Security concepts for SQL Server Big Data Clusters
Applies to: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
The Microsoft SQL Server 2019 Big Data Clusters add-on will be retired. Support for SQL Server 2019 Big Data Clusters will end on February 28, 2025. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
This article will cover key security-related concepts.
SQL Server Big Data Clusters provide coherent and consistent authorization and authentication. A big data cluster can be integrated with Active Directory (AD) through a fully automated deployment that sets up AD integration against an existing domain. Once a big data cluster is configured with AD integration, you can leverage existing identities and user groups for unified access across all endpoints. In addition, once you have created external tables in SQL Server, you can control access to data sources by granting access to external tables to AD users and groups, thus centralizing the data access policies to a single location.
In this 14-minute video you will get an overview of big data cluster security:
Authentication
The external cluster endpoints support AD authentication. Use your AD identity to authenticate to the big data cluster.
Cluster endpoints
There are five entry points to the big data cluster
Master instance - TDS endpoint for accessing SQL Server master instance in the cluster, using database tools and applications like SSMS or Azure Data Studio. When using HDFS or SQL Server commands from Azure Data CLI (
azdata), the tool will connect to the other endpoints, depending on the operation.Gateway to access HDFS files, Spark (Knox) - HTTPS endpoint for accessing services like webHDFS and Spark.
Cluster Management Service (Controller) endpoint - Big data cluster management service that exposes REST APIs for managing the cluster. Azdata tool requires connecting to this endpoint.
Management Proxy - For access to the Logs search dashboard and Metrics dashboard.
Application proxy - Endpoint for managing applications deployed inside the big data cluster.
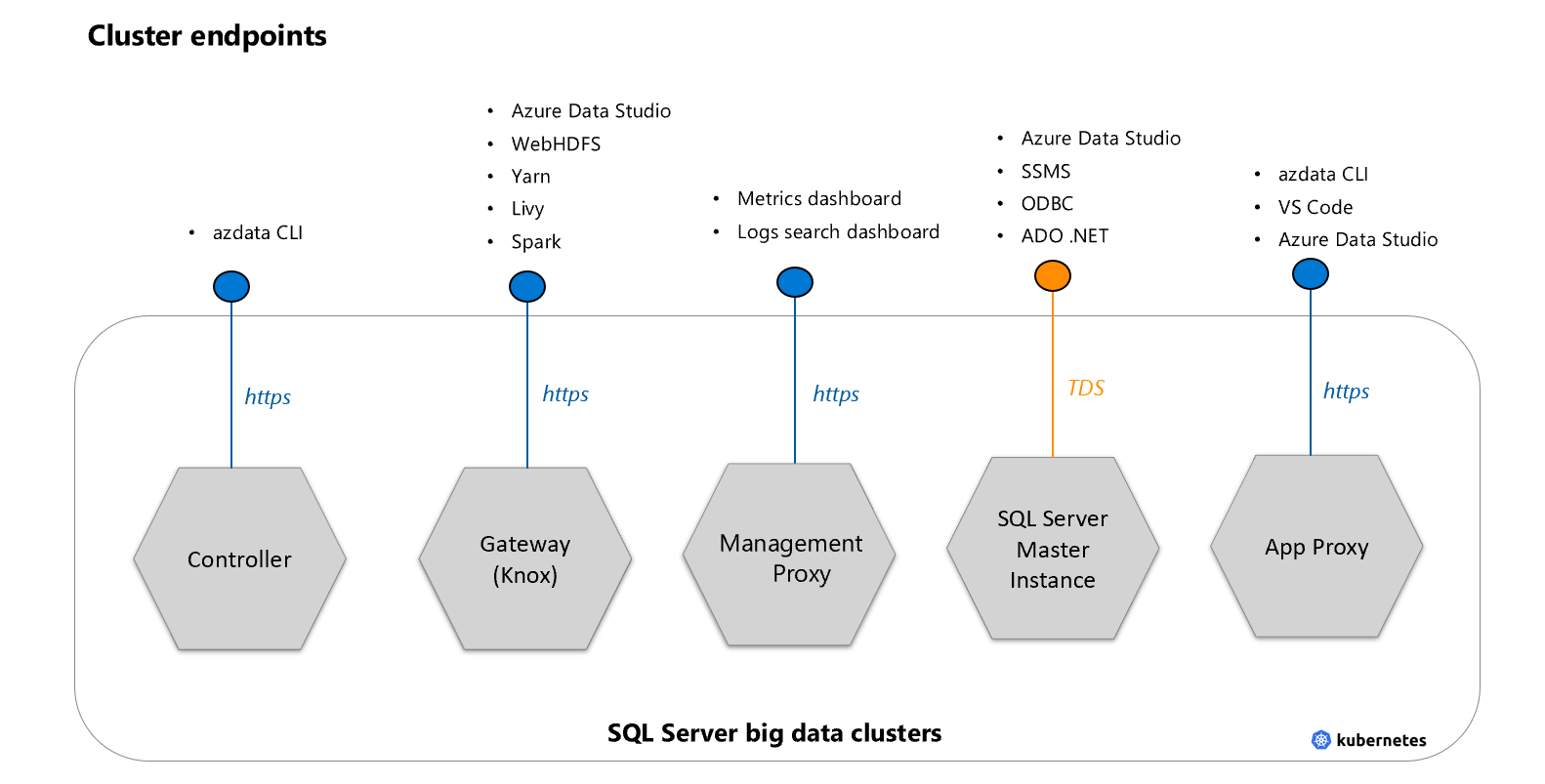
Currently, there is no option of opening up additional ports for accessing the cluster from the outside.
Authorization
Throughout the cluster, integrated security between different components allows the original user's identity to be passed through when issuing queries from Spark and SQL Server, all the way to HDFS. As mentioned above, the various external cluster endpoints support AD authentication.
There are two levels of authorization checks in the cluster for managing data access. Authorization in the context of big data is done in SQL Server, using the traditional SQL Server permissions on objects and in HDFS with control lists (ACLs), which associate user identities with specific permissions.
A secure big data cluster implies consistent and coherent support for authentication and authorization scenarios, across both SQL Server and HDFS/Spark. Authentication is the process of verifying the identity of a user or service and ensuring they are who they are claiming to be. Authorization refers to granting or denying of access to specific resources based on the requesting user's identity. This step is performed after a user is identified through authentication.
Authorization in Big Data context is performed through access control lists (ACLs), which associate user identities with specific permissions. HDFS supports authorization by limiting access to service APIs, HDFS files, and job execution.
Encryption in flight and other security mechanisms
Encryption of communication between clients to the external endpoints, as well as between components inside the cluster are secured with TLS/SSL, using certificates.
All SQL Server to SQL Server communication, such as the SQL master instance communicating with a data pool, is secured using SQL logins.
Important
Big data clusters uses etcd to store credentials. As a best practice, you must ensure your Kubernetes cluster is configured to use etcd encryption at rest. By default, secrets stored in etcd are unencrypted. Kubernetes documentation provides details on this administrative task: https://kubernetes.io/docs/tasks/administer-cluster/kms-provider/ and
https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/.
Data encryption at rest
SQL Server Big Data Clusters encryption at rest capability supports the core scenario of application level encryption for the SQL Server and HDFS components. Follow the Encryption at rest concepts and configuration guide article for a comprehensive feature usage guide.
Important
Volume encryption is recommended for all SQL Server Big Data Cluster deployments. Customer provided storage volumes configured in Kubernetes clusters should be encrypted as well, as a comprehensive approach to data encryption at rest. SQL Server Big Data Cluster encryption at rest capability is an additional security layer, providing application level encryption of SQL Server data and log files and HDFS encryption zone support.
Basic administrator login
You can choose to deploy the cluster in either AD mode, or using only basic administrator login. Only using basic administrator login is not a production supported security mode, and intended for evaluation of the product.
Even if you choose Active directory mode, basic logins will be created for the cluster administrator. This feature provides alternative access, in case AD connectivity is down.
Upon deployment, this basic login will be given administrator permissions in the cluster. The login user will be system administrator in SQL Server master instance and an administrator in the cluster controller. Hadoop components do not support mixed mode authentication, which means that a basic administrator login can't be used to authenticate to Gateway (Knox).
The login credentials you need to define during deployment include.
Cluster admin username:
AZDATA_USERNAME=<username>
Cluster admin password:
AZDATA_PASSWORD=<password>
Note
Note that in non-AD mode, the username has to be used in combination with the above password, for authenticating to the Gateway (Knox) for access to HDFS/Spark. Prior to SQL Server 2019 CU5, the user name was root.
Beginning with SQL Server 2019 (15.x) CU 5, when you deploy a new cluster with basic authentication all endpoints including gateway use AZDATA_USERNAME and AZDATA_PASSWORD. Endpoints on clusters that are upgraded to CU 5 continue to use root as username to connect to gateway endpoint. This change does not apply to deployments using Active Directory authentication. See Credentials for accessing services through gateway endpoint in the release notes.
Manage key versions
SQL Server 2019 Big Data Clusters allows for key version management for SQL Server and HDFS using encryption zones. For more information, see Key versions in Big Data Cluster.
Next steps
Introducing SQL Server 2019 Big Data Clusters
Workshop: Microsoft SQL Server Big Data Clusters Architecture