Document Intelligence general document model
Important
Starting with Document Intelligence versions v4.0 preview versions and going forward, the general document model (prebuilt-document) is deprecated. To extract key-value pairs, selection marks, text, tables, and structure from documents, use the following models:
| Feature | version | Model ID |
|---|---|---|
Layout model with the optional query string parameter features=keyValuePairs enabled. |
• v4:2024-02-29-preview • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| General document model | • v3.1:2023-07-31 (GA) • v3.0:2022-08-31 (GA) • v2.1 (GA) |
prebuilt-document |
The General document model combines powerful Optical Character Recognition (OCR) capabilities with deep learning models to extract key-value pairs, tables, and selection marks from documents. General document is available with the v3.1 and v3.0 APIs. For more information, see our migration guide.
General document features
The general document model is a pretrained model; it doesn't require labels or training.
A single API extracts key-value pairs, selection marks, text, tables, and structure from documents.
The general document model supports structured, semi-structured, and unstructured documents.
Selection marks are identified as fields with a value of
:selected:or:unselected:.
Sample document processed in the Document Intelligence Studio
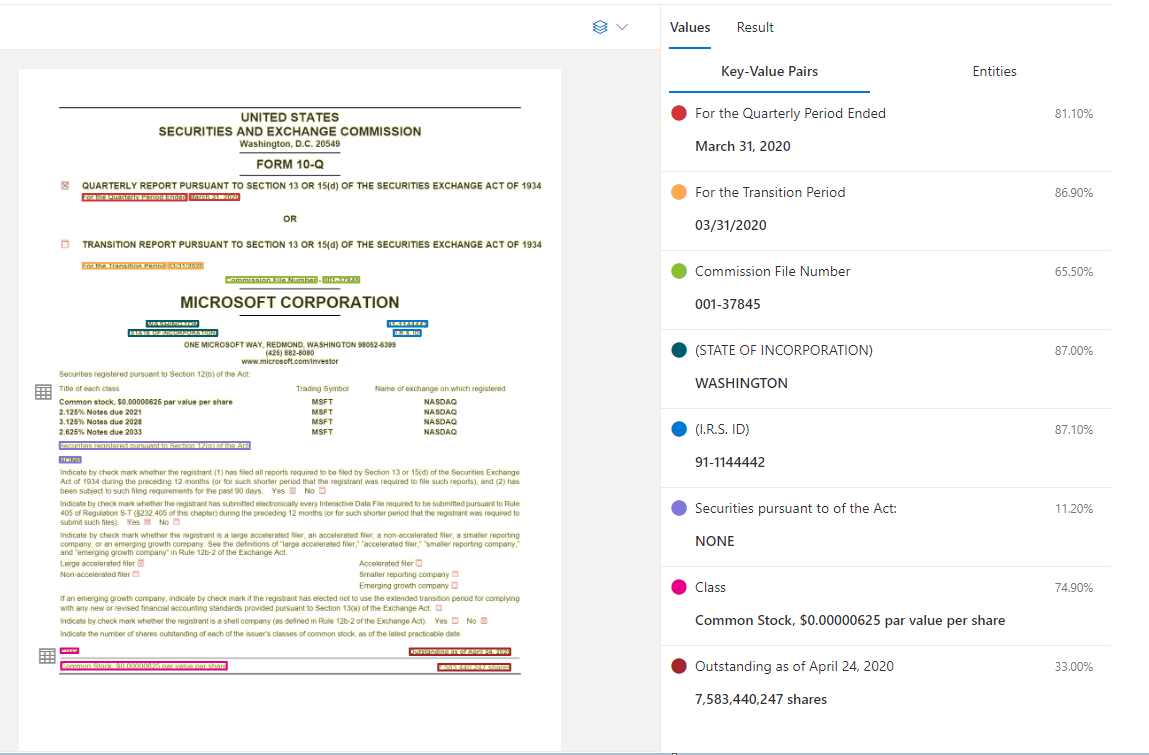
Key-value pair extraction
The general document API supports most form types and analyzes your documents and extract keys and associated values. It's ideal for extracting common key-value pairs from documents. You can use the general document model as an alternative to training a custom model without labels.
Development options
Document Intelligence v3.1 supports the following tools, applications, and libraries:
| Feature | Resources | Model ID |
|---|---|---|
| General document model | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-document |
Document Intelligence v3.0 supports the following tools, applications, and libraries:
| Feature | Resources | Model ID |
|---|---|---|
| General document model | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-document |
Input requirements
Supported file formats:
Model PDF Image: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLRead ✔ ✔ ✔ Layout ✔ ✔ ✔ General Document ✔ ✔ Prebuilt ✔ ✔ Custom extraction ✔ ✔ Custom classification ✔ ✔ ✔ For best results, provide one clear photo or high-quality scan per document.
For PDF and TIFF, up to 2,000 pages can be processed (with a free tier subscription, only the first two pages are processed).
The file size for analyzing documents is 500 MB for paid (S0) tier and
4MB for free (F0) tier.Image dimensions must be between 50 pixels x 50 pixels and 10,000 pixels x 10,000 pixels.
If your PDFs are password-locked, you must remove the lock before submission.
The minimum height of the text to be extracted is 12 pixels for a 1024 x 768 pixel image. This dimension corresponds to about
8point text at 150 dots per inch (DPI).For custom model training, the maximum number of pages for training data is 500 for the custom template model and 50,000 for the custom neural model.
For custom extraction model training, the total size of training data is 50 MB for template model and
1GB for the neural model.For custom classification model training, the total size of training data is
1GB with a maximum of 10,000 pages. For 2024-11-30 (GA), the total size of training data is2GB with a maximum of 10,000 pages.
General document model data extraction
Try extracting data from forms and documents using the Document Intelligence Studio.
You need the following resources:
An Azure subscription—you can create one for free.
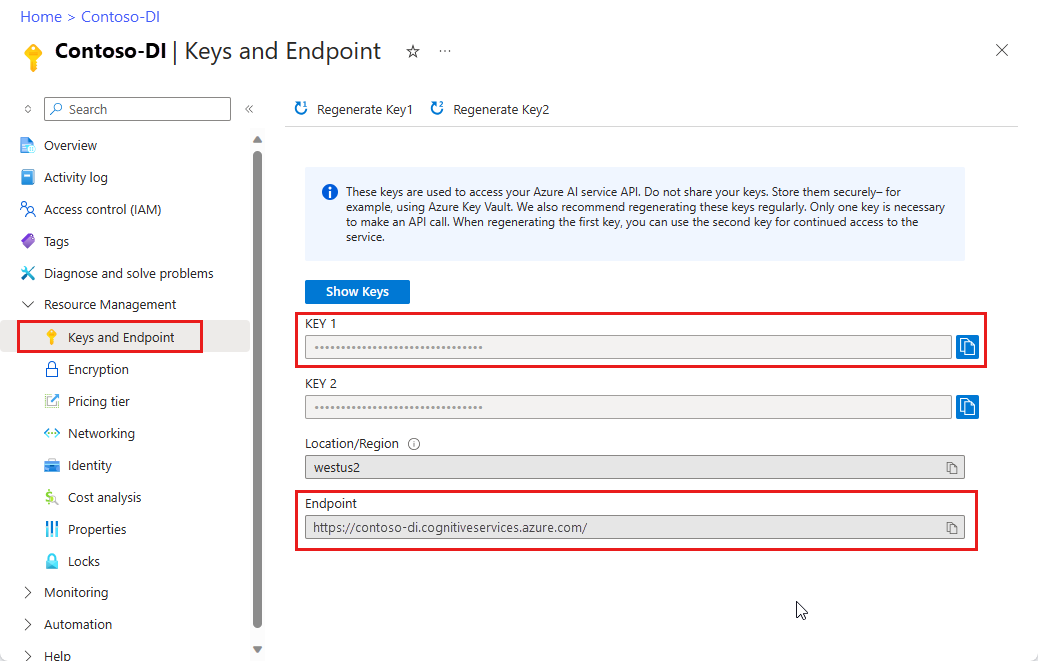
A Document Intelligence instance in the Azure portal. You can use the free pricing tier (
F0) to try the service. After your resource deploys, select Go to resource to get your key and endpoint.
Note
Document Intelligence Studio and the general document model are available with the v3.0 API.
On the Document Intelligence Studio home page, select General documents.
You can analyze the sample document or upload your own files.
Select the Run analysis button and, if necessary, configure the Analyze options:

Key-value pairs
Key-value pairs are specific spans within the document that identify a label or key and its associated response or value. In a structured form, these pairs could be the label and the value the user entered for that field. In an unstructured document, they could be the date a contract was executed on based on the text in a paragraph. The AI model is trained to extract identifiable keys and values based on a wide variety of document types, formats, and structures.
Keys can also exist in isolation when the model detects that a key exists, with no associated value or when processing optional fields. For example, a middle name field can be left blank on a form in some instances. Key-value pairs are spans of text contained in the document. For documents where the same value is described in different ways, for example, customer/user, the associated key is either customer or user (based on context).
Data extraction
| Model | Text extraction | Key-Value pairs | Selection Marks | Tables | Common Names |
|---|---|---|---|---|---|
| General document | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* - Only available in the 2023-07-31 (v3.1 GA) and later API versions.
Supported languages and locales
See our Language Support—document analysis models page for a complete list of supported languages.
Considerations
Because keys are spans of text extracted from the document, for semi structured documents, keys need to be mapped to an existing dictionary of keys.
Expect to see key-value pairs with a key, but no value. For example if a user chose to not provide an email address on the form.
Next steps
Follow our Document Intelligence v3.1 migration guide to learn how to use the v3.1 version in your applications and workflows.
Explore our REST API.