Ανάπτυξη, αξιολόγηση και βαθμολογία ενός μοντέλου πρόβλεψης για πωλήσεις superstore
Αυτό το εκπαιδευτικό βοήθημα παρουσιάζει ένα τελικό παράδειγμα μιας ροής εργασιών Synapse Data Science στο Microsoft Fabric. Το σενάριο δημιουργεί ένα μοντέλο πρόβλεψης που χρησιμοποιεί ιστορικά δεδομένα πωλήσεων για την πρόβλεψη πωλήσεων κατηγορίας προϊόντων σε ένα superstore.
Η πρόβλεψη είναι ένα κρίσιμο στοιχείο στις πωλήσεις. Συνδυάζει ιστορικά δεδομένα και προγνωστικές μεθόδους για την παροχή πληροφοριών σχετικά με μελλοντικές τάσεις. Οι προβλέψεις μπορούν να αναλύσουν προηγούμενες πωλήσεις για να προσδιορίσουν μοτίβα και να μάθουν από τη συμπεριφορά των καταναλωτών για να βελτιστοποιήσουν την απογραφή, την παραγωγή και τις στρατηγικές μάρκετινγκ. Αυτή η προληπτική προσέγγιση ενισχύει την προσαρμοστικότητα, την ανταπόκριση και τις συνολικές επιδόσεις των επιχειρήσεων σε ένα δυναμικό marketplace.
Αυτό το εκπαιδευτικό βοήθημα καλύπτει τα εξής βήματα:
- Φόρτωση των δεδομένων
- Χρήση διερευνητικής ανάλυσης δεδομένων για την κατανόηση και επεξεργασία των δεδομένων
- Εκπαιδεύστε ένα μοντέλο εκμάθησης μηχανής με ένα πακέτο λογισμικού ανοιχτού κώδικα και παρακολουθήστε πειράματα με το MLflow και τη δυνατότητα αυτόματης καταχώρησης fabric
- Αποθηκεύστε το τελικό μοντέλο εκμάθησης μηχανής και κάντε προβλέψεις
- Εμφάνιση των επιδόσεων του μοντέλου με απεικονίσεις του Power BI
Προϋποθέσεις
Λάβετε μια συνδρομής Microsoft Fabric . Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση microsoft Fabric.
Εισέλθετε για να το Microsoft Fabric.
Χρησιμοποιήστε την εναλλαγή εμπειρίας στην κάτω αριστερή πλευρά της αρχικής σελίδας σας για να μεταβείτε σε Fabric.

- Εάν είναι απαραίτητο, δημιουργήστε μια λίμνη Microsoft Fabric όπως περιγράφεται στο Δημιουργία ενός lakehouse στο Microsoft Fabric.
Παρακολούθηση σε σημειωματάριο
Μπορείτε να κάνετε μία από αυτές τις επιλογές για να ακολουθήσετε τις οδηγίες σε ένα σημειωματάριο:
- Άνοιγμα και εκτέλεση του ενσωματωμένου σημειωματάριου στην εμπειρία Synapse Data Science
- Αποστείλετε το σημειωματάριό σας από το GitHub στην εμπειρία Synapse Data Science
Άνοιγμα του ενσωματωμένου σημειωματάριου
Το δείγμα σημειωματάριο πρόβλεψης πωλήσεων συνοδεύει αυτό το πρόγραμμα εκμάθησης.
Για να ανοίξετε το δείγμα σημειωματάριου για αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Εισαγωγή του σημειωματάριου από το GitHub
Το σημειωματάριο AIsample - Superstore Forecast.ipynb συνοδεύει αυτό το πρόγραμμα εκμάθησης.
Για να ανοίξετε το σημειωματάριο που συνοδεύει αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων, να εισαγάγετε το σημειωματάριο στον χώρο εργασίας σας.
Εάν προτιμάτε να αντιγράψετε και να επικολλήσετε τον κώδικα από αυτήν τη σελίδα, μπορείτε να δημιουργήσετε ένα νέο σημειωματάριο.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Βήμα 1: Φόρτωση των δεδομένων
Το σύνολο δεδομένων περιέχει 9.995 παρουσίες πωλήσεων διαφόρων προϊόντων. Περιλαμβάνει επίσης 21 χαρακτηριστικά. Αυτός ο πίνακας προέρχεται από το αρχείο Superstore.xlsx που χρησιμοποιείται σε αυτό το σημειωματάριο:
| Αναγνωριστικό γραμμής | Αναγνωριστικό παραγγελίας | Ημερομηνία παραγγελίας | Ημερομηνία αποστολής | Λειτουργία αποστολής | Αναγνωριστικό πελάτη | Όνομα πελάτη | Τμήμα | Χώρα | Πόλη | Κράτος | Ταχυδρομικός κώδικας | Περιοχή | Αναγνωριστικό προϊόντος | Κατηγορία | Sub-Category | Όνομα προϊόντος | Πωλήσεις | Ποσότητα | Έκπτωση | Κέρδος |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Τυπική κλάση | SO-20335 | Σον Ο'Ντόνελ | Καταναλωτής | Ηνωμένες Πολιτείες | Fort Lauderdale | Φλόριντα | 33311 | Νότια | FUR-TA-10000577 | Έπιπλα | Πίνακες | Λεπτός ορθογώνιος πίνακας σειράς Bretford CR4500 | 957.5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Τυπική κλάση | Τυπική κλάση | Brosina Hoffman | Καταναλωτής | Ηνωμένες Πολιτείες | Λος Άντζελες | Καλιφόρνια | 90032 | Δύση | FUR-TA-10001539 | Έπιπλα | Πίνακες | Ορθογώνιοι πίνακες διάσκεψης Chromcraft | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Τυπική κλάση | TB-21520 | Tracy Blumstein | Καταναλωτής | Ηνωμένες Πολιτείες | Φιλαδέλφεια | Πενσυλβάνια | 19140 | Ανατολικά | OFF-EN-10001509 | Προμήθειες γραφείου | Φάκελοι | Φάκελοι δεσμών πολυ συμβολοσειρών | 3.264 | 2 | 0.2 | 1.1016 |
Καθορίστε αυτές τις παραμέτρους, ώστε να μπορείτε να χρησιμοποιήσετε αυτό το σημειωματάριο με διαφορετικά σύνολα δεδομένων:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Λήψη του συνόλου δεδομένων και αποστολή στο lakehouse
Αυτός ο κώδικας κάνει λήψη μιας δημόσια διαθέσιμης έκδοσης του συνόλου δεδομένων και, στη συνέχεια, τον αποθηκεύει σε μια λίμνη Fabric:
Σημαντικός
Φροντίστε να προσθέσετε ένα lakehouse στο σημειωματάριο προτού το εκτελέσετε. Διαφορετικά, θα λάβετε ένα σφάλμα.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Ρύθμιση παρακολούθησης πειραμάτων MLflow
Το Microsoft Fabric καταγράφει αυτόματα τις τιμές των παραμέτρων εισόδου και των μετρικών εξόδου ενός μοντέλου εκμάθησης μηχανής καθώς το εκπαιδεύετε. Αυτό επεκτείνει τις δυνατότητες αυτόματης καταχώρησης ροής MLflow. Στη συνέχεια, οι πληροφορίες καταγράφονται στον χώρο εργασίας, όπου μπορείτε να αποκτήσετε πρόσβαση και να τις απεικονίσετε με τα API MLflow ή το αντίστοιχο πείραμα στον χώρο εργασίας. Για να μάθετε περισσότερα σχετικά με την αυτόματη καταχώρηση, ανατρέξτε στο θέμα Αυτόματη καταχώρηση στο Microsoft Fabric.
Για να απενεργοποιήσετε την αυτόματη καταχώρηση του Microsoft Fabric σε μια περίοδο λειτουργίας σημειωματάριου, καλέστε mlflow.autolog() και ορίστε disable=True:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Ανάγνωση ανεπεξέργαστων δεδομένων από το lakehouse
Διαβάστε ανεπεξέργαστα δεδομένα από το τμήμα
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Βήμα 2: Εκτέλεση διερευνητικής ανάλυσης δεδομένων
Εισαγωγή βιβλιοθηκών
Πριν από οποιαδήποτε ανάλυση, εισαγάγετε τις απαιτούμενες βιβλιοθήκες:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Εμφάνιση ανεπεξέργαστων δεδομένων
Εξετάστε με μη αυτόματο τρόπο ένα υποσύνολο των δεδομένων, για να κατανοήσετε καλύτερα το ίδιο το σύνολο δεδομένων και χρησιμοποιήστε τη συνάρτηση display για να εκτυπώσετε το DataFrame. Επιπλέον, οι Chart προβολές μπορούν εύκολα να απεικονίσουν υποσύνολα του συνόλου δεδομένων.
display(df)
Αυτό το σημειωματάριο εστιάζει κυρίως στην πρόβλεψη των πωλήσεων κατηγορίας Furniture. Αυτό επιταχύνει τον υπολογισμό και σας βοηθά να εμφανίσετε τις επιδόσεις του μοντέλου. Ωστόσο, αυτό το σημειωματάριο χρησιμοποιεί προσαρμόσιμες τεχνικές. Μπορείτε να επεκτείνετε αυτές τις τεχνικές για να προβλέψετε τις πωλήσεις άλλων κατηγοριών προϊόντων.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Προεπεξεργασία των δεδομένων
Τα πραγματικά επιχειρηματικά σενάρια συχνά χρειάζεται να προβλέψουν πωλήσεις σε τρεις διακριτές κατηγορίες:
- Μια συγκεκριμένη κατηγορία προϊόντος
- Μια συγκεκριμένη κατηγορία πελάτη
- Ένας συγκεκριμένος συνδυασμός κατηγορίας προϊόντων και κατηγορίας πελατών
Πρώτα, καταργήστε τις περιττές στήλες για να προεπεξεργασθετε τα δεδομένα. Ορισμένες από τις στήλες (Row ID, Order ID,Customer IDκαι Customer Name) είναι περιττές καθώς δεν έχουν καμία επίδραση. Θέλουμε να προβλέψουμε τις συνολικές πωλήσεις, σε όλη την πολιτεία και περιοχή, για μια συγκεκριμένη κατηγορία προϊόντων (Furniture), ώστε να μπορέσουμε να αποθέσουμε τις στήλες State, Region, Country, Cityκαι Postal Code. Για να προβλέψετε πωλήσεις για μια συγκεκριμένη τοποθεσία ή κατηγορία, ίσως χρειαστεί να προσαρμόσετε ανάλογα το βήμα προεπεξεργασίας.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Το σύνολο δεδομένων είναι δομημένο σε καθημερινή βάση. Πρέπει να επαναλάβουμε το δείγμα στη στήλη Order Date, επειδή θέλουμε να αναπτύξουμε ένα μοντέλο για πρόβλεψη των πωλήσεων σε μηνιαία βάση.
Πρώτα, ομαδοποιήστε την κατηγορία Furniture κατά Order Date. Στη συνέχεια, υπολογίστε το άθροισμα της στήλης Sales για κάθε ομάδα, για να προσδιορίσετε τις συνολικές πωλήσεις για κάθε μοναδική Order Date τιμή. Επαναλάβετε το δείγμα της στήλης Sales με τη συχνότητα MS, για να συγκεντρώσετε τα δεδομένα κατά μήνα. Τέλος, υπολογίστε τη μέση τιμή πωλήσεων για κάθε μήνα.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Επιδείξτε την επίδραση των Order Date στην Sales για την κατηγορία Furniture:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Πριν από οποιαδήποτε στατιστική ανάλυση, πρέπει να εισαγάγετε τη λειτουργική μονάδα statsmodels Python. Παρέχει και συναρτήσεις για την εκτίμηση πολλών στατιστικών μοντέλων. Παρέχει επίσης και λειτουργίες για τη διεξαγωγή στατιστικών δοκιμών και εξερεύνησης στατιστικών δεδομένων.
import statsmodels.api as sm
Εκτέλεση στατιστικής ανάλυσης
Μια χρονολογική σειρά παρακολουθεί αυτά τα στοιχεία δεδομένων σε καθορισμένα διαστήματα, για να προσδιορίσει την παραλλαγή αυτών των στοιχείων στο μοτίβο χρονικής σειράς:
επιπέδου: Το βασικό στοιχείο που αντιπροσωπεύει τη μέση τιμή για μια συγκεκριμένη χρονική περίοδο
Trend: Περιγράφει εάν η χρονολογική σειρά μειώνεται, παραμένει σταθερή ή αυξάνεται με την πάροδο του χρόνου
εποχικότητας: Περιγράφει το περιοδικό σήμα στη χρονική σειρά και αναζητά κυκλικές εμφανίσεις που επηρεάζουν τα μοτίβα χρονικής σειράς που αυξάνονται ή μειώνονται
θόρυβος/υπολειπόμενο: Αναφέρεται στις τυχαίες διακυμάνσεις και τη διακύμανση στα δεδομένα χρονικής σειράς που δεν μπορεί να εξηγήσει το μοντέλο.
Σε αυτόν τον κώδικα, θα παρακολουθήσετε αυτά τα στοιχεία για το σύνολο δεδομένων σας μετά την προεπεξεργασία:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Τα γραφήματα περιγράφουν την εποχικότητα, τις τάσεις και τον θόρυβο στα δεδομένα πρόβλεψης. Μπορείτε να καταγράψετε τα υποκείμενα μοτίβα και να αναπτύξετε μοντέλα που κάνουν ακριβείς προβλέψεις που είναι ανθεκτικές σε τυχαίες διακυμάνσεις.
Βήμα 3: Εκπαίδευση και παρακολούθηση του μοντέλου
Τώρα που έχετε τα διαθέσιμα δεδομένα, καθορίστε το μοντέλο πρόβλεψης. Σε αυτό το σημειωματάριο, εφαρμόστε το μοντέλο πρόβλεψης που ονομάζεται εποχιακό ενσωματωμένο κινητό μέσο όρο αυτο-παλινδρόμησης με εξωγενείς παράγοντες (SARIMAX). Το SARIMAX συνδυάζει στοιχεία αυτόματης παλινδρόμησης (AR) και κινούμενα μέσα στοιχεία (MA), εποχιακές διαφορές και εξωτερικούς παράγοντες πρόβλεψης για την πραγματοποίηση ακριβών και ευέλικτων προβλέψεων για δεδομένα χρονικής σειράς.
Μπορείτε επίσης να χρησιμοποιήσετε την αυτόματη καταχώρηση MLflow και Fabric για να παρακολουθήσετε τα πειράματα. Εδώ, φορτώστε τον πίνακα δέλτα από το λιμνοθάδικο. Μπορείτε να χρησιμοποιήσετε άλλους πίνακες δέλτα που θεωρούν τη λίμνη ως προέλευση.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Ρύθμιση υπερπαραμετών
Η SARIMAX λαμβάνει υπόψη τις παραμέτρους που εμπλέκονται στην κανονική ενσωματωμένη λειτουργία μετακίνησης (ARIMA) αυτόματης παλινδρόμησης (p, dq) και προσθέτει τις παραμέτρους εποχικότητας (P, D, Q, s). Αυτά τα ορίσματα μοντέλου SARIMAX ονομάζονται σειρά (p, dq) και εποχιακών παραγγελιών (P, D, Qs), αντίστοιχα. Επομένως, για να εκπαιδεύσουμε το μοντέλο, πρέπει πρώτα να ρυθμίσουμε επτά παραμέτρους.
Οι παράμετροι παραγγελίας:
p: Η σειρά του στοιχείου AR, που αντιπροσωπεύει τον αριθμό των προηγούμενων παρατηρήσεων στη χρονική σειρά που χρησιμοποιείται για την πρόβλεψη της τρέχουσας τιμής.Συνήθως, αυτή η παράμετρος πρέπει να είναι ένας μη αρνητικός ακέραιος. Οι κοινές τιμές βρίσκονται στην περιοχή από
0έως3, αν και είναι δυνατές υψηλότερες τιμές, ανάλογα με τα συγκεκριμένα χαρακτηριστικά δεδομένων. Μια υψηλότερη τιμήpυποδεικνύει μεγαλύτερη μνήμη των προηγούμενων τιμών στο μοντέλο.d: Η διαφορετική σειρά, που αντιπροσωπεύει τον αριθμό των φορών που πρέπει να διαφορά η χρονολογική σειρά, για να επιτευχθεί σταθμικότητα.Αυτή η παράμετρος πρέπει να είναι μη αρνητικός ακέραιος. Οι κοινές τιμές είναι στην περιοχή από
0έως2. Μιαdτιμή του0σημαίνει ότι η χρονολογική σειρά είναι ήδη σταθερή. Οι υψηλότερες τιμές υποδεικνύουν τον αριθμό των διαφορετικών λειτουργιών που απαιτούνται για να καταστεί σταθερός.q: Η σειρά του στοιχείου MA, που αντιπροσωπεύει τον αριθμό των τελευταίων όρων σφάλματος λευκού θορύβου που χρησιμοποιούνται για την πρόβλεψη της τρέχουσας τιμής.Αυτή η παράμετρος πρέπει να είναι μη αρνητικός ακέραιος. Οι κοινές τιμές βρίσκονται στην περιοχή των
0έως3, αλλά μπορεί να απαιτούνται υψηλότερες τιμές για συγκεκριμένη χρονολογική σειρά. Μια υψηλότερη τιμήqυποδεικνύει μεγαλύτερη εξάρτηση από προηγούμενους όρους σφάλματος για την πραγματοποίηση προβλέψεων.
Οι παράμετροι εποχιακής παραγγελίας:
-
P: Η εποχιακή σειρά του στοιχείου AR, παρόμοια μεpαλλά για το εποχιακό μέρος -
D: Η εποχιακή σειρά διαφορετικών τιμών, παρόμοια μεdαλλά για το εποχιακό μέρος -
Q: Η εποχιακή σειρά του στοιχείου MA, παρόμοια μεqαλλά για το εποχιακό τμήμα -
s: Ο αριθμός των βημάτων χρόνου ανά εποχιακό κύκλο (για παράδειγμα, 12 για μηνιαία δεδομένα με ετήσια εποχικότητα)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
Η SARIMAX έχει άλλες παραμέτρους:
enforce_stationarity: Ορίζει εάν το μοντέλο πρέπει να επιβάλλει τη σταθμικότητα στα δεδομένα χρονικής σειράς, πριν από την τοποθέτηση του μοντέλου SARIMAX.Εάν
enforce_stationarityέχει οριστεί σεTrue(η προεπιλογή), υποδεικνύει ότι το μοντέλο SARIMAX θα πρέπει να επιβάλλει σταθμικότητα στα δεδομένα χρονικής σειράς. Το μοντέλο SARIMAX έπειτα εφαρμόζει αυτόματα διαφορετικές διαφορές στα δεδομένα, για να το καταστήσει στατικό, όπως καθορίζεται από τιςdκαιDπαραγγελίες, πριν από την τοποθέτηση του μοντέλου. Αυτή είναι μια κοινή πρακτική, επειδή πολλά μοντέλα χρονικής σειράς, συμπεριλαμβανομένου του SARIMAX, υποθέτουν ότι τα δεδομένα είναι σταθερά.Για μια μη σταθερή χρονολογική σειρά (για παράδειγμα, παρουσιάζει τάσεις ή εποχικότητα), συνιστάται να ορίσετε
enforce_stationarityσεTrueκαι να αφήσετε το μοντέλο SARIMAX να χειριστεί τις διαφορετικές έννοιες για να επιτύχει σταθμικότητα. Για μια στατική χρονολογική σειρά (για παράδειγμα, μία χωρίς τάσεις ή εποχικότητα), ορίστεenforce_stationarityσεFalseγια να αποφύγετε περιττές διαφορές.enforce_invertibility: Ελέγχει εάν το μοντέλο πρέπει να επιβάλλει την προσβασιμότητα στις εκτιμώμενες παραμέτρους κατά τη διάρκεια της διαδικασίας βελτιστοποίησης.Εάν
enforce_invertibilityέχει οριστεί σεTrue(η προεπιλογή), υποδεικνύει ότι το μοντέλο SARIMAX θα πρέπει να επιβάλλει την προσβασιμότητα στις εκτιμώμενες παραμέτρους. Η προσβασιμότητα εξασφαλίζει ότι το μοντέλο είναι καλά καθορισμένο και ότι οι εκτιμώμενοι συντελεστές AR και MA εκτρέφονται εντός του εύρους της σταθμικότητας.Η επιβολή της προσβασιμότητας βοηθά να εξασφαλιστεί ότι το μοντέλο SARIMAX συμμορφώνεται με τις θεωρητικές απαιτήσεις για ένα σταθερό μοντέλο χρονικής σειράς. Επίσης, βοηθά στην πρόληψη ζητημάτων με την εκτίμηση μοντέλου και τη σταθερότητα.
Η προεπιλογή είναι ένα AR(1) μοντέλο. Αυτό αναφέρεται στο (1, 0, 0). Ωστόσο, αποτελεί κοινή πρακτική να δοκιμάσετε διαφορετικούς συνδυασμούς των παραμέτρων παραγγελιών και των παραμέτρων εποχιακών παραγγελιών και να αξιολογείτε τις επιδόσεις του μοντέλου για ένα σύνολο δεδομένων. Οι κατάλληλες τιμές μπορεί να διαφέρουν από μία χρονολογική σειρά σε μια άλλη.
Ο προσδιορισμός των βέλτιστων τιμών συχνά περιλαμβάνει την ανάλυση της συνάρτησης αυτόματης συσχέτισης (ACF) και τη μερική συνάρτηση αυτόματης συσχέτισης (PACF) των δεδομένων χρονικής σειράς. Περιλαμβάνει επίσης συχνά τη χρήση κριτηρίων επιλογής μοντέλου - για παράδειγμα, το κριτήριο πληροφοριών Akaike (AIC) ή το κριτήριο πληροφοριών Bayesian (BIC).
Ρυθμίστε τους υπερπαραμετήρες:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Μετά την αξιολόγηση των προηγούμενων αποτελεσμάτων, μπορείτε να καθορίσετε τις τιμές τόσο για τις παραμέτρους παραγγελίας όσο και για τις παραμέτρους εποχιακής παραγγελίας. Η επιλογή είναι order=(0, 1, 1) και seasonal_order=(0, 1, 1, 12), οι οποίες προσφέρουν το χαμηλότερο AIC (για παράδειγμα, 279,58). Χρησιμοποιήστε αυτές τις τιμές για να εκπαιδεύσετε το μοντέλο.
Εκπαίδευση του μοντέλου
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Αυτός ο κώδικας απεικονίζει μια πρόβλεψη χρονικής σειράς για δεδομένα πωλήσεων επίπλων. Τα αποτελέσματα της σχεδίασης εμφανίζουν τα δεδομένα που παρατηρήθηκαν και την πρόβλεψη ενός βήματος προς τα εμπρός, με σκιασμένη περιοχή για το διάστημα εμπιστοσύνης.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Χρησιμοποιήστε predictions για να αξιολογήσετε τις επιδόσεις του μοντέλου, αντιπαραβάλλοντάς τις με τις πραγματικές τιμές. Η τιμή predictions_future υποδεικνύει μελλοντική πρόβλεψη.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Βήμα 4: Βαθμολόγηση του μοντέλου και αποθήκευση προβλέψεων
Ενσωματώστε τις πραγματικές τιμές με τις προβλεπόμενες τιμές, για να δημιουργήσετε μια αναφορά Power BI. Αποθηκεύστε αυτά τα αποτελέσματα σε έναν πίνακα μέσα στο lakehouse.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Βήμα 5: Απεικόνιση στο Power BI
Η αναφορά Power BI εμφανίζει ένα μέσο σφάλμα απόλυτου ποσοστού (MAPE) 16,58. Το μετρικό MAPE ορίζει την ακρίβεια μιας μεθόδου πρόβλεψης. Αντιπροσωπεύει την ακρίβεια των προβλεπόμενων ποσοτήτων, σε σύγκριση με τις πραγματικές ποσότητες.
Το MAPE είναι ένα απλό μετρικό. Μια% MAPE 10 αντιπροσωπεύει ότι η μέση απόκλιση μεταξύ των προβλεπόμενων τιμών και των πραγματικών τιμών είναι 10%, ανεξάρτητα από το αν η απόκλιση ήταν θετική ή αρνητική. Τα πρότυπα των επιθυμητών τιμών MAPE διαφέρουν μεταξύ των κλάδων.
Η ανοιχτό μπλε γραμμή σε αυτό το γράφημα αντιπροσωπεύει τις πραγματικές τιμές πωλήσεων. Η σκούρα μπλε γραμμή αντιπροσωπεύει τις προβλεπόμενες τιμές πωλήσεων. Η σύγκριση των πραγματικών και προβλεπόμενων πωλήσεων αποκαλύπτει ότι το μοντέλο προβλέπει αποτελεσματικά τις πωλήσεις για την κατηγορία Furniture κατά τους πρώτους έξι μήνες του 2023.
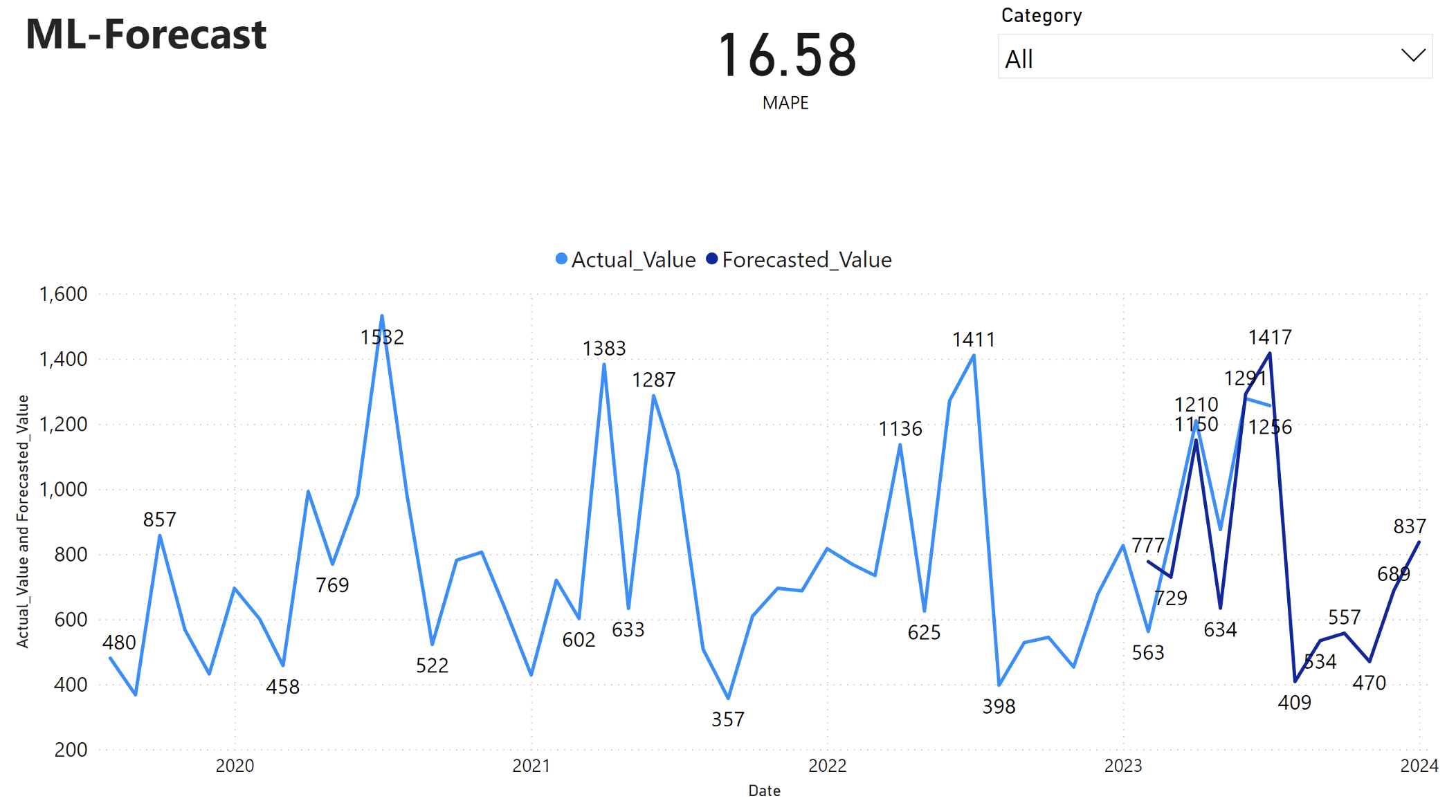
Με βάση αυτή την παρατήρηση, μπορούμε να έχουμε εμπιστοσύνη στις δυνατότητες πρόβλεψης του μοντέλου, για τις συνολικές πωλήσεις το τελευταίο εξάμηνο του 2023 και επεκτείνονται έως το 2024. Αυτή η εμπιστοσύνη μπορεί να ενημερώσει στρατηγικές αποφάσεις σχετικά με τη διαχείριση απογραφής, την προμήθεια πρώτων υλών και άλλα ζητήματα που σχετίζονται με τις επιχειρήσεις.
Σχετικό περιεχόμενο
- Πώς μπορείτε να χρησιμοποιήσετε σημειωματάρια Microsoft Fabric
- μοντέλο εκμάθησης μηχανής στο Microsoft Fabric
- Εκπαίδευση μοντέλων εκμάθησης μηχανής
- πειράματα εκμάθησης μηχανής στο Microsoft Fabric