Explore, learn, create, and use data quality rules
Data quality is the measurement of the integrity of data in an organization and is assessed using data quality scores. Scores generated based on the assessment of the data against rules that are defined in Microsoft Purview Unified Catalog.
Data quality rules are essential guidelines that organizations establish to ensure the accuracy, consistency, and completeness of their data. These rules help maintain data integrity and reliability.
Here are some key aspects of data quality rules:
Accuracy - Data should accurately represent real-world entities. Context matters! For example, if you’re storing customer addresses, ensure they match the actual locations.
Completeness - The objective of this rule is to identify the empty, null, or missing data. This rule validates that all values are present (though not necessarily correct).
Conformity - This rule ensures that the data follows data formatting standards such as representation of dates, addresses, and allowed values.
Consistency - This rule checks that different values of the same record are in conformity with a given rule and there are no contradictions. Data consistency ensures that the same information is represented uniformly across different records. For instance, if you have a product catalog, consistent product names and descriptions are crucial.
Timeliness - This rule aims to ensure that the data is accessible in as short a time as possible. It ensures that the data is up to date.
Uniqueness - This rule checks that values aren't duplicated, for example, if there's supposed to be only one record per customer, then there aren't multiple records for the same customer. Each customer, product, or transaction should have a unique identifier.
Data quality life cycle
Creating data quality rules is the sixth step in the data quality lifecycle. Previous steps are:
- Assign users(s) data quality steward permissions in Unified Catalog to use all data quality features.
- Register and scan a data source in your Microsoft Purview Data Map.
- Add your data asset to a data product
- Set up a data source connection to prepare your source for data quality assessment.
- Configure and run data profiling for an asset in your data source.
Required roles
- To create and manage data quality rules, your users must be in the data quality steward role.
- To view existing quality rules, your users must be in the data quality reader role.
View existing data quality rules
From Microsoft Purview Unified Catalog, select the Health Management menu and Data quality submenu.
In the data quality submenu, select a governance domain.
Select a data product.
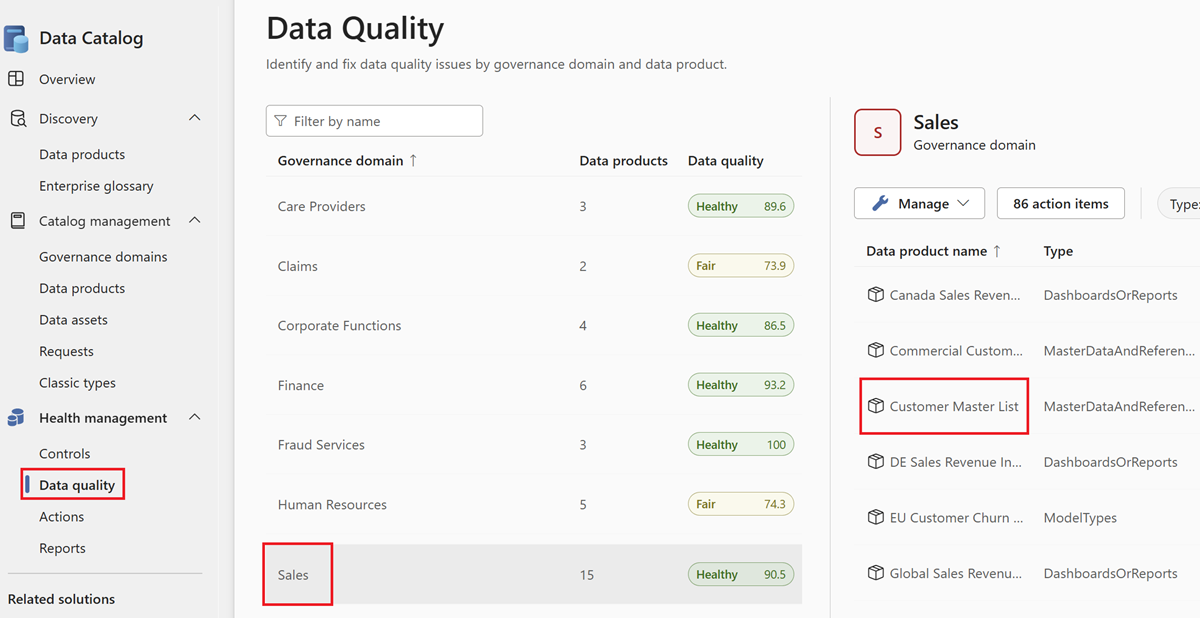
Select a data asset from the asset list of the selected data product.
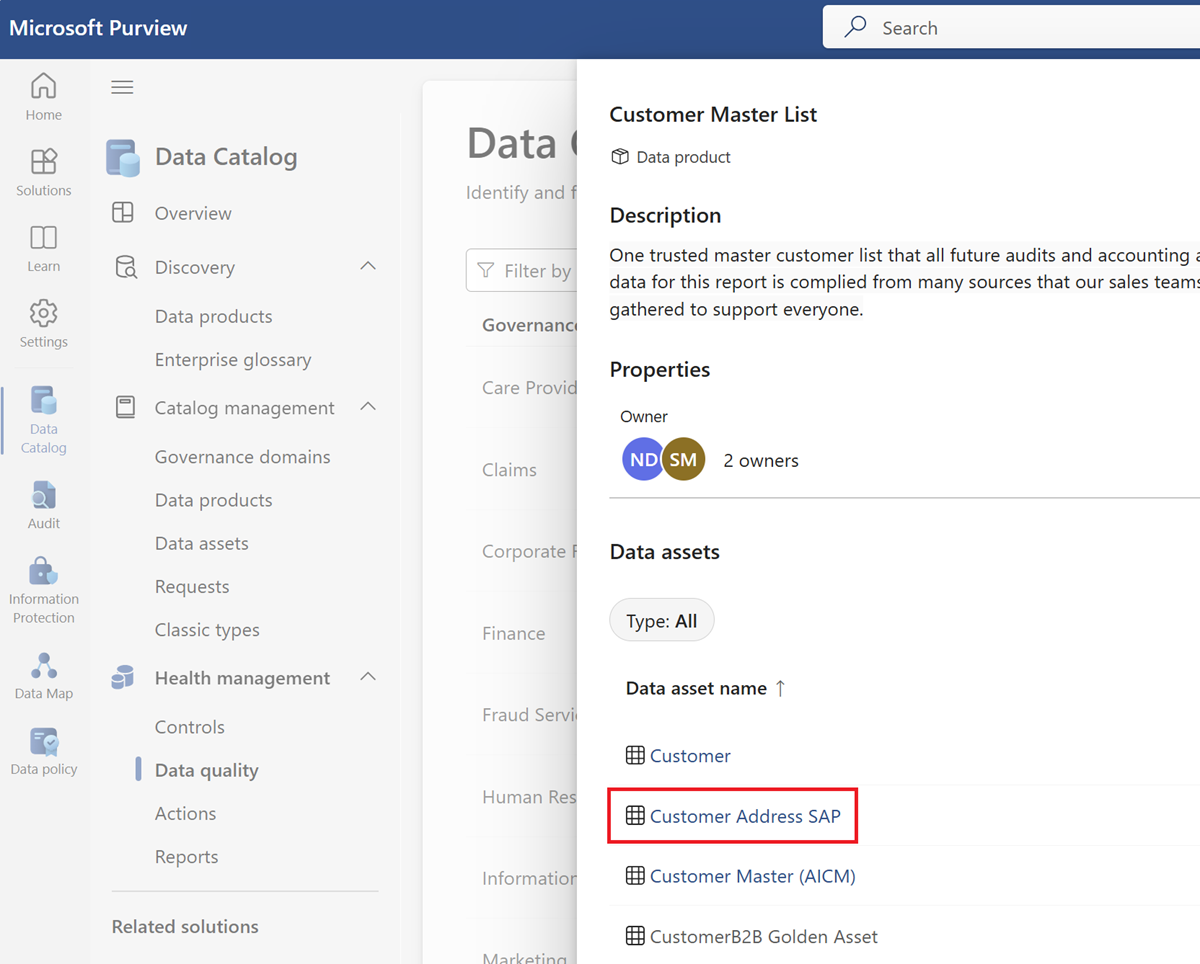
Select the Rules menu tab to see the existing rules applied to the asset.
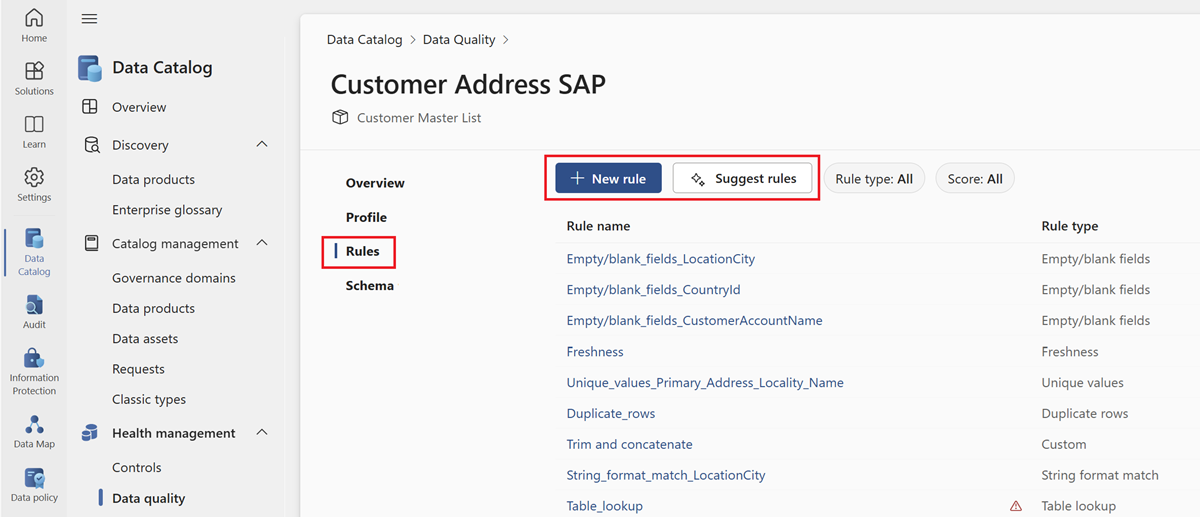
Select a rule to browse the performance history of the applied rule to the selected data asset.
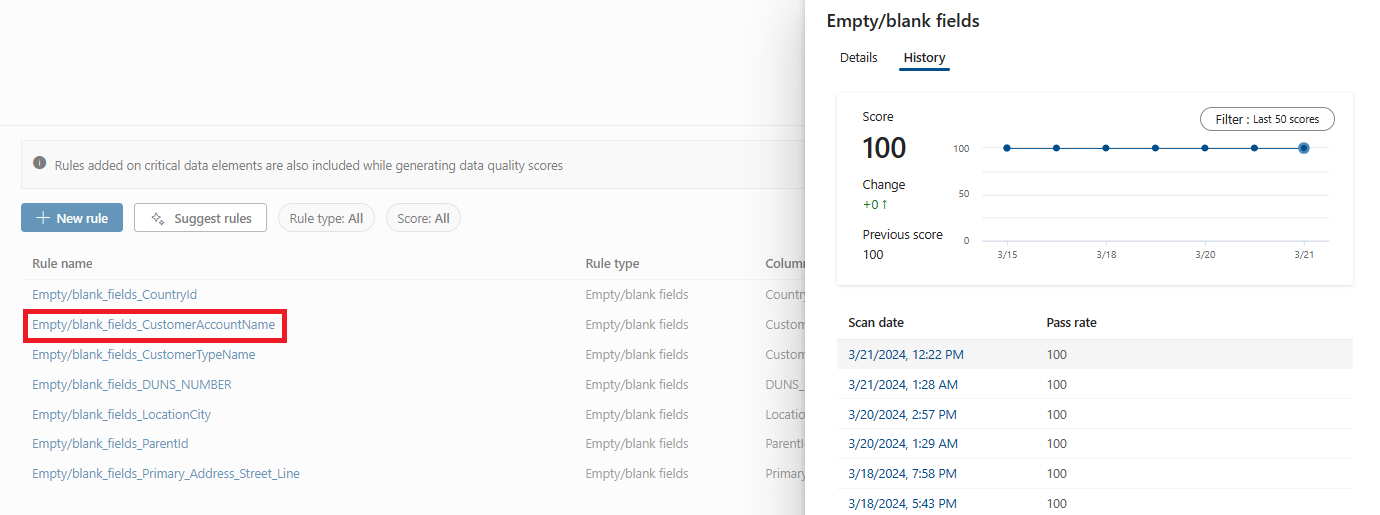




Available data quality rules
Microsoft Purview Data Quality enables configuration of the below rules, these are out of the box rules that offer low-code to no-code way to measure the quality of your data.
| Rule | Definition |
|---|---|
| Freshness | Confirms that all values are up to date. |
| Unique values | Confirms that the values in a column are unique. |
| String format match | Confirms that the values in a column match a specific format or other criteria. |
| Data type match | Confirms that the values in a column match their data type requirements. |
| Duplicate rows | Checks for duplicate rows with the same values across two or more columns. |
| Empty/blank fields | Looks for blank and empty fields in a column where there should be values. |
| Table lookup | Confirms that a value in one table can be found in the specific column of another table. |
| Custom | Create a custom rule with the visual expression builder. |
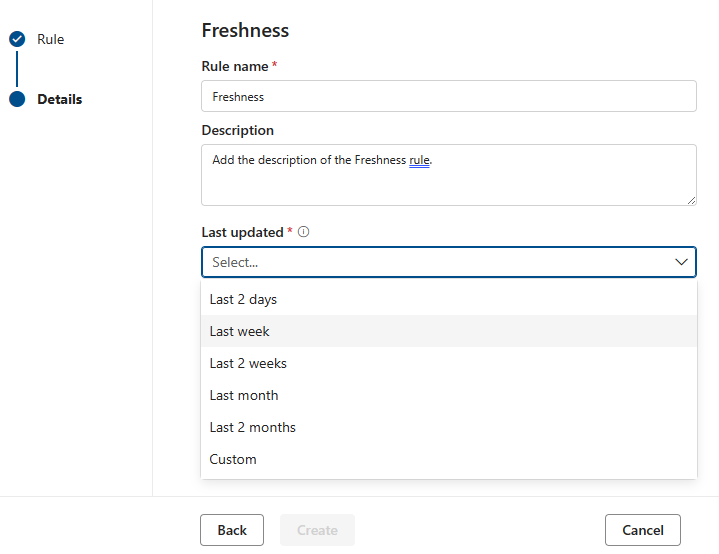
Freshness
The purpose of the freshness rule is to determine if the asset has been updated within the expected time. Microsoft Purview currently supports checking freshness by looking at last modified dates.
Note
Score for the freshness rule is either 100 (it passed) or 0 (it failed).
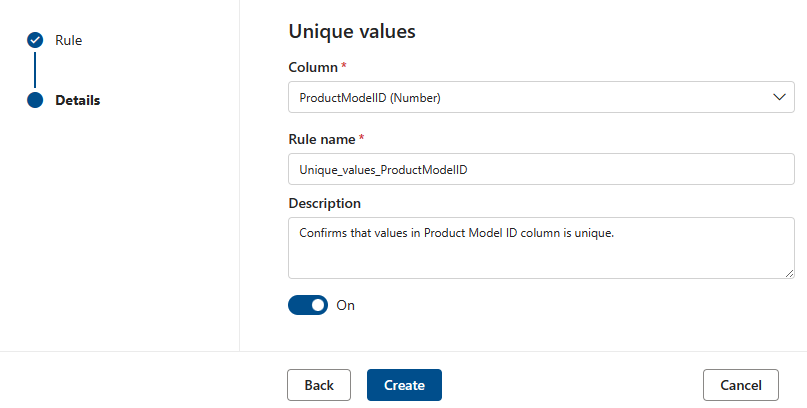
Unique values
The Unique values rule states that all the values in the specified column must be unique. All values that are unique 'pass' and those that don't are treated as fail. If the Empty/blank fields rule isn't defined on the column, then null/empty values will be ignored for the purposes of this rule.
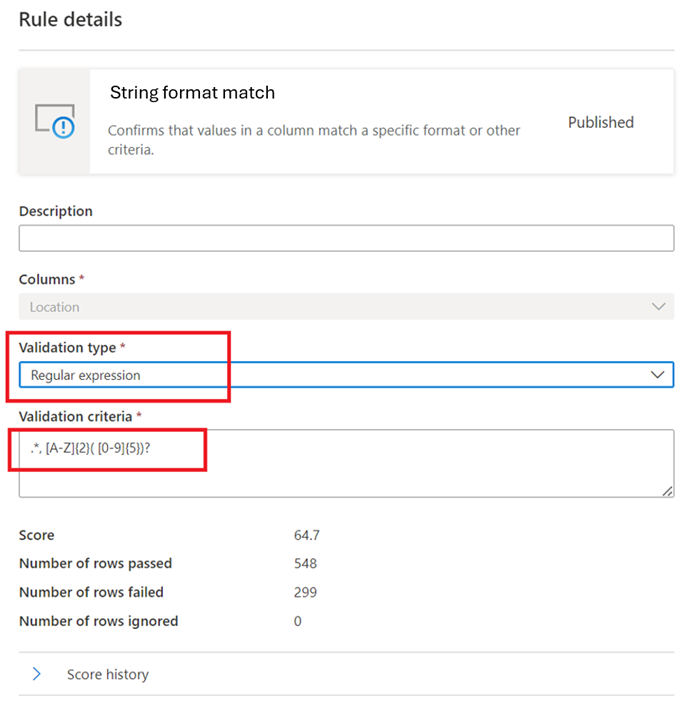
String format match
The Format match rule checks if all the values in the column are valid. If the Empty/blank fields rule isn't defined on a column, then null/empty values will be ignored for the purposes of this rule.
This rule can validate each value in the column using three different approaches:
Enumeration – This is a comma separated list of values. If the value being evaluated can't be compared to one of the listed values then it fails the check. Commas and backslashes can be escaped by using a backslash:
\. Soa \, b, ccontains two values the first isa , band the second isc.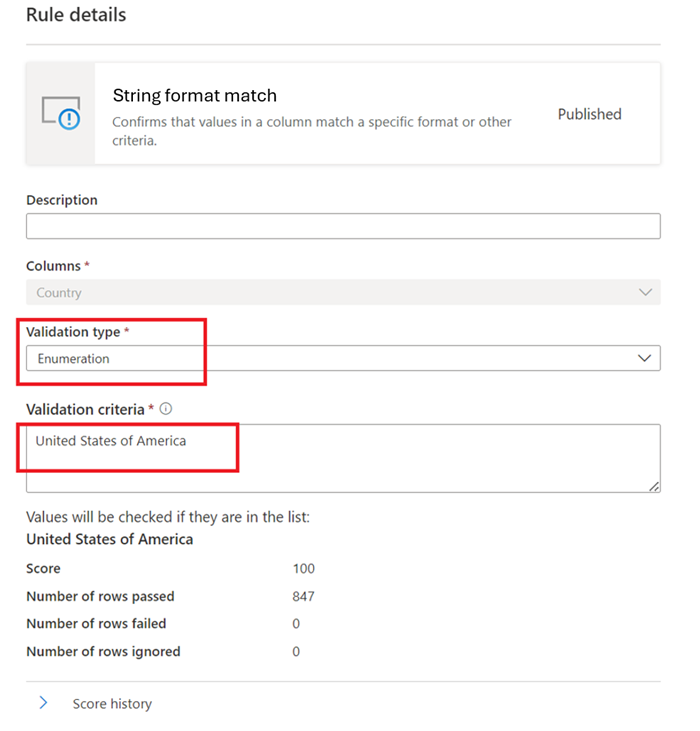
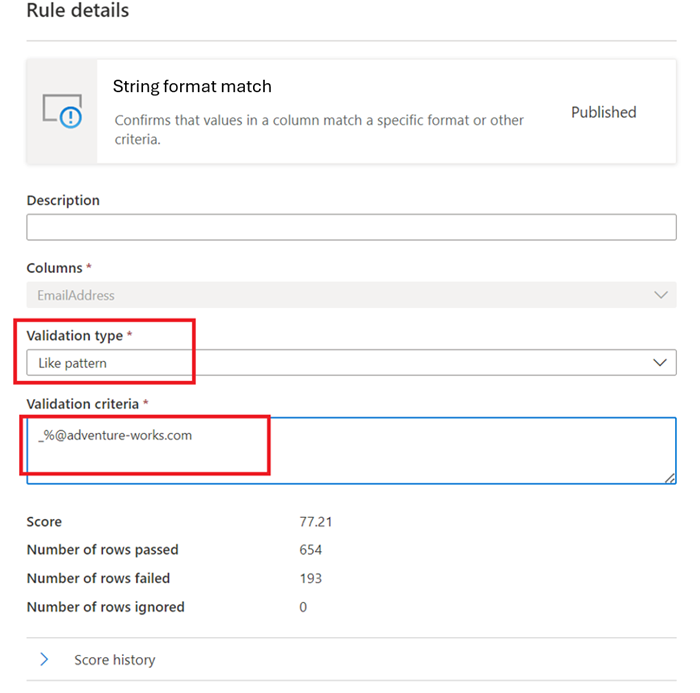
Like Pattern -
like(<string> : string, <pattern match> : string) => boolean
The pattern is a string that is matched literally. The exceptions are the following special symbols: _ matches any one character in the input (similar to . inposixregular expressions) % matches zero or more characters in the input (similar to .* inposixregular expressions). The escape character is ''. If an escape character precedes a special symbol or another escape character, the following character is matched literally. It's invalid to escape any other character.like('icecream', 'ice%') -> true
Regular Expression –
regexMatch(<string> : string, <regex to match> : string) => boolean
Checks if the string matches the given regex pattern. Use<regex>(back quote) to match a string without escaping.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
Data type match
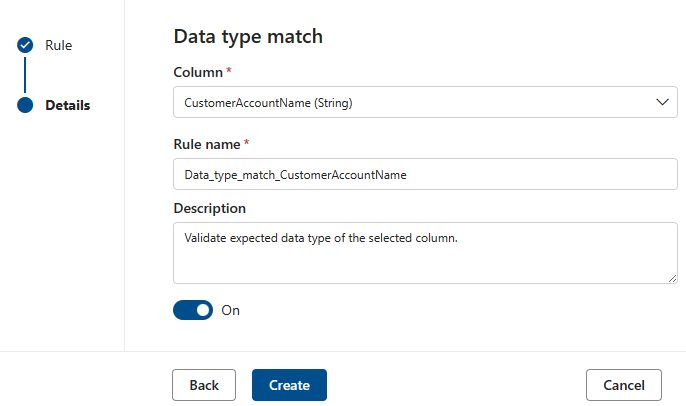
The Data type match rule specifies what data type the associated column is expected to contain. Since the rule engine has to run across many different data sources, it can't use native types like BIGINT or VARCHAR. Instead it has its own type system that it translates the native types into. This rule tells the quality scan engine which of its built-in types the native type should be translated to. The data type system is taken from the Azure Data Flow type system used in Azure Data Factory.
During a quality scan, all, the native types will be tested against the data type match type and if it isn't possible to translate the native type into the data type match type that row will be treated as being in error.
Duplicate rows
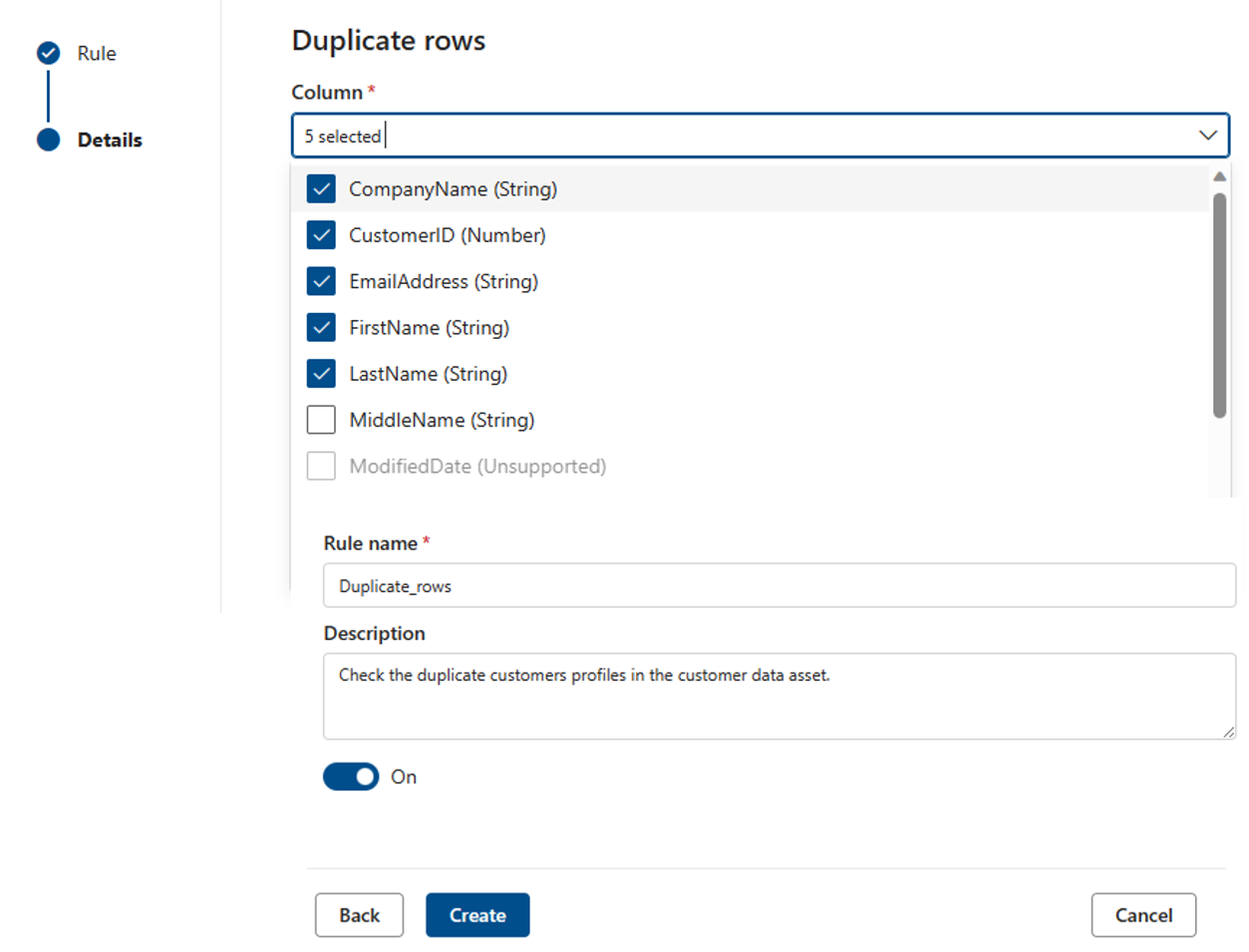
The Duplicate rows rule checks if the combination of the values in the column are unique for every row in the table.
In the example below, the expectation is that the concatenation of _CompanyName, CustomerID, EmailAddress, FirstName, and LastName will produce a value that is unique for all the rows in the table.
Each asset can have zero or one instance of this rule.
Empty/blank fields
The Empty/blank fields rule asserts that the identified columns shouldn't contain any null values and in the specific case of strings, no empty or whitespace only values either. During a quality scan, any value in this column that isn't null will be treated as correct. This rule will affect other rules such as the Unique values or Format match rules. If this rule isn't defined on a column, then those rules when run on that column will automatically ignore any null values. If this rule is defined on a column, then those rules will examine null/empty values on that column and consider them for score purposes.
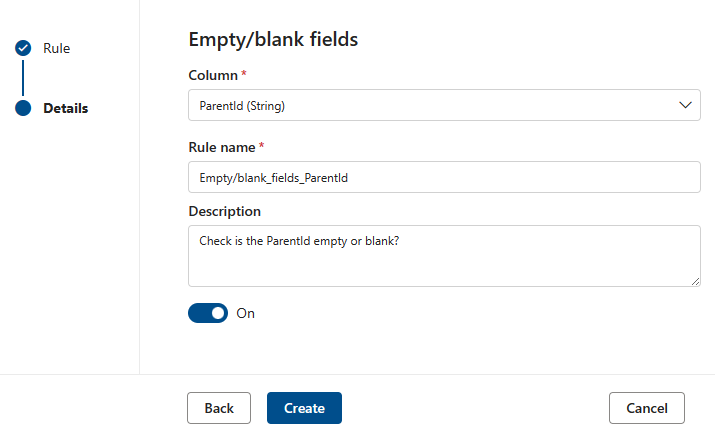
Table lookup
The Table Lookup rule will examine each value in the column that the rule is defined on and compare it to a reference table. For example, primary table has a column called "location" that contains cities, states and zip codes in the form "city, state zip". There's a reference table, called citystate, that contains all the legal combinations of cities, states and zip codes supported in the United States. The goal is to compare all the locations in the current column against that reference list to make sure that only legal combinations are being used.
To do this, we first type in the "citystatezip's name into the search assets dialog. We then select the desired asset and then the column we want to compare against.
Custom rules
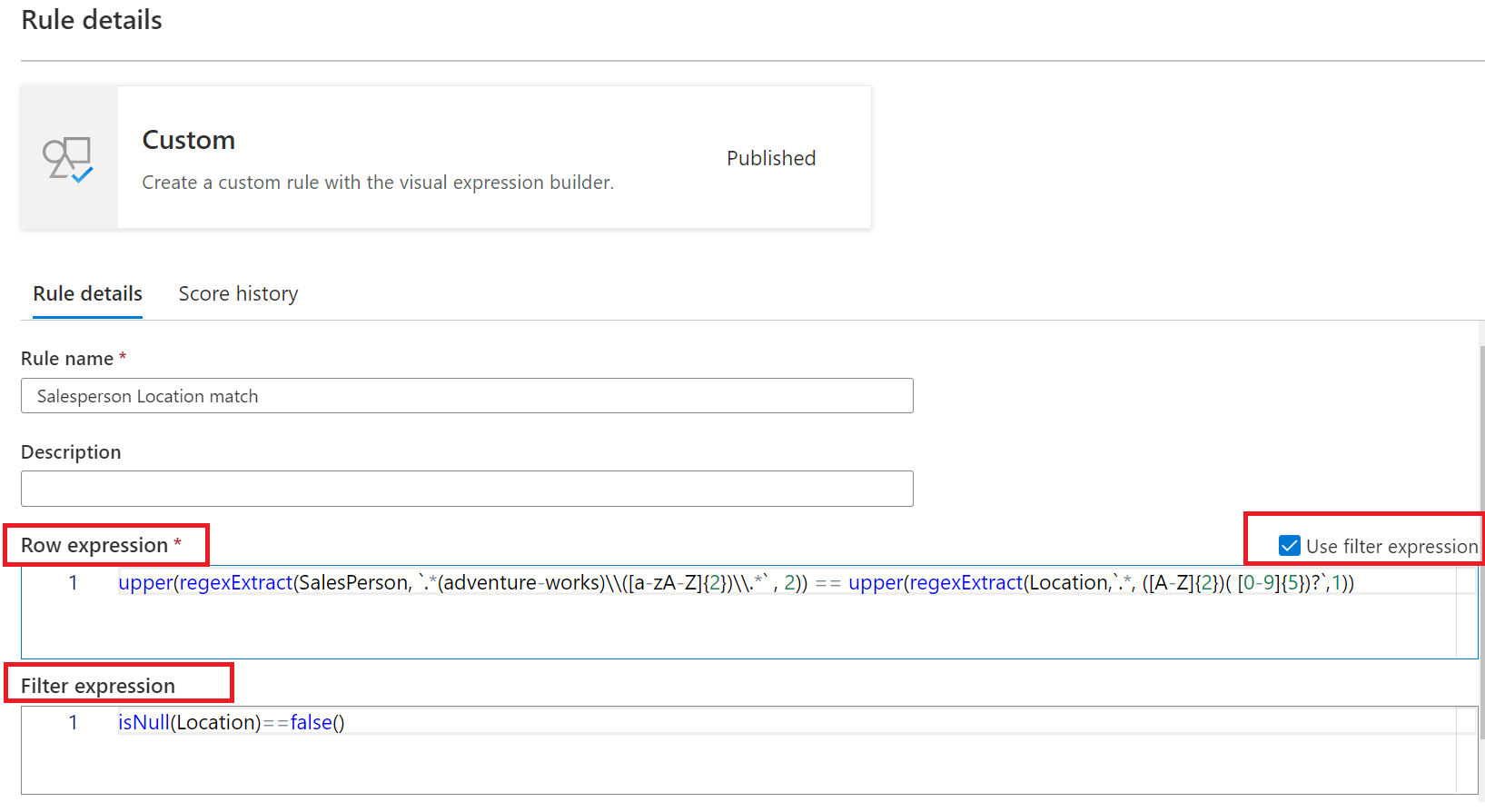
The Custom rule enables specifying rules that try to validate rows based on one or more values in that row. The custom rule has two parts:
- The first part is the filter expression which is optional and is activated by selecting the check box by "Use filter expression". This is an expression that returns a Boolean value. The filter expression will be applied to a row and if it returns true, then that row will be considered for the rule. If the filter expression returns false for that row, then it means that row will be ignored for the purposes of this rule. The default behavior of the filter expression is to pass all rows - so if no filter expression is specified, and one isn't required, then all rows will be considered.
- The second part is the row expression. This is a Boolean expression applied to each row that gets approved by the filter expression. If this expression returns true then the row passes, if false, then it's marked as a fail.
Examples of custom rules
| Scenario | Row expression |
|---|---|
| Validate if state_id is equal to California, and aba_Routing_Number matches a certain regex pattern, and date of birth falls in a certain range | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Verify if VendorID is equal to 124 | {VendorID}=='124' |
| Check if fare_amount is equal or greater than 100 | {fare_amount} >= "100" |
| Validate if fare_amount is greater than 100 and tolls_amount isn't equal to 100 | {fare_amount} >= "100" || {tolls_amount} != "400" |
| Check if Rating is less than 5 | Rating < 5 |
| Verify if number of digits in year is 4 | length(toString(year)) == 4 |
| Compare two columns bbToLoanRatio and bankBalance to check if their values are equal | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Check if trimmed and concatenated number of characters in firstName, lastName, LoanID, uuid is greater than 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Verify if aba_Routing_Number matches certain regex pattern, and initial transaction date is greater than 2022-11-12, and Disallow-Listed is false, and average bankBalance is greater than 50000, and state_id is equal to 'Massachuse', 'Tennessee', 'North Dakota' or 'Albama' | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| Validate if aba_Routing_Number matches certain regex pattern, and dateOfBirth is between 1968-12-13 and 2020-12-13 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Check if number of unique values in aba_Routing_Number is equal to 1,000,000, and number of unique values in EMAIL_ADDR is equal to 1,000,000 | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
Both the filter expression and row expression are defined using the Azure Data Factory expression language as introduced here with the language defined here. Note, however that not all the functions defined for the generic ADF expression language are available. The full list of available functions are in the Functions list available in the expression dialog. The following functions defined in here aren't supported: isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, cached lookup, and Window functions.
Note
<regex> (backquote) can be used in regular expressions included in custom rules to match string without escaping special characters. The regular expression language is based on Java and works as given here. This page identifies the characters that need to be escaped.
AI assisted autogenerated rules
AI-assisted automated rule generation for data quality measurement involves using artificial intelligence (AI) techniques to automatically create rules for assessing and improving the quality of data. Auto generated rules are content specific. Most of the common rules will be generated automatically so that users don't need to put that much effort to create custom rules.
To browse and apply auto generated rules:
- Select Suggest rules on the rules page.
- Browse the list suggested rules.

- Select rules from the suggested rule list to apply to the data asset.

Next steps
- Configure and run a data quality scan on a data product to assess the quality of all supported assets in the data product.
- Review your scan results to evaluate your data product's current data quality.