Learn about exact data match based sensitive information types
Sensitive information types (SITs) are used to help identify sensitive data so that you can prevent it from being inadvertently or inappropriately shared. They're also used to help in locating relevant data in eDiscovery, and to apply governance actions to certain types of information. You define a custom SIT based on:
- patterns
- keyword evidence such as employee, social security number, or ID
- character proximity to evidence in a particular pattern
- confidence levels
But what if you want a custom SIT that uses exact or nearly exact data values, instead of one that finds matches based on generic patterns? With Exact Data Match (EDM) based classification, you can create a custom sensitive information type that is designed to:
- be dynamic and easily refreshed
- result in fewer false positives
- work with structured sensitive data
- handle sensitive information more securely, not sharing it with anyone, including Microsoft
- be used with several Microsoft cloud services
Tip
If you're not an E5 customer, use the 90-day Microsoft Purview solutions trial to explore how additional Purview capabilities can help your organization manage data security and compliance needs. Start now at the Microsoft Purview trials hub. Learn details about signing up and trial terms.
EDM-based classification enables you to create custom SITs that refer to exact values in a database of sensitive information. The database can be refreshed daily and can contain up to 100 million rows of data. So, as employees, patients, and clients come and go, and as records change, your custom sensitive information types remain current and applicable. And, you can use EDM-based classification with policies, such as Microsoft Purview Data Loss Prevention policies or Microsoft Cloud App Security file policies.
The following diagram shows the fundamental workings of EDM classification:
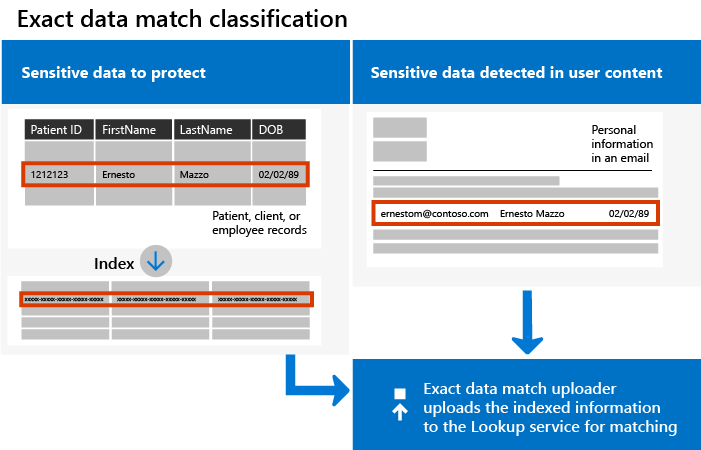
Note
Microsoft Purview Information Protection supports the following languages that use double-byte character sets:
- Chinese (simplified)
- Chinese (traditional)
- Korean
- Japanese
This support is available for sensitive information types. For more information, see Information protection support for double byte character sets: Release Notes (preview).
What's different in an EDM SIT
When you work with EDM SITs, it's helpful to understand a few concepts that are unique to them.
Schema
A schema is an XML file. Microsoft Purview uses the schema to determine whether or not your data contains strings that match those that your sensitive information types are designed to detect.
The schema XML file defines:
- The name of the schema, later referred to as the DataStore.
- The field names that your sensitive information source table contains. There's a 1:1 mapping of schema field names to the column names in the sensitive information source table.
- Which corroborative evidence fields require multi-token match mode.
- Which data fields are searchable.
- Whether or not configurable matches are supported for each field. A configurable match is one with parameters that modify a search, such as ignoring delimiters and case in searched values.
Sensitive information source table
The sensitive information source table contains the values that the EDM SIT looks for. The table is made up of columns and rows. The column headers are the field names, the rows are instances of items and each cell in a row contains the values for that item instance for that field.
Here's a simple example of a sensitive information source table.
| First Name | Last Name | Date of Birth |
|---|---|---|
| Isaiah | Langer | 05-05-1960 |
| Ana | Bowman | 11-24-1971 |
| Oscar | Ward | 02-12-1998 |
Rule package
Every sensitive information type has a rule package. You use the rule package in an EDM SIT to define the various components of your EDM SIT. The following table provides a description of each component.
| Component | Description |
|---|---|
| Match | Specifies the primary element (data field) to be used in exact lookup. It can be a regular expression with or without a checksum validation, a keyword list, a keyword dictionary, or a function. |
| Classification | Specifies the sensitive information type match that triggers an EDM lookup. |
| Supporting elements | Elements that, when found, provide evidence that helps increase the confidence of the match. For example, the occurrence of a last name in close proximity to an actual social security number. A supporting element can be a regular expression with or without a checksum validation, a keyword list, a keyword dictionary, or a single- or multi-token string match. |
| Confidence level (High, Medium, Low) |
Indication of how much supporting evidence is detected in addition to the primary element. The more supporting evidence an item contains, the higher the confidence that a matched item contains the sensitive info you're looking for. For more information about confidence levels, see Fundamental parts of a sensitive information type. |
| Proximity | The number of characters between primary and supporting element. |
You supply your own schema and data
Microsoft Purview comes with many built-in SITs that are predefined. These SITs come with schemas, REGEX patterns, keywords, and confidence levels. However, with EDM SITs, you're responsible for defining the schema, as well as the primary and secondary fields that identify sensitive items. Because the schema and primary and secondary data values are all highly sensitive, you encrypt them via a hash function that includes a randomly generated or self-supplied salt value. Only the hashed values are uploaded to the service, so your sensitive data is never in the open.
Primary and secondary support elements
When you create an EDM SIT, you define a primary element field in the rule package. EDM then searches all of your content for the primary element. So that EDM can detect them, primary elements must be discoverable through an existing SIT.
Note
For a complete list of the available SITs., see Sensitive information type entity definitions
You need to find a built-in SIT that detects the sensitive information that you want your EDM SIT to detect. For example, if your EDM SIT schema has U.S. social security number as the primary element, when you create your EDM schema, you'd associated it with the U.S. Social Security Number (SSN) SIT. Primary elements must follow a defined pattern in order to be detected.
When the primary element is found in a scanned item, EDM then looks for secondary elements (also called supporting elements). Unlike primary elements, secondary elements have the option of following a pattern. If secondary elements contain multiple tokens, those elements need to either be associated with a SIT that can detect that content or that can be configured for multi-token matching. In all cases, secondary elements must be within a certain proximity to the primary element in order for a match to be detected.
How matching works
EDM works by comparing strings in your documents and emails against values in the sensitive information source table. It uses this comparison to determine whether the values in the scanned content are present in the table. The determination is done by comparing one-way cryptographic hashes.
Tip
You can use both EDM SITs and the predefined SITs that they are based on, together in DLP rules to improve the detection of sensitive data. Use the EDM SIT with higher confidence levels, and the predefined SIT with lower confidence levels. For example, use an EDM SIT that looks for social security number and other supporting data with strict requirements with high confidence. If configured for high-confidence matches, EDM generates a DLP match when only a few instances are detected. To trigger a DLP match when greater numbers of occurrences are detected, use a built-in SIT, such as the U.S. Social Security Number.
How supporting elements work with EDM
As discussed in What's different in an EDM SIT, supporting elements are elements that, when found, provide evidence that helps increase the confidence of the match.
With support for EDM SITs, you can look for and detect supporting elements that are composed of multiple fields. Supporting element matches can consist of keyword lists, keyword dictionaries, single alphanumeric strings, or multi-token strings.
Let’s look at an example. Presume that you want to detect U.S. Social Security numbers. To increase the match confidence, your supporting elements include first name, last name, and date of birth (DoB). So, your source table looks something like this:
| SSN | FirstName | LastName | DoB |
|---|---|---|---|
| 987-65-4320 | Isaiah | Langer | 05-05-1960 |
| 078-05-1120 | Ana | Bowman | 11-24-1971 |
| 219-09-9999 | Oscar | Ward | 02-12-1998 |
When looking for matching supporting elements in a protected file, your EDM SIT checks for each supporting element (both individually and in combination) once the primary element is detected.
For instance, say that the first social security number is detected. The exact data match functionality next looks for combinations of supporting elements across all the columns in your source table:
- Isaiah
- Langer
- 05-05-1960
- Isaiah Langer
- Isaiah 05-05-1960
- Langer 05-05-1960
- Isaiah Langer 05-05-1960
Multi-token matching
Multi-token matching is designed to be used when your corroborative evidence field contains multi-token values but matching such values to a SIT isn't easily accomplished. For instance, when you have an Address field containing values like 1 Microsoft Way, Redmond, WA or 123 Main Street, New York, NY.
This feature allows EDM to compare the hashes of consecutive words in the content with the hashes of the multi-token fields in your data source. If they're identical, EDM produces a match. This way, EDM can detect multi-token fields such as names, addresses, medical conditions, or any other corroborative evidence fields that might contain more than one word, as long as they're marked as multi-token in your EDM schema.
For example, if you select multi-token matching as the match option, you get two additional benefits:
- Your policies will detect content that matches multiple fields across the columns in your source table.
- Your source table can include fields with string values that consist of a preconfigured number of words. The following table shows a sample source table:
| SSN | Name | Street Address |
|---|---|---|
| 987-65-4320 | Isaiah Langer | 1432 Lincoln Road |
| 078-05-1120 | Ana Bowman | 8250 First Street |
| 219-09-9999 | Oscar Ward | 424 205th Avenue |
With multi-token matching, the Name and Street Address fields are matched both as independent supporting element strings and in combination as individual fields. So, when matched as multi-token strings as supporting elements for Social Security number 987-65-4320, the matches are:
- Isaiah Langer
- 1432 Lincoln Road
When matched in combination, the match is like this:
- Isaiah Langer + 1432 Lincoln Road
Multi-token matching is also supported for double-byte character sets, which generally don't use spaces to separate words.
Services that EDM supports
| Service | Locations |
|---|---|
| Microsoft Purview Data Loss Prevention | - SharePoint - OneDrive - Teams Chat - Exchange Online - Devices |
| Microsoft Defender for Cloud Apps | - SharePoint - OneDrive |
| Auto-labeling (service side) | - SharePoint - OneDrive - Exchange Online |
| Auto-labeling (client side) | - Word - Excel - PowerPoint - Exchange desktop clients |
| Customer Managed Key | - SharePoint - OneDrive - Teams Chat - Exchange Online - Word - Excel - PowerPoint - Exchange desktop clients - Devices |
| eDiscovery | - SharePoint - OneDrive - Teams Chat - Exchange Online - Word - Excel - PowerPoint - Exchange desktop clients |
| Insider Risk Management | - SharePoint - OneDrive - Teams Chat - Exchange Online - Word - Excel - PowerPoint - Exchange desktop clients |