Configure Azure Event Hubs and Kafka data flow endpoints
Important
This page includes instructions for managing Azure IoT Operations components using Kubernetes deployment manifests, which is in preview. This feature is provided with several limitations, and shouldn't be used for production workloads.
See the Supplemental Terms of Use for Microsoft Azure Previews for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability.
To set up bi-directional communication between Azure IoT Operations and Apache Kafka brokers, you can configure a data flow endpoint. This configuration allows you to specify the endpoint, Transport Layer Security (TLS), authentication, and other settings.
Prerequisites
- An instance of Azure IoT Operations
Azure Event Hubs
Azure Event Hubs is compatible with the Kafka protocol and can be used with data flows with some limitations.
Create an Azure Event Hubs namespace and event hub
First, create a Kafka-enabled Azure Event Hubs namespace
Next, create an event hub in the namespace. Each individual event hub corresponds to a Kafka topic. You can create multiple event hubs in the same namespace to represent multiple Kafka topics.
Assign permission to managed identity
To configure a data flow endpoint for Azure Event Hubs, we recommend using either a user-assigned or system-assigned managed identity. This approach is secure and eliminates the need for managing credentials manually.
After the Azure Event Hubs namespace and event hub is created, you need to assign a role to the Azure IoT Operations managed identity that grants permission to send or receive messages to the event hub.
If using system-assigned managed identity, in Azure portal, go to your Azure IoT Operations instance and select Overview. Copy the name of the extension listed after Azure IoT Operations Arc extension. For example, azure-iot-operations-xxxx7. Your system-assigned managed identity can be found using the same name of the Azure IoT Operations Arc extension.
Then, go to the Event Hubs namespace > Access control (IAM) > Add role assignment.
- On the Role tab, select an appropriate role like
Azure Event Hubs Data SenderorAzure Event Hubs Data Receiver. This gives the managed identity the necessary permissions to send or receive messages for all event hubs in the namespace. To learn more, see Authenticate an application with Microsoft Entra ID to access Event Hubs resources. - On the Members tab:
- If using system-assigned managed identity, for Assign access to, select User, group, or service principal option, then select + Select members and search for the name of the Azure IoT Operations Arc extension.
- If using user-assigned managed identity, for Assign access to, select Managed identity option, then select + Select members and search for your user-assigned managed identity set up for cloud connections.
Create data flow endpoint for Azure Event Hubs
Once the Azure Event Hubs namespace and event hub is configured, you can create a data flow endpoint for the Kafka-enabled Azure Event Hubs namespace.
In the operations experience, select the Data flow endpoints tab.
Under Create new data flow endpoint, select Azure Event Hubs > New.
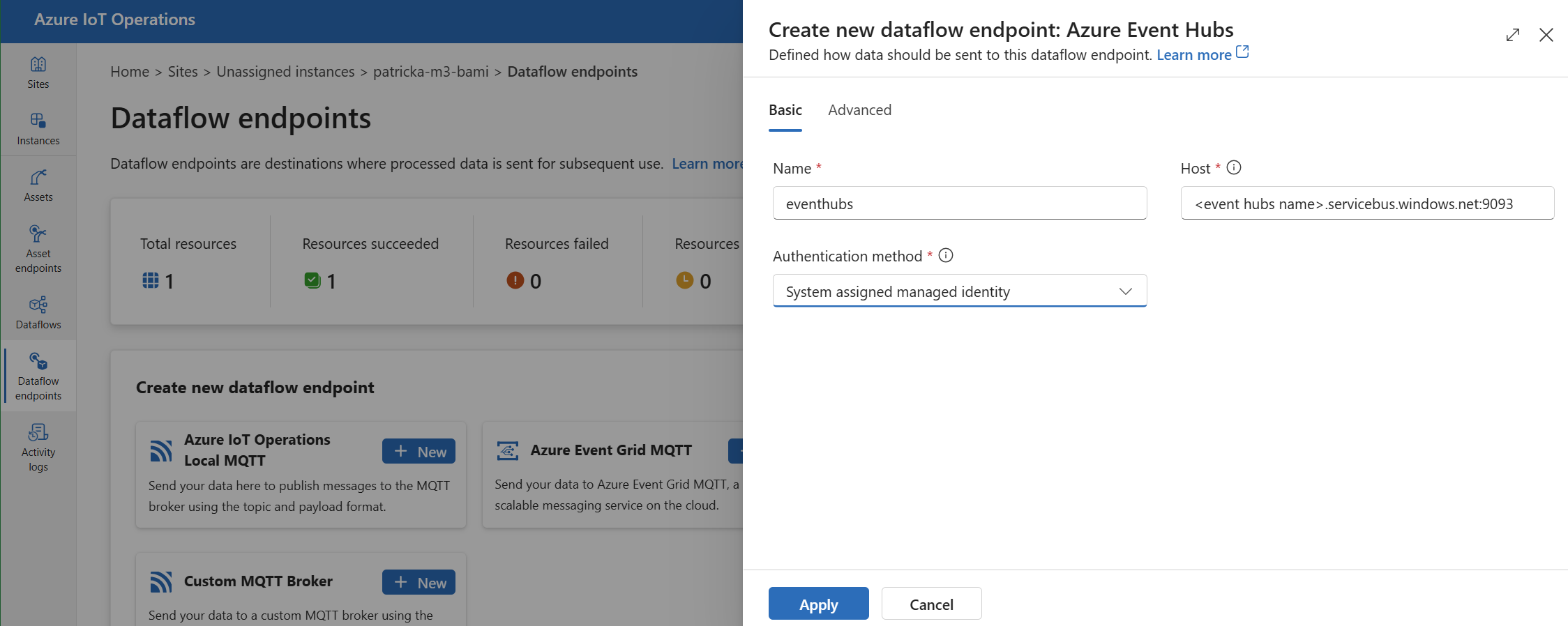
Enter the following settings for the endpoint:
Setting Description Name The name of the data flow endpoint. Host The hostname of the Event Hubs host. You can search for an existing Event Hubs host or enter the host name manually using the format <NAMESPACE>.servicebus.windows.net.Port The port of the Event Hubs host. For Event Hubs, the port is 9093.Authentication method The method used for authentication. We recommend that you choose System assigned managed identity or User assigned managed identity. Select Apply to provision the endpoint.
Note
The Kafka topic, or individual event hub, is configured later when you create the data flow. The Kafka topic is the destination for the data flow messages.
Use connection string for authentication to Event Hubs
Important
To use the operations experience web UI to manage secrets, Azure IoT Operations must first be enabled with secure settings by configuring an Azure Key Vault and enabling workload identities. To learn more, see Enable secure settings in Azure IoT Operations deployment.
In the operations experience data flow endpoint settings page, select the Basic tab then choose Authentication method > SASL.
Enter the following settings for the endpoint:
| Setting | Description |
|---|---|
| SASL type | Choose Plain. |
| Synced secret name | Enter a name of the Kubernetes secret that contains the connection string. |
| Username reference or token secret | The reference to the username or token secret used for SASL authentication. Either pick it from the Key Vault list or create a new one. The value must be $ConnectionString. |
| Password reference of token secret | The reference to the password or token secret used for SASL authentication. Either pick it from the Key Vault list or create a new one. The value must be in the format of Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
After you select Add reference, if you select Create new, enter the following settings:
| Setting | Description |
|---|---|
| Secret name | The name of the secret in Azure Key Vault. Pick a name that is easy to remember to select the secret later from the list. |
| Secret value | For the username, enter $ConnectionString. For the password, enter the connection string in the format Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
| Set activation date | If turned on, the date when the secret becomes active. |
| Set expiration date | If turned on, the date when the secret expires. |
To learn more about secrets, see Create and manage secrets in Azure IoT Operations.
Limitations
Azure Event Hubs doesn't support all the compression types that Kafka supports. Only GZIP compression is supported in Azure Event Hubs premium and dedicated tiers currently. Using other compression types might result in errors.
Custom Kafka brokers
To configure a data flow endpoint for non-Event-Hub Kafka brokers, set the host, TLS, authentication, and other settings as needed.
In the operations experience, select the Data flow endpoints tab.
Under Create new data flow endpoint, select Custom Kafka Broker > New.
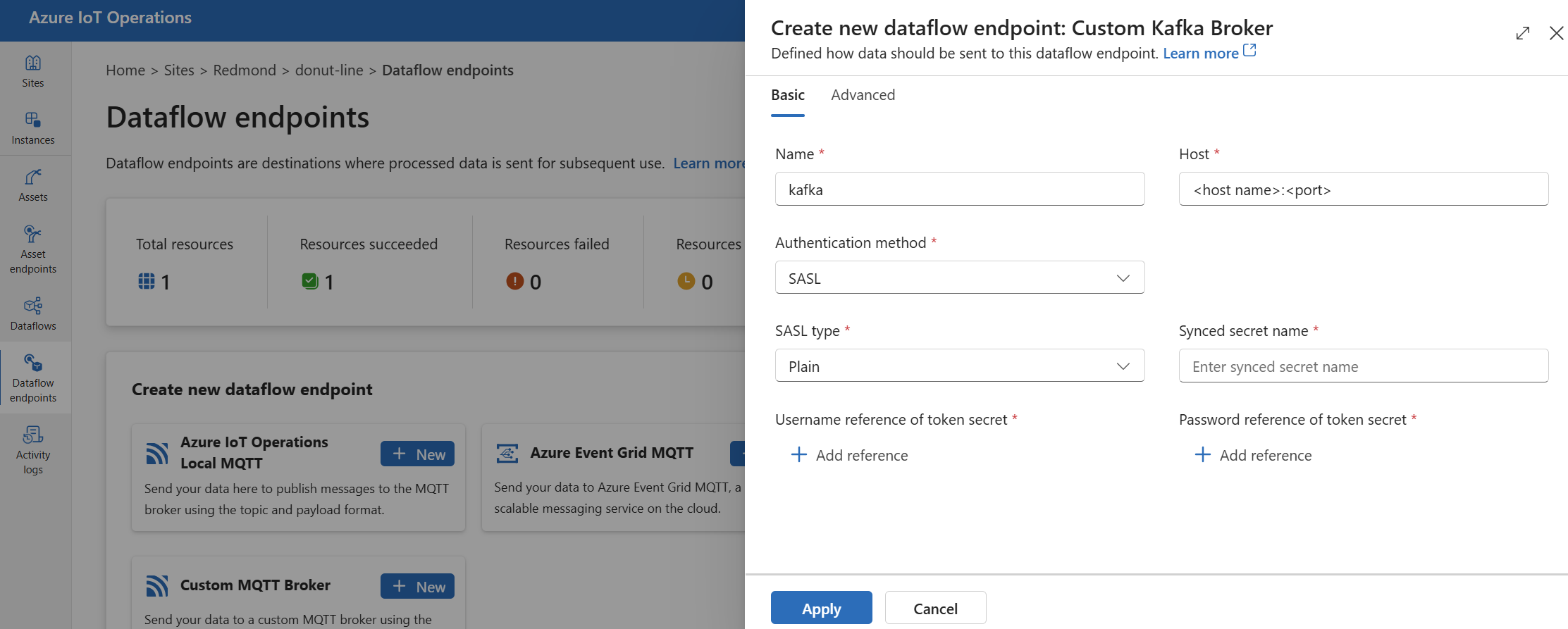
Enter the following settings for the endpoint:
Setting Description Name The name of the data flow endpoint. Host The hostname of the Kafka broker in the format <Kafka-broker-host>:xxxx. Include port number in the host setting.Authentication method The method used for authentication. Choose SASL. SASL type The type of SASL authentication. Choose Plain, ScramSha256, or ScramSha512. Required if using SASL. Synced secret name The name of the secret. Required if using SASL. Username reference of token secret The reference to the username in the SASL token secret. Required if using SASL. Select Apply to provision the endpoint.
Note
Currently, the operations experience doesn't support using a Kafka data flow endpoint as a source. You can create a data flow with a source Kafka data flow endpoint using Kubernetes or Bicep.
To customize the endpoint settings, use the following sections for more information.
Available authentication methods
The following authentication methods are available for Kafka broker data flow endpoints.
System-assigned managed identity
Before you configure the data flow endpoint, assign a role to the Azure IoT Operations managed identity that grants permission to connect to the Kafka broker:
- In Azure portal, go to your Azure IoT Operations instance and select Overview.
- Copy the name of the extension listed after Azure IoT Operations Arc extension. For example, azure-iot-operations-xxxx7.
- Go to the cloud resource you need to grant permissions. For example, go to the Event Hubs namespace > Access control (IAM) > Add role assignment.
- On the Role tab, select an appropriate role.
- On the Members tab, for Assign access to, select User, group, or service principal option, then select + Select members and search for the Azure IoT Operations managed identity. For example, azure-iot-operations-xxxx7.
Then, configure the data flow endpoint with system-assigned managed identity settings.
In the operations experience data flow endpoint settings page, select the Basic tab then choose Authentication method > System assigned managed identity.
This configuration creates a managed identity with the default audience, which is the same as the Event Hubs namespace host value in the form of https://<NAMESPACE>.servicebus.windows.net. However, if you need to override the default audience, you can set the audience field to the desired value.
Not supported in the operations experience.
User-assigned managed identity
To use user-assigned managed identity for authentication, you must first deploy Azure IoT Operations with secure settings enabled. Then you need to set up a user-assigned managed identity for cloud connections. To learn more, see Enable secure settings in Azure IoT Operations deployment.
Before you configure the data flow endpoint, assign a role to the user-assigned managed identity that grants permission to connect to the Kafka broker:
- In Azure portal, go to the cloud resource you need to grant permissions. For example, go to the Event Grid namespace > Access control (IAM) > Add role assignment.
- On the Role tab, select an appropriate role.
- On the Members tab, for Assign access to, select Managed identity option, then select + Select members and search for your user-assigned managed identity.
Then, configure the data flow endpoint with user-assigned managed identity settings.
In the operations experience data flow endpoint settings page, select the Basic tab then choose Authentication method > User assigned managed identity.
Here, the scope is the audience of the managed identity. The default value is the same as the Event Hubs namespace host value in the form of https://<NAMESPACE>.servicebus.windows.net. However, if you need to override the default audience, you can set the scope field to the desired value using Bicep or Kubernetes.
SASL
To use SASL for authentication, specify the SASL authentication method and configure SASL type and a secret reference with the name of the secret that contains the SASL token.
In the operations experience data flow endpoint settings page, select the Basic tab then choose Authentication method > SASL.
Enter the following settings for the endpoint:
| Setting | Description |
|---|---|
| SASL type | The type of SASL authentication to use. Supported types are Plain, ScramSha256, and ScramSha512. |
| Synced secret name | The name of the Kubernetes secret that contains the SASL token. |
| Username reference or token secret | The reference to the username or token secret used for SASL authentication. |
| Password reference of token secret | The reference to the password or token secret used for SASL authentication. |
The supported SASL types are:
PlainScramSha256ScramSha512
The secret must be in the same namespace as the Kafka data flow endpoint. The secret must have the SASL token as a key-value pair.
Anonymous
To use anonymous authentication, update the authentication section of the Kafka settings to use the Anonymous method.
In the operations experience data flow endpoint settings page, select the Basic tab then choose Authentication method > None.
Advanced settings
You can set advanced settings for the Kafka data flow endpoint such as TLS, trusted CA certificate, Kafka messaging settings, batching, and CloudEvents. You can set these settings in the data flow endpoint Advanced portal tab or within the data flow endpoint resource.
In the operations experience, select the Advanced tab for the data flow endpoint.
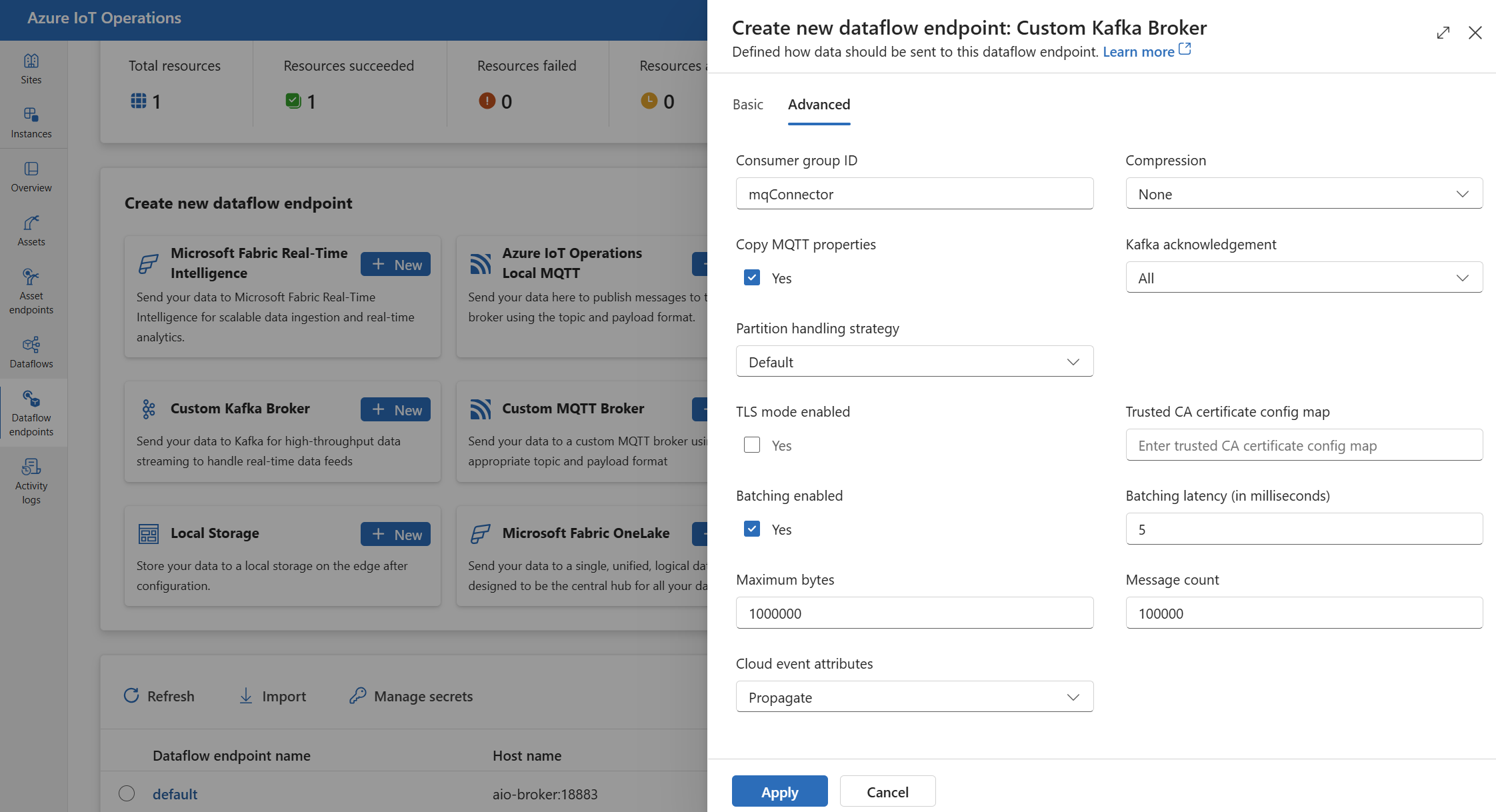
TLS settings
TLS mode
To enable or disable TLS for the Kafka endpoint, update the mode setting in the TLS settings.
In the operations experience data flow endpoint settings page, select the Advanced tab then use the checkbox next to TLS mode enabled.
The TLS mode can be set to Enabled or Disabled. If the mode is set to Enabled, the data flow uses a secure connection to the Kafka broker. If the mode is set to Disabled, the data flow uses an insecure connection to the Kafka broker.
Trusted CA certificate
Configure the trusted CA certificate for the Kafka endpoint to establish a secure connection to the Kafka broker. This setting is important if the Kafka broker uses a self-signed certificate or a certificate signed by a custom CA that isn't trusted by default.
In the operations experience data flow endpoint settings page, select the Advanced tab then use the Trusted CA certificate config map field to specify the ConfigMap containing the trusted CA certificate.
This ConfigMap should contain the CA certificate in PEM format. The ConfigMap must be in the same namespace as the Kafka data flow resource. For example:
kubectl create configmap client-ca-configmap --from-file root_ca.crt -n azure-iot-operations
Tip
When connecting to Azure Event Hubs, the CA certificate isn't required because the Event Hubs service uses a certificate signed by a public CA that is trusted by default.
Consumer group ID
The consumer group ID is used to identify the consumer group that the data flow uses to read messages from the Kafka topic. The consumer group ID must be unique within the Kafka broker.
Important
When the Kafka endpoint is used as source, the consumer group ID is required. Otherwise, the data flow can't read messages from the Kafka topic, and you get an error "Kafka type source endpoints must have a consumerGroupId defined".
In the operations experience data flow endpoint settings page, select the Advanced tab then use the Consumer group ID field to specify the consumer group ID.
This setting takes effect only if the endpoint is used as a source (that is, the data flow is a consumer).
Compression
The compression field enables compression for the messages sent to Kafka topics. Compression helps to reduce the network bandwidth and storage space required for data transfer. However, compression also adds some overhead and latency to the process. The supported compression types are listed in the following table.
| Value | Description |
|---|---|
None |
No compression or batching is applied. None is the default value if no compression is specified. |
Gzip |
GZIP compression and batching are applied. GZIP is a general-purpose compression algorithm that offers a good balance between compression ratio and speed. Only GZIP compression is supported in Azure Event Hubs premium and dedicated tiers currently. |
Snappy |
Snappy compression and batching are applied. Snappy is a fast compression algorithm that offers moderate compression ratio and speed. This compression mode isn't supported by Azure Event Hubs. |
Lz4 |
LZ4 compression and batching are applied. LZ4 is a fast compression algorithm that offers low compression ratio and high speed. This compression mode isn't supported by Azure Event Hubs. |
To configure compression:
In the operations experience data flow endpoint settings page, select the Advanced tab then use the Compression field to specify the compression type.
This setting takes effect only if the endpoint is used as a destination where the data flow is a producer.
Batching
Aside from compression, you can also configure batching for messages before sending them to Kafka topics. Batching allows you to group multiple messages together and compress them as a single unit, which can improve the compression efficiency and reduce the network overhead.
| Field | Description | Required |
|---|---|---|
mode |
Can be Enabled or Disabled. The default value is Enabled because Kafka doesn't have a notion of unbatched messaging. If set to Disabled, the batching is minimized to create a batch with a single message each time. |
No |
latencyMs |
The maximum time interval in milliseconds that messages can be buffered before being sent. If this interval is reached, then all buffered messages are sent as a batch, regardless of how many or how large they are. If not set, the default value is 5. | No |
maxMessages |
The maximum number of messages that can be buffered before being sent. If this number is reached, then all buffered messages are sent as a batch, regardless of how large or how long they're buffered. If not set, the default value is 100000. | No |
maxBytes |
The maximum size in bytes that can be buffered before being sent. If this size is reached, then all buffered messages are sent as a batch, regardless of how many or how long they're buffered. The default value is 1000000 (1 MB). | No |
For example, if you set latencyMs to 1000, maxMessages to 100, and maxBytes to 1024, messages are sent either when there are 100 messages in the buffer, or when there are 1,024 bytes in the buffer, or when 1,000 milliseconds elapse since the last send, whichever comes first.
To configure batching:
In the operations experience data flow endpoint settings page, select the Advanced tab then use the Batching enabled field to enable batching. Use the Batching latency, Maximum bytes, and Message count fields to specify the batching settings.
This setting takes effect only if the endpoint is used as a destination where the data flow is a producer.
Partition handling strategy
The partition handling strategy controls how messages are assigned to Kafka partitions when sending them to Kafka topics. Kafka partitions are logical segments of a Kafka topic that enable parallel processing and fault tolerance. Each message in a Kafka topic has a partition and an offset, which are used to identify and order the messages.
This setting takes effect only if the endpoint is used as a destination where the data flow is a producer.
By default, a data flow assigns messages to random partitions, using a round-robin algorithm. However, you can use different strategies to assign messages to partitions based on some criteria, such as the MQTT topic name or an MQTT message property. This can help you to achieve better load balancing, data locality, or message ordering.
| Value | Description |
|---|---|
Default |
Assigns messages to random partitions, using a round-robin algorithm. This is the default value if no strategy is specified. |
Static |
Assigns messages to a fixed partition number that is derived from the instance ID of the data flow. This means that each data flow instance sends messages to a different partition. This can help to achieve better load balancing and data locality. |
Topic |
Uses the MQTT topic name from the data flow source as the key for partitioning. This means that messages with the same MQTT topic name are sent to the same partition. This can help to achieve better message ordering and data locality. |
Property |
Uses an MQTT message property from the data flow source as the key for partitioning. Specify the name of the property in the partitionKeyProperty field. This means that messages with the same property value are sent to the same partition. This can help to achieve better message ordering and data locality based on a custom criterion. |
For example, if you set the partition handling strategy to Property and the partition key property to device-id, messages with the same device-id property are sent to the same partition.
To configure the partition handling strategy:
In the operations experience data flow endpoint settings page, select the Advanced tab then use the Partition handling strategy field to specify the partition handling strategy. Use the Partition key property field to specify the property used for partitioning if the strategy is set to Property.
Kafka acknowledgments
Kafka acknowledgments (acks) are used to control the durability and consistency of messages sent to Kafka topics. When a producer sends a message to a Kafka topic, it can request different levels of acknowledgments from the Kafka broker to ensure that the message is successfully written to the topic and replicated across the Kafka cluster.
This setting takes effect only if the endpoint is used as a destination (that is, the data flow is a producer).
| Value | Description |
|---|---|
None |
The data flow doesn't wait for any acknowledgments from the Kafka broker. This setting is the fastest but least durable option. |
All |
The data flow waits for the message to be written to the leader partition and all follower partitions. This setting is the slowest but most durable option. This setting is also the default option |
One |
The data flow waits for the message to be written to the leader partition and at least one follower partition. |
Zero |
The data flow waits for the message to be written to the leader partition but doesn't wait for any acknowledgments from the followers. This is faster than One but less durable. |
For example, if you set the Kafka acknowledgment to All, the data flow waits for the message to be written to the leader partition and all follower partitions before sending the next message.
To configure the Kafka acknowledgments:
In the operations experience data flow endpoint settings page, select the Advanced tab then use the Kafka acknowledgment field to specify the Kafka acknowledgment level.
This setting only takes effect if the endpoint is used as a destination where the data flow is a producer.
Copy MQTT properties
By default, the copy MQTT properties setting is enabled. These user properties include values such as subject that stores the name of the asset sending the message.
In the operations experience data flow endpoint settings page, select the Advanced tab then use checkbox next to Copy MQTT properties field to enable or disable copying MQTT properties.
The following sections describe how MQTT properties are translated to Kafka user headers and vice versa when the setting is enabled.
Kafka endpoint is a destination
When a Kafka endpoint is a data flow destination, all MQTT v5 specification defined properties are translated Kafka user headers. For example, an MQTT v5 message with "Content Type" being forwarded to Kafka translates into the Kafka user header "Content Type":{specifiedValue}. Similar rules apply to other built-in MQTT properties, defined in the following table.
| MQTT Property | Translated Behavior |
|---|---|
| Payload Format Indicator | Key: "Payload Format Indicator" Value: "0" (Payload is bytes) or "1" (Payload is UTF-8) |
| Response Topic | Key: "Response Topic" Value: Copy of Response Topic from original message. |
| Message Expiry Interval | Key: "Message Expiry Interval" Value: UTF-8 representation of number of seconds before message expires. See Message Expiry Interval property for more details. |
| Correlation Data: | Key: "Correlation Data" Value: Copy of Correlation Data from original message. Unlike many MQTT v5 properties that are UTF-8 encoded, correlation data can be arbitrary data. |
| Content Type: | Key: "Content Type" Value: Copy of Content Type from original message. |
MQTT v5 user property key value pairs are directly translated to Kafka user headers. If a user header in a message has the same name as a built-in MQTT property (for example, a user header named "Correlation Data") then whether forwarding the MQTT v5 specification property value or the user property is undefined.
Data flows never receive these properties from an MQTT Broker. Thus, a data flow never forwards them:
- Topic Alias
- Subscription Identifiers
The Message Expiry Interval property
The Message Expiry Interval specifies how long a message can remain in an MQTT broker before being discarded.
When a data flow receives an MQTT message with the Message Expiry Interval specified, it:
- Records the time the message was received.
- Before the message is emitted to the destination, time is subtracted from the message has been queued from the original expiry interval time.
- If the message hasn't expired (the operation above is > 0), then the message is emitted to the destination and contains the updated Message Expiry Time.
- If the message has expired (the operation above is <= 0), then the message isn't emitted by the Target.
Examples:
- A data flow receives an MQTT message with Message Expiry Interval = 3600 seconds. The corresponding destination is temporarily disconnected but is able to reconnect. 1,000 seconds pass before this MQTT Message is sent to the Target. In this case, the destination's message has its Message Expiry Interval set as 2600 (3600 - 1000) seconds.
- The data flow receives an MQTT message with Message Expiry Interval = 3600 seconds. The corresponding destination is temporarily disconnected but is able to reconnect. In this case, however, it takes 4,000 seconds to reconnect. The message expired and data flow doesn't forward this message to the destination.
Kafka endpoint is a data flow source
Note
There's a known issue when using Event Hubs endpoint as a data flow source where Kafka header gets corrupted as its translated to MQTT. This only happens if using Event Hubs through the Event Hubs client which uses AMQP under the covers. For for instance "foo"="bar", the "foo" is translated, but the value becomes"\xa1\x03bar".
When a Kafka endpoint is a data flow source, Kafka user headers are translated to MQTT v5 properties. The following table describes how Kafka user headers are translated to MQTT v5 properties.
| Kafka Header | Translated Behavior |
|---|---|
| Key | Key: "Key" Value: Copy of the Key from original message. |
| Timestamp | Key: "Timestamp" Value: UTF-8 encoding of Kafka Timestamp, which is number of milliseconds since Unix epoch. |
Kafka user header key/value pairs - provided they're all encoded in UTF-8 - are directly translated into MQTT user key/value properties.
UTF-8 / Binary Mismatches
MQTT v5 can only support UTF-8 based properties. If data flow receives a Kafka message that contains one or more non-UTF-8 headers, data flow will:
- Remove the offending property or properties.
- Forward the rest of the message on, following the previous rules.
Applications that require binary transfer in Kafka Source headers => MQTT Target properties must first UTF-8 encode them - for example, via Base64.
>=64KB property mismatches
MQTT v5 properties must be smaller than 64 KB. If data flow receives a Kafka message that contains one or more headers that is >= 64KB, data flow will:
- Remove the offending property or properties.
- Forward the rest of the message on, following the previous rules.
Property translation when using Event Hubs and producers that use AMQP
If you have a client forwarding messages a Kafka data flow source endpoint doing any of the following actions:
- Sending messages to Event Hubs using client libraries such as Azure.Messaging.EventHubs
- Using AMQP directly
There are property translation nuances to be aware of.
You should do one of the following:
- Avoid sending properties
- If you must send properties, send values encoded as UTF-8.
When Event Hubs translates properties from AMQP to Kafka, it includes the underlying AMQP encoded types in its message. For more information on the behavior, see Exchanging Events Between Consumers and Producers Using Different Protocols.
In the following code example when the data flow endpoint receives the value "foo":"bar", it receives the property as <0xA1 0x03 "bar">.
using global::Azure.Messaging.EventHubs;
using global::Azure.Messaging.EventHubs.Producer;
var propertyEventBody = new BinaryData("payload");
var propertyEventData = new EventData(propertyEventBody)
{
Properties =
{
{"foo", "bar"},
}
};
var propertyEventAdded = eventBatch.TryAdd(propertyEventData);
await producerClient.SendAsync(eventBatch);
The data flow endpoint can't forward the payload property <0xA1 0x03 "bar"> to an MQTT message because the data isn't UTF-8. However if you specify a UTF-8 string, the data flow endpoint translates the string before sending onto MQTT. If you use a UTF-8 string, the MQTT message would have "foo":"bar" as user properties.
Only UTF-8 headers are translated. For example, given the following scenario where the property is set as a float:
Properties =
{
{"float-value", 11.9 },
}
The data flow endpoint discards packets that contain the "float-value" field.
Not all event data properties including propertyEventData.correlationId are forwarded. For more information, see Event User Properties,
CloudEvents
CloudEvents are a way to describe event data in a common way. The CloudEvents settings are used to send or receive messages in the CloudEvents format. You can use CloudEvents for event-driven architectures where different services need to communicate with each other in the same or different cloud providers.
The CloudEventAttributes options are Propagate orCreateOrRemap.
In the operations experience data flow endpoint settings page, select the Advanced tab then use the Cloud event attributes field to specify the CloudEvents setting.
The following sections describe how CloudEvent properties are propagated or created and remapped.
Propagate setting
CloudEvent properties are passed through for messages that contain the required properties. If the message doesn't contain the required properties, the message is passed through as is. If the required properties are present, a ce_ prefix is added to the CloudEvent property name.
| Name | Required | Sample value | Output name | Output value |
|---|---|---|---|---|
specversion |
Yes | 1.0 |
ce-specversion |
Passed through as is |
type |
Yes | ms.aio.telemetry |
ce-type |
Passed through as is |
source |
Yes | aio://mycluster/myoven |
ce-source |
Passed through as is |
id |
Yes | A234-1234-1234 |
ce-id |
Passed through as is |
subject |
No | aio/myoven/telemetry/temperature |
ce-subject |
Passed through as is |
time |
No | 2018-04-05T17:31:00Z |
ce-time |
Passed through as is. It's not restamped. |
datacontenttype |
No | application/json |
ce-datacontenttype |
Changed to the output data content type after the optional transform stage. |
dataschema |
No | sr://fabrikam-schemas/123123123234234234234234#1.0.0 |
ce-dataschema |
If an output data transformation schema is given in the transformation configuration, dataschema is changed to the output schema. |
CreateOrRemap setting
CloudEvent properties are passed through for messages that contain the required properties. If the message doesn't contain the required properties, the properties are generated.
| Name | Required | Output name | Generated value if missing |
|---|---|---|---|
specversion |
Yes | ce-specversion |
1.0 |
type |
Yes | ce-type |
ms.aio-dataflow.telemetry |
source |
Yes | ce-source |
aio://<target-name> |
id |
Yes | ce-id |
Generated UUID in the target client |
subject |
No | ce-subject |
The output topic where the message is sent |
time |
No | ce-time |
Generated as RFC 3339 in the target client |
datacontenttype |
No | ce-datacontenttype |
Changed to the output data content type after the optional transform stage |
dataschema |
No | ce-dataschema |
Schema defined in the schema registry |
Next steps
To learn more about data flows, see Create a data flow.