Quickstart: Get started using Azure OpenAI audio generation
The gpt-4o-audio-preview model introduces the audio modality into the existing /chat/completions API. The audio model expands the potential for AI applications in text and voice-based interactions and audio analysis. Modalities supported in gpt-4o-audio-preview model include: text, audio, and text + audio.
Here's a table of the supported modalities with example use cases:
| Modality input | Modality output | Example use case |
|---|---|---|
| Text | Text + audio | Text to speech, audio book generation |
| Audio | Text + audio | Audio transcription, audio book generation |
| Audio | Text | Audio transcription |
| Text + audio | Text + audio | Audio book generation |
| Text + audio | Text | Audio transcription |
By using audio generation capabilities, you can achieve more dynamic and interactive AI applications. Models that support audio inputs and outputs allow you to generate spoken audio responses to prompts and use audio inputs to prompt the model.
Supported models
Currently only gpt-4o-audio-preview version: 2024-12-17 supports audio generation.
The gpt-4o-audio-preview model is available for global deployments in East US 2 and Sweden Central regions.
Currently the following voices are supported for audio out: Alloy, Echo, and Shimmer.
The maximum audio file size is 20 MB.
Note
The Realtime API uses the same underlying GPT-4o audio model as the completions API, but is optimized for low-latency, real-time audio interactions.
API support
Support for audio completions was first added in API version 2025-01-01-preview.
Deploy a model for audio generation
To deploy the gpt-4o-audio-preview model in the Azure AI Foundry portal:
- Go to the Azure OpenAI Service page in Azure AI Foundry portal. Make sure you're signed in with the Azure subscription that has your Azure OpenAI Service resource and the deployed
gpt-4o-audio-previewmodel. - Select the Chat playground from under Playgrounds in the left pane.
- Select + Create new deployment > From base models to open the deployment window.
- Search for and select the
gpt-4o-audio-previewmodel and then select Deploy to selected resource. - In the deployment wizard, select the
2024-12-17model version. - Follow the wizard to finish deploying the model.
Now that you have a deployment of the gpt-4o-audio-preview model, you can interact with it in the Azure AI Foundry portal Chat playground or chat completions API.
Use GPT-4o audio generation
To chat with your deployed gpt-4o-audio-preview model in the Chat playground of Azure AI Foundry portal, follow these steps:
Go to the Azure OpenAI Service page in Azure AI Foundry portal. Make sure you're signed in with the Azure subscription that has your Azure OpenAI Service resource and the deployed
gpt-4o-audio-previewmodel.Select the Chat playground from under Resource playground in the left pane.
Select your deployed
gpt-4o-audio-previewmodel from the Deployment dropdown.Start chatting with the model and listen to the audio responses.
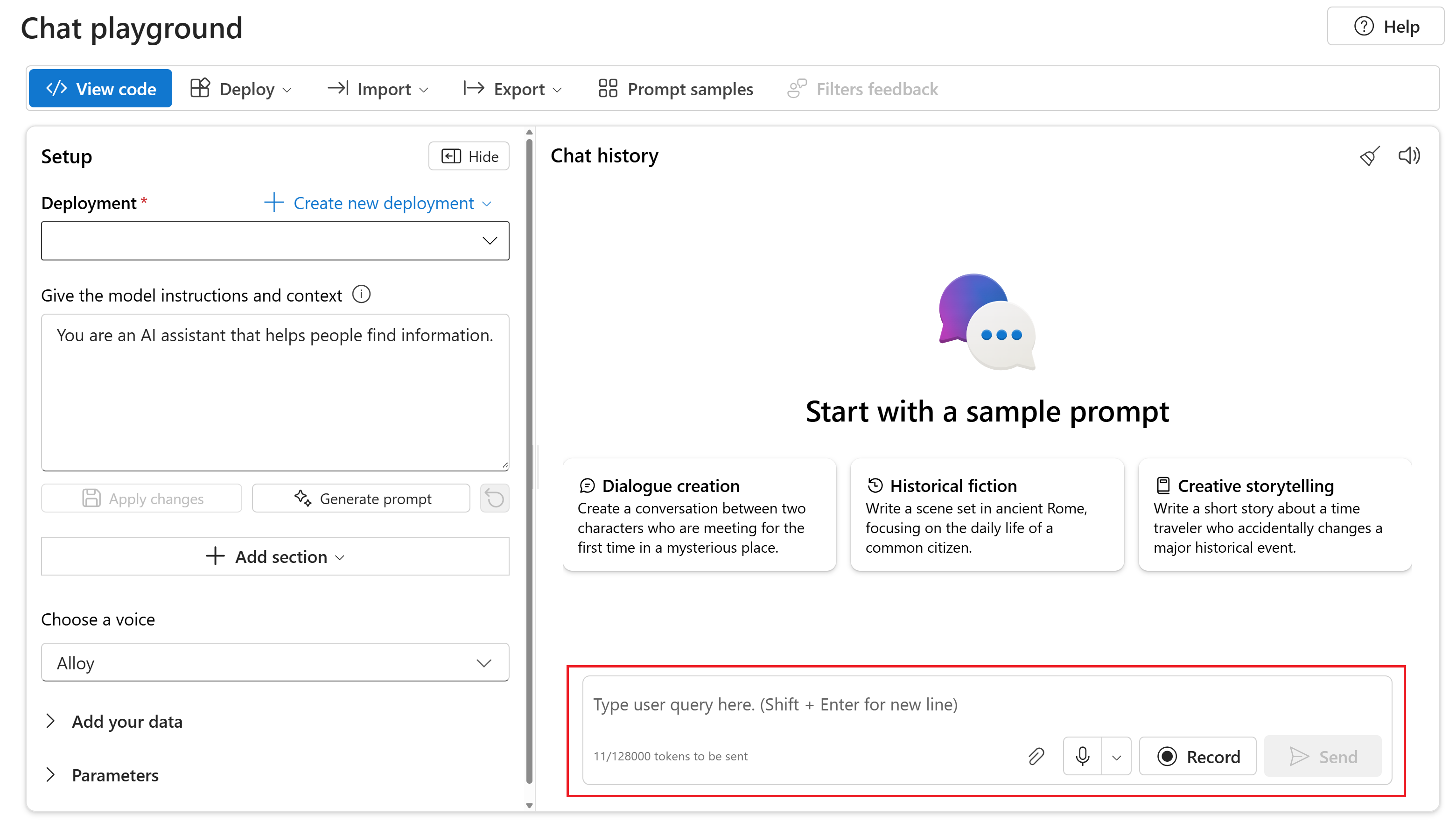
You can:
- Record audio prompts.
- Attach audio files to the chat.
- Enter text prompts.

Reference documentation | Library source code | Package (npm) | Samples
The gpt-4o-audio-preview model introduces the audio modality into the existing /chat/completions API. The audio model expands the potential for AI applications in text and voice-based interactions and audio analysis. Modalities supported in gpt-4o-audio-preview model include: text, audio, and text + audio.
Here's a table of the supported modalities with example use cases:
| Modality input | Modality output | Example use case |
|---|---|---|
| Text | Text + audio | Text to speech, audio book generation |
| Audio | Text + audio | Audio transcription, audio book generation |
| Audio | Text | Audio transcription |
| Text + audio | Text + audio | Audio book generation |
| Text + audio | Text | Audio transcription |
By using audio generation capabilities, you can achieve more dynamic and interactive AI applications. Models that support audio inputs and outputs allow you to generate spoken audio responses to prompts and use audio inputs to prompt the model.
Supported models
Currently only gpt-4o-audio-preview version: 2024-12-17 supports audio generation.
The gpt-4o-audio-preview model is available for global deployments in East US 2 and Sweden Central regions.
Currently the following voices are supported for audio out: Alloy, Echo, and Shimmer.
The maximum audio file size is 20 MB.
Note
The Realtime API uses the same underlying GPT-4o audio model as the completions API, but is optimized for low-latency, real-time audio interactions.
API support
Support for audio completions was first added in API version 2025-01-01-preview.
Prerequisites
- An Azure subscription - Create one for free
- Node.js LTS or ESM support.
- An Azure OpenAI resource created in the East US 2 or Sweden Central regions. See Region availability.
- Then, you need to deploy a
gpt-4o-audio-previewmodel with your Azure OpenAI resource. For more information, see Create a resource and deploy a model with Azure OpenAI.
Microsoft Entra ID prerequisites
For the recommended keyless authentication with Microsoft Entra ID, you need to:
- Install the Azure CLI used for keyless authentication with Microsoft Entra ID.
- Assign the
Cognitive Services Userrole to your user account. You can assign roles in the Azure portal under Access control (IAM) > Add role assignment.
Set up
Create a new folder
audio-completions-quickstartto contain the application and open Visual Studio Code in that folder with the following command:mkdir audio-completions-quickstart && code audio-completions-quickstartCreate the
package.jsonwith the following command:npm init -yUpdate the
package.jsonto ECMAScript with the following command:npm pkg set type=moduleInstall the OpenAI client library for JavaScript with:
npm install openaiFor the recommended keyless authentication with Microsoft Entra ID, install the
@azure/identitypackage with:npm install @azure/identity
Retrieve resource information
You need to retrieve the following information to authenticate your application with your Azure OpenAI resource:
| Variable name | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
This value can be found in the Keys and Endpoint section when examining your resource from the Azure portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
This value will correspond to the custom name you chose for your deployment when you deployed a model. This value can be found under Resource Management > Model Deployments in the Azure portal. |
OPENAI_API_VERSION |
Learn more about API Versions. |
Learn more about keyless authentication and setting environment variables.
Caution
To use the recommended keyless authentication with the SDK, make sure that the AZURE_OPENAI_API_KEY environment variable isn't set.
Generate audio from text input
Create the
to-audio.jsfile with the following code:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Sign in to Azure with the following command:
az loginRun the JavaScript file.
node to-audio.js
Wait a few moments to get the response.
Output for audio generation from text input
The script generates an audio file named dog.wav in the same directory as the script. The audio file contains the spoken response to the prompt, "Is a golden retriever a good family dog?"
Generate audio and text from audio input
Create the
from-audio.jsfile with the following code:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Sign in to Azure with the following command:
az loginRun the JavaScript file.
node from-audio.js
Wait a few moments to get the response.
Output for audio and text generation from audio input
The script generates a transcript of the summary of the spoken audio input. It also generates an audio file named analysis.wav in the same directory as the script. The audio file contains the spoken response to the prompt.
Generate audio and use multi-turn chat completions
Create the
multi-turn.jsfile with the following code:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Sign in to Azure with the following command:
az loginRun the JavaScript file.
node multi-turn.js
Wait a few moments to get the response.
Output for multi-turn chat completions
The script generates a transcript of the summary of the spoken audio input. Then, it makes a multi-turn chat completion to briefly summarize the spoken audio input.
Library source code | Package | Samples
The gpt-4o-audio-preview model introduces the audio modality into the existing /chat/completions API. The audio model expands the potential for AI applications in text and voice-based interactions and audio analysis. Modalities supported in gpt-4o-audio-preview model include: text, audio, and text + audio.
Here's a table of the supported modalities with example use cases:
| Modality input | Modality output | Example use case |
|---|---|---|
| Text | Text + audio | Text to speech, audio book generation |
| Audio | Text + audio | Audio transcription, audio book generation |
| Audio | Text | Audio transcription |
| Text + audio | Text + audio | Audio book generation |
| Text + audio | Text | Audio transcription |
By using audio generation capabilities, you can achieve more dynamic and interactive AI applications. Models that support audio inputs and outputs allow you to generate spoken audio responses to prompts and use audio inputs to prompt the model.
Supported models
Currently only gpt-4o-audio-preview version: 2024-12-17 supports audio generation.
The gpt-4o-audio-preview model is available for global deployments in East US 2 and Sweden Central regions.
Currently the following voices are supported for audio out: Alloy, Echo, and Shimmer.
The maximum audio file size is 20 MB.
Note
The Realtime API uses the same underlying GPT-4o audio model as the completions API, but is optimized for low-latency, real-time audio interactions.
API support
Support for audio completions was first added in API version 2025-01-01-preview.
Use this guide to get started generating audio with the Azure OpenAI SDK for Python.
Prerequisites
- An Azure subscription. Create one for free.
- Python 3.8 or later version. We recommend using Python 3.10 or later, but having at least Python 3.8 is required. If you don't have a suitable version of Python installed, you can follow the instructions in the VS Code Python Tutorial for the easiest way of installing Python on your operating system.
- An Azure OpenAI resource created in the East US 2 or Sweden Central regions. See Region availability.
- Then, you need to deploy a
gpt-4o-audio-previewmodel with your Azure OpenAI resource. For more information, see Create a resource and deploy a model with Azure OpenAI.
Microsoft Entra ID prerequisites
For the recommended keyless authentication with Microsoft Entra ID, you need to:
- Install the Azure CLI used for keyless authentication with Microsoft Entra ID.
- Assign the
Cognitive Services Userrole to your user account. You can assign roles in the Azure portal under Access control (IAM) > Add role assignment.
Set up
Create a new folder
audio-completions-quickstartto contain the application and open Visual Studio Code in that folder with the following command:mkdir audio-completions-quickstart && code audio-completions-quickstartCreate a virtual environment. If you already have Python 3.10 or higher installed, you can create a virtual environment using the following commands:
Activating the Python environment means that when you run
pythonorpipfrom the command line, you then use the Python interpreter contained in the.venvfolder of your application. You can use thedeactivatecommand to exit the python virtual environment, and can later reactivate it when needed.Tip
We recommend that you create and activate a new Python environment to use to install the packages you need for this tutorial. Don't install packages into your global python installation. You should always use a virtual or conda environment when installing python packages, otherwise you can break your global installation of Python.
Install the OpenAI client library for Python with:
pip install openaiFor the recommended keyless authentication with Microsoft Entra ID, install the
azure-identitypackage with:pip install azure-identity
Retrieve resource information
You need to retrieve the following information to authenticate your application with your Azure OpenAI resource:
| Variable name | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
This value can be found in the Keys and Endpoint section when examining your resource from the Azure portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
This value will correspond to the custom name you chose for your deployment when you deployed a model. This value can be found under Resource Management > Model Deployments in the Azure portal. |
OPENAI_API_VERSION |
Learn more about API Versions. |
Learn more about keyless authentication and setting environment variables.
Generate audio from text input
Create the
to-audio.pyfile with the following code:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Run the Python file.
python to-audio.py
Wait a few moments to get the response.
Output for audio generation from text input
The script generates an audio file named dog.wav in the same directory as the script. The audio file contains the spoken response to the prompt, "Is a golden retriever a good family dog?"
Generate audio and text from audio input
Create the
from-audio.pyfile with the following code:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Run the Python file.
python from-audio.py
Wait a few moments to get the response.
Output for audio and text generation from audio input
The script generates a transcript of the summary of the spoken audio input. It also generates an audio file named analysis.wav in the same directory as the script. The audio file contains the spoken response to the prompt.
Generate audio and use multi-turn chat completions
Create the
multi-turn.pyfile with the following code:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Run the Python file.
python multi-turn.py
Wait a few moments to get the response.
Output for multi-turn chat completions
The script generates a transcript of the summary of the spoken audio input. Then, it makes a multi-turn chat completion to briefly summarize the spoken audio input.
The gpt-4o-audio-preview model introduces the audio modality into the existing /chat/completions API. The audio model expands the potential for AI applications in text and voice-based interactions and audio analysis. Modalities supported in gpt-4o-audio-preview model include: text, audio, and text + audio.
Here's a table of the supported modalities with example use cases:
| Modality input | Modality output | Example use case |
|---|---|---|
| Text | Text + audio | Text to speech, audio book generation |
| Audio | Text + audio | Audio transcription, audio book generation |
| Audio | Text | Audio transcription |
| Text + audio | Text + audio | Audio book generation |
| Text + audio | Text | Audio transcription |
By using audio generation capabilities, you can achieve more dynamic and interactive AI applications. Models that support audio inputs and outputs allow you to generate spoken audio responses to prompts and use audio inputs to prompt the model.
Supported models
Currently only gpt-4o-audio-preview version: 2024-12-17 supports audio generation.
The gpt-4o-audio-preview model is available for global deployments in East US 2 and Sweden Central regions.
Currently the following voices are supported for audio out: Alloy, Echo, and Shimmer.
The maximum audio file size is 20 MB.
Note
The Realtime API uses the same underlying GPT-4o audio model as the completions API, but is optimized for low-latency, real-time audio interactions.
API support
Support for audio completions was first added in API version 2025-01-01-preview.
Prerequisites
- An Azure subscription. Create one for free.
- Python 3.8 or later version. We recommend using Python 3.10 or later, but having at least Python 3.8 is required. If you don't have a suitable version of Python installed, you can follow the instructions in the VS Code Python Tutorial for the easiest way of installing Python on your operating system.
- An Azure OpenAI resource created in the East US 2 or Sweden Central regions. See Region availability.
- Then, you need to deploy a
gpt-4o-audio-previewmodel with your Azure OpenAI resource. For more information, see Create a resource and deploy a model with Azure OpenAI.
Microsoft Entra ID prerequisites
For the recommended keyless authentication with Microsoft Entra ID, you need to:
- Install the Azure CLI used for keyless authentication with Microsoft Entra ID.
- Assign the
Cognitive Services Userrole to your user account. You can assign roles in the Azure portal under Access control (IAM) > Add role assignment.
Set up
Create a new folder
audio-completions-quickstartto contain the application and open Visual Studio Code in that folder with the following command:mkdir audio-completions-quickstart && code audio-completions-quickstartCreate a virtual environment. If you already have Python 3.10 or higher installed, you can create a virtual environment using the following commands:
Activating the Python environment means that when you run
pythonorpipfrom the command line, you then use the Python interpreter contained in the.venvfolder of your application. You can use thedeactivatecommand to exit the python virtual environment, and can later reactivate it when needed.Tip
We recommend that you create and activate a new Python environment to use to install the packages you need for this tutorial. Don't install packages into your global python installation. You should always use a virtual or conda environment when installing python packages, otherwise you can break your global installation of Python.
Install the OpenAI client library for Python with:
pip install openaiFor the recommended keyless authentication with Microsoft Entra ID, install the
azure-identitypackage with:pip install azure-identity
Retrieve resource information
You need to retrieve the following information to authenticate your application with your Azure OpenAI resource:
| Variable name | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
This value can be found in the Keys and Endpoint section when examining your resource from the Azure portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
This value will correspond to the custom name you chose for your deployment when you deployed a model. This value can be found under Resource Management > Model Deployments in the Azure portal. |
OPENAI_API_VERSION |
Learn more about API Versions. |
Learn more about keyless authentication and setting environment variables.
Generate audio from text input
Create the
to-audio.pyfile with the following code:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Run the Python file.
python to-audio.py
Wait a few moments to get the response.
Output for audio generation from text input
The script generates an audio file named dog.wav in the same directory as the script. The audio file contains the spoken response to the prompt, "Is a golden retriever a good family dog?"
Generate audio and text from audio input
Create the
from-audio.pyfile with the following code:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Run the Python file.
python from-audio.py
Wait a few moments to get the response.
Output for audio and text generation from audio input
The script generates a transcript of the summary of the spoken audio input. It also generates an audio file named analysis.wav in the same directory as the script. The audio file contains the spoken response to the prompt.
Generate audio and use multi-turn chat completions
Create the
multi-turn.pyfile with the following code:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Run the Python file.
python multi-turn.py
Wait a few moments to get the response.
Output for multi-turn chat completions
The script generates a transcript of the summary of the spoken audio input. Then, it makes a multi-turn chat completion to briefly summarize the spoken audio input.
Reference documentation | Library source code | Package (npm) | Samples
The gpt-4o-audio-preview model introduces the audio modality into the existing /chat/completions API. The audio model expands the potential for AI applications in text and voice-based interactions and audio analysis. Modalities supported in gpt-4o-audio-preview model include: text, audio, and text + audio.
Here's a table of the supported modalities with example use cases:
| Modality input | Modality output | Example use case |
|---|---|---|
| Text | Text + audio | Text to speech, audio book generation |
| Audio | Text + audio | Audio transcription, audio book generation |
| Audio | Text | Audio transcription |
| Text + audio | Text + audio | Audio book generation |
| Text + audio | Text | Audio transcription |
By using audio generation capabilities, you can achieve more dynamic and interactive AI applications. Models that support audio inputs and outputs allow you to generate spoken audio responses to prompts and use audio inputs to prompt the model.
Supported models
Currently only gpt-4o-audio-preview version: 2024-12-17 supports audio generation.
The gpt-4o-audio-preview model is available for global deployments in East US 2 and Sweden Central regions.
Currently the following voices are supported for audio out: Alloy, Echo, and Shimmer.
The maximum audio file size is 20 MB.
Note
The Realtime API uses the same underlying GPT-4o audio model as the completions API, but is optimized for low-latency, real-time audio interactions.
API support
Support for audio completions was first added in API version 2025-01-01-preview.
Prerequisites
- An Azure subscription - Create one for free
- Node.js LTS or ESM support.
- TypeScript installed globally.
- An Azure OpenAI resource created in the East US 2 or Sweden Central regions. See Region availability.
- Then, you need to deploy a
gpt-4o-audio-previewmodel with your Azure OpenAI resource. For more information, see Create a resource and deploy a model with Azure OpenAI.
Microsoft Entra ID prerequisites
For the recommended keyless authentication with Microsoft Entra ID, you need to:
- Install the Azure CLI used for keyless authentication with Microsoft Entra ID.
- Assign the
Cognitive Services Userrole to your user account. You can assign roles in the Azure portal under Access control (IAM) > Add role assignment.
Set up
Create a new folder
audio-completions-quickstartto contain the application and open Visual Studio Code in that folder with the following command:mkdir audio-completions-quickstart && code audio-completions-quickstartCreate the
package.jsonwith the following command:npm init -yUpdate the
package.jsonto ECMAScript with the following command:npm pkg set type=moduleInstall the OpenAI client library for JavaScript with:
npm install openaiFor the recommended keyless authentication with Microsoft Entra ID, install the
@azure/identitypackage with:npm install @azure/identity
Retrieve resource information
You need to retrieve the following information to authenticate your application with your Azure OpenAI resource:
| Variable name | Value |
|---|---|
AZURE_OPENAI_ENDPOINT |
This value can be found in the Keys and Endpoint section when examining your resource from the Azure portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
This value will correspond to the custom name you chose for your deployment when you deployed a model. This value can be found under Resource Management > Model Deployments in the Azure portal. |
OPENAI_API_VERSION |
Learn more about API Versions. |
Learn more about keyless authentication and setting environment variables.
Caution
To use the recommended keyless authentication with the SDK, make sure that the AZURE_OPENAI_API_KEY environment variable isn't set.
Generate audio from text input
Create the
to-audio.tsfile with the following code:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Create the
tsconfig.jsonfile to transpile the TypeScript code and copy the following code for ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile from TypeScript to JavaScript.
tscSign in to Azure with the following command:
az loginRun the code with the following command:
node to-audio.js
Wait a few moments to get the response.
Output for audio generation from text input
The script generates an audio file named dog.wav in the same directory as the script. The audio file contains the spoken response to the prompt, "Is a golden retriever a good family dog?"
Generate audio and text from audio input
Create the
from-audio.tsfile with the following code:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Create the
tsconfig.jsonfile to transpile the TypeScript code and copy the following code for ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile from TypeScript to JavaScript.
tscSign in to Azure with the following command:
az loginRun the code with the following command:
node from-audio.js
Wait a few moments to get the response.
Output for audio and text generation from audio input
The script generates a transcript of the summary of the spoken audio input. It also generates an audio file named analysis.wav in the same directory as the script. The audio file contains the spoken response to the prompt.
Generate audio and use multi-turn chat completions
Create the
multi-turn.tsfile with the following code:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Create the
tsconfig.jsonfile to transpile the TypeScript code and copy the following code for ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile from TypeScript to JavaScript.
tscSign in to Azure with the following command:
az loginRun the code with the following command:
node multi-turn.js
Wait a few moments to get the response.
Output for multi-turn chat completions
The script generates a transcript of the summary of the spoken audio input. Then, it makes a multi-turn chat completion to briefly summarize the spoken audio input.
Clean-up resources
If you want to clean up and remove an Azure OpenAI resource, you can delete the resource. Before deleting the resource, you must first delete any deployed models.
Related content
- Learn more about Azure OpenAI deployment types
- Learn more about Azure OpenAI quotas and limits