What is Azure Kubernetes Service backup?
Azure Kubernetes Service (AKS) backup is a simple, cloud-native process you can use to back up and restore containerized applications and data that run in your AKS cluster. You can configure scheduled backups for cluster state and application data that's stored on persistent volumes in CSI driver-based Azure Disk Storage. The solution gives you granular control to choose a specific namespace or an entire cluster to back up or restore by storing backups locally in a blob container and as disk snapshots. You can use AKS backup for end-to-end scenarios, including operational recovery, cloning developer/test environments, and cluster upgrade scenarios.
AKS backup integrates with Backup center in Azure, providing a single view that can help you govern, monitor, operate, and analyze backups at scale. Your backups are also available in the Azure portal under Settings in the service menu for an AKS instance.
How does AKS backup work?
Use AKS backup to back up your AKS workloads and persistent volumes that are deployed in AKS clusters. The solution requires the Backup extension to be installed inside the AKS cluster. The Backup vault communicates to the extension to complete operations that are related to backup and restore. Using the Backup extension is mandatory, and the extension must be installed inside the AKS cluster to enable backup and restore for the cluster. When you configure AKS backup, you add values for a storage account and a blob container where backups are stored.
Along with the Backup extension, a user identity (called an extension identity) is created in the AKS cluster's managed resource group. The extension identity is assigned the Storage Account Contributor role on the storage account where backups are stored in a blob container.
To support public, private, and authorized IP-based clusters, AKS backup requires Trusted Access to be enabled between the AKS cluster and the Backup vault. Trusted Access allows the Backup vault to access the AKS cluster because of specific permissions that are assigned to it for backup operations. For more information on AKS Trusted Access, see Enable Azure resources to access AKS clusters by using Trusted Access.
Note
AKS backup allows you to store backups in both Operational Tier and Vault Tier. The Operational Tier is a local datastore (backups are stored in your tenant as snapshots). You can now move one recovery point per day and store it in Vault Tier as blobs (outside your tenant) using AKS backup. Backups stored in the Vault can also be used to restore data in a secondary region (Azure paired region).
After the Backup extension is installed and Trusted Access is enabled, you can configure scheduled backups for the clusters per your backup policy. You also can restore the backups to the original cluster or to an alternate cluster that's in the same subscription and region. You can choose a specific namespace or an entire cluster as a backup and restore configuration as you set up the specific operation.
The backup solution enables the backup operations for your AKS datasources that are deployed in the cluster and for the data that's stored in the persistent volume for the cluster, and then store the backups in a blob container. The disk-based persistent volumes are backed up as disk snapshots in a snapshot resource group. The snapshots and cluster state in a blob both combine to form a recovery point that is stored in your tenant called Operational Tier. You can also convert backups (first successful backup in a day, week, month, or year) in the Operational Tier to blobs, and then move them to a Vault (outside your tenant) once a day.
Note
Currently, Azure Backup supports only persistent volumes in CSI driver-based Azure Disk Storage. During backups, the solution skips other persistent volume types, such as Azure File Share and blobs. Also, if you have defined retention rules for Vault tier then backups are only eligible to be moved to the vault if the persistent volumes are of size less than or equal to 1 TB.
Configure backup
To configure backups for AKS clusters, first create a Backup vault. The vault gives you a consolidated view of the backups that are configured across different datasources. AKS backup supports both Operational Tier and Vault Tier backups.
Note
- The Backup vault and the AKS cluster that you want to back up or restore must be in the same region and subscription.
- The Backup vault storage redundancy setting (LRS/GRS) only applies to backups stored in Vault Tier. If you want to use backups for disaster recovery, set the storage redundancy as GRS with Cross Region Restore enabled.
AKS backup automatically triggers a scheduled backup job. The job copies the cluster resources to a blob container and creates an incremental snapshot of the disk-based persistent volumes as per the backup frequency. The backups are retained in the Operational Tier and Vault Tier as per the retention duration defined in the backup policy and are deleted once the duration is over.
Note
You can use AKS backup to create multiple backup instances for a single AKS cluster by using different backup configurations per backup instance. However, each backup instance of an AKS cluster should be created either in a different Backup vault or by using a separate backup policy in the same Backup vault.
Manage backup
When the backup configuration for an AKS cluster is finished, a backup instance is created in the Backup vault. You can view the backup instance for the cluster in the Backup section for an AKS instance in the Azure portal. You can perform any backup-related operations for the instance, such as initiating restores, monitoring, stopping protection, and so on, through its corresponding backup instance.
AKS backup also integrates directly with Backup center to help you manage protection for all your AKS clusters and other backup-supported workloads centrally. Backup center is a single view for all your backup requirements, such as monitoring jobs and the state of backups and restores. Backup center helps you ensure compliance and governance, analyze backup usage, and perform critical operations to back up and restore data.
AKS backup uses managed identity to access other Azure resources. To configure backup of an AKS cluster and to restore from an earlier backup, the Backup vault's managed identity requires a set of permissions on the AKS cluster and the snapshot resource group where snapshots are created and managed. Currently, the AKS cluster requires a set of permissions on the snapshot resource group. Also, the Backup extension creates a user identity and assigns a set of permissions to access the storage account where backups are stored in a blob. You can grant permissions to the managed identity by using Azure role-based access control (Azure RBAC). A managed identity is a special type of service principle that can be used only with Azure resources. Learn more about managed identities.
Restore from a backup
You can restore data from any point in time for which a recovery point exists. A recovery point is created when a backup instance is in a protected state and can be used to restore data until it's retained by the backup policy.
Azure Backup gives you the option to restore all the items that are backed up or to use granular controls to select specific items from the backups by choosing namespaces and other filter options. Also, you can do the restore on the original AKS cluster (the cluster that's backed up) or on an alternate AKS cluster. You can restore backups that are stored in Operational and Vault Tier to a cluster in the same and different subscription. Only backups stored in Vault Tier can be used to do a restore to a cluster in a different region (Azure Paired Region).
To restore backup stored in Vault Tier, you must provide a staging location where the backup data is hydrated. This staging location includes a resource group and a storage account in it within the same region and a subscription as the target cluster for restore. During restore, specific resources (blob container, disk, and disk snapshots) are created as part of hydration, which is then cleared after the restore operation is complete.
Azure Backup for AKS currently supports the following two options when doing a restore operation when resource clash happens (backed-up resource has the same name as the resource in the target AKS cluster). You can choose one of these options when defining the restore configuration.
Skip: This option is selected by default. For example, if you have backed up a PVC named pvc-azuredisk and you're restoring it in a target cluster that has the PVC with the same name, then the backup extension skips restoring the backed-up persistent volume claim (PVC). In such scenarios, we recommend you to delete the resource from the cluster, and then do the restore operation so that the backed-up items are only available in the cluster and aren't skipped.
Patch: This option allows the patching mutable variable in the backed-up resource on the resource in the target cluster. If you want to update the number of replicas in the target cluster, you can opt for patching as an operation.
Note
AKS backup currently doesn't delete and recreate resources in the target cluster if they already exist. If you attempt to restore Persistent Volumes in the original location, delete the existing Persistent Volumes, and then do the restore operation.
Use custom hooks for backup and restore
You can use custom hooks to take application-consistent snapshots of volumes that are used for databases deployed as containerized workloads.
What are custom hooks?
You can use AKS backup to execute custom hooks as part of a backup and restore operation. Hooks are commands that are configured to run one or more commands to execute in a pod under a container during a backup operation or after restore. You define these hooks as a custom resource and deploy them in the AKS cluster that you want to back up or restore. When the custom resource is deployed in the AKS cluster in the required namespace, you provide the details as input for the flow to configure backup and restore. The Backup extension runs the hooks as defined in a YAML file.
Note
Hooks aren't executed in a shell on the containers.
Backup in AKS has two types of hooks:
- Backup hooks
- Restore hooks
Backup hooks
In a backup hook, you can configure the commands to run the hook before any custom action processing (pre-hooks), or after all custom actions are finished and any additional items specified by custom actions are backed up (post-hooks).
For example, here's the YAML template for a custom resource to be deployed by using backup hooks:
apiVersion: clusterbackup.dataprotection.microsoft.com/v1alpha1
kind: BackupHook
metadata:
# BackupHook CR Name and Namespace
name: bkphookname0
namespace: default
spec:
# BackupHook is a list of hooks to execute before and after backing up a resource.
backupHook:
# BackupHook Name. This is the name of the hook that will be executed during backup.
# compulsory
- name: hook1
# Namespaces where this hook will be executed.
includedNamespaces:
- hrweb
excludedNamespaces:
labelSelector:
# PreHooks is a list of BackupResourceHooks to execute prior to backing up an item.
preHooks:
- exec:
# Container is the container in the pod where the command should be executed.
container: webcontainer
# Command is the command and arguments to execute.
command:
- /bin/uname
- -a
# OnError specifies how Velero should behave if it encounters an error executing this hook
onError: Continue
# Timeout is the amount of time to wait for the hook to complete before considering it failed.
timeout: 10s
- exec:
command:
- /bin/bash
- -c
- echo hello > hello.txt && echo goodbye > goodbye.txt
container: webcontainer
onError: Continue
# PostHooks is a list of BackupResourceHooks to execute after backing up an item.
postHooks:
- exec:
container: webcontainer
command:
- /bin/uname
- -a
onError: Continue
timeout: 10s
Restore hooks
In the restore hook script, custom commands or scripts are written to be executed in the containers of a restored AKS pod.
Here's the YAML template for a custom resource to be deployed by using restore hooks:
apiVersion: clusterbackup.dataprotection.microsoft.com/v1alpha1
kind: RestoreHook
metadata:
name: restorehookname0
namespace: default
spec:
# RestoreHook is a list of hooks to execute after restoring a resource.
restoreHook:
# Name is the name of this hook.
- name: myhook-1
# Restored Namespaces where this hook will be executed.
includedNamespaces:
excludedNamespaces:
labelSelector:
# PostHooks is a list of RestoreResourceHooks to execute during and after restoring a resource.
postHooks:
- exec:
# Container is the container in the pod where the command should be executed.
container: webcontainer
# Command is the command and arguments to execute from within a container after a pod has been restored.
command:
- /bin/bash
- -c
- echo hello > hello.txt && echo goodbye > goodbye.txt
# OnError specifies how Velero should behave if it encounters an error executing this hook
# default value is Continue
onError: Continue
# Timeout is the amount of time to wait for the hook to complete before considering it failed.
execTimeout: 30s
# WaitTimeout defines the maximum amount of time Velero should wait for the container to be ready before attempting to run the command.
waitTimeout: 5m
Learn how to use hooks during AKS backup.
Note
- During restore, backup extension waits for container to come up and then executes exec commands on them, defined in the restore hooks.
- In case you are performing restore to the same namespace that was backed up, the restore hooks will not be executed as it only looks for new container that gets spawned. This is regardless of whether skip or patch policy is opted.
Modify resource while restoring backups to AKS cluster
You can use the Resource Modification feature to modify backed-up Kubernetes resources during restore by specifying JSON patches as configmap deployed in the AKS cluster.
Create and apply a resource modifier configmap during restore
To create and apply resource modification, follow these steps:
Create resource modifiers configmap.
You need to create one configmap in your preferred namespace from a YAML file that defined resource modifiers.
Example for creating command:
version: v1 resourceModifierRules: - conditions: groupResource: persistentvolumeclaims resourceNameRegex: "^mysql.*$" namespaces: - bar - foo labelSelector: matchLabels: foo: bar patches: - operation: replace path: "/spec/storageClassName" value: "premium" - operation: remove path: "/metadata/labels/test"- The above configmap applies the JSON patch to all the Persistent Volume Copies in the namespaces bar and foo with name that starts with
mysqlandmatch label foo: bar. The JSON patch replaces thestorageClassNamewithpremiumand removes the labeltestfrom the Persistent Volume Copies. - Here, the Namespace is the original namespace of the backed-up resource, and not the new namespace where the resource is going to be restored.
- You can specify multiple JSON patches for a particular resource. The patches are applied as per the order specified in the configmap. A subsequent patch is applied in order. If multiple patches are specified for the same path, the last patch overrides the previous patches.
- You can specify multiple
resourceModifierRulesin the configmap. The rules are applied as per the order specified in the configmap.
- The above configmap applies the JSON patch to all the Persistent Volume Copies in the namespaces bar and foo with name that starts with
Creating a resource modifier reference in the restore configuration
When you perform a restore operation, provide the ConfigMap name and the Namespace where it's deployed as part of restore configuration. These details need to be provided under Resource Modifier Rules.
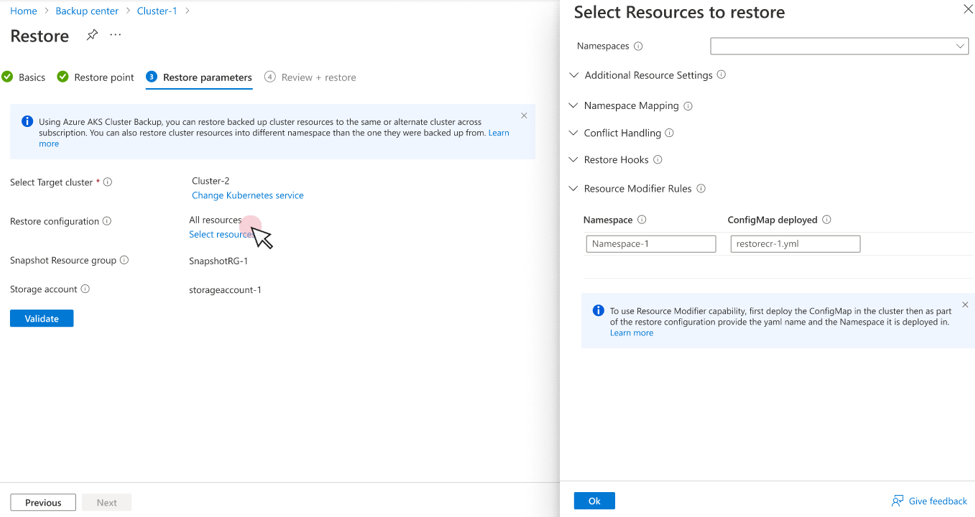

Operations supported by Resource Modifier
Add
You can use the Add operation to add a new block to the resource json. In the example below, the operation add a new container details to the spec with a deployment.
version: v1 resourceModifierRules: - conditions: groupResource: deployments.apps resourceNameRegex: "^test-.*$" namespaces: - bar - foo patches: # Dealing with complex values by escaping the yaml - operation: add path: "/spec/template/spec/containers/0" value: "{\"name\": \"nginx\", \"image\": \"nginx:1.14.2\", \"ports\": [{\"containerPort\": 80}]}"Remove
You can use the Remove operation to remove a key from the resource json. In the example below, the operation removes the label with test as key.
version: v1 resourceModifierRules: - conditions: groupResource: persistentvolumeclaims resourceNameRegex: "^mysql.*$" namespaces: - bar - foo labelSelector: matchLabels: foo: bar patches: - operation: remove path: "/metadata/labels/test"Replace
You can use the Replace operation to replace a value for the path mentioned to an alternate one. In the example below, the operation replaces the storageClassName in the persistent volume claim with premium.
version: v1 resourceModifierRules: - conditions: groupResource: persistentvolumeclaims resourceNameRegex: "^mysql.*$" namespaces: - bar - foo labelSelector: matchLabels: foo: bar patches: - operation: replace path: "/spec/storageClassName" value: "premium"Copy
You can use the Copy operation to copy a value from one path from the resources defined to another path.
version: v1 resourceModifierRules: - conditions: groupResource: deployments.apps resourceNameRegex: "^test-.*$" namespaces: - bar - foo patches: - operation: copy from: "/spec/template/spec/containers/0" path: "/spec/template/spec/containers/1"Test
You can use the Test operation to check if a particular value is present in the resource. If the value is present, the patch is applied. If the value isn't present, the patch isn't applied. In the example below, the operation checks whether the persistent volume claims have premium as StorageClassName and replaces if with standard, if true.
version: v1 resourceModifierRules: - conditions: groupResource: persistentvolumeclaims resourceNameRegex: ".*" namespaces: - bar - foo patches: - operation: test path: "/spec/storageClassName" value: "premium" - operation: replace path: "/spec/storageClassName" value: "standard"JSON Patch
This configmap applies the JSON patch to all the deployments in the namespaces by default and ``nginx
with the name that starts withnginxdep`. The JSON patch updates the replica count to 12 for all such deployments.version: v1 resourceModifierRules: - conditions: groupResource: deployments.apps resourceNameRegex: "^nginxdep.*$" namespaces: - default - nginx patches: - operation: replace path: "/spec/replicas" value: "12"JSON Merge Patch
This config map will apply the JSON Merge Patch to all the deployments in the namespaces default and nginx with the name starting with nginxdep. The JSON Merge Patch will add/update the label "app" with the value "nginx1".
version: v1 resourceModifierRules: - conditions: groupResource: deployments.apps resourceNameRegex: "^nginxdep.*$" namespaces: - default - nginx mergePatches: - patchData: | { "metadata" : { "labels" : { "app" : "nginx1" } } }Strategic Merge Patch
This config map will apply the Strategic Merge Patch to all the pods in the namespace default with the name starting with nginx. The Strategic Merge Patch will update the image of container nginx to mcr.microsoft.com/cbl-mariner/base/nginx:1.22
version: v1 resourceModifierRules: - conditions: groupResource: pods resourceNameRegex: "^nginx.*$" namespaces: - default strategicPatches: - patchData: | { "spec": { "containers": [ { "name": "nginx", "image": "mcr.microsoft.com/cbl-mariner/base/nginx:1.22" } ] } }
Which backup storage tier does AKS backup support?
Azure Backup for AKS supports two storage tiers as backup datastores:
Operational Tier: The Backup Extension installed in the AKS cluster first takes the backup by taking Volume snapshots via CSI Driver and stores cluster state in a blob container in your own tenant. This tier supports lower RPO with the minimum duration between two backups of four hours. Additionally, for Azure Disk-based volumes, Operational Tier supports quicker restores.
Vault Tier: To store backup data for longer duration at lower cost than snapshots, AKS backup supports Vault-standard datastore. As per the retention rules set in the backup policy, the first successful backup (of a day, week, month, or year) is moved to a blob container outside your tenant. This datastore not only allows longer retention, but also provides ransomware protection. You can also move backups stored in the vault to another region (Azure Paired Region) for recovery by enabling Geo redundancy and Cross Region Restore in the Backup vault.
Note
You can store the backup data in a vault-standard datastore via Backup Policy by defining retention rules. Only one scheduled recovery point per day is moved to Vault Tier. However, you can move any number of on-demand backups to the Vault as per the rule selected.
Understand pricing
You incur charges for:
Protected instance fee: Azure Backup for AKS charges a protected instance fee per namespace per month. When you configure backup for an AKS cluster, a protected instance is created. Each instance has a specific number of namespaces that are backed up as defined in the backup configuration. For more information on the AKS backup pricing, see Pricing for Cloud Backup and select Azure Kubernetes Service as workload
Snapshot fee: Azure Backup for AKS protects a disk-based persistent volume by taking snapshots that are stored in the resource group in your Azure subscription. These snapshots incur snapshot storage charges. Because the snapshots aren't copied to the Backup vault, backup storage cost doesn't apply. For more information on the snapshot pricing, see Managed Disk pricing.
Backup Storage fee: Azure Backup for AKS also supports storing backups in Vault Tier. This can be achieved by defining retention rules for vault-standard in the backup policy, with one restore point per day eligible to be moved into the Vault. Restore points stored in the Vault Tier are charged a separate fee called Backup Storage fee as per the total data stored (in GBs) and redundancy type enable on the Backup Vault.