Ενοποίηση του OneLake με το Azure Databricks
Αυτό το σενάριο δείχνει πώς μπορείτε να συνδεθείτε στο OneLake μέσω του Azure Databricks. Μετά την ολοκλήρωση αυτής της εκμάθησης, θα μπορείτε να διαβάσετε και να γράψετε σε μια λίμνη Microsoft Fabric από τον χώρο εργασίας σας Azure Databricks.
Προαπαιτούμενα στοιχεία
Πριν συνδεθείτε, πρέπει να έχετε:
- Ένας χώρος εργασίας Fabric και ένα lakehouse.
- Ένας premium χώρος εργασίας Azure Databricks. Μόνο οι premium χώροι εργασίας Azure Databricks υποστηρίζουν διαβίβαση διαπιστευτηρίων Microsoft Entra, την οποία χρειάζεστε για αυτό το σενάριο.
Ρύθμιση του χώρου εργασίας σας Databricks
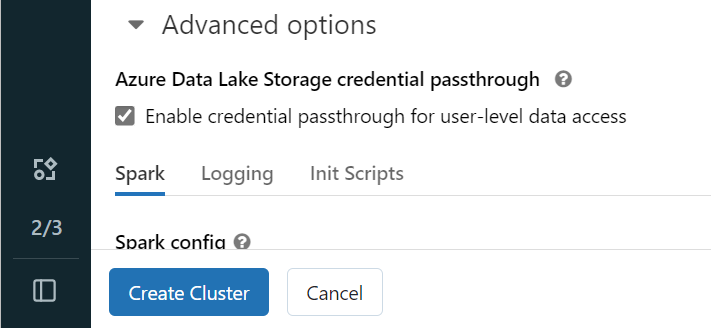
Ανοίξτε τον χώρο εργασίας σας Azure Databricks και επιλέξτε Δημιουργία>συμπλέγματος.
Για να πραγματοποιήσετε έλεγχο ταυτότητας στο OneLake με την ταυτότητά σας Microsoft Entra, πρέπει να ενεργοποιήσετε τη διαβίβαση διαπιστευτηρίων Azure Data Lake Υπηρεσία αποθήκευσης (ADLS) στο σύμπλεγμα στις Επιλογές για προχωρημένους.
Σημείωμα
Μπορείτε επίσης να συνδέσετε το Databricks στο OneLake χρησιμοποιώντας μια κύρια υπηρεσία. Για περισσότερες πληροφορίες σχετικά με τον έλεγχο ταυτότητας του Azure Databricks με χρήση μιας κύριας υπηρεσίας, ανατρέξτε στο θέμα Διαχείριση οντοτήτων υπηρεσίας.
Δημιουργήστε το σύμπλεγμα με τις παραμέτρους που προτιμάτε. Για περισσότερες πληροφορίες σχετικά με τη δημιουργία ενός συμπλέγματος Databricks, ανατρέξτε στο θέμα Ρύθμιση παραμέτρων συμπλεγμάτων - Azure Databricks.
Ανοίξτε ένα σημειωματάριο και συνδέστε το στο σύμπλεγμα που μόλις δημιουργήσατε.
Σύνταξη του σημειωματάριού σας
Μεταβείτε στο lakehouse Fabric και αντιγράψτε τη διαδρομή Azure Blob Filesystem (ABFS) στο lakehouse σας. Μπορείτε να τη βρείτε στο τμήμα παραθύρου Ιδιότητες .
Σημείωμα
Το Azure Databricks υποστηρίζει μόνο το πρόγραμμα οδήγησης Azure Blob Filesystem (ABFS) κατά την ανάγνωση και εγγραφή στα ADLS Gen2 και OneLake:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Αποθηκεύστε τη διαδρομή προς το lakehouse στο σημειωματάριό σας Databricks. Αυτό το lakehouse είναι το σημείο όπου γράφετε τα επεξεργασμένα δεδομένα σας αργότερα:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Φορτώστε δεδομένα από ένα δημόσιο σύνολο δεδομένων Databricks σε ένα πλαίσιο δεδομένων. Μπορείτε, επίσης, να διαβάσετε ένα αρχείο από κάποιο άλλο σημείο του Fabric ή να επιλέξετε ένα αρχείο από έναν άλλο λογαριασμό ADLS Gen2 που έχετε ήδη στην κατοχή σας.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Φιλτράρετε, μετασχηματίστε ή προετοιμασία των δεδομένων σας. Για αυτό το σενάριο, μπορείτε να περιορίσετε το σύνολο δεδομένων σας για ταχύτερη φόρτωση, να συνδεθείτε με άλλα σύνολα δεδομένων ή να φιλτράρετε προς τα κάτω για συγκεκριμένα αποτελέσματα.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Συντάξετε το φιλτραρισμένο πλαίσιο δεδομένων σας στη λίμνη Fabric χρησιμοποιώντας τη διαδρομή OneLake.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Ελέγξτε ότι τα δεδομένα σας γράφτηκαν με επιτυχία διαβάζοντας το αρχείο σας που μόλις φορτώθηκε.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Συγχαρητήρια. Μπορείτε πλέον να διαβάζετε και να γράφετε δεδομένα στο Fabric χρησιμοποιώντας το Azure Databricks.