Συνταγή: Υπηρεσίες AI Azure - Εντοπισμός πολλαπλών ανωμαλιών
Αυτή η συνταγή δείχνει πώς μπορείτε να χρησιμοποιήσετε τις υπηρεσίες SynapseML και Azure AI στο Apache Spark για εντοπισμό πολλαπλών ανωμαλιών. Ο εντοπισμός πολλαπλών ανωμαλιών επιτρέπει τον εντοπισμό ανωμαλιών μεταξύ πολλών μεταβλητών ή χρονολογικής σειράς, λαμβάνοντας υπόψη όλες τις αλληλεπιδράσεις και τις εξαρτήσεις μεταξύ των διαφορετικών μεταβλητών. Σε αυτό το σενάριο, χρησιμοποιούμε το SynapseML για την εκπαίδευση ενός μοντέλου για τον εντοπισμό πολυμεταβλημένων ανωμαλιών με χρήση των υπηρεσιών Azure AI και, στη συνέχεια, χρησιμοποιούμε στο μοντέλο για να συνάγουμε πολυμεταβλητέες ανωμαλίες μέσα σε ένα σύνολο δεδομένων που περιέχει συνθετικές μετρήσεις από τρεις αισθητήρες IoT.
Σημαντικό
Ξεκινώντας από τις 20 Σεπτεμβρίου 2023 δεν θα μπορείτε να δημιουργήσετε νέους πόρους για το Πρόγραμμα εντοπισμού ανωμαλιών. Η υπηρεσία εντοπισμού ανωμαλιών αποσύρεται την 1η Οκτωβρίου 2026.
Για να μάθετε περισσότερα σχετικά με το Πρόγραμμα εντοπισμού ανωμαλιών του Azure AI, ανατρέξτε σε αυτή τη σελίδα τεκμηρίωσης.
Προαπαιτούμενα στοιχεία
- Μια συνδρομή Azure - Δημιουργήστε μία δωρεάν
- Επισυνάψτε το σημειωματάριό σας σε ένα lakehouse. Στην αριστερή πλευρά, επιλέξτε Προσθήκη για να προσθέσετε μια υπάρχουσα λίμνη ή να δημιουργήσετε μια λίμνη.
Ρύθμιση
Ακολουθήστε τις οδηγίες για να δημιουργήσετε έναν Anomaly Detector πόρο χρησιμοποιώντας την πύλη Azure ή, εναλλακτικά, μπορείτε επίσης να χρησιμοποιήσετε το Azure CLI για να δημιουργήσετε αυτόν τον πόρο.
Αφού ρυθμίσετε ένα Anomaly Detector, μπορείτε να εξερευνήσετε μεθόδους χειρισμού δεδομένων από διάφορες φόρμες. Ο κατάλογος υπηρεσιών στο Azure AI παρέχει διάφορες επιλογές: Οπτική απεικόνιση, ομιλία, γλώσσα, αναζήτηση στο Web, απόφαση, μετάφραση και ευφυΐα εγγράφων.
Δημιουργία πόρου εντοπισμού ανωμαλιών
- Στην πύλη Azure, επιλέξτε Δημιουργία στην ομάδα πόρων σας και, στη συνέχεια, πληκτρολογήστε Πρόγραμμα εντοπισμού ανωμαλιών. Επιλέξτε τον πόρο Πρόγραμμα εντοπισμού ανωμαλιών.
- Δώστε ένα όνομα στον πόρο και ιδανικά χρησιμοποιήστε την ίδια περιοχή με την υπόλοιπη ομάδα πόρων σας. Χρησιμοποιήστε τις προεπιλεγμένες επιλογές για τα υπόλοιπα και, στη συνέχεια, επιλέξτε Αναθεώρηση + Δημιουργία και, στη συνέχεια, Δημιουργία.
- Μόλις δημιουργηθεί ο πόρος για το Πρόγραμμα εντοπισμού ανωμαλιών, ανοίξτε τον και επιλέξτε τον
Keys and Endpointsπίνακα στο αριστερό παράθυρο περιήγησης. Αντιγράψτε το κλειδί για τον πόρο πρόγραμμα εντοπισμού ανωμαλιών στηANOMALY_API_KEYμεταβλητή περιβάλλοντος ή αποθηκεύστε τοanomalyKeyστη μεταβλητή.
Δημιουργία πόρου λογαριασμού υπηρεσίας αποθήκευσης
Για να αποθηκεύσετε ενδιάμεσα δεδομένα, πρέπει να δημιουργήσετε έναν λογαριασμό χώρου αποθήκευσης αντικειμένων blob Azure. Σε αυτόν τον λογαριασμό χώρου αποθήκευσης, δημιουργήστε ένα κοντέινερ για την αποθήκευση των ενδιάμεσων δεδομένων. Σημειώστε το όνομα του κοντέινερ και αντιγράψτε τη συμβολοσειρά σύνδεσης σε αυτό το κοντέινερ. Θα τη χρειαστείτε αργότερα για να συμπληρώσετε τη containerName μεταβλητή και τη BLOB_CONNECTION_STRING μεταβλητή περιβάλλοντος.
Εισαγωγή των κλειδιών υπηρεσίας
Ας ξεκινήσουμε ρυθμίζοντας τις μεταβλητές περιβάλλοντος για τα κλειδιά υπηρεσίας μας. Το επόμενο κελί ορίζει τις ANOMALY_API_KEY BLOB_CONNECTION_STRING μεταβλητές περιβάλλοντος και τις μεταβλητές περιβάλλοντος με βάση τις τιμές που είναι αποθηκευμένες στο Azure Key Vault. Εάν εκτελείτε αυτό το πρόγραμμα εκμάθησης στο δικό σας περιβάλλον, βεβαιωθείτε ότι έχετε ορίσει αυτές τις μεταβλητές περιβάλλοντος προτού συνεχίσετε.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Τώρα, επιτρέπει την ανάγνωση των ANOMALY_API_KEY μεταβλητών περιβάλλοντος και BLOB_CONNECTION_STRING και τον ορισμό των containerName μεταβλητών και location .
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Πρώτα, συνδεόμαστε στον λογαριασμό μας χώρου αποθήκευσης έτσι ώστε το πρόγραμμα εντοπισμού ανωμαλιών να μπορεί να αποθηκεύσει τα ενδιάμεσα αποτελέσματα εκεί:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Ας εισαγάγουμε όλες τις απαραίτητες λειτουργικές μονάδες.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Τώρα, ας διαβάσουμε το δείγμα δεδομένων μας σε ένα Spark DataFrame.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Μπορούμε τώρα να δημιουργήσουμε ένα estimator αντικείμενο, το οποίο χρησιμοποιείται για την εκπαίδευση του μοντέλου μας. Καθορίσαμε την ώρα έναρξης και λήξης για τα δεδομένα εκπαίδευσης. Επίσης, θα καθορίσουμε τις στήλες εισόδου που θα χρησιμοποιηθούν και το όνομα της στήλης που περιέχει τα χρονικά σημάνσεις. Τέλος, καθορίζουμε τον αριθμό των σημείων δεδομένων που θα χρησιμοποιηθούν στο συρόμενο παράθυρο εντοπισμού ανωμαλίας και ορίζουμε τη συμβολοσειρά σύνδεσης στον λογαριασμό χώρου αποθήκευσης αντικειμένων blob Azure.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Τώρα που δημιουργήσαμε το estimator, ας το προσαρμόσουμε στα δεδομένα:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Όταν καλέσαμε .show(5) το προηγούμενο κελί, μας έδειξε τις πρώτες πέντε γραμμές στο πλαίσιο δεδομένων. Τα αποτελέσματα ήταν όλα null επειδή δεν ήταν μέσα στο παράθυρο συμπερασματικότητας.
Για να εμφανίσετε τα αποτελέσματα μόνο για τα δεδομένα που συνάγεται, μπορείτε να επιλέξετε τις στήλες που χρειαζόμαστε. Στη συνέχεια, μπορούμε να παραγγείλουμε τις γραμμές στο πλαίσιο δεδομένων με αύξουσα σειρά και να φιλτράρουμε το αποτέλεσμα ώστε να εμφανίζονται μόνο οι γραμμές που βρίσκονται στην περιοχή του παραθύρου συμπερασμάτων. Στην περίπτωσή inferenceEndTime μας, είναι το ίδιο με την τελευταία γραμμή στο πλαίσιο δεδομένων, επομένως, μπορείτε να το αγνοήσετε.
Τέλος, για να μπορέσετε να σχεδιάσετε καλύτερα τα αποτελέσματα, ας μετατρέψουμε το πλαίσιο δεδομένων Spark σε ένα πλαίσιο δεδομένων Pandas.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Μορφοποιήστε τη contributors στήλη που αποθηκεύει τη βαθμολογία συμβολής από κάθε αισθητήρα στις εντοπισμένες ανωμαλίες. Το επόμενο κελί μορφοποιεί αυτά τα δεδομένα και διαιρεί τη βαθμολογία συμβολής κάθε αισθητήρα σε δική του στήλη.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Εξαιρετικά! Έχουμε τώρα τις βαθμολογίες συμβολής των αισθητήρων 1, 2 και 3 στις series_0στήλες , series_1και series_2 αντίστοιχα.
Εκτελέστε το επόμενο κελί για να σχεδιάσετε τα αποτελέσματα. Η minSeverity παράμετρος καθορίζει το ελάχιστο επίπεδο σοβαρότητας των ανωμαλιών που θα σχεδιαστούν.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
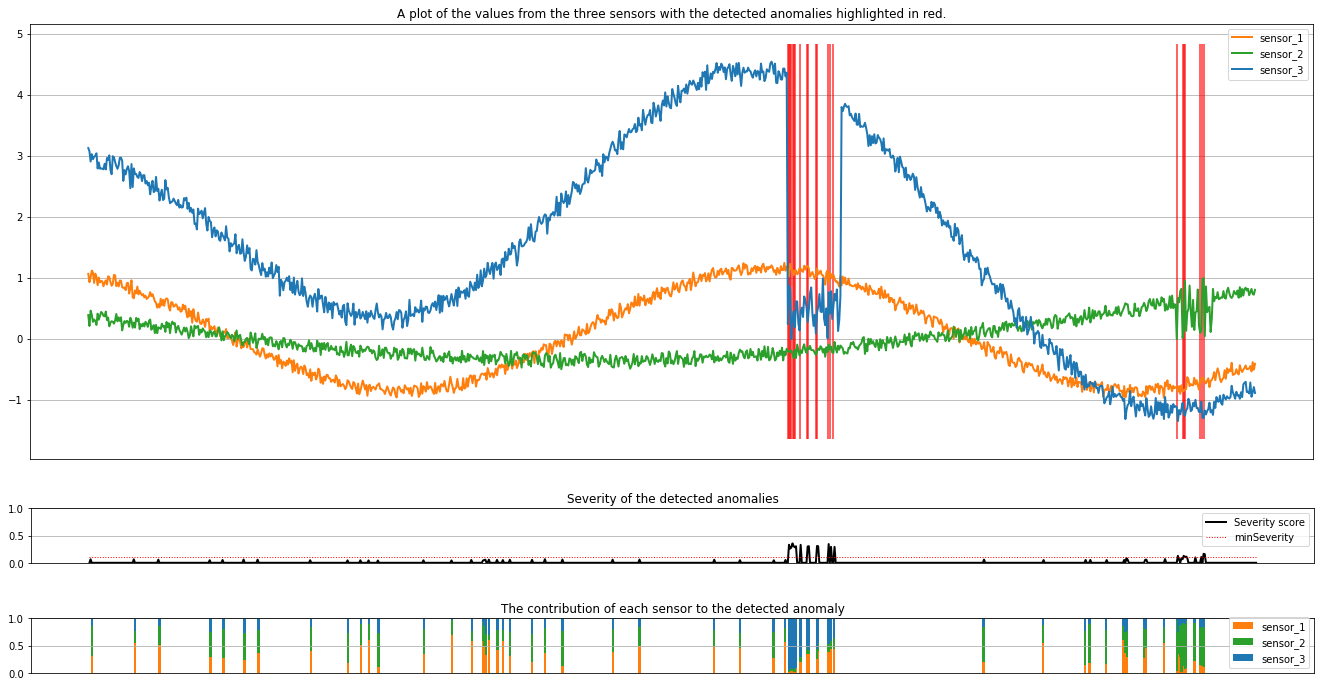
Οι σχεδιάσεις εμφανίζουν τα ανεπεξέργαστα δεδομένα από τους αισθητήρες (μέσα στο παράθυρο συμπερασμάτων) με πορτοκαλί, πράσινο και μπλε. Οι κόκκινες κατακόρυφες γραμμές στην πρώτη εικόνα εμφανίζουν τις εντοπισμένες ανωμαλίες που έχουν σοβαρότητα μεγαλύτερη ή ίση με minSeverity.
Η δεύτερη σχεδίαση εμφανίζει τη βαθμολογία σοβαρότητας όλων των ανωμαλιών που εντοπίστηκαν, με το minSeverity όριο να εμφανίζεται στη διάστικτη κόκκινη γραμμή.
Τέλος, η τελευταία σχεδίαση δείχνει τη συμβολή των δεδομένων από κάθε αισθητήρα στις εντοπισμένες ανωμαλίες. Μας βοηθά στη διάγνωση και την κατανόηση της πιο πιθανής αιτίας κάθε ανωμαλίας.