Tutorial: Migrate WebSphere Application Server to Azure Virtual Machines with high availability and disaster recovery
This tutorial shows you a simple and effective way to implement high availability and disaster recovery (HA/DR) for Java using WebSphere Application Server on Azure Virtual Machines (VMs). The solution illustrates how to achieve a low Recovery Time Objective (RTO) and Recovery Point Objective (RPO) using a simple database-driven Jakarta EE application running on WebSphere Application Server. HA/DR is a complex topic, with many possible solutions. The best solution depends on your unique requirements. For other ways to implement HA/DR, see the resources at the end of this article.
In this tutorial, you learn how to:
- Use Azure optimized best practices to achieve high availability and disaster recovery.
- Set up a Microsoft Azure SQL Database failover group in paired regions.
- Set up the primary WebSphere cluster on Azure VMs.
- Set up disaster recovery for the cluster using Azure Site Recovery.
- Set up an Azure Traffic Manager.
- Test failover from primary to secondary.
The following diagram illustrates the architecture you build:

Azure Traffic Manager checks the health of your regions and routes the traffic accordingly to the application tier. The primary region has a full deployment of the WebSphere cluster. After the primary region is protected by Azure Site Recovery, you can restore the secondary region during the failover. As a result, the primary region is actively servicing network requests from the users, while the secondary region is passive and activated to receive traffic only when the primary region experiences a service disruption.
Azure Traffic Manager detects the health of the app deployed in the IBM HTTP Server to implement the conditional routing. The geo-failover RTO of the application tier depends on the time for shutting down the primary cluster, restoring the secondary cluster, starting VMs, and running the secondary WebSphere cluster. The RPO depends on the replication policy of Azure Site Recovery and Azure SQL Database. This dependency is because the cluster data is stored and replicated in the local storage of the VMs and the application data is persisted and replicated in the Azure SQL Database failover group.
The preceding diagram shows Primary region and Secondary region as the two regions comprising the HA/DR architecture. These regions need to be Azure paired regions. For more information on paired regions, see Azure cross-region replication. The article uses East US and West US as the two regions, but they can be any paired regions that make sense for your scenario. For the list of region pairings, see the Azure paired regions section of Azure cross-region replication.
The database tier consists of an Azure SQL Database failover group with a primary server and a secondary server. The read/write listener endpoint always points to the primary server and is connected to the WebSphere cluster in each region. A geo-failover switches all secondary databases in the group to the primary role. For geo-failover RPO and RTO of Azure SQL Database, see Overview of business continuity with Azure SQL Database.
This tutorial was written with Azure Site Recovery and the Azure SQL Database service because the tutorial relies on the HA features of these services. Other database choices are possible, but you must consider the HA features of whatever database you choose.
Prerequisites
- An Azure subscription. If you don't have an Azure subscription, create a free account before you begin.
- Make sure you have the
Contributorrole in the subscription. You can verify the assignment by following the steps in List Azure role assignments using the Azure portal. - Prepare a local machine with Windows, Linux, or macOS installed.
- Install and set up Git.
- Install a Java SE implementation, version 17 or later - for example, the Microsoft build of OpenJDK.
- Install Maven, version 3.9.3 or later.
Set up an Azure SQL Database failover group in paired regions
In this section, you create an Azure SQL Database failover group in paired regions for use with your WebSphere clusters and app. In a later section, you configure WebSphere to store its session data to this database. This practice references Creating a table for session persistence.
First, create the primary Azure SQL Database by following the Azure portal steps in Quickstart: Create a single database - Azure SQL Database. Follow the steps up to, but not including, the "Clean up resources" section. Use the following directions as you go through the article, then return to this article after you create and configure the Azure SQL Database:
When you reach the section Create a single database, use the following steps:
- In step 4 for creating new resource group, save aside the Resource group name value - for example,
myResourceGroup. - In step 5 for database name, save aside the Database name value - for example,
mySampleDatabase. - In step 6 for creating the server, use the following steps:
- Fill in a unique server name - for example,
sqlserverprimary-mjg022624. - For Location, select (US) East US.
- For Authentication method, select Use SQL authentication.
- Save aside the Server admin login value - for example,
azureuser. - Save aside the Password value.
- Fill in a unique server name - for example,
- In step 8, for Workload environment, select Development. Look at the description and consider other options for your workload.
- In step 11, for Backup storage redundancy, select Locally-redundant backup storage. Consider other options for your backups. For more information, see the Backup storage redundancy section of Automated backups in Azure SQL Database.
- In step 14, in the Firewall rules configuration, for Allow Azure services and resources to access this server, select Yes.
- In step 4 for creating new resource group, save aside the Resource group name value - for example,
When you reach the section Query the database, use the following steps:
In step 3, enter your SQL authentication server admin sign-in information to sign in.
Note
If sign-in fails with an error message similar to Client with IP address 'xx.xx.xx.xx' is not allowed to access the server, select Allowlist IP xx.xx.xx.xx on server <your-sqlserver-name> at the end of the error message. Wait until the server firewall rules complete updating, then select OK again.
After you run the sample query in step 5, clear the editor and enter the following query, then select Run again:
CREATE TABLE sessions ( ID VARCHAR(128) NOT NULL, PROPID VARCHAR(128) NOT NULL, APPNAME VARCHAR(128) NOT NULL, LISTENERCNT SMALLINT, LASTACCESS BIGINT, CREATIONTIME BIGINT, MAXINACTIVETIME INT, USERNAME VARCHAR(256), SMALL VARBINARY(MAX), MEDIUM VARCHAR(MAX), LARGE VARBINARY(MAX) );After a successful run, you should see the message Query succeeded: Affected rows: 0.
The database table
sessionsis used for storing session data for your WebSphere app. The WebSphere cluster data including transaction logs is persisted to local storage of VMs where the cluster is deployed.
Then, create an Azure SQL Database failover group by following the Azure portal steps in Configure a failover group for Azure SQL Database. You just need the following sections: Create failover group and Test planned failover. Use the following steps as you go through the article, then return to this article after you create and configure the Azure SQL Database failover group:
In the section Create failover group, use the following steps:
- In step 5 for creating the failover group, enter and save aside the unique failover group name - for example,
failovergroup-mjg022624. - In step 5 for configuring the server, select the option to create a new secondary server and then use the following steps:
- Enter a unique server name - for example,
sqlserversecondary-mjg022624. - Enter the same server admin and password as your primary server.
- For Location, select (US) West US.
- Make sure Allow Azure services to access server is selected.
- Enter a unique server name - for example,
- In step 5 for configuring the Databases within the group, select the database you created in the primary server - for example,
mySampleDatabase.
- In step 5 for creating the failover group, enter and save aside the unique failover group name - for example,
After you complete all the steps in the section Test planned failover, keep the failover group page open and use it for the failover test of the WebSphere clusters later.
Note
This article guides you to create an Azure SQL Database single database with SQL authentication. A more secure practice is to use Microsoft Entra authentication for Azure SQL for authenticating the database server connection. SQL authentication is required for the WebSphere cluster to connect to the database for session persistence later. For more information, see Configuring for database session persistence.
Set up the primary WebSphere cluster on Azure VMs
In this section, you create the primary WebSphere clusters on Azure VMs using the IBM WebSphere Application Server Cluster on Azure VMs offer. The secondary cluster is restored from the primary cluster during the failover using Azure Site Recovery later.
Deploy the primary WebSphere cluster
First, open the IBM WebSphere Application Server Cluster on Azure VMs offer in your browser and select Create. You should see the Basics pane of the offer.
Use the following steps to fill out the Basics pane:
- Ensure that the value shown for Subscription is the same one that has the roles listed in the prerequisites section.
- In the Resource group field, select Create new and fill in a unique value for the resource group - for example,
was-cluster-eastus-mjg022624. - Under Instance details, for Region, select East US.
- For Deploy with existing WebSphere entitlement or with evaluation license?, select Evaluation for this tutorial. You can also select Entitled and provide your IBMid credential.
- Select I have read and accept the IBM License Agreement..
- Leave the defaults for other fields.
- Select Next to go to the Cluster configuration pane.

Use the following steps to fill out the Cluster configuration pane:
- For Password for VM administrator, provide a password. For better security, consider using SSH Public Key as the VM authentication type.
- For Password for WebSphere administrator, provide a password. Save aside the username and password for WebSphere administrator.
- Leave the defaults for other fields.
- Select Next to go to the Load balancer pane.

Use the following steps to fill out the Load balancer pane:
- For Password for VM administrator, provide a password. For better security, consider using SSH Public Key as the VM authentication.
- For Password for IBM HTTP Server administrator, provide a password.
- Leave the defaults for other fields.
- Select Next to go to the Networking pane.

You should see all fields prepopulated with the defaults in the Networking pane. Select Next to go to the Database pane.

The following steps show you how to fill out the Database pane:
- For Connect to database?, select Yes.
- For Choose database type, select Microsoft SQL Server .
- For JNDI Name, enter jdbc/WebSphereCafeDB.
- For Data source connection string (jdbc:sqlserver://<host>:<port>;database=<database>), replace the placeholders with the values you saved aside in the preceding section for the failover group for the Azure SQL Database - for example,
jdbc:sqlserver://failovergroup-mjg022624.database.windows.net:1433;database=mySampleDatabase. - For Database username, enter the server admin sign-in name and the failover group name you saved aside in the preceding section - for example,
azureuser@failovergroup-mjg022624.Note
Be extra careful to use the correct database server hostname and database username for the failover group, instead of the server hostname and username from the primary or backup database. By using the values from the failover group, you are, in effect, telling WebSphere to talk to the failover group. However, ss far as WebSphere is concerned, it's just a normal database connection.
- Enter the server admin sign-in password that you saved aside previously for Database Password. Enter the same value for Confirm password.
- Leave the defaults for the other fields.
- Select Review + create.
- Wait until Running final validation... successfully completes, then select Create.

Note
This article guides you to connect to an Azure SQL Database with SQL authentication. A more secure practice is to use Microsoft Entra authentication for Azure SQL for authenticating the database server connection. SQL authentication is required for the WebSphere cluster to connect to the database for session persistence later. For more information, see Configuring for database session persistence.
After a while, you should see the Deployment page where Deployment is in progress is displayed.
Note
If you see any problems during Running final validation..., fix them and try again.
Depending on network conditions and other activity in your selected region, the deployment can take up to 25 minutes to complete. After that, you should see the text Your deployment is complete displayed on the deployment page.
Verify the deployment of the cluster
You deployed an IBM HTTP Server (IHS) and a WebSphere Deployment Manager (Dmgr) in the cluster. The IHS acts as load balancer for all application servers in the cluster. The Dmgr provides a web console for cluster configuration.
Use the following steps to verify whether the IHS and Dmgr console work before moving to next step:
Return to the Deployment page, then select Outputs.
Copy the value of the property ihsConsole. Open that URL in a new browser tab. Note that we don't use
httpsfor the IHS in this example. You should see a welcome page of the IHS without any error message. If you don't, you must troubleshoot and resolve the issue before you continue. Keep the console open and use it for verifying the app deployment of the cluster later.
Copy and save aside the value of the property adminSecuredConsole. Open it in a new browser tab. Accept the browser warning for the self-signed TLS certificate. Don't go to production using a self-signed TLS certificate.
You should see the sign-in page of the WebSphere Integrated Solutions Console. Sign in to the console with the user name and password for WebSphere administrator you saved aside previously. If you aren't able to sign in, you must troubleshoot and resolve the issue before you continue. Keep the console open and use it for further configuration of the WebSphere cluster later.

Use the following steps to get the name of the public IP address of the IHS. You use it when you set up the Azure Traffic Manager later.
- Open the resource group where your cluster is deployed - for example, select Overview to switch back to the Overview pane of the deployment page, then select Go to resource group.
- In the table of resources, find the Type column. Select it to sort by type of resource.
- Find the Public IP address resource prefixed with
ihs, then copy and save aside its name.
Configure the cluster
First, use the following steps to enable the option Synchronize changes with Nodes so that any configuration can be automatically synchronized to all application servers:
- Switch back to the WebSphere Integrated Solutions Console and sign in again if you're signed out.
- In the navigation pane, select System administration > Console Preferences.
- In the Console Preferences pane, select Synchronize changes with Nodes, and then select Apply. You should see the message Your preferences have been changed.
Then, use the following steps to configure database distributed sessions for all application servers:
- In the navigation pane, select Servers > Server Types > WebSphere application servers.
- In the Application servers pane, you should see 3 application servers listed. For each application server, use the following instructions to configure the database distributed sessions:
- In the table under the text You can administer the following resources, select the hyperlink for the application server, which starts with
MyCluster. - In the Container Settings section, select Session management.
- In the Additional Properties section, select Distributed environment settings.
- For Distributed sessions, select Database (Supported for Web container only.).
- Select Database and use the following steps:
- For Datasource JNDI name, enter jdbc/WebSphereCafeDB.
- For User ID, enter the server admin sign-in name and the failover group name that you saved aside in the preceding section - for example,
azureuser@failovergroup-mjg022624. - Fill in the Azure SQL server admin sign-in password that you saved aside previously for Password.
- For Table space name, enter sessions.
- Select Use multi row schema.
- Select OK. You're directed back to the Distributed environment settings pane.
- Under the Additional Properties section, select Custom tuning parameters.
- For Tuning level, select Low (optimize for failover).
- Select OK.
- Under Messages, select Save. Wait until completion.
- Select Application servers from the top breadcrumb bar. You're directed back to the Application servers pane.
- In the table under the text You can administer the following resources, select the hyperlink for the application server, which starts with
- In the navigation pane, select Servers > Clusters > WebSphere application server clusters.
- In the WebSphere application server clusters pane, you should see the cluster
MyClusterlisted. Select the checkbox next to MyCluster. - Select Ripplestart.
- Wait until the cluster is restarted. You can select the Status icon and if the new window doesn't show Started, then switch back to the console and refresh the web page after a while. Repeat the operation until you see Started. You might see Partial Start before reaching the state Started
Keep the console open and use it for app deployment later.
Deploy a sample app
This section shows you how to deploy and run a sample CRUD Java/Jakarta EE application on a WebSphere cluster for disaster recovery failover test later.
You configured application servers to use the datasource jdbc/WebSphereCafeDB to store session data previously, which enables failover and load balancing across a cluster of WebSphere application servers. The sample app also configures a persistence schema to persist application data coffee in the same datasource jdbc/WebSphereCafeDB.
First, use the following commands to download, build, and package the sample:
git clone https://github.com/Azure-Samples/websphere-cafe
cd websphere-cafe
git checkout 20240326
mvn clean package
If you see a message about being in a Detached HEAD state, this message is safe to ignore.
The package should be successfully generated and located at <parent-path-to-your-local-clone>/websphere-cafe/websphere-cafe-application/target/websphere-cafe.ear. If you don't see the package, you must troubleshoot and resolve the issue before you continue.
Then, use the following steps to deploy the sample app to the cluster:
- Switch back to the WebSphere Integrated Solutions Console and sign in again if you're signed out.
- In the navigation pane, select Applications > Application Types > WebSphere enterprise applications.
- In the Enterprise Applications pane, select Install > Choose File. Then, find the package located at <parent-path-to-your-local-clone>/websphere-cafe/websphere-cafe-application/target/websphere-cafe.ear and select Open. Select Next > Next > Next.
- In the Map modules to servers pane, press Ctrl and select all the items listed under Clusters and servers. Select the checkbox next to websphere-cafe.war. Select Apply. Select Next until you see the Finish button.
- Select Finish > Save, then wait until completion. Select OK.
- Select the installed application
websphere-cafe, and then select Start. Wait until you see messages indicating application successfully started. If you aren't able to see the successful message, you must troubleshoot and resolve the issue before you continue.
Now, use the following steps to verify that the app is running as expected:
Switch back to the IHS console. Append the context root
/websphere-cafe/of the deployed app to the address bar - for example,http://ihs70685e.eastus.cloudapp.azure.com/websphere-cafe/, and then press Enter. You should see the welcome page of the sample app.Create a new coffee with a name and price - for example, Coffee 1 with price $10 - which is persisted into both the application data table and the session table of the database. The UI that you see should be similar to the following screenshot:
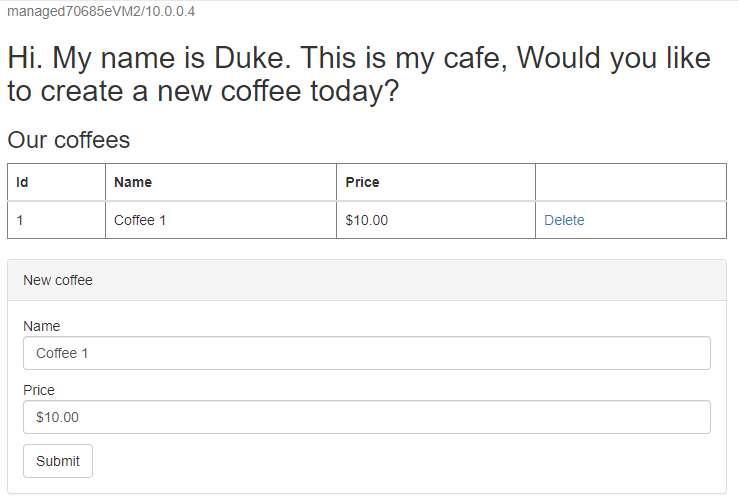

If your UI doesn't look similar, troubleshoot and resolve the issue you continue.
Set up disaster recovery for the cluster using Azure Site Recovery
In this section, you set up disaster recovery for Azure VMs in the primary cluster using Azure Site Recovery, by following the steps in Tutorial: Set up disaster recovery for Azure VMs. You just need the following sections: Create a Recovery Services vault and Enable replication. Pay attention to the following steps as you go through the article, then return to this article after the primary cluster is protected:
In the section Create a Recovery Services vault, use the following steps:
In step 5 for Resource group, create a new resource group with a unique name in your subscription - for example,
was-cluster-westus-mjg022624.In step 6 for Vault name, provide a vault name - for example,
recovery-service-vault-westus-mjg022624.In step 7 for Region, select West US.
Before you select Review + create in step 8, select Next: Redundancy. In the Redundancy pane, select Geo-redundant for Backup Storage Redundancy and Enable for Cross Region Restore.
Note
Make sure you select Geo-redundant for Backup Storage Redundancy and Enable for Cross Region Restore in the Redundancy pane. Otherwise the storage of the primary cluster can't be replicated to the secondary region.
Enable Site Recovery by following the steps in the section Enable Site Recovery.
When you reach the section Enable replication, use the following steps:
- In the section Select source settings, use the following steps:
For Region, select East US.
For Resource group, select the resource where the primary cluster is deployed - for example,
was-cluster-eastus-mjg022624.Note
If the desired resource group is not listed, you can select West US for the region first, and then switch back to East US.
Leave the defaults for other fields. Select Next.
- In the section Select the VMs, for Virtual machines, select all five VMs listed, and then select Next.
- In the section Review replication settings, use the following steps:
- For Target location, select West US.
- For Target resource group, select the resource group where the service recovery vault is deployed - for example,
was-cluster-westus-mjg022624. - Note down the new failover virtual network and failover subnet, which are mapped from ones in the primary region.
- Leave the defaults for other fields.
- Select Next.
- In the section Manage, use the following steps:
- For Replication policy, use the default policy 24-hour-retention-policy. You can also create a new policy for your business.
- Leave the defaults for other fields.
- Select Next.
- In the section Review, use the following steps:
After selecting Enable replication, notice the message Creating Azure resources. Don't close this blade. displayed at the bottom of the page. Do nothing and wait until the pane is closed automatically. You're redirected to the Site Recovery page.
Under Protected items, select Replicated items. Initially, there are no items listed because the replication is still in progress. The replication takes about one hour to complete. Refresh the page periodically until you see that all the VMs are in the Protected state, as shown in the following example screenshot:
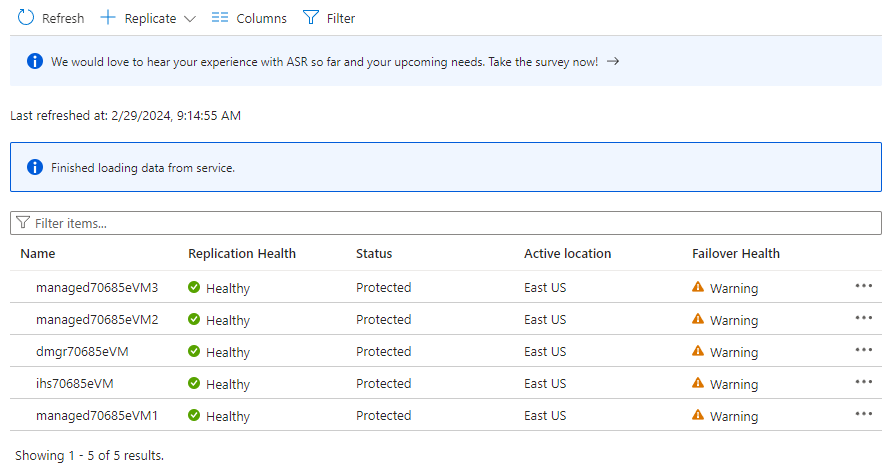
- In the section Select source settings, use the following steps:

Next, create a recovery plan to include all replicated items so that they can fail over together. Use the instructions in Create a recovery plan, with the following customizations:
- In step 2, enter a name for the plan - for example,
recovery-plan-mjg022624. - In step 3, for Source, select East US and for Target, select West US.
- In step 4 for Select items, select all five protected VMs for this tutorial.
Next, you create a recovery plan. Keep the page open so you can use it for failover testing later.
Further network configuration for the secondary region
You also need further network configuration to enable and protect external access to the secondary region in a failover event. Use the following steps for this configuration:
Create a public IP address for Dmgr in the secondary region by following the instructions in Quickstart: Create a public IP address using the Azure portal, with the following customizations:
- For Resource group, select the resource group where the service recovery vault is deployed - for example,
was-cluster-westus-mjg022624. - For Region, select (US) West US.
- For Name, enter a value - for example,
dmgr-public-ip-westus-mjg022624. - For DNS name label, enter a unique value - for example,
dmgrmjg022624.
- For Resource group, select the resource group where the service recovery vault is deployed - for example,
Create another public IP address for IHS in the secondary region by following the same guide, with the following customizations:
- For Resource group, select the resource group where the service recovery vault is deployed - for example,
was-cluster-westus-mjg022624. - For Region, select (US) West US.
- For Name, enter a value - for example,
ihs-public-ip-westus-mjg022624. Write it down. - For DNS name label, enter a unique value - for example,
ihsmjg022624.
- For Resource group, select the resource group where the service recovery vault is deployed - for example,
Create a network security group in the secondary region by following the instructions in the Create a network security group section of Create, change, or delete a network security group, with the following customizations:
- For Resource group, select the resource group where the service recovery vault is deployed - for example,
was-cluster-westus-mjg022624. - For Name, enter a value - for example,
nsg-westus-mjg022624. - For Region, select West US.
- For Resource group, select the resource group where the service recovery vault is deployed - for example,
Create an inbound security rule for the network security group by following the instructions in the Create a security rule section of the same article, with the following customizations:
- In step 2, select the network security group you created - for example,
nsg-westus-mjg022624. - In step 3, select Inbound security rules.
- In step 4, customize the following settings:
- For Destination port ranges, enter 9060,9080,9043,9443,80.
- For Protocol, select TCP.
- For Name, enter ALLOW_HTTP_ACCESS.
- In step 2, select the network security group you created - for example,
Associate the network security group with a subnet by following the instructions in the Associate or dissociate a network security group to or from a subnet section of the same article, with the following customizations:
- In step 2, select the network security group you created - for example,
nsg-westus-mjg022624. - Select Associate to associate the network security group to the failover subnet you noted down previously.
- In step 2, select the network security group you created - for example,
Set up an Azure Traffic Manager
In this section, you create an Azure Traffic Manager for distributing traffic to your public facing applications across the global Azure regions. The primary endpoint points to the public IP address of the IHS in the primary region. The secondary endpoint points to the public IP address of the IHS in the secondary region.
Create an Azure Traffic Manager profile by following the instructions in Quickstart: Create a Traffic Manager profile using the Azure portal. You just need the following sections: Create a Traffic Manager profile and Add Traffic Manager endpoints. You must skip the sections where you're directed to create App Service resources. Use the following steps as you go through these sections, then return to this article after you create and configure the Azure Traffic Manager.
In the section Create a Traffic Manager profile, in step 2, for Create Traffic Manager profile, use the following steps:
- Save aside the unique Traffic Manager profile name for Name - for example,
tmprofile-mjg022624. - Save aside the new resource group name for Resource group - for example,
myResourceGroupTM1.
- Save aside the unique Traffic Manager profile name for Name - for example,
When you reach the section Add Traffic Manager endpoints, use the following steps:
- After you open the Traffic Manager profile in step 2, in the Configuration page, use the following steps:
- For DNS time to live (TTL), enter 10.
- Under Endpoint monitor settings, for Path, enter /websphere-cafe/, which is the context root of the deployed sample app.
- Under Fast endpoint failover settings, use the following values:
- For Probing internal, select 10.
- For Tolerated number of failures, enter 3.
- For Probe timeout, use 5.
- Select Save. Wait until it completes.
- In step 4 for adding the primary endpoint
myPrimaryEndpoint, use the following steps:- For Target resource type, select Public IP address.
- Select the Choose public IP address dropdown and enter the name of the public IP address of the IHS in the East US region that you saved aside previously. You should see one entry matched. Select it for Public IP address.
- In step 6 for adding a failover/secondary endpoint
myFailoverEndpoint, use the following steps:- For Target resource type, select Public IP address.
- Select the Choose public IP address dropdown and enter the name of the public IP address of the IHS in the West US region that you saved aside previously. You should see one entry matched. Select it for Public IP address.
- Wait for a while. Select Refresh until the Monitor status for endpoint
myPrimaryEndpointis Online and Monitor status for endpointmyFailoverEndpointis Degraded.
- After you open the Traffic Manager profile in step 2, in the Configuration page, use the following steps:
Next, use the following steps to verify that the sample app deployed to the primary WebSphere cluster is accessible from the Traffic Manager profile:
Select Overview for the Traffic Manager profile you created.
Select and copy the domain name system (DNS) name of the Traffic Manager profile, then append it with
/websphere-cafe/- for example,http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/.Open the URL in a new tab of the browser. You should see the coffee you created previously listed on the page.
Create another coffee with a different name and price - for example, Coffee 2 with price 20 - which is persisted into both application data table and session table of the database. The UI that you see should be similar to the following screenshot:
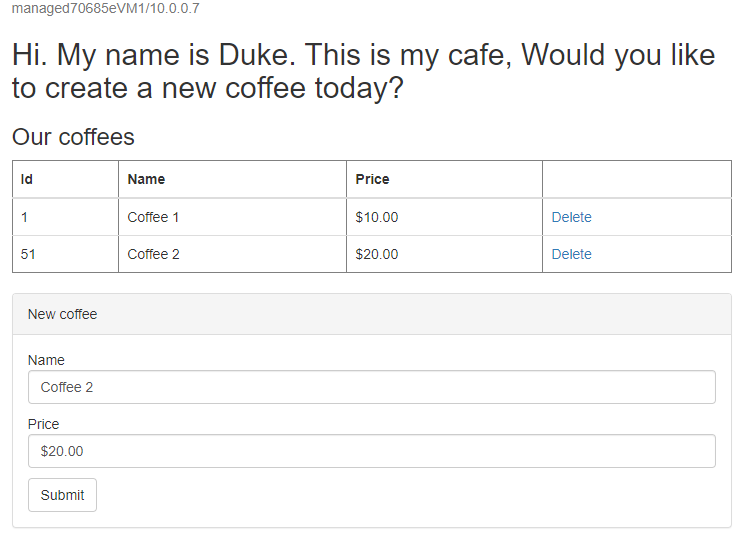

If your UI doesn't look similar, troubleshoot and resolve the issue before you continue. Keep the console open and use it for failover test later.
Now you set up the Traffic Manager profile. Keep the page open and you use it for monitoring the endpoint status change in a failover event later.
Test failover from primary to secondary
To test failover, you manually failover your Azure SQL Database server and cluster, and then fail back using the Azure portal.
Failover to the secondary site
First, use the following steps to failover the Azure SQL Database from the primary server to the secondary server:
- Switch to the browser tab of your Azure SQL Database failover group - for example,
failovergroup-mjg022624. - Select Failover > Yes.
- Wait until it completes.
Next, use the following steps to failover the WebSphere cluster with the recovery plan:
In the search box at the top of the Azure portal, enter Recovery Services vaults and then select Recovery Services vaults in the search results.
Select the name of your Recovery Services vault - for example,
recovery-service-vault-westus-mjg022624.Under Manage, select Recovery Plans (Site Recovery). Select the recovery plan you created - for example,
recovery-plan-mjg022624.Select Failover. Select I understand the risk. Skip test failover.. Leave the default values for other fields and select OK.
Note
You can optionally execute Test failover and Cleanup test failover to make sure everything works as expected before you test Failover. For more information, see Tutorial: Run a disaster recovery drill for Azure VMs. This tutorial tests Failover directly to simplify the exercise.
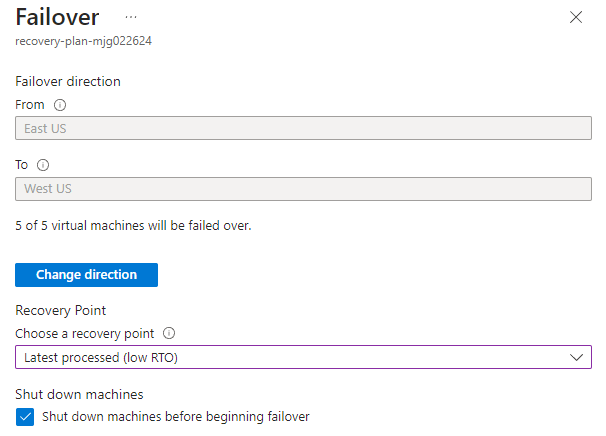
Monitor the failover in notifications until it completes. It takes about 10 minutes for the exercise in this tutorial.
Optionally, you can view details of failover job by selecting the failover event - for example, Failover of 'recovery-plan-mjg022624' is in progress... - from notifications.
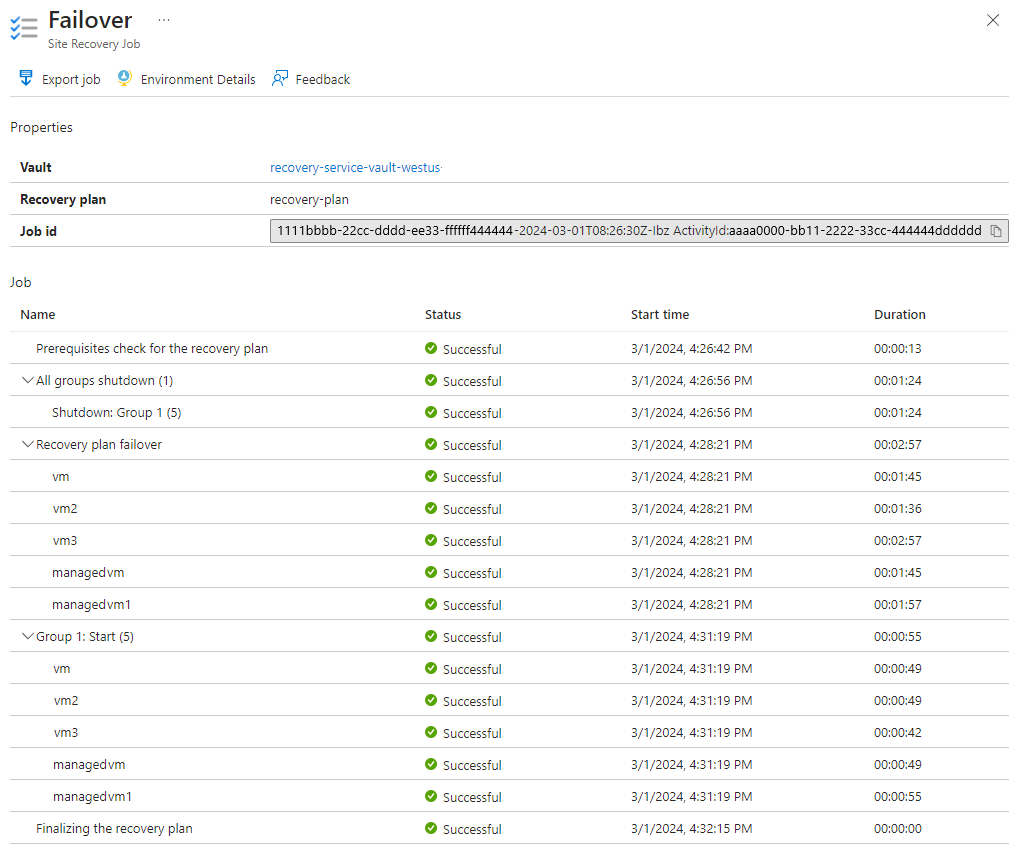




Then, use the following steps to enable the external access to the WebSphere Integrated Solutions Console and sample app in the secondary region:
- In the search box at the top of the Azure portal, enter Resource groups and then select Resource groups in the search results.
- Select the name of resource group for your secondary region - for example,
was-cluster-westus-mjg022624. Sort items by Type in the Resource Group page. - Select Network Interface prefixed with
dmgr. Select IP configurations > ipconfig1. Select Associate public IP address. For Public IP address, select the public IP address prefixed withdmgr. This address is the one you created previously. In this article, the address is nameddmgr-public-ip-westus-mjg022624. Select Save, and then wait until it completes. - Switch back to the resource group, and select the Network Interface prefixed with
ihs. Select IP configurations > ipconfig1. Select Associate public IP address. For Public IP address, select the public IP address prefixed withihs. This address is the one you created previously. In this article, the address is namedihs-public-ip-westus-mjg022624. Select Save, and then wait until it completes.
Now, use the following steps to verify that the failover works as expected:
Find the DNS name label for the public IP address of the Dmgr you created previously. Open the URL of Dmgr WebSphere Integrated Solutions Console in a new browser tab. Don't forget to use
https. For example,https://dmgrmjg022624.westus.cloudapp.azure.com:9043/ibm/console. Refresh the page until you see the welcome page for sign in.Sign in to the console with the user name and password for WebSphere administrator that you saved aside previously, and then use the following steps:
In the navigation pane, select Servers > All servers. In the Middleware servers pane, you should see 4 servers listed, including 3 WebSphere application servers consisting of WebSphere cluster
MyClusterand 1 Web server that is an IHS. Refresh the page until you see that all servers are started.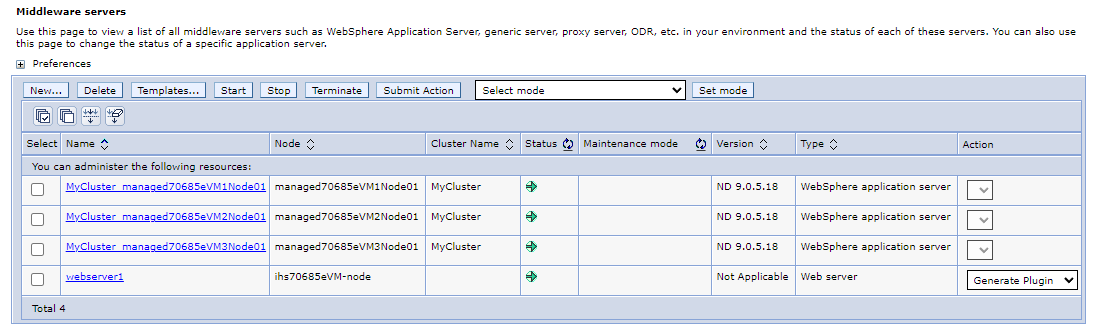
In the navigation pane, select Applications > Application Types > WebSphere enterprise applications. In the Enterprise Applications pane, you should see 1 application -
websphere-cafe- listed and started.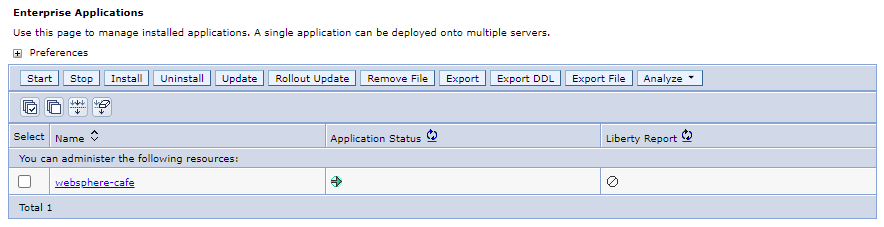
To validate the cluster configuration in the secondary region, follow the steps in the Configure the cluster section. You should see that the settings for Synchronize changes with Nodes and Distributed sessions are replicated to the failover cluster, as shown in the following screenshots:
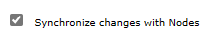
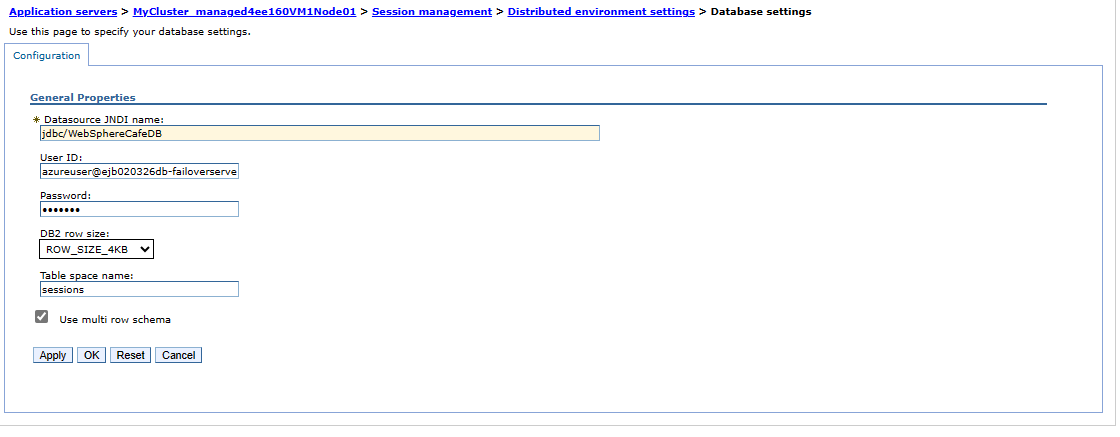
Find the DNS name label for the public IP address of the IHS you created previously. Open the URL of IHS console appended with the root context
/websphere-cafe/. Note that you must not usehttps. This example doesn't usehttpsfor IHS - for example,http://ihsmjg022624.westus.cloudapp.azure.com/websphere-cafe/. You should see two coffees you created previously listed in the page.Switch to the browser tab of your Traffic Manager profile, then refresh the page until you see that the Monitor status value of the endpoint
myFailoverEndpointbecomes Online and the Monitor status value of the endpointmyPrimaryEndpointbecomes Degraded.Switch to the browser tab with the DNS name of the Traffic Manager profile - for example,
http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/. Refresh the page and you should see the same data persisted in the application data table and the session table displayed. The UI that you see should be similar to the following screenshot: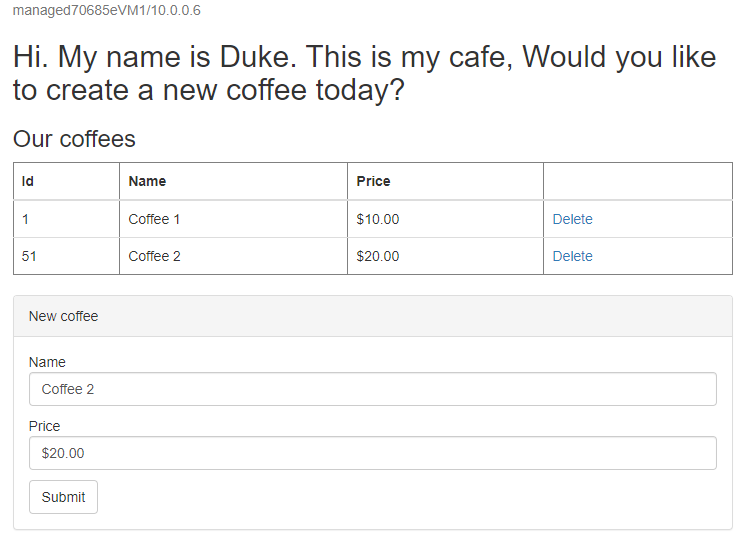
If you don't observe this behavior, it might be because the Traffic Manager is taking time to update DNS to point to the failover site. The problem could also be that your browser cached the DNS name resolution result that points to the failed site. Wait for a while and refresh the page again.





Commit the failover
Use the following steps to commit the failover after you're satisfied the failover result:
In the search box at the top of the Azure portal, enter Recovery Services vaults and then select Recovery Services vaults in the search results.
Select the name of your Recovery Services vault - for example,
recovery-service-vault-westus-mjg022624.Under Manage, select Recovery Plans (Site Recovery). Select the recovery plan you created - for example,
recovery-plan-mjg022624.Select Commit > OK.
Monitor the commit in notifications until it completes.
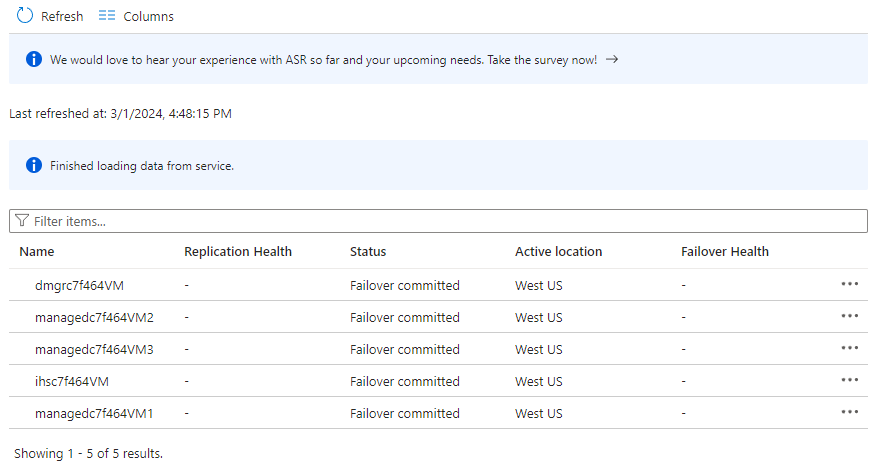
Select Items in recovery plan. You should see 5 items listed as Failover committed.



Disable the replication
Use the following steps to disable the replication for items in the recovery plan and then delete the recovery plan:
For each item in Items in recovery plan, select the ellipsis button (...), and then select Disable Replication.
If you're prompted to provide a reason for disabling protection for this virtual machine, select one you prefer - for example, I completed migrating my application. Select OK.
Repeat step 1 until you disable replication for all items.
Monitor the process in notifications until it completes.
Select Overview > Delete. Select Yes to confirm deletion.

Prepare for fail back: reprotect the failover site
The secondary region is now the failover site and active. You should reprotect it in your primary region.
First, use the following steps to clean up resources that are unused and that the Azure Site Recovery service is going to replicate in your primary region later. You can't just delete the resource group, because the site recovery restores resources into the existing resource group.
- In the search box at the top of the Azure portal, enter Resource groups and then select Resource groups in the search results.
- Select the name of resource group for your primary region - for example,
was-cluster-eastus-mjg022624. Sort items by Type on the Resource Group page. - Use the following steps to delete the virtual machines:
- Select the Type filter, then select Virtual machine from the Value dropdown list.
- Select Apply.
- Select all virtual machines, select Delete, then enter delete to confirm deletion.
- Select Delete.
- Monitor the process in notifications until it completes.
- Use the following steps to delete the disks:
- Select the Type filter, then select Disks from the Value dropdown list.
- Select Apply.
- Select all disks, select Delete, then enter delete to confirm deletion.
- Select Delete.
- Monitor the process in notifications, and wait until it completes.
- Use the following steps to delete the endpoints:
- Select the Type filter, select Private endpoint from the Value dropdown list.
- Select Apply.
- Select all private endpoints, select Delete, then enter delete to confirm deletion.
- Select Delete.
- Monitor the process in notifications until it completes. Ignore this step if type Private endpoint isn't listed.
- Use the following steps to delete the network interfaces:
- Select the Type filter > select Network Interface from the Value dropdown list.
- Select Apply.
- Select all network interfaces, select Delete, then enter delete to confirm deletion.
- Select Delete. Monitor the process in notifications until it completes.
- Use the following steps to delete storage accounts:
- Select the Type filter > select Storage account from the Value dropdown list.
- Select Apply.
- Select all storage accounts, select Delete, then enter delete to confirm deletion.
- Select Delete. Monitor the process in notifications until it completes.
Next, use the same steps in the Set up disaster recovery for the cluster using Azure Site Recovery section for the primary region, except for the following differences:
- For the Create a Recovery Services vault section, use the following steps:
- Select the resource group deployed in the primary region - for example,
was-cluster-eastus-mjg022624. - Enter a different name for the service vault - for example,
recovery-service-vault-eastus-mjg022624. - For Region, select East US.
- Select the resource group deployed in the primary region - for example,
- For Enable replication, use the following steps:
- For Region in Source, select West US.
- For Replication settings, use the following steps:
- For Target resource group, select the existing resource group deployed in the primary region - for example,
was-cluster-eastus-mjg022624. - For Failover virtual network, select the existing virtual network in the primary region.
- For Target resource group, select the existing resource group deployed in the primary region - for example,
- For Create a recovery plan, for Source, select West US, and for Target, select East US.
- Skip the steps in the section Further network configuration for the secondary region because you created and configured these resources previously.
Note
You might notice that Azure Site Recovery supports VM reprotection when the target VM exists. For more information, see the Reprotect the VM section of Tutorial: Fail over Azure VMs to a secondary region. Due to the approach we're taking for WebSphere, this feature doesn't work. The reason is that the only changes between the source disk and the target disk are synchronized for the WebSphere cluster, based on the verification result. To replace the functionality of the VM reprotection feature, this tutorial establishes a new replication from the secondary site to the primary site after failover. The entire disks are copied from the failed over region to the primary region. For more information, see the What happens during reprotection? section of Reprotect failed over Azure virtual machines to the primary region.
Fail back to the primary site
Use the same steps in the Failover to the secondary site section to fail back to the primary site including database server and cluster, except for the following differences:
- Select the recovery service vault deployed in the primary region - for example,
recovery-service-vault-eastus-mjg022624. - Select the resource group deployed in the primary region - for example,
was-cluster-eastus-mjg022624. - After you enable the external access to the WebSphere Integrated Solutions Console and sample app in the primary region, revisit the browser tabs for the WebSphere Integrated Solutions Console and the sample app for the primary cluster you opened previously. Verify that they work as expected. Depending on how much time it took to fail back, you might not see session data displayed in the New coffee section of the sample app UI if it expired more than one hour previously.
- In the Commit the failover section, select your Recovery Services vault deployed in the primary - for example,
recovery-service-vault-eastus-mjg022624. - In the Traffic Manager profile, you should see that endpoint
myPrimaryEndpointbecomes Online and endpointmyFailoverEndpointbecomes Degraded. - In the Prepare for fail back: reprotect the failover site section, use the following steps:
- The primary region is your failover site and is active, so you should reprotect it in your secondary region.
- Clean up resource deployed in your secondary region - for example, resources deployed in
was-cluster-westus-mjg022624. - Use the same steps in the Set up disaster recovery for the cluster using Azure Site Recovery section for protecting the primary region in the secondary region, except for the following changes:
- Skip the steps in the Create a Recovery Services vault section because you created one previously - for example,
recovery-service-vault-westus-mjg022624. - For Enable replication > Replication settings > Failover virtual network, select the existing virtual network in the secondary region.
- Skip the steps in the Further network configuration for the secondary region section because you created and configured these resources previously.
- Skip the steps in the Create a Recovery Services vault section because you created one previously - for example,
Clean up resources
If you're not going to continue to use the WebSphere clusters and other components, use the following steps to delete the resource groups to clean up the resources used in this tutorial:
- Enter the resource group name of Azure SQL Database servers - for example,
myResourceGroup- in the search box at the top of the Azure portal, and select the matched resource group from the search results. - Select Delete resource group.
- In Enter resource group name to confirm deletion, enter the resource group name.
- Select Delete.
- Repeat steps 1-4 for the resource group of the Traffic Manager - for example,
myResourceGroupTM1. - In the search box at the top of the Azure portal, enter Recovery Services vaults and then select Recovery Services vaults in the search results.
- Select the name of your Recovery Services vault - for example,
recovery-service-vault-westus-mjg022624. - Under Manage, select Recovery Plans (Site Recovery). Select the recovery plan you created - for example,
recovery-plan-mjg022624. - Use the same steps in the Disable the replication section to remove locks on replicated items.
- Repeat steps 1-4 for the resource group of the primary WebSphere cluster - for example,
was-cluster-westus-mjg022624. - Repeat steps 1-4 for the resource group of the secondary WebSphere cluster - for example,
was-cluster-eastus-mjg022624.
Next steps
In this tutorial, you set up an HA/DR solution consisting of an active-passive application infrastructure tier with an active-passive database tier, and in which both tiers span two geographically different sites. At the first site, both the application infrastructure tier and the database tier are active. At the second site, the secondary domain is restored with Azure Site Recovery service, and the secondary database is on standby.
Continue to explore the following references for more options to build HA/DR solutions and run WebSphere on Azure: