. To define data properties like data types, columns, folders, tables, etc. in Fabric Data Factory pipelines, you define these characteristics inline inside pipeline activities and inside the Connection object referenced previously in the Linked Service section.
Dataflows
In Data Factory for Fabric, the term dataflows refers to the code-free data transformation activities, whereas in ADF, the same feature is referred to as data flows. Fabric Data Factory dataflows have a user interface built on Power Query, which is used in the ADF Power Query activity. The compute used to execute dataflows in Fabric is a native execution engine that can scale out for large-scale data transformation using the new Fabric Data Warehouse compute engine.
In ADF, Data Flows are built on the Synapse Spark infrastructure and defined using a construction user interface that uses an underlying domain-specific language (DSL) known as data flow script. This definition language differs considerably from the Power Query based dataflows in Fabric that use a definition language known as M to define their behavior. Because of these differences in user interfaces, languages, and execute engines, Fabric dataflows and ADF data flows aren't compatible and you need to recreate your ADF data flows as Fabric dataflows when upgrading your solutions to Fabric.
Triggers
Triggers signal ADF to execute a pipeline based upon a wall-clock time schedule, tumbling window time slices, file-based events, or custom events. These features are similar in Fabric although the underlying implementation is different.
In Fabric, triggers only exist as a pipeline concept. The larger framework that pipeline triggers use in Fabric is known as Data Activator, which is an event and alerting subsystem of the Real-time Intelligence features in Fabric.
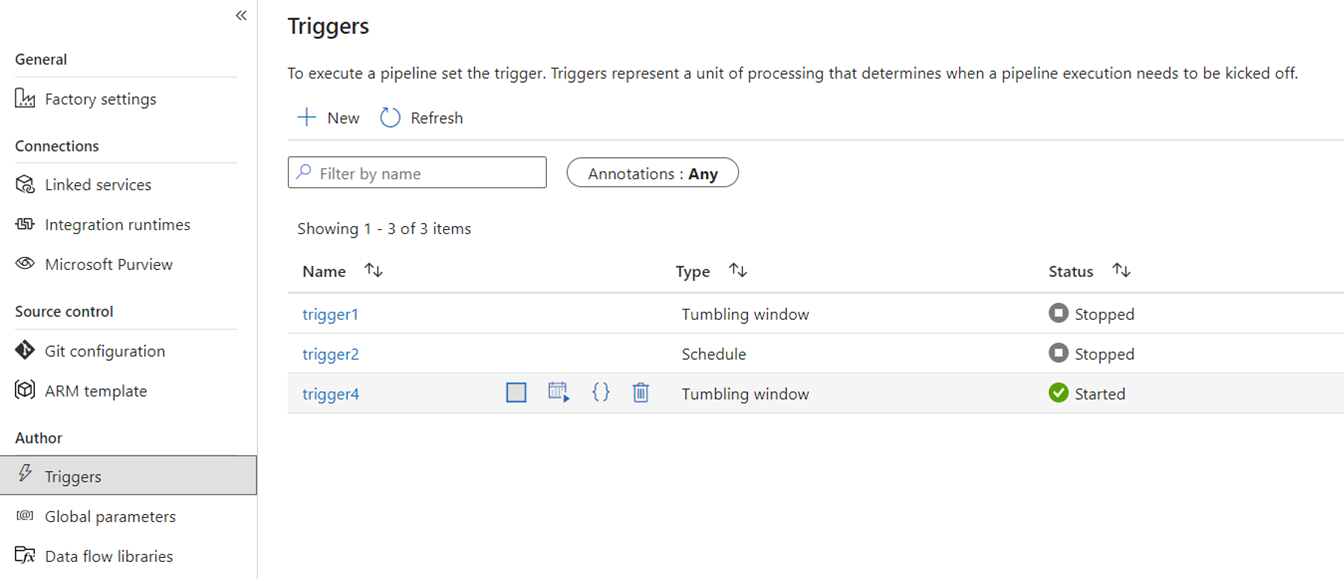
Fabric Data Activator has alerts that can be used to create file event and custom event triggers. While schedule triggers are a separate entity in Fabric known as schedules. These schedules are at a platform-level in Fabric, and not specific to pipelines. They also aren't referred to as triggers in Fabric.
To migrate your triggers from ADF to Fabric, think about rebuilding your schedule triggers simply as schedules that are properties of your Fabric pipelines. And for all other trigger types, use the Triggers button inside the Fabric pipeline or use Data Activator natively in Fabric.
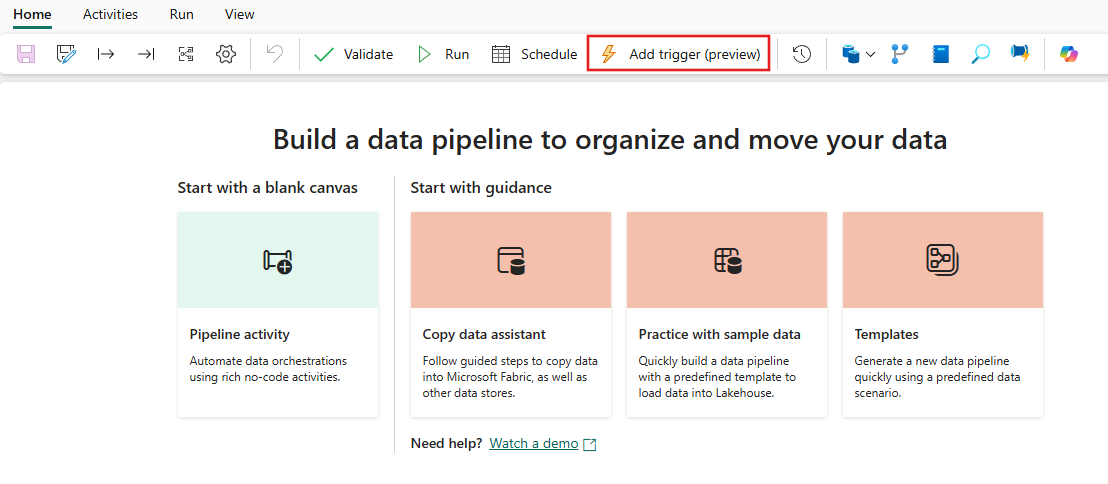
Debugging
Debugging pipelines is simpler in Fabric than in ADF. This simplicity is because Fabric Data Factory pipelines don't have a separate concept of debug mode that you find in ADF pipelines and data flows. Instead, when you build your pipeline, you're always in interactive mode. To test and debug your pipelines, you only need to select the play button from the Pipeline editor toolbar when you're ready in your development cycle. Pipelines in Fabric don't include the debug until stepwise pattern of debugging interactively. Instead, in Fabric, you utilize the activity state and set only the activities that you wish to test as active while setting all other activities to inactive to achieve the same testing and debug patterns. Refer to the following video that walks through how to achieve this debugging experience in Fabric.
Change Data Capture
Change Data Capture (CDC) in ADF is a preview feature that makes it easy to move data quickly in an incremental manner by applying source-side CDC features of your data stores. To migrate your CDC artifacts to Fabric Data Factory, you recreate these artifacts as Copy job items in your Fabric workspace. This feature provides similar capabilities of incremental data movement with an easy-to-use UI without requiring a pipeline, just like in ADF CDC. For more information, see the Copy job for Data Factory in Fabric.
Azure Synapse Link
Although not available in ADF, Synapse pipeline users frequently utilize Azure Synapse Link to replicate data from SQL databases to their data lake in turnkey approach. In Fabric, you recreate the Azure Synapse Link artifacts as Mirroring items in your workspace. For more information, see on Fabric database mirroring.
SQL Server Integration Services (SSIS)
SSIS is the on-premises data integration and ETL tool that Microsoft ships with SQL Server. In ADF, you can lift-and-shift your SSIS packages into the cloud using the ADF SSIS IR. In Fabric, we don't have the concept of IRs, so this functionality isn't possible today. However, we're working on enabling SSIS package execution natively from Fabric which we hope to bring to the product soon. In the meantime, the best way to execute SSIS packages in the cloud with Fabric Data Factory is to start an SSIS IR in your ADF factory and then invoke an ADF pipeline to call your SSIS packages. You can remote call an ADF pipeline from your Fabric pipelines using the Invoked pipeline activity described in the following section.
Invoke pipeline activity
A common activity that is used in ADF pipelines is the Execute pipeline activity which allows you to call another pipeline in your factory. In Fabric, we enhanced this activity as the Invoke pipeline activity. Refer to the Invoke pipeline activity documentation.
This activity is useful for migration scenarios where you have many ADF pipelines that use ADF-specific features like Mapping Data Flows or SSIS. You can maintain those pipelines as-is in ADF or even Synapse pipelines, and then call that pipeline inline from your new Fabric Data Factory pipeline by using the Invoke pipeline activity and pointing to the remote factory pipeline.
Sample migration scenarios
The following scenarios are common migration scenarios that you could encounter when migrating from ADF to Fabric Data Factory.
Scenario #1: ADF pipelines and data flows
The primary use cases for factory migrations are based on modernizing your ETL environment from the ADF factory PaaS model to the new Fabric SaaS model. The primary factory items to migrate are pipelines and data flows. There are several fundamental factory elements that you need to plan for migration outside of those two top-level items: linked services, integration runtimes, datasets, and triggers.
- Linked services need to be recreated in Fabric as connections in your pipeline activities.
- Datasets don't exist in Factory. The properties of your datasets are represented as properties inside pipeline activities like Copy or Lookup, while Connections contain other dataset properties.
- Integration runtimes don't exist in Fabric. However, your self-hosted IRs can be recreated using On-premises Data Gateways (OPDG) in Fabric and Azure virtual network IRs as managed virtual network gateways in Fabric.
- These ADF pipeline activities aren't included in Fabric Data Factory:
- Data Lake Analytics (U-SQL) - This feature is a deprecated Azure service.
- Validation activity - The validation activity in ADF is a helper activity that you can rebuild in your Fabric pipelines easily using a Get Metadata activity, a pipeline loop, and an If activity.
- Power Query - In Fabric, all dataflows are built using the Power Query UI, so you can just copy and paste your M code from your ADF Power Query activities and build them as dataflows in Fabric.
- If you're using any of the ADF pipeline capabilities that aren't found in Fabric Data Factory, use the Invoke pipeline activity in Fabric to call your existing pipelines in ADF.
- The following ADF pipeline activities are combined into a single-purpose activity:
- Azure Databricks activities (Notebook, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
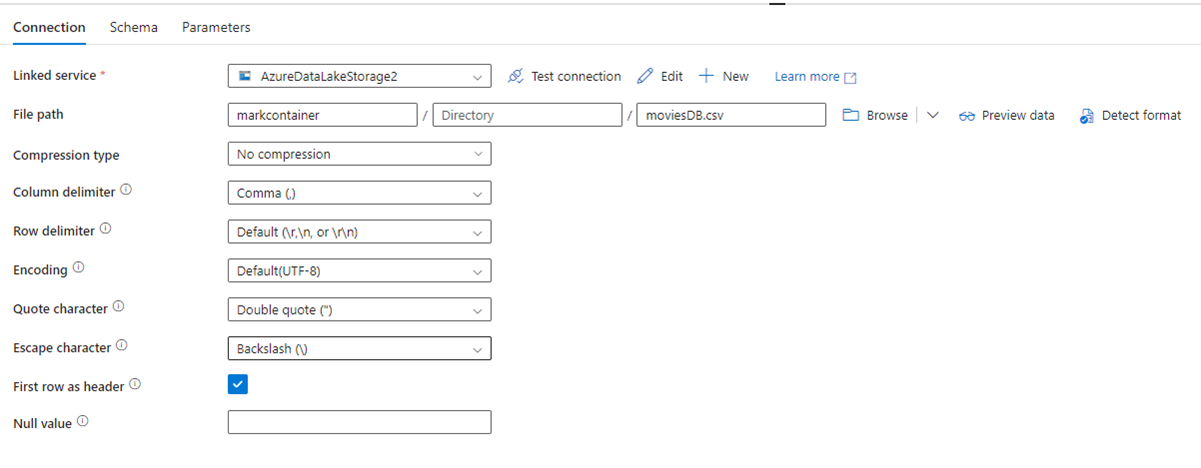
The following image shows the ADF dataset configuration page, with its file path and compression settings:
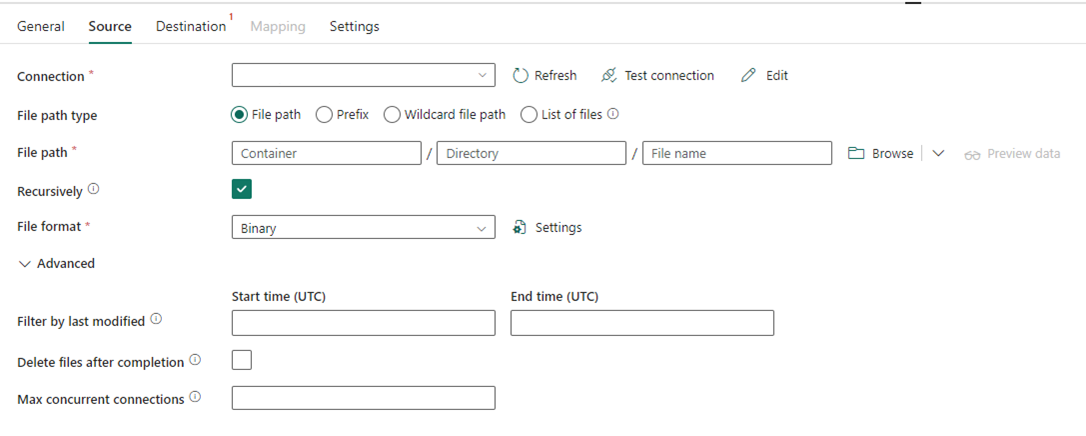
The following image shows the configuration of the Copy activity for Data Factory in Fabric, where compression and file path are inline in the activity:
Scenario #2: ADF with CDC, SSIS, and Airflow
CDC & Airflow in ADF are preview features while SSIS in ADF is a generally available feature for many years. Each of these features serves different data integration needs, but require special attention when migrating from ADF to Fabric. Change Data Capture (CDC) is a top-level ADF concept but in Fabric, you see this capability as the Copy job.
Airflow is the ADF cloud-managed Apache Airflow feature and is also available in Fabric Data Factory. You should be able to use the same Airflow source repo or take your DAGs and copy/paste the code into the Fabric Airflow offering with little to no change required.
Scenario #3: Git-enabled Data Factory migration to Fabric
It's common, although not required, that your ADF or Synapse factories and workspaces are connected to your own external Git provider in ADO or GitHub. In this scenario, you need to migrate your factory and workspace items to a Fabric workspace and then set-up Git integration on your Fabric workspace.
Fabric provides two primary ways to enable CI/CD, both at the workspace level: Git integration, where you bring your own Git repo in ADO and connect to it from Fabric and built-in deployment pipelines where you can promote code to higher environments without the need of bringing your own Git.
In both cases, your existing Git repo from ADF doesn't work with Fabric. Instead, you need to point to a new repo, or start a new deployment pipeline in Fabric, and rebuild your pipeline artifacts in Fabric.
Mount your existing ADF instances directly to a Fabric workspace
Previously, we spoke about using the Fabric Data Factory Invoke Pipeline activity as a mechanism to maintain existing ADF pipeline investments and call them inline from Fabric. Within Fabric, you can take that similar concept one step further and mount the entire factory inside your Fabric workspace as a native Fabric item.
For more information about mounting usage scenarios, see Content collaboration and delivery scenarios.
Mounting your Azure Data Factory inside your Fabric workspace brings many benefits to consider. If you're new to Fabric and would like to keep your factories side-by-side within the same pane-of-glass, you can mount them into Fabric so that you can manage both inside of Fabric. The complete ADF UI is now available to you from your mounted factory where you can monitor, manage, and edit your ADF factory items fully from within the Fabric workspace. This feature makes it much easier to begin migrating these items into Fabric as native Fabric artifacts. This feature is primarily for ease-of-use and makes it easy to see your ADF factories in your Fabric workspace. However, the actual execution of the pipelines, activities, integration runtimes, etc., still occurs inside of your Azure resources.