Options to get data into the Fabric Lakehouse
The get data experience covers all user scenarios for bringing data into the lakehouse, like:
- Connecting to existing SQL Server and copying data into Delta table on the lakehouse.
- Uploading files from your computer.
- Copying and merging multiple tables from other lakehouses into a new Delta table.
- Connecting to a streaming source to land data in a lakehouse.
- Referencing data without copying it from other internal lakehouses or external sources.
Different ways to load data into a lakehouse
In Microsoft Fabric, there are a few ways you can get data into a lakehouse:
- File upload from local computer
- Run a copy tool in pipelines
- Set up a dataflow
- Apache Spark libraries in notebook code
- Stream real-time events with Eventstream
- Get data from Eventhouse
Local file upload
You can also upload data stored on your local machine. You can do it directly in the Lakehouse explorer.

Copy tool in pipelines
The Copy tool is a highly scalable Data Integration solution that allows you to connect to different data sources and load the data either in original format or convert it to a Delta table. Copy tool is a part of pipelines activities that you can modify in multiple ways, such as scheduling or triggering based on an event. For more information, see How to copy data using copy activity.
Dataflows
For users that are familiar with Power BI dataflows, the same tool is available to load data into your lakehouse. You can quickly access it from the Lakehouse explorer "Get data" option, and load data from over 200 connectors. For more information, see Quickstart: Create your first dataflow to get and transform data.
Notebook code
You can use available Spark libraries to connect to a data source directly, load data to a data frame, and then save it in a lakehouse. This method is the most open way to load data in the lakehouse that user code is fully managing.
Note
External Delta tables created with Spark code won't be visible to a SQL analytics endpoint. Use shortcuts in Table space to make external Delta tables visible for a SQL analytics endpoint. To learn how to create a shortcut, see Create a shortcut to files or tables.
Stream real-time events with Eventstream
With Eventstream, you can get, process, and route high volumes real-time events from a wide variety of sources.
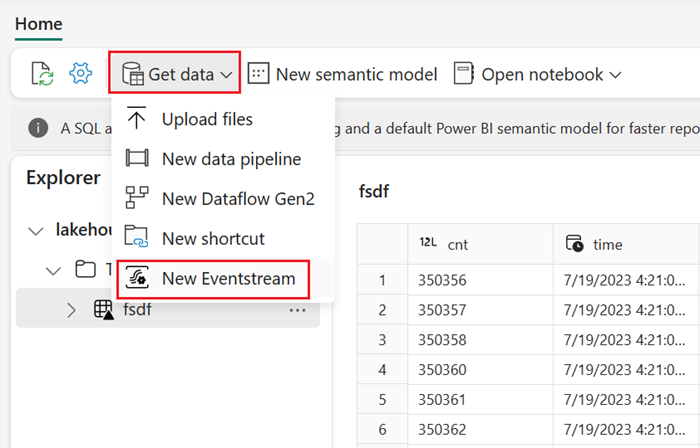
To see how to add lakehouse as a destination for Eventstream, see Get data from Eventstream in a lakehouse.
For optimal streaming performance, you can stream data from Eventstream into an Eventhouse and then enable OneLake availability.
Get data from Eventhouse
When you enable OneLake availability on data in an Eventhouse, a Delta table is created in OneLake. This Delta table can be accessed by a lakehouse using a shortcut. For more information, see OneLake shortcuts. For more information, see Eventhouse OneLake Availability.
Considerations when choosing approach to load data
| Use case | Recommendation |
|---|---|
| Small file upload from local machine | Use Local file upload |
| Small data or specific connector | Use Dataflows |
| Large data source | Use Copy tool in pipelines |
| Complex data transformations | Use Notebook code |
| Streaming data | Use Eventstream to stream data into Eventhouse; enable OneLake availability and create a shortcut from Lakehouse |
| Time-series data | Get data from Eventhouse |