Εκτέλεση OCR σε πολύγλωσσα έγγραφα
Με την οπτική αναγνώριση χαρακτήρων (OCR) μπορείτε να εντοπίσετε και να εξαγάγετε κείμενο από εικόνες ή από την οθόνη.
Μολονότι τα περισσότερα σενάρια απαιτούν το χειρισμό κειμένου σε μια συγκεκριμένη γλώσσα, υπάρχουν περιπτώσεις στις οποίες οι προελεύσεις είναι πολύγλωσσες.
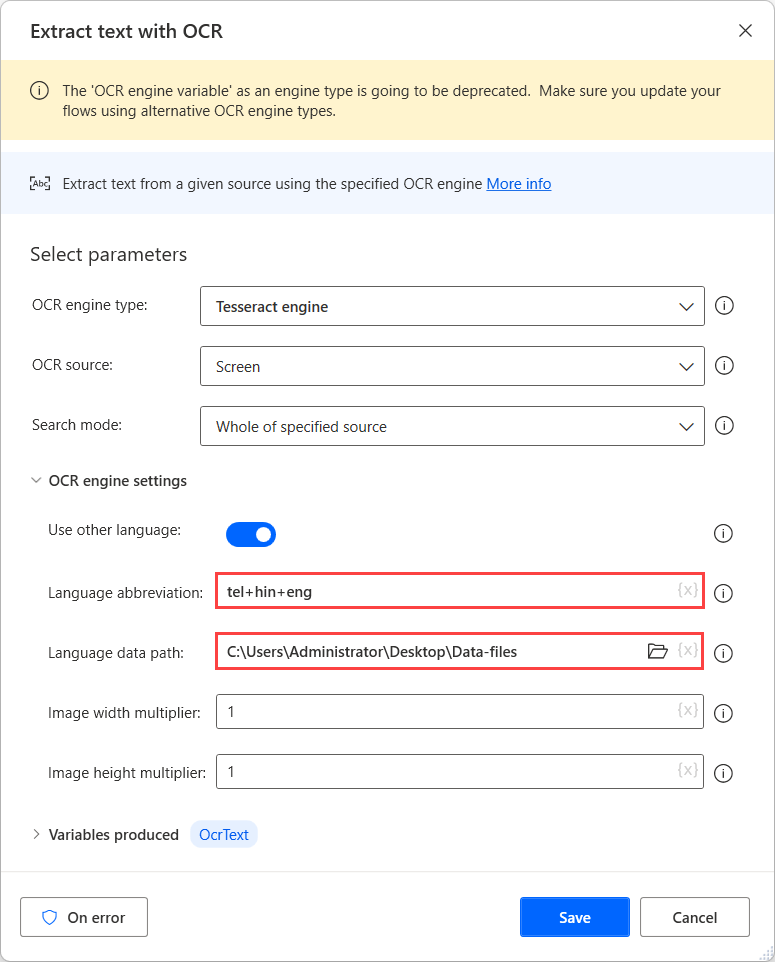
Για να εκτελέσετε OCR σε αυτές τις προελεύσεις, χρησιμοποιήστε μια μηχανή Tesseract στην αντίστοιχη ενέργεια OCR και ενεργοποιήστε την επιλογή Χρήση άλλων γλωσσών στις ρυθμίσεις της μηχανής.
Όταν ενεργοποιηθεί η επιλογή Χρήση άλλων γλωσσών, η ενέργεια εμφανίζει δύο πρόσθετες ρυθμίσεις: τη συντομογραφία Γλώσσας και τα πεδία Διαδρομή δεδομένων γλώσσας.
Το πεδίο συντομογραφία γλώσσας υποδεικνύει στη μηχανή τη γλώσσα που θα αναζητήσετε στη διάρκεια της επιλογής OCR. Το πεδίο διαδρομής δεδομένων γλώσσας περιέχει τα αρχεία δεδομένων γλώσσας (.traineddata) που χρησιμοποιούνται για την εκπαίδευση του μηχανής OCR.
Αφού κάνετε λήψη των αρχείων δεδομένων για τις απαραίτητες γλώσσες, μετακινήστε τα σε έναν κοινό φάκελο ώστε να είναι διαθέσιμα στην ίδια διαδρομή.
Στη συνέχεια, επιλέξτε το φάκελο που δημιουργήθηκε στο πεδίο Διαδρομή δεδομένων γλώσσας και συμπληρώστε τους αντίστοιχους κωδικούς γλώσσας στο πεδίο συντομογραφίας γλώσσας. Για να διαχωρίσετε τους κωδικούς γλώσσας, χρησιμοποιήστε το χαρακτήρα συν (+).
Σημείωμα
Μπορείτε να βρείτε όλους τους διαθέσιμους κωδικούς γλώσσας στην προέλευση των αρχείων δεδομένων γλώσσας. Στο παρακάτω παράδειγμα, οι κωδικοί που χρησιμοποιούνται αντιπροσωπεύουν το Τελούγκου, τα Χίντι και τα Αγγλικά.