Εκπαιδευτικό βοήθημα, Μέρος 2: Εξερεύνηση και απεικόνιση δεδομένων με χρήση σημειωματάριων Microsoft Fabric
Σε αυτή την εκμάθηση, θα μάθετε πώς να διεξάγετε διερευνητική ανάλυση δεδομένων (EDA) για να εξετάσετε και να διερευνήσετε τα δεδομένα, συνοψίζοντας παράλληλα τα βασικά χαρακτηριστικά τους μέσω της χρήσης τεχνικών απεικόνισης δεδομένων.
Θα χρησιμοποιήσετε seaborn, μια βιβλιοθήκη απεικόνισης δεδομένων Python που παρέχει μια διασύνδεση υψηλού επιπέδου για τη δημιουργία απεικονίσεων σε πλαίσια δεδομένων και πίνακες. Για περισσότερες πληροφορίες σχετικά με seaborn, ανατρέξτε στο θέμα Seaborn: Statistical Data Visualization.
Θα χρησιμοποιήσετε επίσης το Data Wrangler, ένα εργαλείο που βασίζεται σε σημειωματάριο, το οποίο σας παρέχει μια συναρπαστική εμπειρία για τη διεξαγωγή διερευνητικής ανάλυσης και εκκαθάρισης δεδομένων.
Τα κύρια βήματα σε αυτή την εκμάθηση είναι τα εξής:
- Διαβάστε τα δεδομένα που είναι αποθηκευμένα από έναν πίνακα δέλτα στο lakehouse.
- Μετατρέψτε ένα Spark DataFrame σε Pandas DataFrame, το οποίο υποστηρίζουν οι βιβλιοθήκες απεικόνισης python.
- Χρησιμοποιήστε το Data Wrangler για την εκτέλεση αρχικής εκκαθάρισης και μετασχηματισμού δεδομένων.
- Εκτελέστε διερευνητική ανάλυση δεδομένων χρησιμοποιώντας
seaborn.
Προϋποθέσεις
Λάβετε μια συνδρομής Microsoft Fabric . Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση microsoft Fabric.
Εισέλθετε για να το Microsoft Fabric.
Χρησιμοποιήστε την εναλλαγή εμπειρίας στην κάτω αριστερή πλευρά της αρχικής σελίδας σας για να μεταβείτε σε Fabric.

Αυτό είναι το μέρος 2 από το 5 της σειράς εκμάθησης. Για να ολοκληρώσετε αυτή την εκμάθηση, ολοκληρώστε πρώτα τα εξής:
Παρακολούθηση στο σημειωματάριο
2-explore-cleanse-data.ipynb είναι το σημειωματάριο που συνοδεύει αυτό το πρόγραμμα εκμάθησης.
Για να ανοίξετε το σημειωματάριο που συνοδεύει αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων, να εισαγάγετε το σημειωματάριο στον χώρο εργασίας σας.
Εάν προτιμάτε να αντιγράψετε και να επικολλήσετε τον κώδικα από αυτήν τη σελίδα, μπορείτε να δημιουργήσετε ένα νέο σημειωματάριο.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Σημαντικός
Επισυνάψτε το ίδιο lakehouse που χρησιμοποιήσατε στο Μέρος 1.
Ανάγνωση ανεπεξέργαστων δεδομένων από το lakehouse
Διαβάστε ανεπεξέργαστα δεδομένα από το τμήμα
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Δημιουργία dataFrame pandas από το σύνολο δεδομένων
Μετατρέψτε το spark DataFrame σε pandas DataFrame για ευκολότερη επεξεργασία και απεικόνιση.
df = df.toPandas()
Εμφάνιση ανεπεξέργαστων δεδομένων
Εξερευνήστε τα ανεπεξέργαστα δεδομένα με display, κάντε ορισμένα βασικά στατιστικά στοιχεία και εμφανίστε προβολές γραφήματος. Σημειώστε ότι πρέπει πρώτα να εισαγάγετε τις απαιτούμενες βιβλιοθήκες, όπως οι Numpy, Pnadas, Seabornκαι Matplotlib για την ανάλυση δεδομένων και την απεικόνιση.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Χρήση του Data Wrangler για την εκτέλεση αρχικής εκκαθάρισης δεδομένων
Για να εξερευνήσετε και να μετασχηματίστε οποιαδήποτε πλαίσια δεδομένων pandas στο σημειωματάριό σας, εκκινήστε το Data Wrangler απευθείας από το σημειωματάριο.
Σημείωση
Δεν είναι δυνατό το άνοιγμα του Wrangler δεδομένων, ενώ ο πυρήνας σημειωματάριου είναι απασχολημένος. Η εκτέλεση του κελιού πρέπει να ολοκληρωθεί πριν την εκκίνηση του Data Wrangler.
- Στην κορδέλα σημειωματάριου καρτέλα Δεδομένα, επιλέξτε Εκκίνηση του data Wrangler. Θα δείτε μια λίστα με τα ενεργοποιημένα dataFrames pandas που είναι διαθέσιμα για επεξεργασία.
- Επιλέξτε το DataFrame που θέλετε να ανοίξετε στο Data Wrangler. Δεδομένου ότι αυτό το σημειωματάριο περιέχει μόνο ένα DataFrame,
df, επιλέξτεdf.
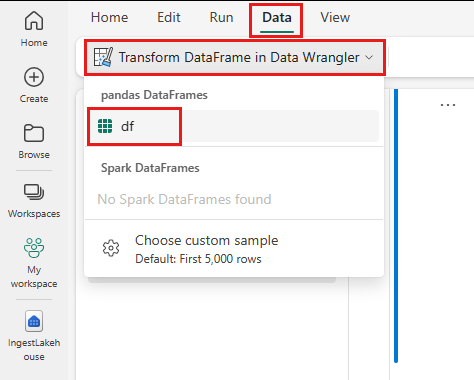
Το Data Wrangler εκκινεί και δημιουργεί μια περιγραφική επισκόπηση των δεδομένων σας. Ο πίνακας στο μέσον εμφανίζει κάθε στήλη δεδομένων. Ο πίνακας

Κάθε λειτουργία που κάνετε μπορεί να εφαρμοστεί σε ένα θέμα κλικ, την ενημέρωση της εμφάνισης των δεδομένων σε πραγματικό χρόνο και τη δημιουργία κώδικα που μπορείτε να αποθηκεύσετε ξανά στο σημειωματάριό σας ως λειτουργία που μπορεί να επαναχρησιμοποιηθεί.
Η υπόλοιπη ενότητα σάς καθοδηγεί στα βήματα για την εκτέλεση εκκαθάρισης δεδομένων με το Data Wrangler.
Κατάργηση διπλότυπων γραμμών
Στον αριστερό πίνακα υπάρχει μια λίστα λειτουργιών (όπως Εύρεση και αντικατάσταση, Μορφοποίηση, Τύποι, Αριθμητικοί) που μπορείτε να εκτελέσετε στο σύνολο δεδομένων.
Αναπτύξτε Εύρεση και αντικαταστήστε και επιλέξτε Απόθεση διπλότυπων γραμμών.
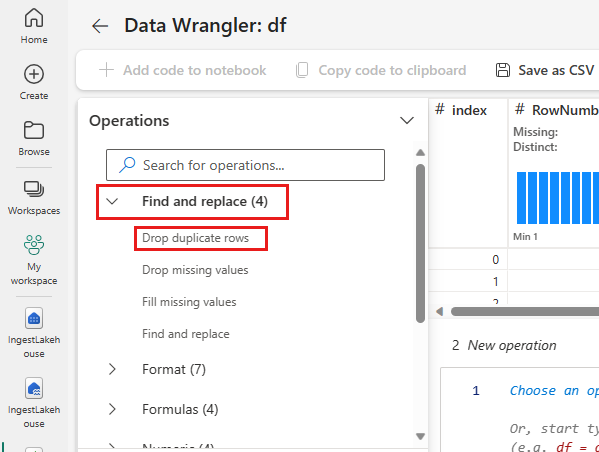
Εμφανίζεται ένας πίνακας για να επιλέξετε τη λίστα των στηλών που θέλετε να συγκρίνετε για να ορίσετε μια διπλότυπη γραμμή. Επιλέξτε RowNumber και CustomerId.
Στον μεσαίο πίνακα υπάρχει μια προεπισκόπηση των αποτελεσμάτων αυτής της λειτουργίας. Στην προεπισκόπηση βρίσκεται ο κώδικας για την εκτέλεση της λειτουργίας. Σε αυτή την περίπτωση, τα δεδομένα φαίνεται να είναι αμετάβλητα. Ωστόσο, δεδομένου ότι εξετάζετε μια περικομημένη προβολή, είναι καλή ιδέα να εφαρμόσετε ακόμα τη λειτουργία.
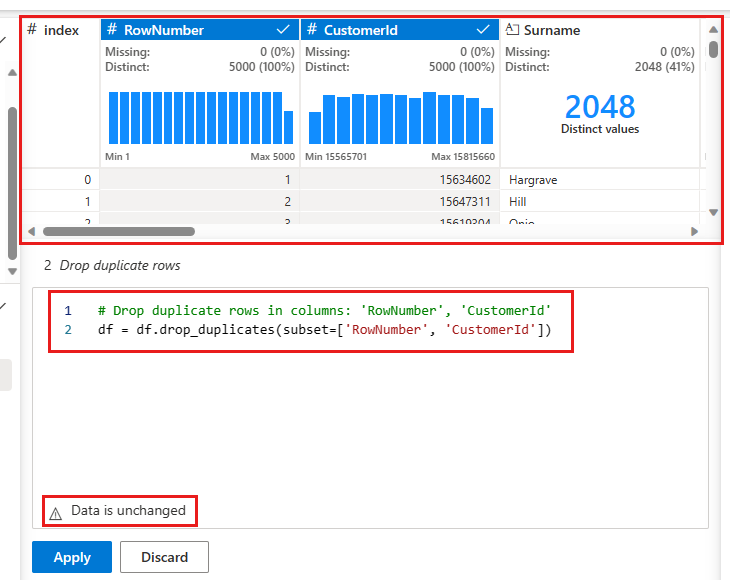
Επιλέξτε Εφαρμογή (είτε στο πλάι είτε στο κάτω μέρος) για να μεταβείτε στο επόμενο βήμα.

Απόθεση γραμμών με δεδομένα που απουσίες
Χρησιμοποιήστε το Data Wrangler για να αποθέσετε γραμμές με δεδομένα που απουσίες σε όλες τις στήλες.
Επιλέξτε απουσιάζει τιμές από Εύρεση και αντικαταστήστε.
Επιλέξτε Επιλογή όλων των από τις στήλες Target.
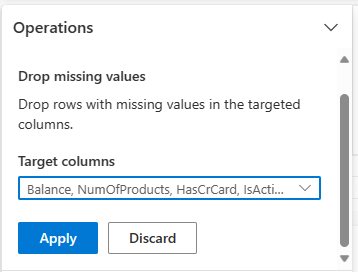
Επιλέξτε Εφαρμογή για να προχωρήσετε στο επόμενο βήμα.

Απόθεση στηλών
Χρησιμοποιήστε το Data Wrangler για να αποθέσετε στήλες που δεν χρειάζεστε.
Αναπτύξτε σχήματος και επιλέξτε Στήλες απόθεσης.
Επιλέξτε πεδίο RowNumber, CustomerId, Surname. Αυτές οι στήλες εμφανίζονται με κόκκινο χρώμα στην προεπισκόπηση, για να δείξουν ότι έχουν αλλάξει από τον κώδικα (σε αυτή την περίπτωση, απορρίπτονται.)
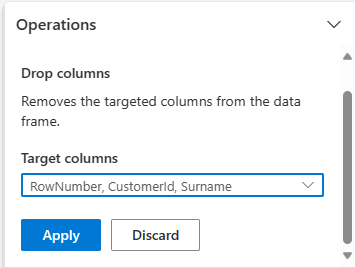
Επιλέξτε Εφαρμογή για να προχωρήσετε στο επόμενο βήμα.

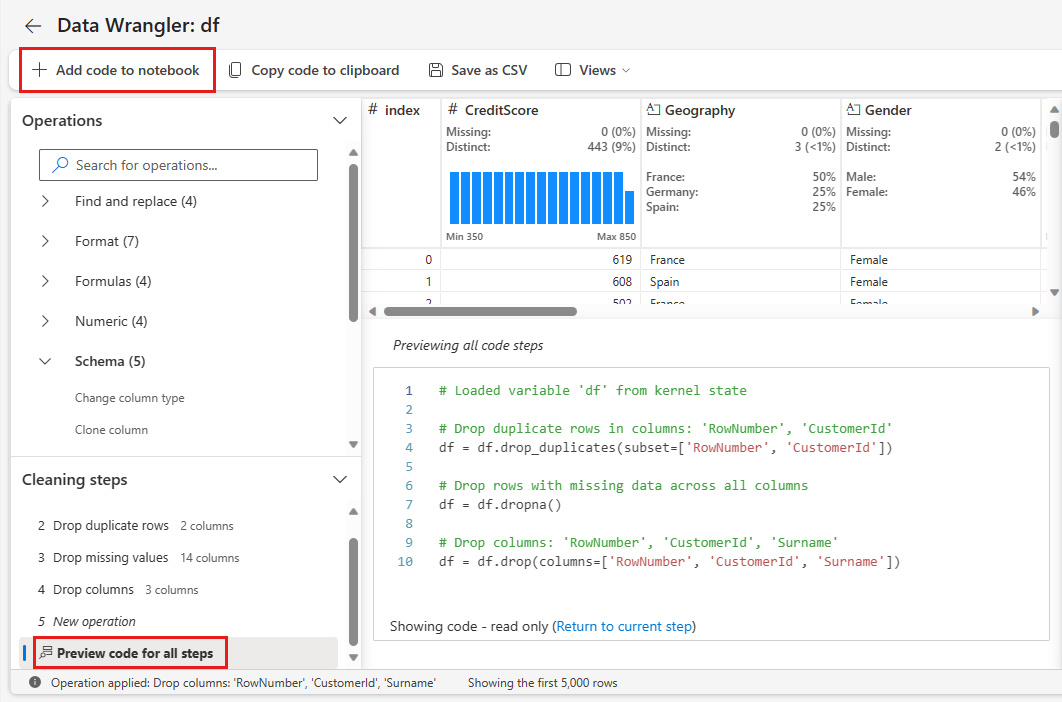
Προσθήκη κώδικα στο σημειωματάριο
Κάθε φορά που επιλέγετε Εφαρμογή, δημιουργείται ένα νέο βήμα στα Βήματα καθαρισμού πίνακα κάτω αριστερά. Στο κάτω μέρος του πίνακα, επιλέξτε Κωδικός προεπισκόπησης για όλα τα βήματα να προβάλετε έναν συνδυασμό όλων των ξεχωριστών βημάτων.
Επιλέξτε Προσθήκη κώδικα στο σημειωματάριο στην επάνω αριστερή γωνία για να κλείσετε το Data Wrangler και να προσθέσετε αυτόματα τον κώδικα. Το Προσθήκη κώδικα στο σημειωματάριο ενσωματώνει τον κώδικα σε μια συνάρτηση και, στη συνέχεια, καλεί τη συνάρτηση.
Φιλοδώρημα
Ο κώδικας που δημιουργείται από το Data Wrangler δεν θα εφαρμοστεί μέχρι να εκτελέσετε με μη αυτόματο τρόπο το νέο κελί.
Εάν δεν χρησιμοποιήσατε τη δυνατότητα Data Wrangler, μπορείτε να χρησιμοποιήσετε αυτό το επόμενο κελί κώδικα.
Αυτός ο κώδικας είναι παρόμοιος με τον κώδικα που παράγεται από τη Data Wrangler, αλλά προσθέτει το όρισμα inplace=True σε καθένα από τα βήματα που δημιουργούνται. Ορίζοντας inplace=True, τα pandas θα αντικαταστήσουν το αρχικό DataFrame αντί να παράγουν ένα νέο DataFrame ως έξοδο.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Εξερεύνηση των δεδομένων
Εμφανίστε ορισμένες συνόψεις και απεικονίσεις των καθαρισμένων δεδομένων.
Προσδιορισμός κατηγορικών, αριθμητικών και χαρακτηριστικών προορισμού
Χρησιμοποιήστε αυτόν τον κώδικα για να προσδιορίσετε τα χαρακτηριστικά κατηγορίας, αριθμών και προορισμού.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Η σύνοψη πέντε αριθμών
Εμφανίστε τη σύνοψη πέντε αριθμών (την ελάχιστη βαθμολογία, το πρώτο τεταρτημόριο, τη διάμεσο, το τρίτο τεταρτημόριο, τη μέγιστη βαθμολογία) για τα αριθμητικά χαρακτηριστικά, χρησιμοποιώντας γραφήματα πλαισίων.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
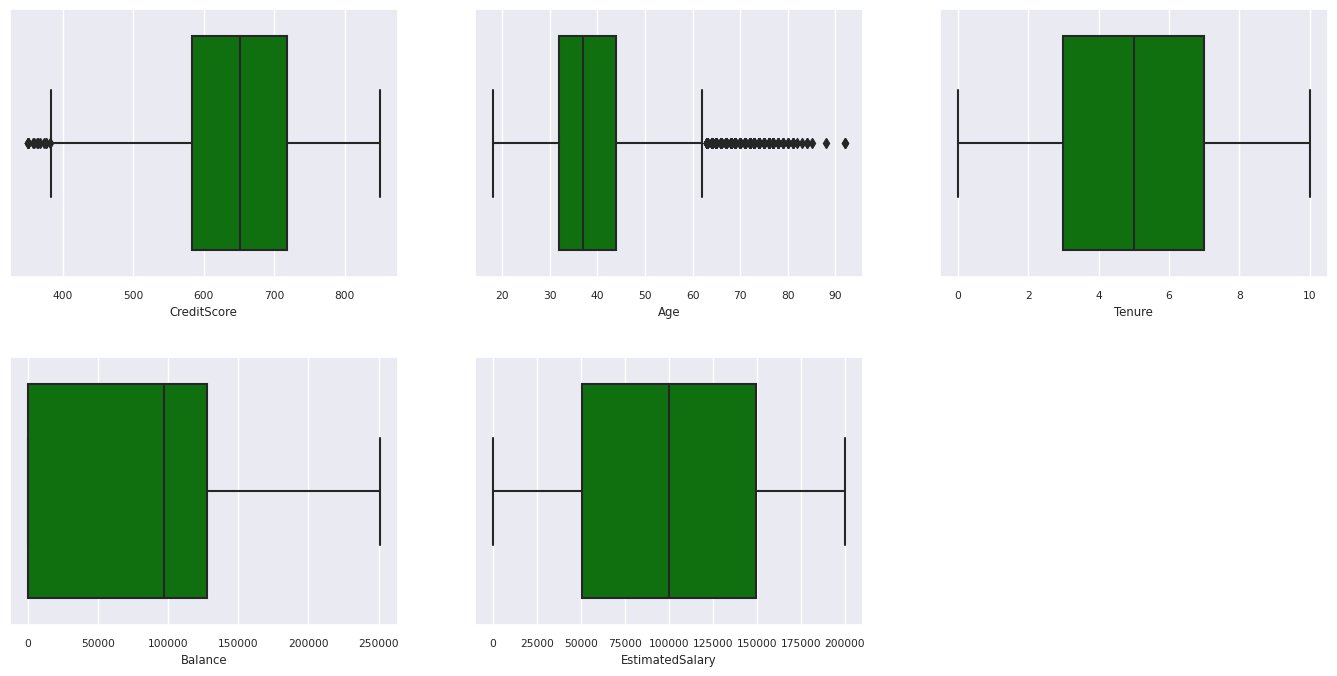
Διανομή πελατών που έχουν αποχωρήσει και δεν έχουν κάνει αλλαγές
Εμφάνιση της κατανομής των εξόδων έναντι πελατών χωρίς εξουσιοδότηση σε όλα τα κατηγορικά χαρακτηριστικά.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Κατανομή αριθμητικών χαρακτηριστικών
Εμφάνιση της κατανομής συχνότητας αριθμητικών χαρακτηριστικών με χρήση ιστογράμματος.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Εκτέλεση μηχανικής δυνατοτήτων
Εκτελέστε τη μηχανική δυνατοτήτων για να δημιουργήσετε νέα χαρακτηριστικά με βάση τα τρέχοντα χαρακτηριστικά:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Χρήση του Data Wrangler για εκτέλεση κωδικοποίησης μίας χρήσης
Το Data Wrangler μπορεί επίσης να χρησιμοποιηθεί για την εκτέλεση κωδικοποίησης μίας χρήσης. Για να το κάνετε αυτό, ανοίξτε ξανά το Data Wrangler. Αυτή τη φορά, επιλέξτε τα df_clean δεδομένα.
- Αναπτύξτε Τύποι και επιλέξτε κωδικοποιητής μίας πρόσβασης.
- Εμφανίζεται ένας πίνακας για να επιλέξετε τη λίστα των στηλών στις οποίες θέλετε να εκτελέσετε κωδικοποίηση μίας ώρας. Επιλέξτε geography και Gender.
Μπορείτε να αντιγράψετε τον κώδικα που δημιουργήθηκε, να κλείσετε το Data Wrangler για να επιστρέψετε στο σημειωματάριο και, στη συνέχεια, να το επικολλήσετε σε ένα νέο κελί. Εναλλακτικά, επιλέξτε Προσθήκη κώδικα στο σημειωματάριο επάνω αριστερά για να κλείσετε το Data Wrangler και να προσθέσετε αυτόματα τον κώδικα.
Εάν δεν χρησιμοποιήσατε τη δυνατότητα Data Wrangler, μπορείτε να χρησιμοποιήσετε αυτό το επόμενο κελί κώδικα:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Σύνοψη παρατηρήσεων από την διερευνητική ανάλυση δεδομένων
- Οι περισσότεροι πελάτες προέρχονται από τη Γαλλία σε σύγκριση με την Ισπανία και τη Γερμανία, ενώ η Ισπανία έχει το χαμηλότερο ποσοστό απώλειας σε σύγκριση με τη Γαλλία και τη Γερμανία.
- Οι περισσότεροι πελάτες έχουν πιστωτικές κάρτες.
- Υπάρχουν πελάτες των οποίων η ηλικία και το πιστωτικό αποτέλεσμα είναι πάνω από 60 και κάτω από 400, αντίστοιχα, αλλά δεν μπορούν να θεωρηθούν ως έκτοπα.
- Πολύ λίγοι πελάτες έχουν περισσότερα από δύο προϊόντα της τράπεζας.
- Οι πελάτες που δεν είναι ενεργοί έχουν υψηλότερο ποσοστό απώλειας.
- Τα έτη φύλου και διάρκειας δεν φαίνεται να επηρεάζουν την απόφαση του πελάτη να κλείσει τον τραπεζικό λογαριασμό.
Δημιουργία πίνακα δέλτα για τα καθαροποιημένα δεδομένα
Θα χρησιμοποιήσετε αυτά τα δεδομένα στο επόμενο σημειωματάριο αυτής της σειράς.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Επόμενο βήμα
Εκπαιδεύστε και καταχωρήστε μοντέλα εκμάθησης μηχανής με αυτά τα δεδομένα: