Analyze document API response
In this article, let's examine the different objects returned as part of the AnalyzeDocument response and how to use the document analysis API response in your applications.
Analyze document request
The Document Intelligence APIs analyze images, PDFs, and other document files to extract and detect various content, layout, style, and semantic elements. The Analyze operation is an async API. Submitting a document returns an Operation-Location header that contains the URL to poll for completion. When an analysis request completes successfully, the response contains the elements described in the model data extraction.
Response elements
Content elements are the basic text elements extracted from the document.
Layout elements group content elements into structural units.
Style elements describe the font and language of content elements.
Semantic elements assign meaning to the specified content elements.
All content elements are grouped according to pages, specified by page number (1-indexed). They're also sorted by reading order that arranges semantically contiguous elements together, even if they cross line or column boundaries. When the reading order among paragraphs and other layout elements is ambiguous, the service generally returns the content in a left-to-right, top-to-bottom order.
Note
Currently, Document Intelligence does not support reading order across page boundaries. Selection marks are not positioned within the surrounding words.
The top-level content property contains a concatenation of all content elements in reading order. All elements specify their position in the reader order via spans within this content string. The content of some elements isn't always contiguous.
Analyze response
The Analyze response for each API returns different objects. API responses contain elements from component models where applicable.
| Response content | Description | API |
|---|---|---|
| pages | Words, lines and spans recognized from each page of the input document. | Read, Layout, General Document, Prebuilt, and Custom models |
| paragraphs | Content recognized as paragraphs. | Read, Layout, General Document, Prebuilt, and Custom models |
| styles | Identified text element properties. | Read, Layout, General Document, Prebuilt, and Custom models |
| languages | Identified language associated with each span of the text extracted | Read |
| tables | Tabular content identified and extracted from the document. Tables relate to tables identified by the pretrained layout model. Content labeled as tables is extracted as structured fields in the documents object. | Layout, General Document, Invoice, and Custom models |
| figures | Figures (charts, images) identified and extracted from the document, providing visual representations that aid in the understanding of complex information. | The Layout model |
| sections | Hierarchical document structure identified and extracted from the document. Section or subsection with the corresponding elements (paragraph, table, figure) attached to it. | The Layout model |
| keyValuePairs | Key-value pairs recognized by a pretrained model. The key is a span of text from the document with the associated value. | General document and Invoice models |
| documents | Fields recognized are returned in the fields dictionary within the list of documents |
Prebuilt models, Custom models. |
For more information on the objects returned by each API, see model data extraction.
Element properties
Spans
Spans specify the logical position of each element in the overall reading order, with each span specifying a character offset and length into the top-level content string property. By default, character offsets and lengths are returned in units of user-perceived characters (also known as grapheme clusters or text elements). To accommodate different development environments that use different character units, user can specify the stringIndexIndex query parameter to return span offsets and lengths in Unicode code points (Python 3) or UTF16 code units (Java, JavaScript, .NET) as well. For more information, see multilingual/emoji support.
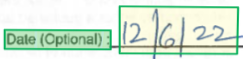
Bounding Region
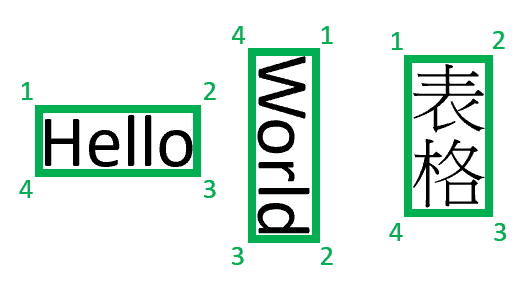
Bounding regions describe the visual position of each element in the file. When elements aren't visually contiguous or cross pages (tables), the positions of most elements are described via an array of bounding regions. Each region specifies the page number (1-indexed) and bounding polygon. The bounding polygon is described as a sequence of points, clockwise from the left relative to the natural orientation of the element. For quadrilaterals, plot points are top-left, top-right, bottom-right, and bottom-left corners. Each point represents its x, y coordinate in the page unit specified by the unit property. In general, unit of measure for images is pixels while PDFs use inches.
Note
Currently, Document Intelligence only returns 4-vertex quadrilaterals as bounding polygons. Future versions may return different number of points to describe more complex shapes, such as curved lines or non-rectangular images. Bounding regions applied only to rendered files, if the file is not rendered, bounding regions are not returned. Currently files of docx/xlsx/pptx/html format are not rendered.
Content elements
Word
A word is a content element composed of a sequence of characters. With Document Intelligence, a word is defined as a sequence of adjacent characters, with whitespace separating words from one another. For languages that don't use space separators between words each character is returned as a separate word, even if it doesn't represent a semantic word unit.

Selection marks
A selection mark is a content element that represents a visual glyph indicating the state of a selection. Checkbox is a common form of selection marks. However, they're also represented via radio buttons or a boxed cell in a visual form. The state of a selection mark can be selected or unselected, with different visual representation to indicate the state.

Layout elements
Line
A line is an ordered sequence of consecutive content elements separated by a visual space, or ones that are immediately adjacent for languages without space delimiters between words. Content elements in the same horizontal plane (row) but separated by more than a single visual space are most often split into multiple lines. While this feature sometimes splits semantically contiguous content into separate lines, it enables the representation of textual content split into multiple columns or cells. Lines in vertical writing are detected in the vertical direction.

Paragraph
A paragraph is an ordered sequence of lines that form a logical unit. Typically, the lines share common alignment and spacing between lines. Paragraphs are often delimited via indentation, added spacing, or bullets/numbering. Content can only be assigned to a single paragraph. Select paragraphs can also be associated with a functional role in the document. Currently supported roles include page header, page footer, page number, title, section heading, and footnote.

Page
A page is a grouping of content that typically corresponds to one side of a sheet of paper. A rendered page is characterized via width and height in the specified unit. In general, images use pixel while PDFs use inch. The angle property describes the overall text angle in degrees for pages that can be rotated.
Note
For spreadsheets like Excel, each sheet is mapped to a page. For presentations, like PowerPoint, each slide is mapped to a page. For file formats without a native concept of pages without rendering like HTML or Word documents, the main content of the file is considered a single page.
Table
A table organizes content into a group of cells in a grid layout. The rows and columns can be visually separated by grid lines, color banding, or greater spacing. The position of a table cell is specified via its row and column indices. A cell can span across multiple rows and columns.
Based on its position and styling, a cell can be classified as general content, row header, column header, stub head, or description:
A row header cell is typically the first cell in a row that describes the other cells in the row.
A column header cell is typically the first cell in a column that describes the other cells in a column.
A row or column can contain multiple header cells to describe hierarchical content.
A stub head cell is typically the cell in the first row and first column position. It can be empty or describe the values in the header cells in the same row/column.
A description cell generally appears at the topmost or bottom area of a table, describing the overall table content. However, it can sometimes appear in the middle of a table to break the table into sections. Typically, description cells span across multiple cells in a single row.
A table caption specifies content that explains the table. A table can further have an associated caption and a set of footnotes. Unlike a description cell, a caption typically lies outside the grid layout. A table footnote annotates content inside the table, often marked with a footnote symbol often found below the table grid.
Layout tables differ from document fields extracted from tabular data. Layout tables are extracted from tabular visual content in the document without considering the semantics of the content. In fact, some layout tables are designed purely for visual layout and don't always contain structured data. The method to extract structured data from documents with diverse visual layout, like itemized details of a receipt, generally requires significant post processing. It's essential to map the row or column headers to structured fields with normalized field names. Depending on the document type, use prebuilt models or train a custom model to extract such structured content. The resulting information is exposed as document fields. Such trained models can also handle tabular data without headers and structured data in nontabular forms, for example the work experience section of a resume.
Note
The bounding regions for figures and tables cover only the core content and exclude associated caption and footnotes.

Figures
Figures (charts, images) in documents play a crucial role in complementing and enhancing the textual content, providing visual representations that aid in the understanding of complex information. The figures object detected by the Layout model has key properties like boundingRegions (the spatial locations of the figure on the document pages, including the page number and the polygon coordinates that outline the figure's boundary), spans (details the text spans related to the figure, specifying their offsets and lengths within the document's text. This connection helps in associating the figure with its relevant textual context), elements (the identifiers for text elements or paragraphs within the document that are related to or describe the figure) and caption, if any.
When output=figures is specified during the initial Analyze operation, the service generates cropped images for all detected figures that can be accessed via /analyeResults/{resultId}/figures/{figureId}.
FigureId is included in each figure object, following an undocumented convention of {pageNumber}.{figureIndex} where figureIndex resets to one per page.
{
"figures": [
{
"id": "{figureId}",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Sections
Hierarchical document structure analysis is pivotal in organizing, comprehending, and processing extensive documents. This approach is vital for semantically segmenting long documents to boost comprehension, facilitate navigation, and improve information retrieval. The advent of Retrieval Augmented Generation (RAG) in document generative AI underscores the significance of hierarchical document structure analysis. The Layout model supports sections and subsections in the output, which identifies the relationship of sections and object within each section. The hierarchical structure is maintained in elements of each section.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Form field (key value pair)
A form field consists of a field label (key) and value. The field label is generally a descriptive text string describing the meaning of the field. It often appears to the left of the value, though it can also appear over or under the value. The field value contains the content value of a specific field instance. The value can consist of words, selection marks, and other content elements. It can also be empty for unfilled form fields. A special type of form field has a selection mark value with the field label to its right. Document field is a similar but distinct concept from general form fields. The field label (key) in a general form field must appear in the document. Thus, it can't generally capture information like the merchant name in a receipt. Document fields are labeled and don't extract a key. Document fields only map an extracted value to a labeled key. For more information, see document fields.

Style elements
Style
A style element describes the font style to apply to text content. The content is specified via spans into the global content property. Currently, the only detected font style is whether the text is handwritten. As other styles are added, text can be described via multiple nonconflicting style objects. For compactness, all text sharing the particular font style (with the same confidence) are described via a single style object.
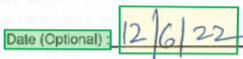
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
Language
A language element describes the detected language for content specified via spans into the global content property. The detected language is specified via a BCP-47 language tag to indicate the primary language and optional script and region information. For example, English and traditional Chinese are recognized as "en" and zh-Hant, respectively. Regional spelling differences for UK English can lead to text being detected as en-GB. Language elements don't cover text without a dominant language (ex. numbers).
Semantic elements
Note
The semantic elements discussed here apply to Document Intelligence prebuilt models. Your custom models may return different data representations. For example, date and time returned by a custom model may be represented in a pattern that differs from standard ISO 8601 formatting.
Document
A document is a semantically complete unit. A file can contain multiple documents, such as multiple tax forms within a PDF file, or multiple receipts within a single page. However, the ordering of documents within the file doesn't fundamentally affect the information it conveys.
Note
Currently, Document Intelligence does not support multiple documents on a single page.
The document type describes documents sharing a common set of semantic fields, represented by a structured schema, independent of its visual template or layout. For example, all documents of type "receipt" can contain the merchant name, transaction date, and transaction total, although restaurant and hotel receipts often differ in appearance.
A document element includes the list of recognized fields from among the fields specified by the semantic schema of the detected document type:
A document field can be extracted or inferred. Extracted fields are represented via the extracted content and optionally its normalized value, if interpretable.
An inferred field doesn't have content property and is represented only via its value.
An array field doesn't include a content property. The content can be concatenated from the content of the array elements.
An object field does contain a content property that specifies the full content representing the object that can be a superset of the extracted subfields.
The semantic schema of a document type is described via the fields it contains. Each field schema is specified via its canonical name and value type. Field value types include basic (ex. string), compound (ex. address), and structured (ex. array, object) types. The field value type also specifies the semantic normalization performed to convert detected content into a normalization representation. Normalization can be locale dependent.
Basic types
| Field value type | Description | Normalized representation | Example (Field content -> Value) |
|---|---|---|---|
| string | Plain text | Same as content | MerchantName: "Contoso" → "Contoso" |
| date | Date | ISO 8601 - YYYY-MM-DD | InvoiceDate: "5/7/2022" → "2022-05-07" |
| time | Time | ISO 8601 - hh:mm:ss | TransactionTime: "9:45 PM" → "21:45:00" |
| phoneNumber | Phone number | E.164 - +{CountryCode}{SubscriberNumber} | WorkPhone: "(800) 555-7676" → "+18005557676" |
| countryRegion | Country/Region | ISO 3166-1 alpha-3 | CountryRegion: "United States" → "USA" |
| selectionMark | Is selected | "signed" or "unsigned" | AcceptEula: ☑ → "selected" |
| signature | Is signed | Same as content | LendeeSignature: {signature} → "signed" |
| number | Floating point number | Floating point number | Quantity: "1.20" → 1.2 |
| integer | Integer number | 64-bit signed number | Count: "123" → 123 |
| boolean | Boolean value | true/false | IsStatutoryEmployee: ☑ → true |
Compound types
Currency: Currency amount with optional currency unit. A value, for example:
InvoiceTotal: $123.45{ "amount": 123.45, "currencySymbol": "$" }Address: Parsed address. For example:
ShipToAddress: 123 Main St., Redmond, WA 98052{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
Structured types
Array: List of fields of the same type
"Items": { "type": "array", "valueArray": [ ] }Object: Named list of subfields of potentially different types
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }
Next steps
Try processing your own forms and documents with Document Intelligence Studio.
Complete a Document Intelligence quickstart and get started creating a document processing app in the development language of your choice.