Process event data with event processor editor
The event processor editor is a no-code experience that allows you to drag and drop to design the event data processing logic. This article describes how to use the editor to design your processing logic.
Note
Enhanced capabilities are enabled by default when you create eventstreams now. If you have eventstreams that were created using standard capabilities, those eventstreams will continue to work. You can still edit and use them as usual. We recommend that you create a new eventstream to replace standard eventstreams so that you can take advantage of additional capabilities and benefits of enhanced eventstreams.
Prerequisites
Before you start, you must complete the following prerequisites:
- Access to a workspace in the Fabric capacity license mode (or) the Trial license mode with Contributor or higher permissions.
Design the event processing with the editor
To perform stream processing operations on your data streams using a no-code editor, follow these steps:
Select Edit on the ribbon if you aren't already in the edit mode. Ensure the upstream node for the operations that are connected has a schema.
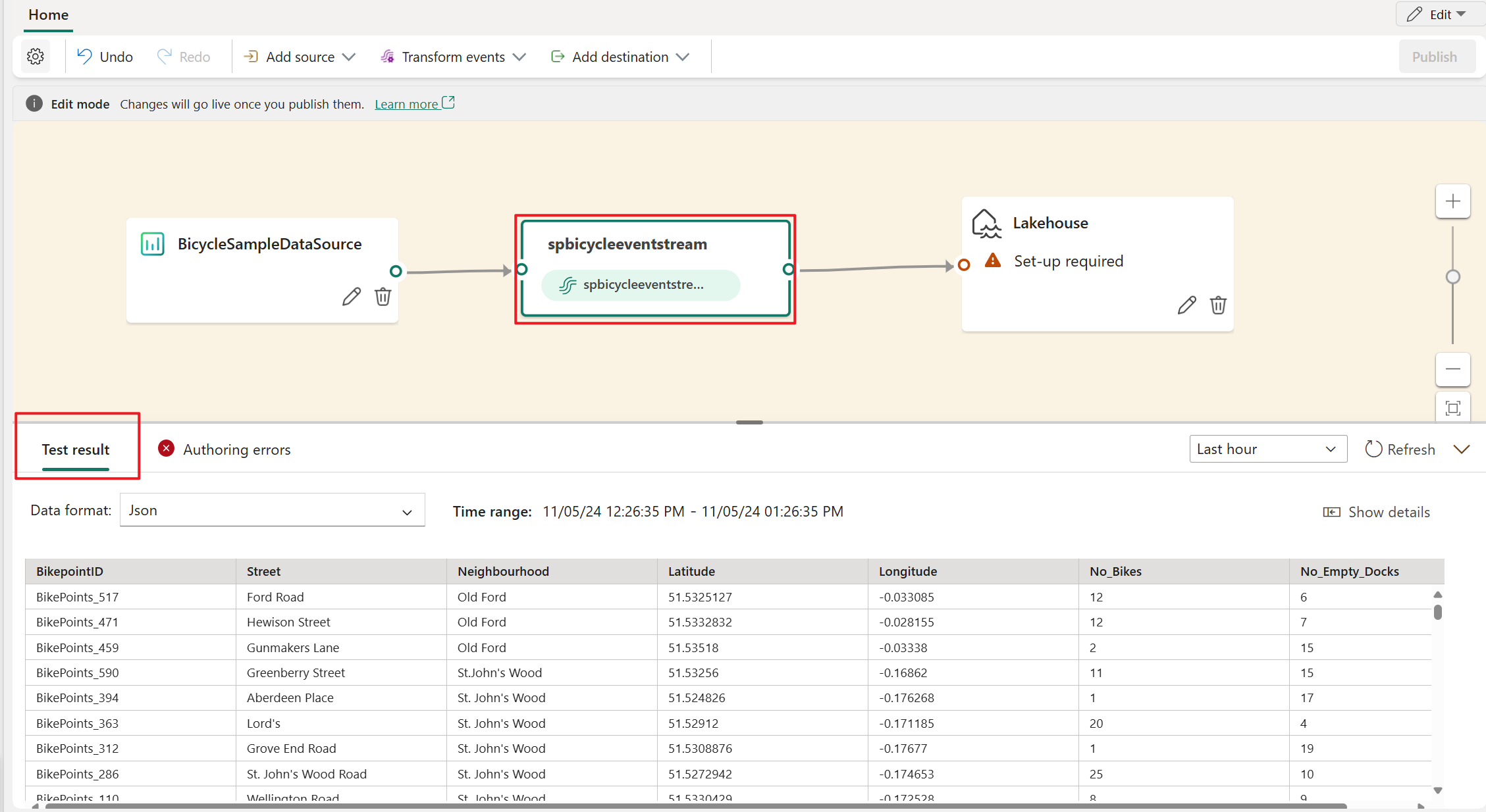
To insert an event processing operator between stream node and destination in the edit mode, you can use one of the following two methods:
Insert the operator directly from the connection line. Hover on the connection line and then select the + button. A drop-down menu appears on the connection line, and you can select an operator from this menu.
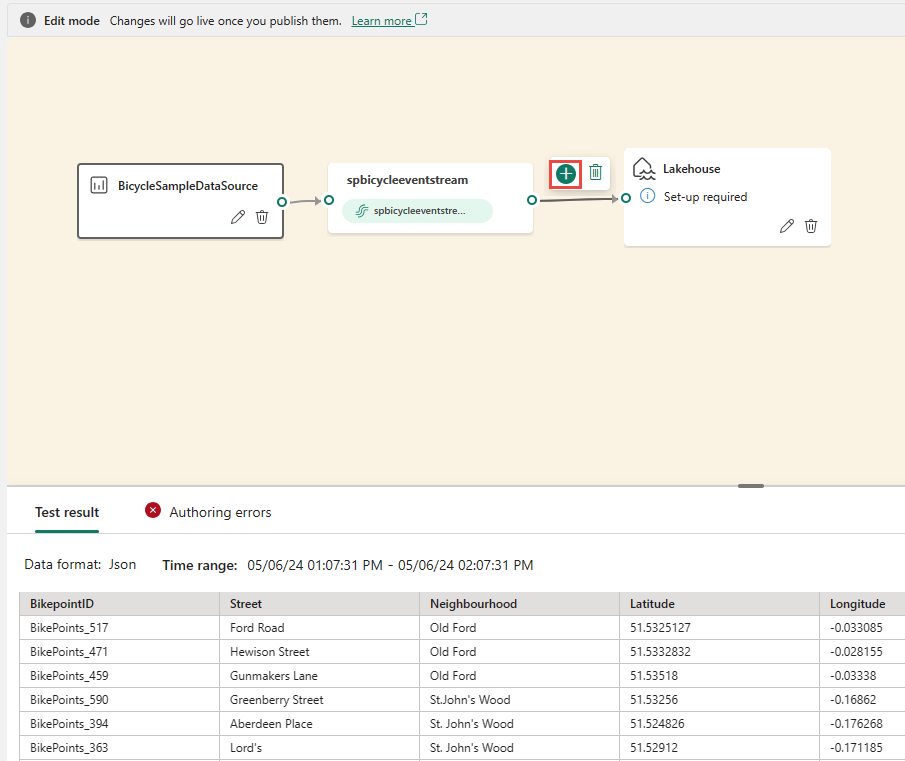
Insert the operator from ribbon menu or canvas.
You can select an operator from the Transform events menu in the ribbon.
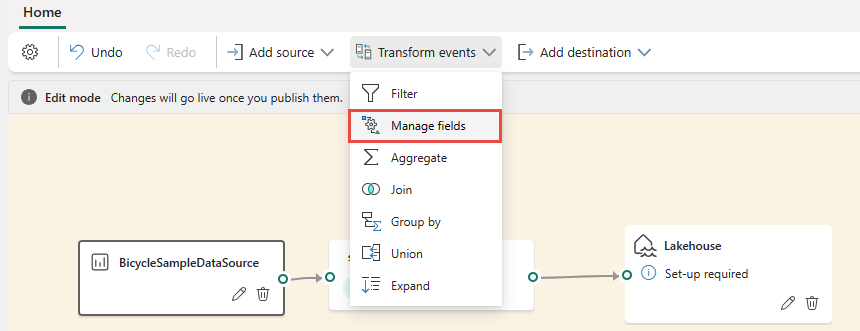
Alternatively, you can hover on one of the nodes and then select the + button if you deleted the connection line. A drop-down menu appears next to that node, and you can select an operator from this menu.
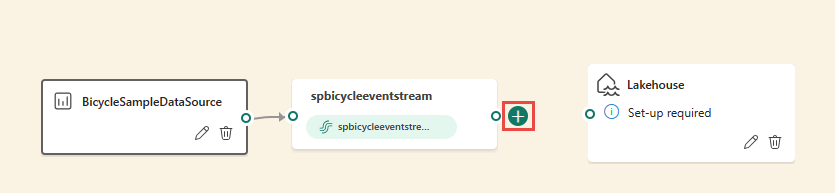
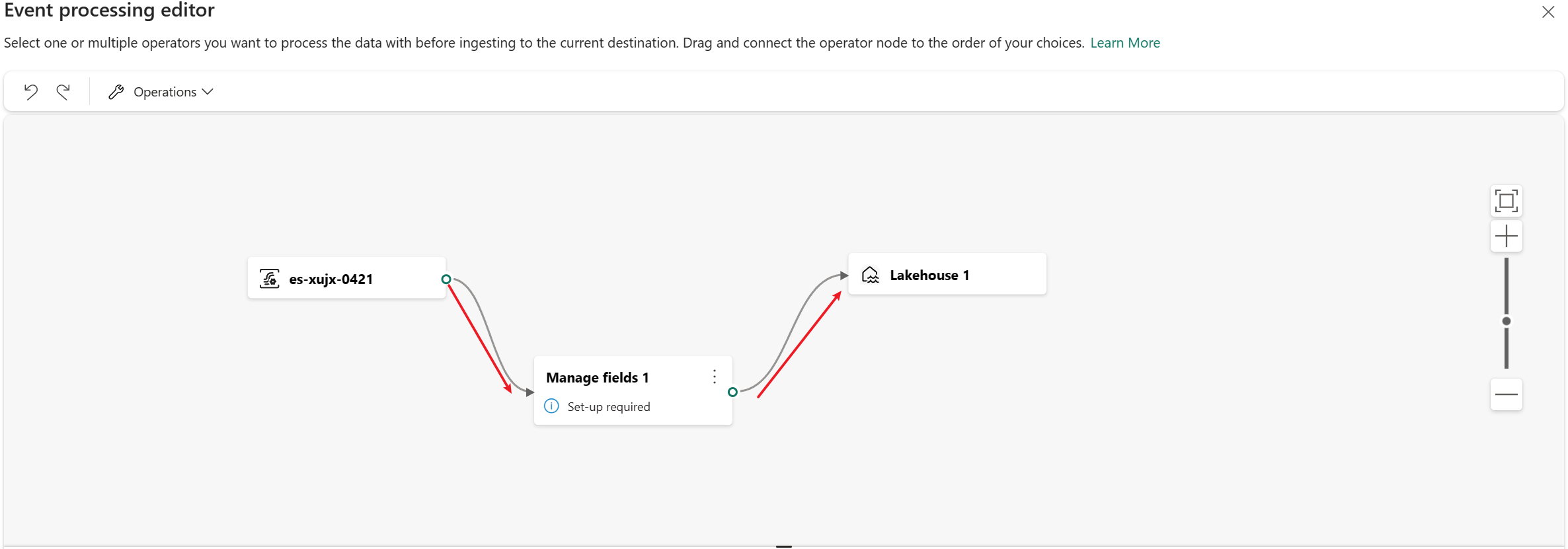
After inserting the operator, you need to reconnect these nodes. Hover on the left edge of the stream node, and then select and drag the green circle to connect it to the Manage fields operator node. Follow the same process to connect the Manage fields operator node to your destination.

Select the Manage fields operator node. In the Manage fields configuration panel, select the fields you want to output. If you want to add all fields, select Add all fields. You can also add a new field with the built-in functions to aggregate the data from upstream. (Currently, the built-in functions we support are some functions in String Functions, Date and Time Functions, Mathematical Functions. To find them, search on
built-in.)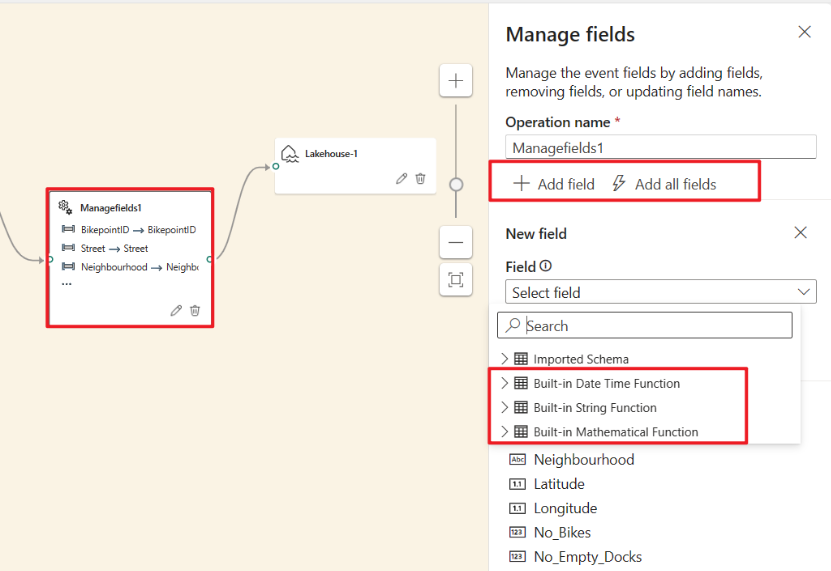
After you configured the Manage fields operator, select Refresh to validate test result produced by this operator.
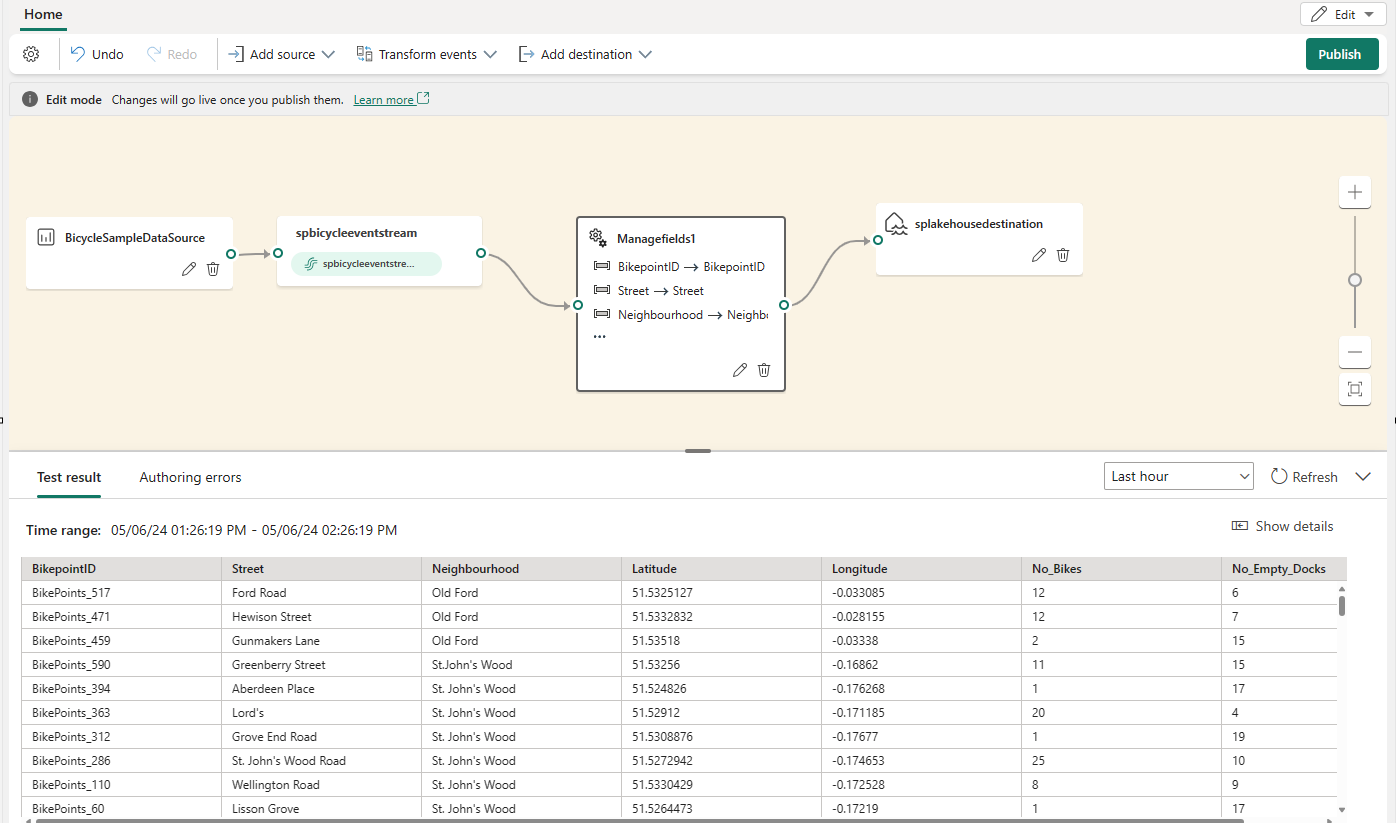
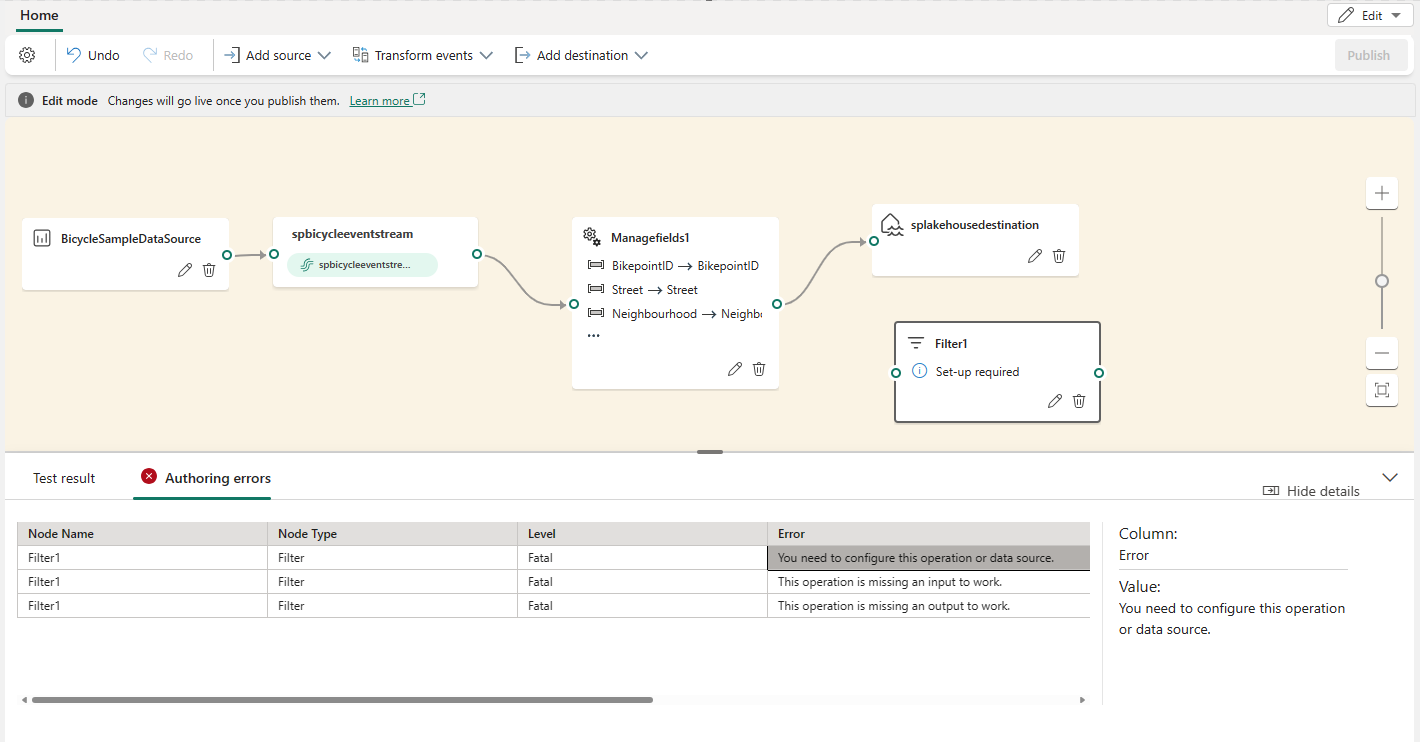
If you have any configuration errors, they appear in the Authoring errors tab in the bottom pane.
If your test result looks correct, select Publish to save the event processing logic and return to Live view.
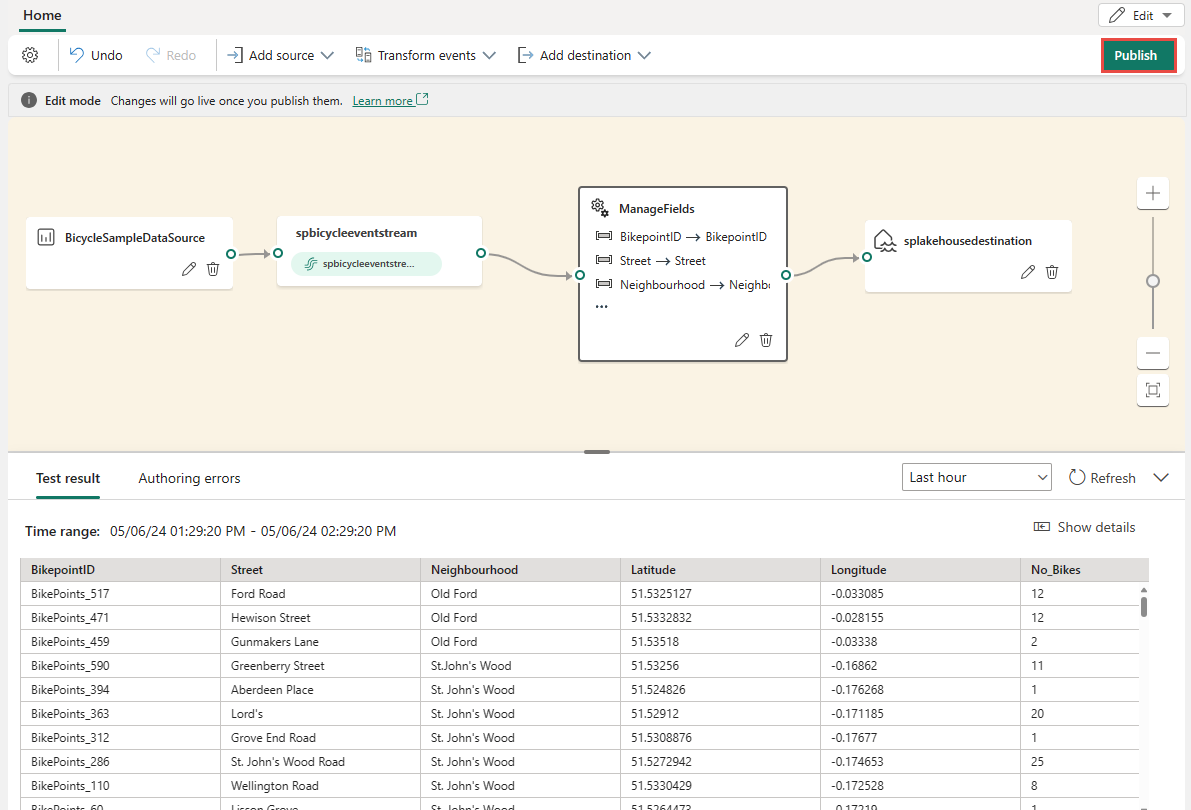
After you complete these steps, you can visualize how your eventstream start streaming and processing data in Live view.
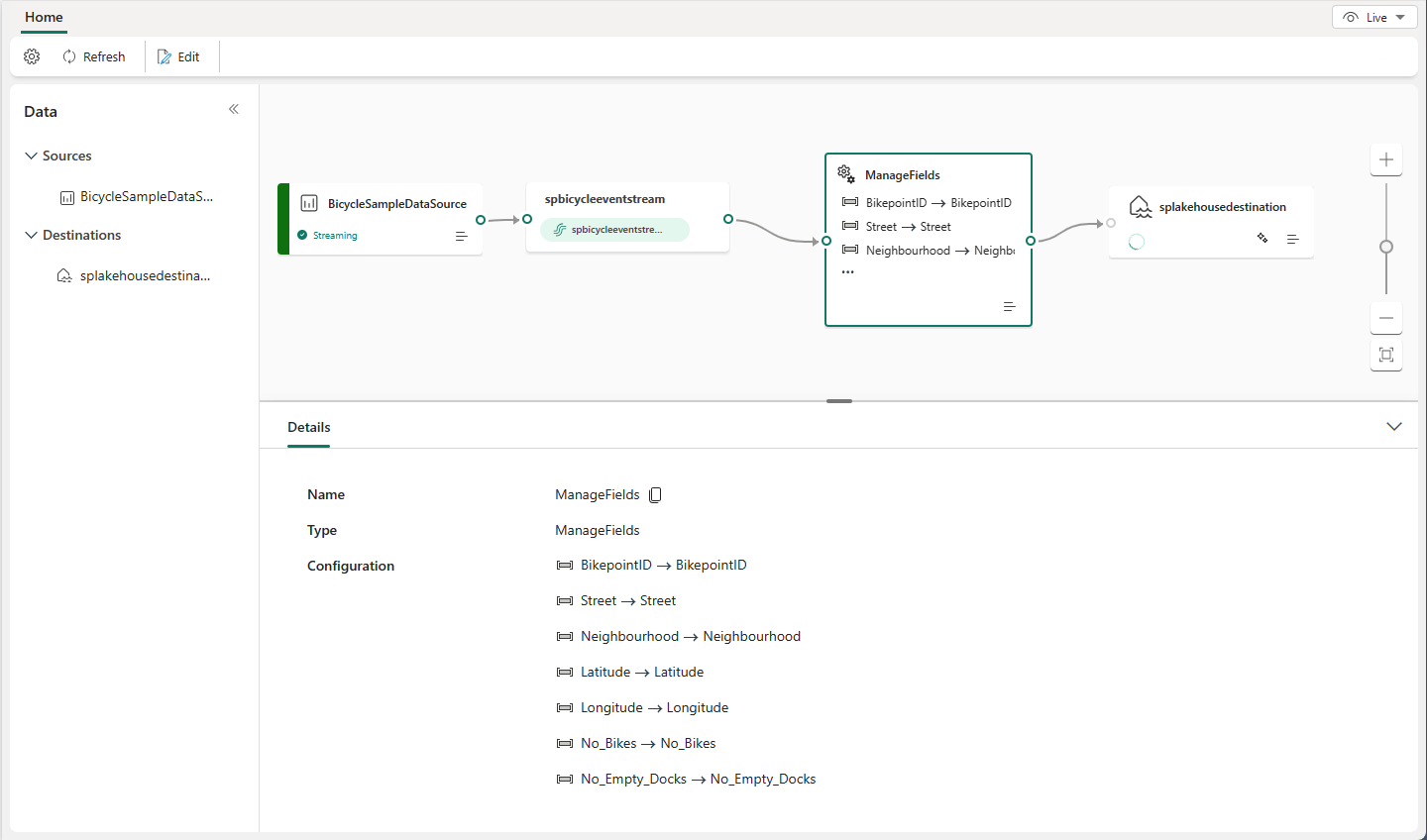









Event processing editor
The event processor editor (the canvas in Edit mode) allows you to transform data into various destinations. Enter Edit mode to design stream processing operations for your data streams.

The Edit mode includes a canvas and lower pane where you can:
- Build the event data transformation logic with drag and drop.
- Preview test result in each of the processing nodes from beginning to end.
- Discover any authoring errors within the processing nodes.
Editor layout

- Ribbon menu and Canvas (Numbered one in the image): In this pane, you can design your data transformation logic by selecting an operator (from the Transform events menu) and connecting the stream and the destination nodes via the newly created operator node. You can drag and drop connecting lines or select and delete connections.
- Right editing pane (two in the image): This pane allows you to configure the selected node or view stream name.
- Bottom pane with data preview and authoring error tabs (three in the image): In this pane, preview the test result in a selected node with Test result tab. The Authoring errors tab lists any incomplete or incorrect configuration in the operation nodes.
Supported node types and examples
Here are the destination types that support to add operators before ingestion:
- Lakehouse
- Eventhouse (Event processing before ingestion)
- Derived stream
- Activator
Note
For destinations that don't support pre-ingestion operator addition, you can first add a derived stream as the output of your operator. Then, append your intended destination to this derived stream.

The event processor in Lakehouse and KQL Database (Event processing before ingestion) allows you to process your data before it's ingested into your destination.
Prerequisites
Before you start, you must complete the following prerequisites:
- Access to a workspace in the Fabric capacity license mode (or) the Trial license mode with Contributor or higher permissions.
- Get access to a workspace with Contributor or above permissions where your lakehouse or KQL Database is located.
Design the event processing with the editor
To design your event processing with the event processor editor:
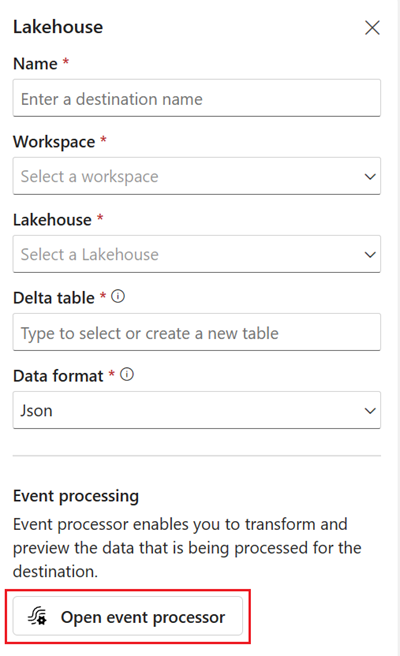
Add a Lakehouse destination and enter the necessary parameters in the right pane. (See Add and manage a destination in an eventstream for detailed instructions. )
Select Open event processor. The Event processing editor screen appears.
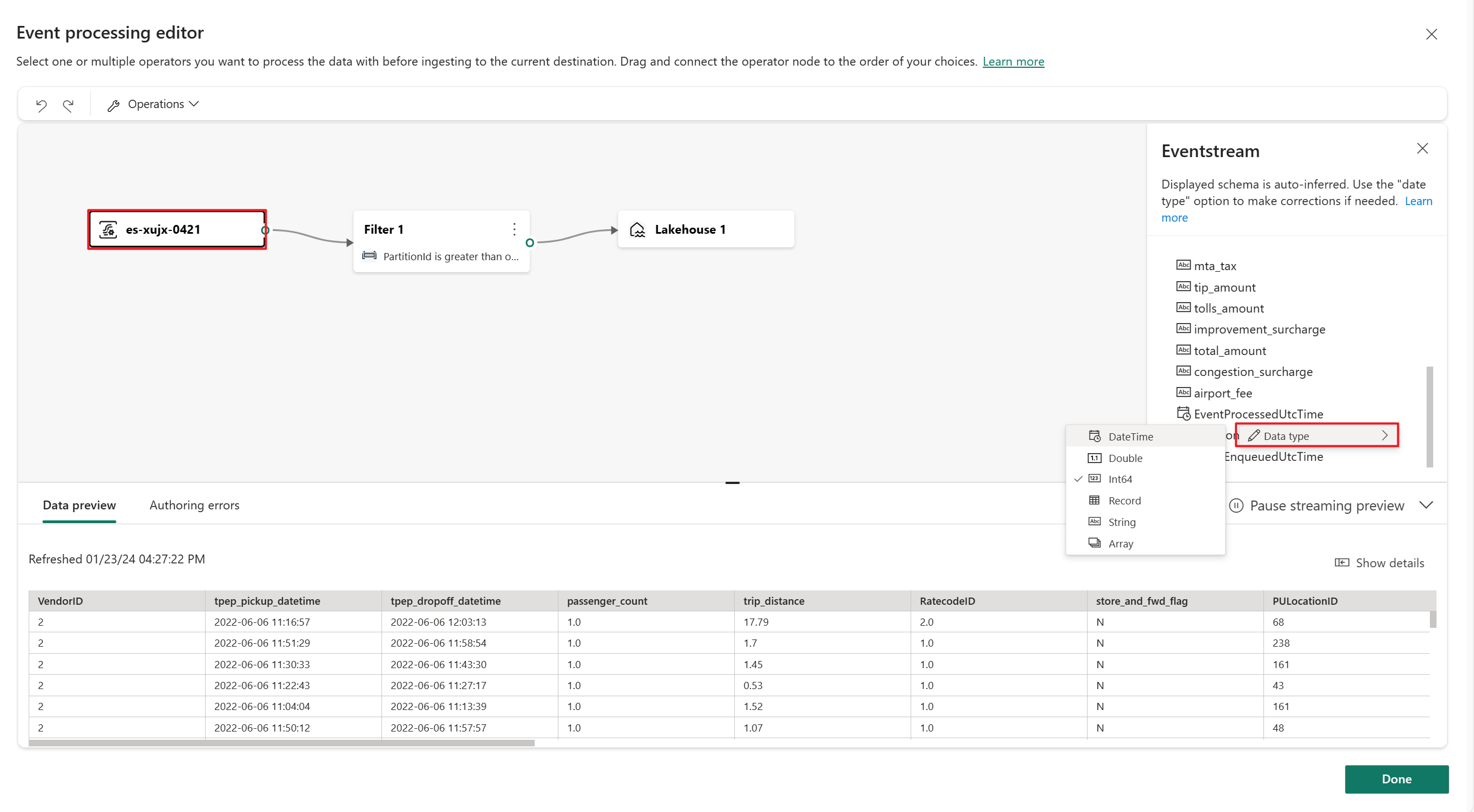
In the Event processing editor canvas, select the eventstream node. You can preview the data schema or change the data type in the right Eventstream pane.
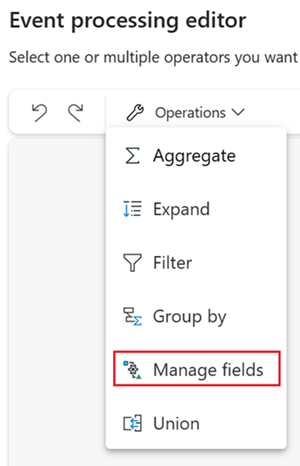
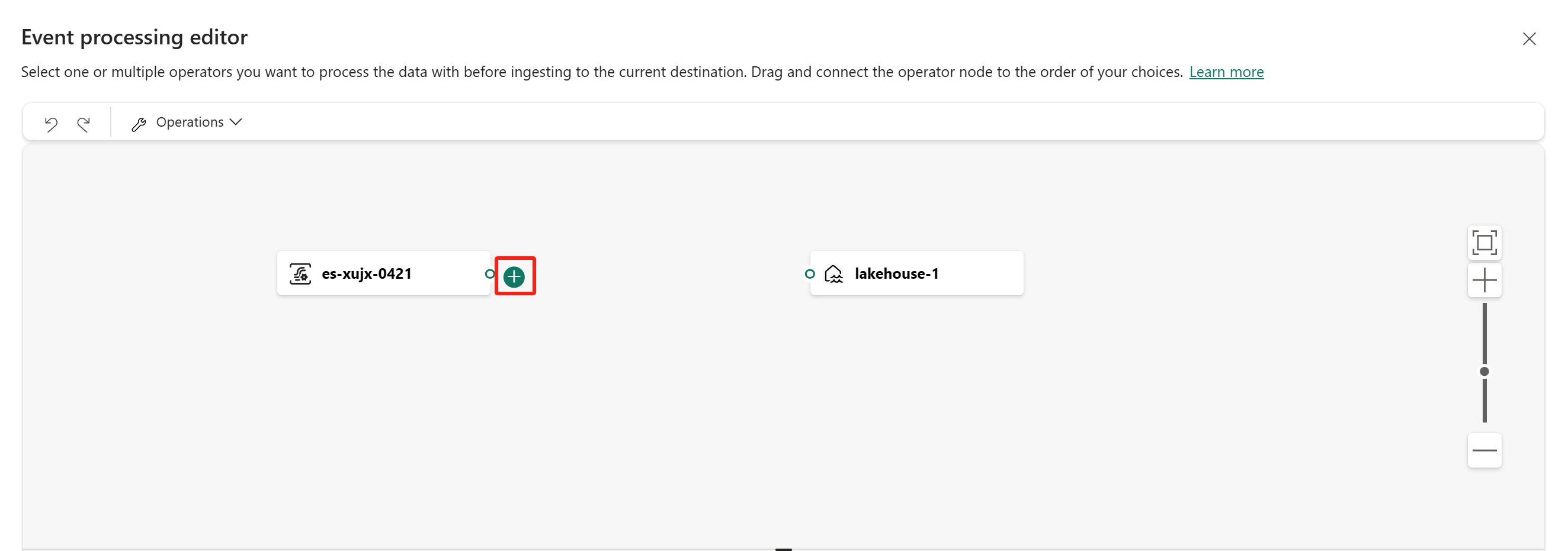
To insert an event processing operator between this eventstream and destination in the event processor editor, you can use one of the following two methods:
Insert the operator directly from the connection line. Hover on the connection line and then select the "+" button. A drop-down menu appears on the connection line, and you can select an operator from this menu.
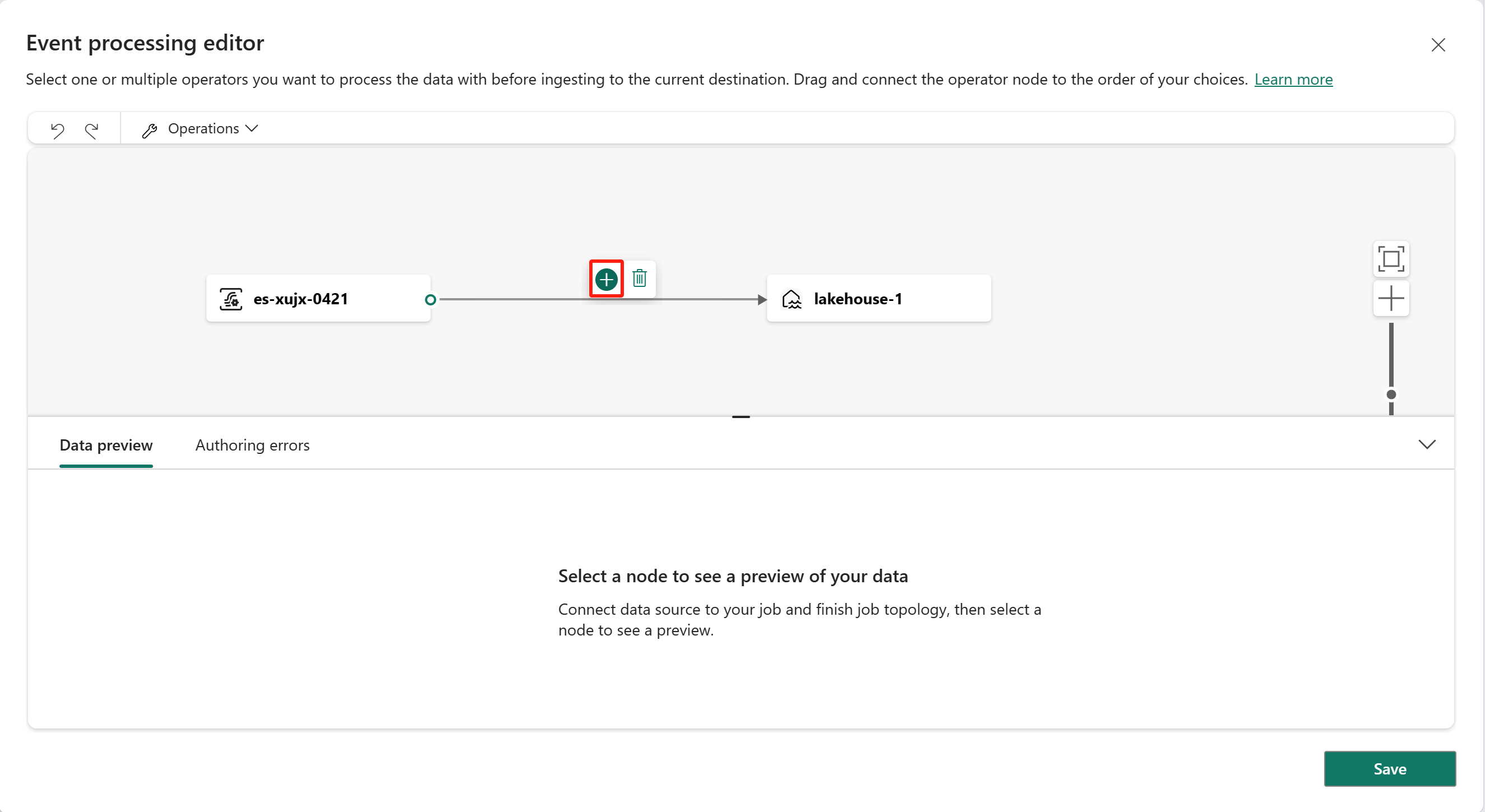
Insert the operator from ribbon menu or canvas.
You can select an operator from the Operations menu in the ribbon. Alternatively, you can hover on one of the nodes and then select the "+" button if you deleted the connection line. A drop-down menu appears next to that node, and you can select an operator from this menu.
Finally, you need to reconnect these nodes. Hover on the left edge of the eventstream node, and then select and drag the green circle to connect it to the Manage fields operator node. Follow the same process to connect the Manage fields operator node to the lakehouse node.
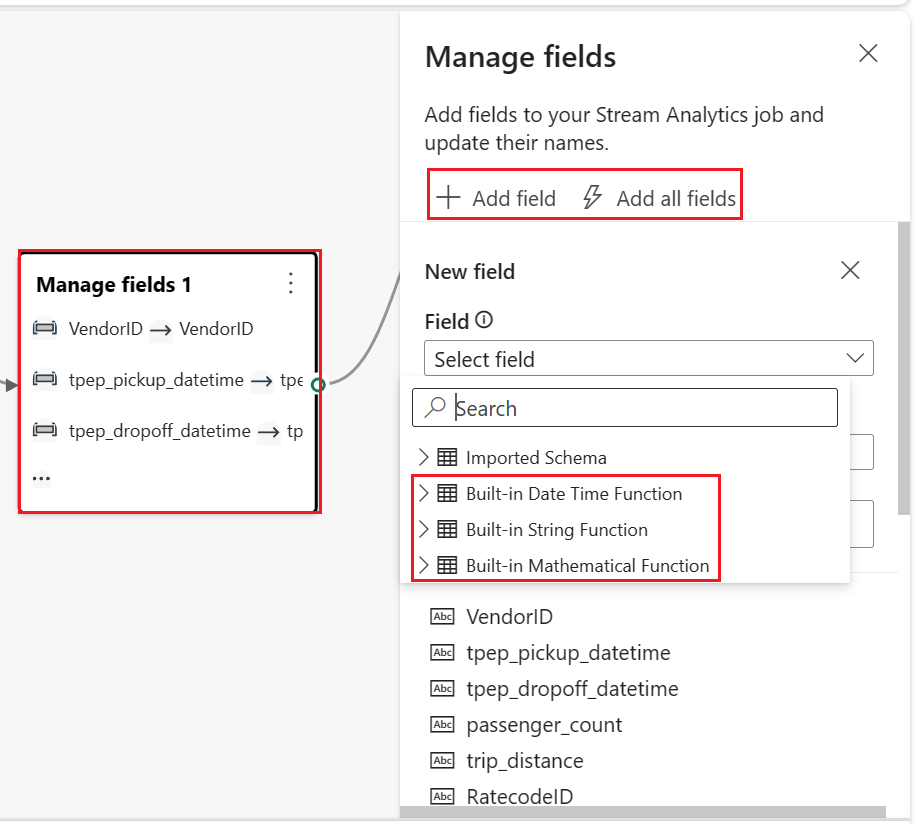
Select the Manage fields operator node. In the Manage fields configuration panel, select the fields you want to output. If you want to add all fields, select Add all fields. You can also add a new field with the built-in functions to aggregate the data from upstream. (Currently, the built-in functions we support are some functions in String Functions, Date and Time Functions, Mathematical Functions. To find them, search on "built-in.")
After you configured the Manage fields operator, select Refresh static preview to preview the data this operator produces.
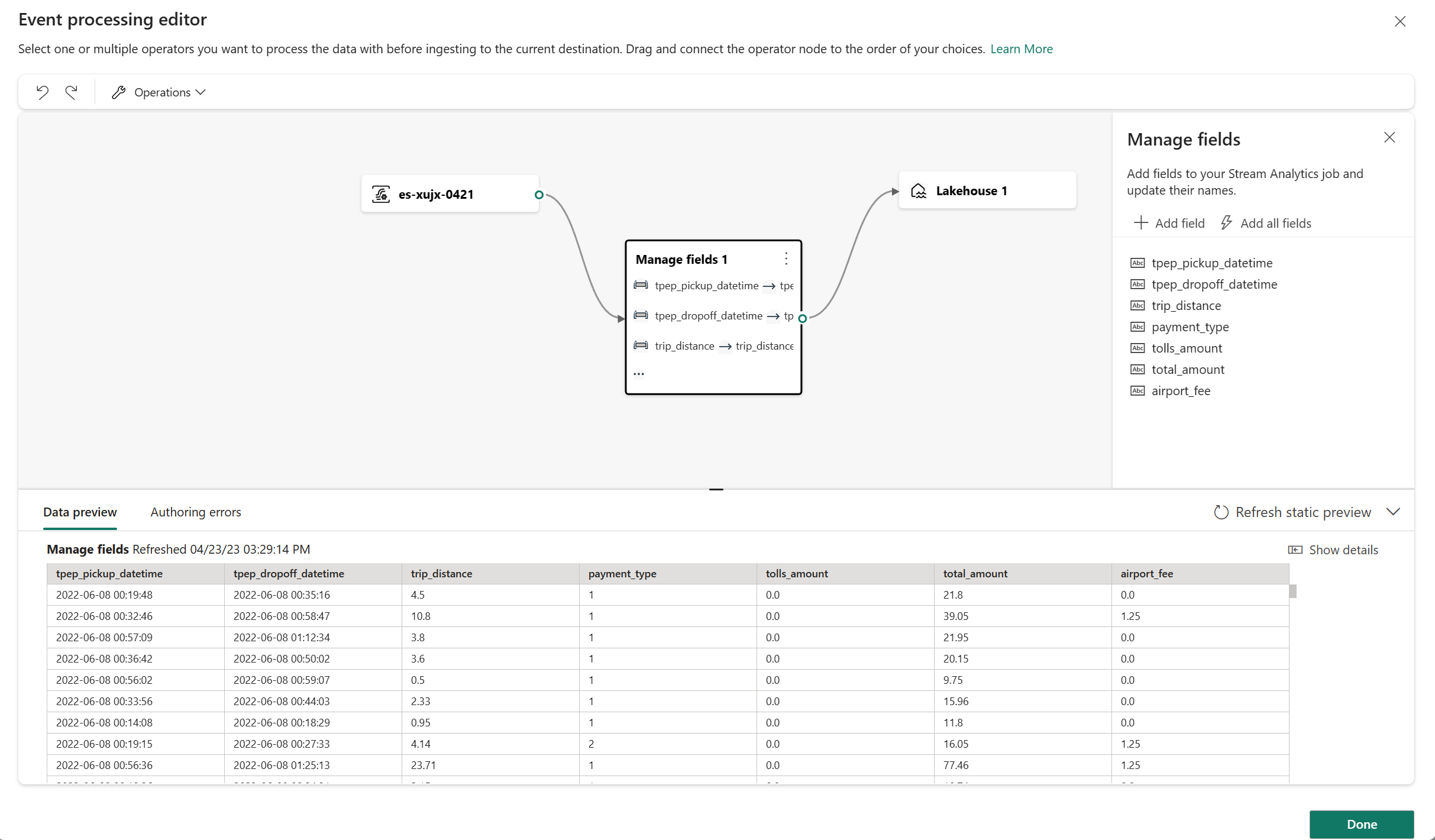
If you have any configuration errors, they appear in the Authoring error tab in the bottom pane.
If your previewed data looks correct, select Done to save the event processing logic and return to the Lakehouse destination configuration screen.
Select Add to complete the creation of your lakehouse destination.




Event processor editor
The Event processor enables you to transform the data that you're ingesting into a lakehouse destination. When you configure your lakehouse destination, you find the Open event processor option in the middle of the Lakehouse destination configuration screen.

Selecting Open event processor launches the Event processing editor screen, where you can define your data transformation logic.
The event processor editor includes a canvas and lower pane where you can:
- Build the event data transformation logic with drag and drop.
- Preview the data in each of the processing nodes from beginning to end.
- Discover any authoring errors within the processing nodes.
The screen layout is like the main editor. It consists of three sections, shown in the following image:

Canvas with diagram view: In this pane, you can design your data transformation logic by selecting an operator (from the Operations menu) and connecting the eventstream and the destination nodes via the newly created operator node. You can drag and drop connecting lines or select and delete connections.
Right editing pane: This pane allows you to configure the selected operation node or view the schema of the eventstream and destination.
Bottom pane with data preview and authoring error tabs: In this pane, preview the data in a selected node with Data preview tab. The Authoring errors tab lists any incomplete or incorrect configuration in the operation nodes.
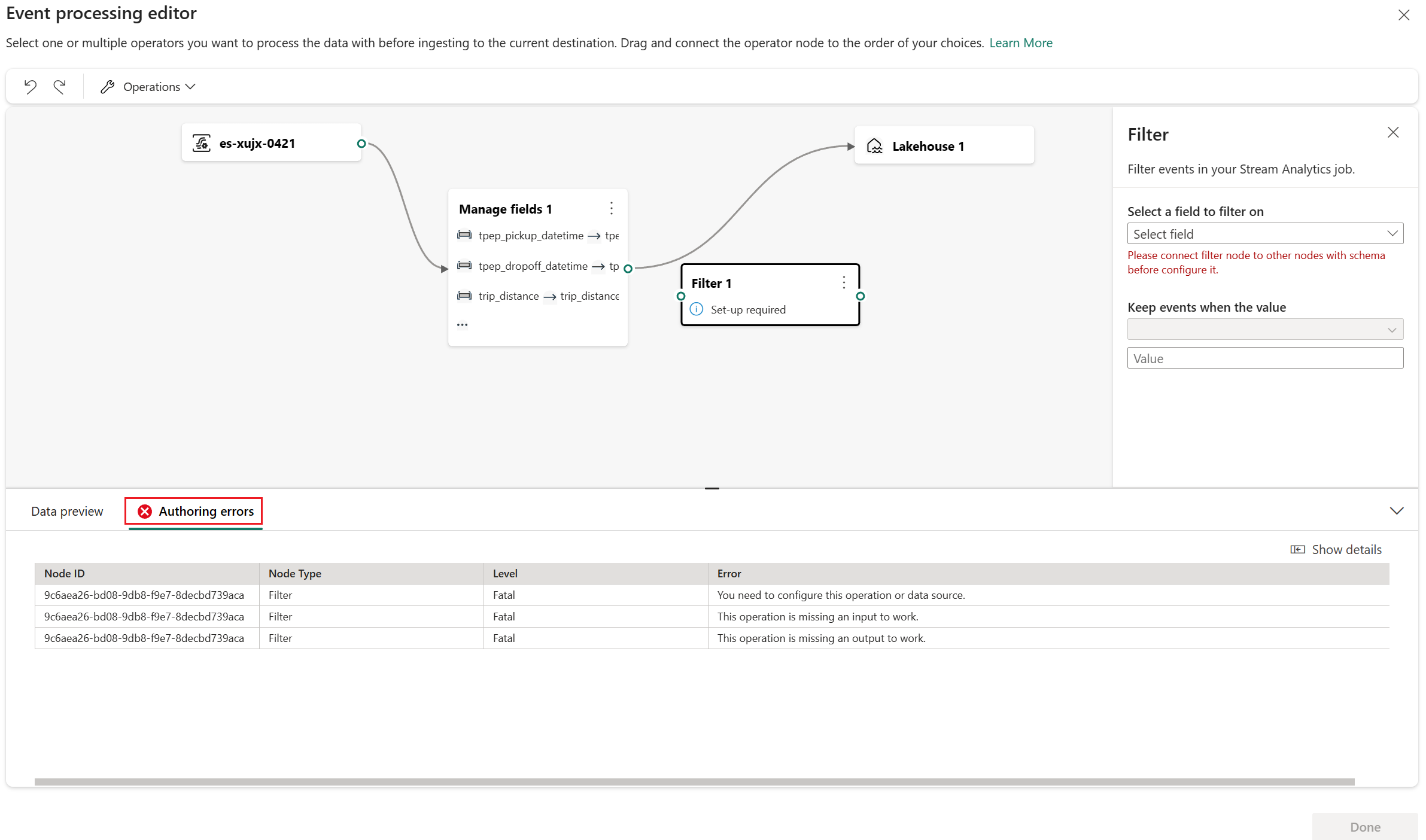
Authoring errors
Authoring errors refers to the errors that occur in the Event processor editor due to incomplete or incorrect configuration of the operation nodes, helping you find and fix potential problems in your event processor.
You can view Authoring errors in the bottom panel of the Event processor editor. The bottom panel lists all the authoring errors, each authoring error has four columns:
- Node ID: Indicates the ID of the operation node where the Authoring error occurred.
- Node type: Indicates the type of the operation node where the Authoring error occurred.
- Level: Indicates the severity of the Authoring error, there are two levels, Fatal and Information. Fatal level authoring error means that your event processor has serious problems and can't be saved or run. Information level authoring error means that your event processor has some tips or suggestions that can help you optimize or improve your event processor.
- Error: Indicates the specific information of the authoring error, briefly describing the cause and impact of the authoring error. You can select the Show details tab to see details.
Since Eventstream and Eventhouse support different data types, the process of data type conversion might generate authoring errors.
The following table shows the results of data type conversion from Eventstream to Eventhouse. The columns represent the data types supported by Eventstream, and the rows represent the data types supported by Eventhouse. The cells indicate the conversion results, which can be one of the following three:
✔️ Indicates successful conversion, no errors, or warnings are generated.
❌ Indicates impossible conversion, fatal authoring error is generated. The error message is similar to: The data type "{1}" for the column "{0}" doesn't match the expected type "{2}" in the selected KQL table, and can't be autoconverted.
⚠️ Indicates possible but inaccurate conversion, information authoring error is generated. The error message is similar to: The data type "{1}" for the column "{0}" doesn't exactly match the expected type "{2}" in the selected KQL table. It's autoconverted to "{2}".
| string | bool | datetime | dynamic | guid | int | long | real | timespan | decimal | |
|---|---|---|---|---|---|---|---|---|---|---|
| Int64 | ❌ | ❌ | ❌ | ✔️ | ❌ | ⚠️ | ✔️ | ⚠️ | ❌ | ✔️ |
| Double | ❌ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ⚠️ | ❌ | ⚠️ |
| String | ✔️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Datetime | ⚠️ | ❌ | ✔️ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Record | ⚠️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Array | ⚠️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
As you can see from the table, some data type conversions are successful, such as string to string. These conversions don't generate any authoring errors, and don't affect the operation of your event processor.
Some data type conversions are impossible, such as int to string. These conversions generate fatal level authoring errors, causing your event processor to fail to save. You need to change your data type either in your Eventstream or in KQL table to avoid these errors.
Some data type conversions are possible, but not precise, such as int to real. These conversions generate information level authoring errors, indicating the mismatch between data types, and the automatic conversion results. These conversions might cause your data to lose precision or structure. You can choose whether to ignore these errors, or modify your data type either in your Eventstream or in KQL table to optimize your event processor.
Transformation operators
The event processor provides seven operators, which you can use to transform your event data according to your business needs.
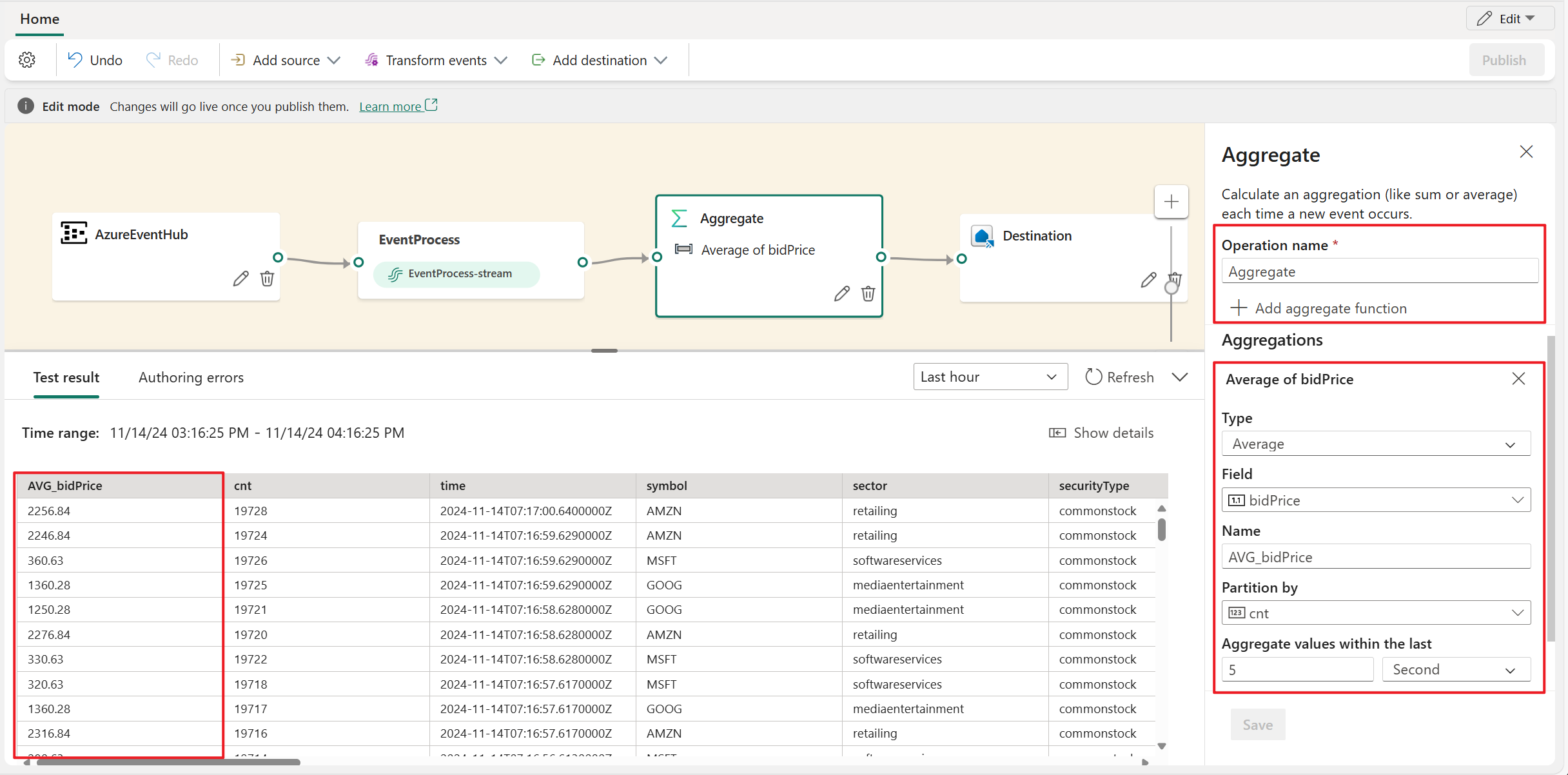
Aggregate
Use the Aggregate transformation to calculate an aggregation (Sum, Minimum, Maximum, or Average) every time a new event occurs over a period of time. This operation also allows for the renaming of these calculated columns, and filtering or slicing the aggregation based on other dimensions in your data. You can have one or more aggregations in the same transformation.
- Operator name: Specify the name of the aggregation operation.
- Add aggregate function: Add one or more aggregations in aggregate operation.
- Type: Choose an aggregation type: Sum, Minimum, Maximum, or Average.
- Field: Select the column to process.
- Name: Define a name for this aggregation function.
- Partition by: Select a column to group the aggregation.
- Aggregate values within the last: Specify a time window for aggregation (default is 5 seconds).
Expand
Use the Expand array transformation to create a new row for each value within an array. You can choose create row for missing/empty array , or don't create row for missing/empty array.
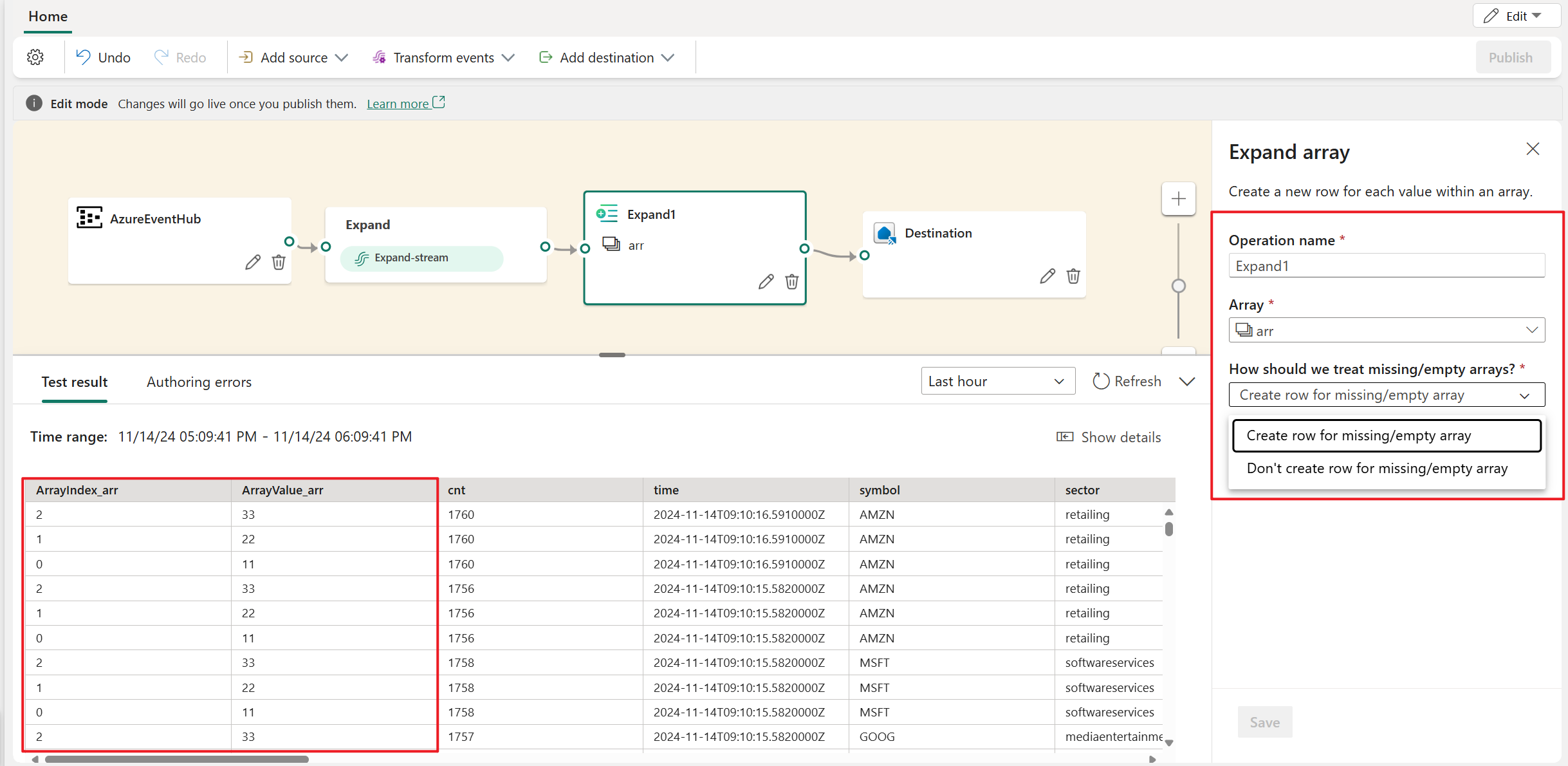
Filter
Use the Filter transformation to filter events based on the value of a field in the input. Depending on the data type (number or text), the transformation keeps the values that match the selected condition, such as is null or is not null.
Group by
Use the Group by transformation to calculate aggregations across all events within a certain time window. You can group by the values in one or more fields. It's like the Aggregate transformation allows for the renaming of columns, but provides more options for aggregation and includes more complex options for time windows. Like Aggregate, you can add more than one aggregation per transformation.
The aggregations available in the transformation are:
- Average
- Count
- Maximum
- Minimum
- Percentile (continuous and discrete)
- Standard Deviation
- Sum
- Variance
In time-streaming scenarios, performing operations on the data contained in temporal windows is a common pattern. The event processor supports windowing functions, which is integrated with the Group by operator. You can define it in the setting of this operator.

Manage fields
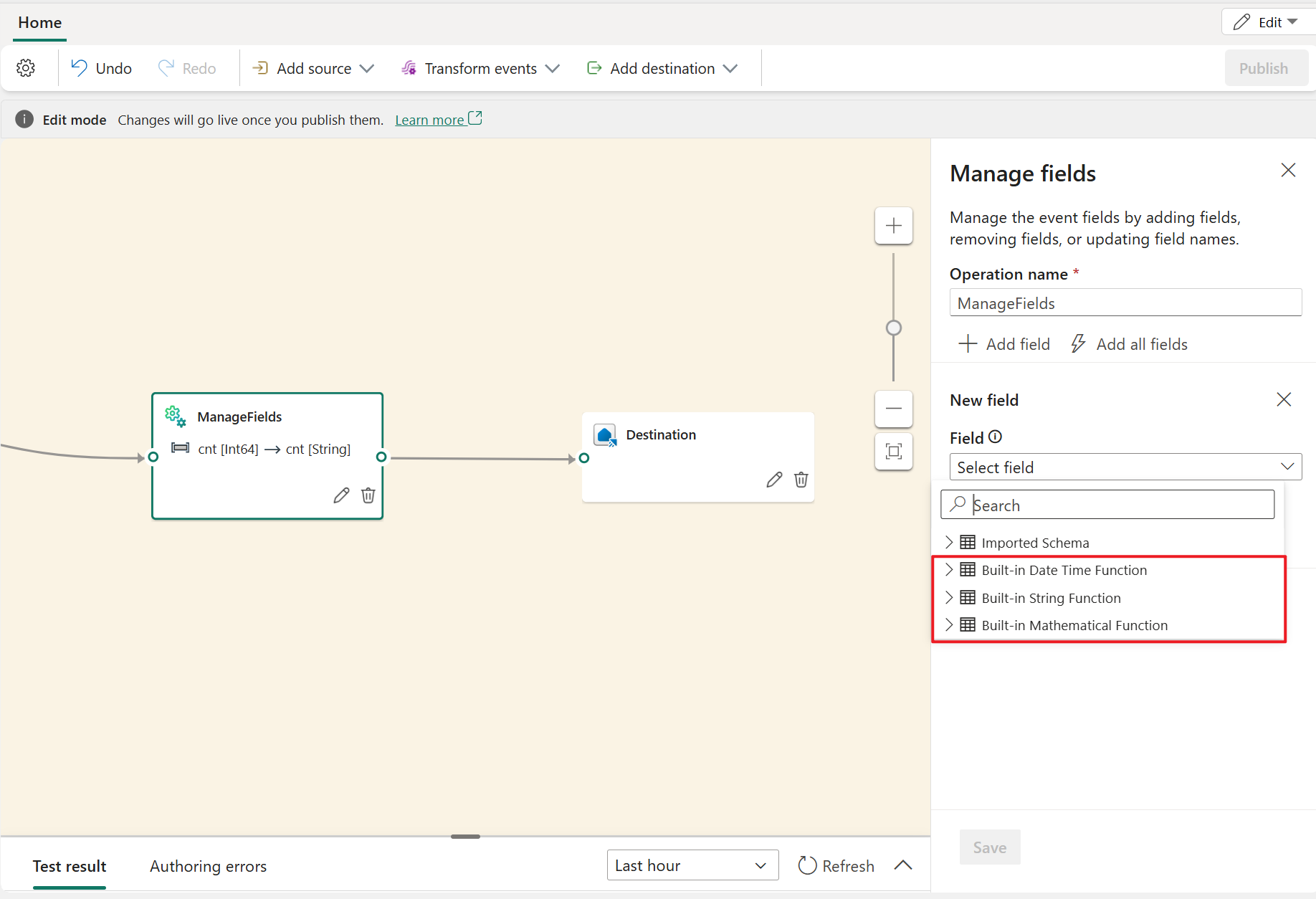
The Manage fields transformation allows you to add, remove, change data type, or rename fields coming in from an input or another transformation. The side pane settings give you the option of adding a new field by selecting Add field, adding multiple fields, or adding all fields at once.
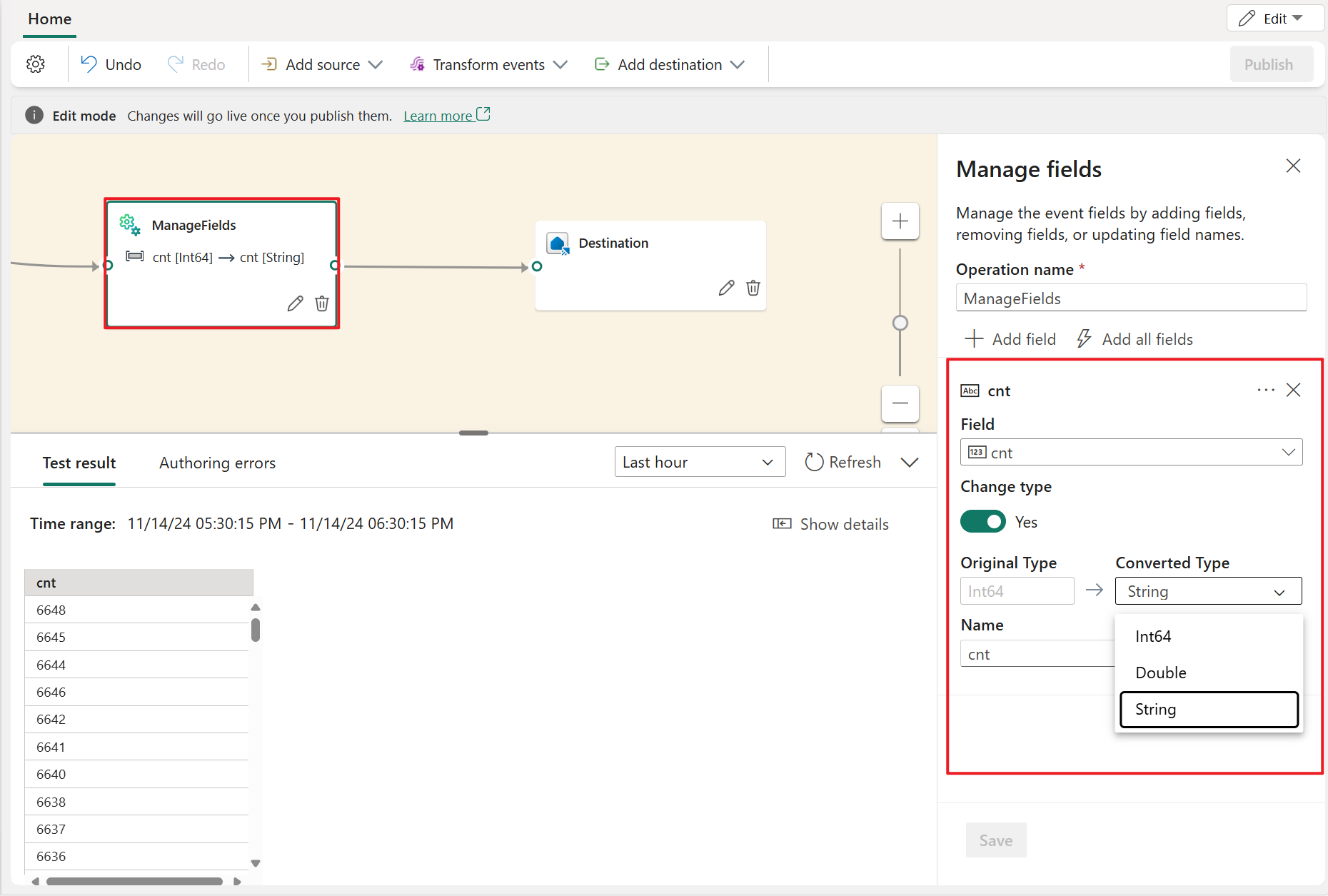
Furthermore, you can add a new field with the built-in functions to aggregate the data from upstream. (Currently, the built-in functions we support are some functions in String Functions, Date and Time Functions, and Mathematical Functions. To find them, search on "built-in.")
The following table shows the results of changing the data type using manage fields. The columns represent the original data types, and the rows represent the target data type.
- If there's a ✔️ in the cell, it means that it can be converted directly and the target data type option is shown in the dropdown list.
- If there's a ❌ in the cell, it means that it can't be converted and the target data type option isn't shown in the dropdown list.
- If there's a ⚠️ in the cell, it means that it can be converted, but it needs to meet certain conditions, such as the string format must conform to the requirements of the target data type. For example, when converting from string to int, the string needs to be a valid integer form, such as
123, notabc.
| Int64 | Double | String | Datetime | Record | Array | |
|---|---|---|---|---|---|---|
| Int64 | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| Double | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| String | ⚠️ | ⚠️ | ✔️ | ⚠️ | ❌ | ❌ |
| Datetime | ❌ | ❌ | ✔️ | ✔️ | ❌ | ❌ |
| Record | ❌ | ❌ | ✔️ | ❌ | ✔️ | ❌ |
| Array | ❌ | ❌ | ✔️ | ❌ | ❌ | ✔️ |
Union
Use the Union transformation to connect two or more nodes and add events that shared fields (with the same name and data type) into one table. Fields that don't match are dropped and not included in the output.
Join
Use the Join transformation to combine events from two inputs based on the field pairs that you select. If you don't select a field pair, the join is based on time by default. The default is what makes this transformation different from a batch one.
As with regular joins, you have options for your join logic:
- Inner join: Include only records from both tables where the pair matches.
- Left outer join: Include all records from the left (first) table and only the records from the second one that match the pair of fields. If there's no match, the fields from the second input are blank.