Εκμάθηση: Δημιουργία, αξιολόγηση και βαθμολογία μοντέλου πρόβλεψης απώλειας
Αυτό το εκπαιδευτικό βοήθημα παρουσιάζει ένα τελικό παράδειγμα μιας ροής εργασιών Synapse Data Science στο Microsoft Fabric. Το σενάριο δημιουργεί ένα μοντέλο για να προβλέψει εάν οι πελάτες τραπεζών χάνονται ή όχι. Το ποσοστό απώλειας, ή το ποσοστό φθοράς, αφορά το ποσοστό με το οποίο οι πελάτες τραπεζών τελειώνουν τις δραστηριότητές τους με την τράπεζα.
Αυτό το εκπαιδευτικό βοήθημα καλύπτει τα εξής βήματα:
- Εγκατάσταση προσαρμοσμένων βιβλιοθηκών
- Φόρτωση των δεδομένων
- Κατανόηση και επεξεργασία των δεδομένων μέσω διερευνητικής ανάλυσης δεδομένων και εμφάνιση της χρήσης της δυνατότητας Fabric Data Wrangler
- Χρησιμοποιήστε scikit-learn και LightGBM για να εκπαιδεύσετε μοντέλα εκμάθησης μηχανής και να παρακολουθήσετε πειράματα με τις δυνατότητες MLflow και Fabric Autologging
- Αξιολόγηση και αποθήκευση του τελικού μοντέλου εκμάθησης μηχανής
- Εμφάνιση των επιδόσεων του μοντέλου με απεικονίσεις του Power BI
Προϋποθέσεις
Λάβετε μια συνδρομής Microsoft Fabric . Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση microsoft Fabric.
Εισέλθετε για να το Microsoft Fabric.
Χρησιμοποιήστε την εναλλαγή εμπειρίας στην κάτω αριστερή πλευρά της αρχικής σελίδας σας για να μεταβείτε σε Fabric.

- Εάν είναι απαραίτητο, δημιουργήστε μια λίμνη Microsoft Fabric όπως περιγράφεται στο Δημιουργία ενός lakehouse στο Microsoft Fabric.
Παρακολούθηση σε σημειωματάριο
Μπορείτε να κάνετε μία από αυτές τις επιλογές για να ακολουθήσετε τις οδηγίες σε ένα σημειωματάριο:
- Ανοίξτε και εκτελέστε το ενσωματωμένο σημειωματάριο.
- Αποστείλετε το σημειωματάριό σας από το GitHub.
Άνοιγμα του ενσωματωμένου σημειωματάριου
Το δείγμα την απώλεια πελατών σημειωματάριο συνοδεύει αυτό το πρόγραμμα εκμάθησης.
Για να ανοίξετε το δείγμα σημειωματάριου για αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Εισαγωγή του σημειωματάριου από το GitHub
Το σημειωματάριο AIsample - Bank Customer Churn.ipynb συνοδεύει αυτό το εκπαιδευτικό βοήθημα.
Για να ανοίξετε το σημειωματάριο που συνοδεύει αυτό το εκπαιδευτικό βοήθημα, ακολουθήστε τις οδηγίες στο Προετοιμασία του συστήματός σας για εκπαιδευτικά βοηθήματα επιστήμης δεδομένων, να εισαγάγετε το σημειωματάριο στον χώρο εργασίας σας.
Εάν προτιμάτε να αντιγράψετε και να επικολλήσετε τον κώδικα από αυτήν τη σελίδα, μπορείτε να δημιουργήσετε ένα νέο σημειωματάριο.
Βεβαιωθείτε ότι επισυνάψετε μια λίμνη στο σημειωματάριο προτού ξεκινήσετε την εκτέλεση κώδικα.
Βήμα 1: Εγκατάσταση προσαρμοσμένων βιβλιοθηκών
Για την ανάπτυξη μοντέλου εκμάθησης μηχανής ή την ανάλυση δεδομένων ad-hoc, ίσως χρειαστεί να εγκαταστήσετε γρήγορα μια προσαρμοσμένη βιβλιοθήκη για την περίοδο λειτουργίας Apache Spark. Έχετε δύο επιλογές για την εγκατάσταση βιβλιοθηκών.
- Χρησιμοποιήστε τις δυνατότητες ενσωματωμένης εγκατάστασης (
%pipή%conda) του σημειωματάριού σας για να εγκαταστήσετε μια βιβλιοθήκη, μόνο στο τρέχον σημειωματάριό σας. - Εναλλακτικά, μπορείτε να δημιουργήσετε ένα περιβάλλον Fabric, να εγκαταστήσετε βιβλιοθήκες από δημόσιες προελεύσεις ή να αποστείλετε προσαρμοσμένες βιβλιοθήκες σε αυτό και, στη συνέχεια, ο διαχειριστής του χώρου εργασίας σας μπορεί να συνδέσει το περιβάλλον ως προεπιλογή για τον χώρο εργασίας. Στη συνέχεια, όλες οι βιβλιοθήκες στο περιβάλλον θα γίνουν διαθέσιμες για χρήση σε οποιαδήποτε σημειωματάρια και ορισμούς εργασίας Spark στον χώρο εργασίας. Για περισσότερες πληροφορίες σχετικά με τα περιβάλλοντα, ανατρέξτε στο θέμα δημιουργία, ρύθμιση παραμέτρων και χρήση περιβάλλοντος στο Microsoft Fabric.
Για αυτή την εκμάθηση, χρησιμοποιήστε %pip install για να εγκαταστήσετε τη βιβλιοθήκη imblearn στο σημειωματάριό σας.
Σημείωση
Ο πυρήνας του PySpark επανεκκινείται μετά την %pip install εκτελέσεων. Εγκαταστήστε τις απαραίτητες βιβλιοθήκες πριν εκτελέσετε οποιαδήποτε άλλα κελιά.
# Use pip to install libraries
%pip install imblearn
Βήμα 2: Φόρτωση των δεδομένων
Το σύνολο δεδομένων σε churn.csv περιέχει την κατάσταση απώλειας 10.000 πελατών, μαζί με 14 χαρακτηριστικά που περιλαμβάνουν:
- Πιστωτικό αποτέλεσμα
- Γεωγραφική θέση (Γερμανία, Γαλλία, Ισπανία)
- Φύλο (άνδρας, γυναίκα)
- Ηλικία
- Διάρκεια (αριθμός ετών που το άτομο ήταν πελάτης στη συγκεκριμένη τράπεζα)
- Υπόλοιπο λογαριασμού
- Εκτιμώμενος μισθός
- Ο αριθμός των προϊόντων που αγόρασε ένας πελάτης μέσω της τράπεζας
- Κατάσταση πιστωτικής κάρτας (είτε ένας πελάτης διαθέτει πιστωτική κάρτα είτε όχι)
- Κατάσταση ενεργού μέλους (είτε το άτομο είναι ενεργός πελάτης τράπεζας είτε όχι)
Το σύνολο δεδομένων περιλαμβάνει επίσης τον αριθμό γραμμής, το αναγνωριστικό πελάτη και τις στήλες επωνύμου πελάτη. Οι τιμές σε αυτές τις στήλες δεν θα πρέπει να επηρεάζουν την απόφαση ενός πελάτη να αποχωρήσει από την τράπεζα.
Ένα συμβάν κλεισίματος τραπεζικού λογαριασμού πελάτη ορίζει την απώλεια για τον συγκεκριμένο πελάτη. Το σύνολο δεδομένων Exited στήλη αναφέρεται στην εγκατάλειψη του πελάτη. Δεδομένου ότι έχουμε λίγα στοιχεία σχετικά με αυτά τα χαρακτηριστικά, δεν χρειαζόμαστε πληροφορίες ιστορικού σχετικά με το σύνολο δεδομένων. Θέλουμε να κατανοήσουμε τον τρόπο με τον οποίο αυτά τα χαρακτηριστικά συμβάλλουν στην κατάσταση Exited.
Από αυτούς τους 10.000 πελάτες, μόνο οι πελάτες του 2037 (περίπου 20%) εγκατέλειψαν την τράπεζα. Λόγω της αναλογίας ανισορροπίας κλάσης, συνιστούμε τη δημιουργία συνθετικών δεδομένων. Η ακρίβεια μήτρας σύγχυσης μπορεί να μην έχει σημασία για την μη ισορροπημένη ταξινόμηση. Μπορεί να θέλουμε να μετρήσουμε την ακρίβεια χρησιμοποιώντας την Περιοχή κάτω από την καμπύλη Precision-Recall (AUPRC).
- Αυτός ο πίνακας εμφανίζει μια προεπισκόπηση των
churn.csvδεδομένων:
| Αναγνωριστικό πελάτη | Επώνυμο | CreditScore | Γεωγραφία | Γένος | Ηλικία | Κατοχή | Ισορροπία | NumOfProducts | HasCrCard | IsActiveMember | Εκτιμώμενεςπριστικές | Αποχώρησε |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Χάργκρεϊβ | 619 | Γαλλία | Θηλυκός | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Λόφος | 608 | Ισπανία | Θηλυκός | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Λήψη του συνόλου δεδομένων και αποστολή στο lakehouse
Καθορίστε αυτές τις παραμέτρους, ώστε να μπορείτε να χρησιμοποιήσετε αυτό το σημειωματάριο με διαφορετικά σύνολα δεδομένων:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Αυτός ο κώδικας κάνει λήψη μιας δημόσια διαθέσιμης έκδοσης του συνόλου δεδομένων και, στη συνέχεια, αποθηκεύει αυτό το σύνολο δεδομένων σε μια λίμνη Fabric:
Σημαντικός
Προσθέστε ένα lakehouse στο σημειωματάριο πριν το εκτελέσετε. Εάν δεν το κάνετε αυτό, θα παρουσιαστεί σφάλμα.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Ξεκινήστε την εγγραφή του χρόνου που απαιτείται για την εκτέλεση του σημειωματάριου:
# Record the notebook running time
import time
ts = time.time()
Ανάγνωση ανεπεξέργαστων δεδομένων από το lakehouse
Αυτός ο κώδικας διαβάζει ανεπεξέργαστα δεδομένα από την ενότητα Files του lakehouse και προσθέτει περισσότερες στήλες για διαφορετικά τμήματα ημερομηνίας. Η δημιουργία του διαμετμηισμένου πίνακα δέλτα χρησιμοποιεί αυτές τις πληροφορίες.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Δημιουργία dataFrame pandas από το σύνολο δεδομένων
Αυτός ο κώδικας μετατρέπει το Spark DataFrame σε ένα dataFrame pandas, για ευκολότερη επεξεργασία και απεικόνιση:
df = df.toPandas()
Βήμα 3: Εκτέλεση διερευνητικής ανάλυσης δεδομένων
Εμφάνιση ανεπεξέργαστων δεδομένων
Εξερευνήστε τα ανεπεξέργαστα δεδομένα με display, υπολογίστε ορισμένα βασικά στατιστικά στοιχεία και εμφανίστε προβολές γραφημάτων. Πρέπει πρώτα να εισαγάγετε τις απαιτούμενες βιβλιοθήκες για την απεικόνιση δεδομένων - για παράδειγμα, θαλάσσιες. Το Seaborn είναι μια βιβλιοθήκη απεικονίσεων δεδομένων Python και παρέχει μια διασύνδεση υψηλού επιπέδου για τη δημιουργία απεικονίσεων σε πλαίσια δεδομένων και πίνακες.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Χρήση του Data Wrangler για την εκτέλεση αρχικής εκκαθάρισης δεδομένων
Εκκινήστε το Data Wrangler απευθείας από το σημειωματάριο για να εξερευνήσετε και να μετασχηματίστε πλαίσια δεδομένων pandas. Επιλέξτε την αναπτυσσόμενη λίστα Data Wrangler από την οριζόντια γραμμή εργαλείων για να περιηγηθείτε στα ενεργοποιημένα dataFrames pandas που είναι διαθέσιμα για επεξεργασία. Επιλέξτε το DataFrame που θέλετε να ανοίξετε στο Data Wrangler.
Σημείωση
Δεν είναι δυνατό το άνοιγμα του Data Wrangler, ενώ ο πυρήνας σημειωματάριου είναι απασχολημένος. Η εκτέλεση του κελιού πρέπει να ολοκληρωθεί πριν εκκινήσετε το Data Wrangler. Μάθετε περισσότερα σχετικά με το data Wrangler.

Μετά την εκκίνηση του Data Wrangler, δημιουργείται μια περιγραφική επισκόπηση του πίνακα δεδομένων, όπως φαίνεται στις παρακάτω εικόνες. Η επισκόπηση περιλαμβάνει πληροφορίες σχετικά με τη διάσταση του DataFrame, τυχόν τιμές που λείπουν κ.λπ. Μπορείτε να χρησιμοποιήσετε το Data Wrangler για να δημιουργήσετε τη δέσμη ενεργειών για να αποθέσετε τις γραμμές με τιμές που απουσιάζουν, τις διπλότυπες γραμμές και τις στήλες με συγκεκριμένα ονόματα. Στη συνέχεια, μπορείτε να αντιγράψετε τη δέσμη ενεργειών σε ένα κελί. Το επόμενο κελί εμφανίζει τη δέσμη ενεργειών που αντιγράψατε.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Προσδιορισμός χαρακτηριστικών
Αυτός ο κώδικας προσδιορίζει τα χαρακτηριστικά κατηγορίας, αριθμών και προορισμού:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Εμφάνιση της σύνοψης πέντε αριθμών
Χρήση σχεδίων πλαισίων για εμφάνιση της σύνοψης πέντε αριθμών
- η ελάχιστη βαθμολογία
- πρώτο τεταρτημόριο
- διάμεσος
- τρίτο τεταρτημόριο
- μέγιστη βαθμολογία
για τα αριθμητικά χαρακτηριστικά.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
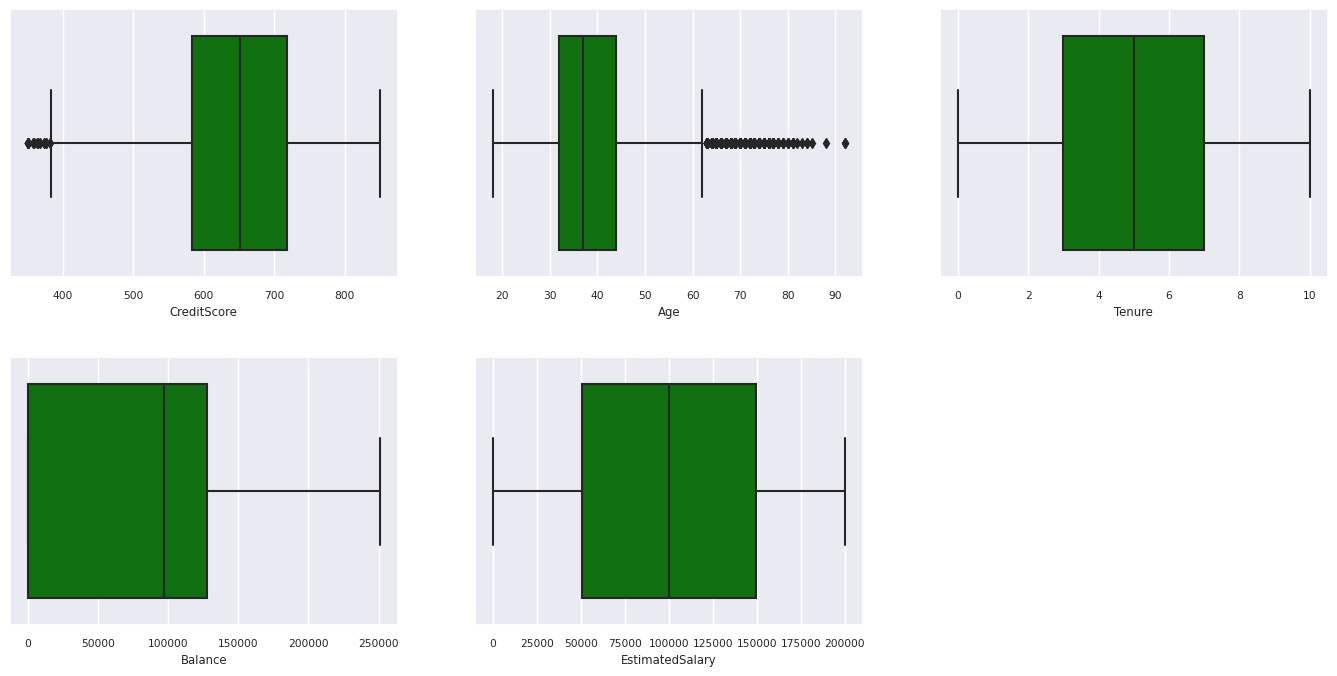
Εμφάνιση της κατανομής των πελατών που έχουν εξέλθει και δεν έχουν εξέλθει
Εμφάνιση της κατανομής των εξόδων έναντι των πελατών που δεν έχουν εξέλθει, σε όλα τα κατηγορικά χαρακτηριστικά:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
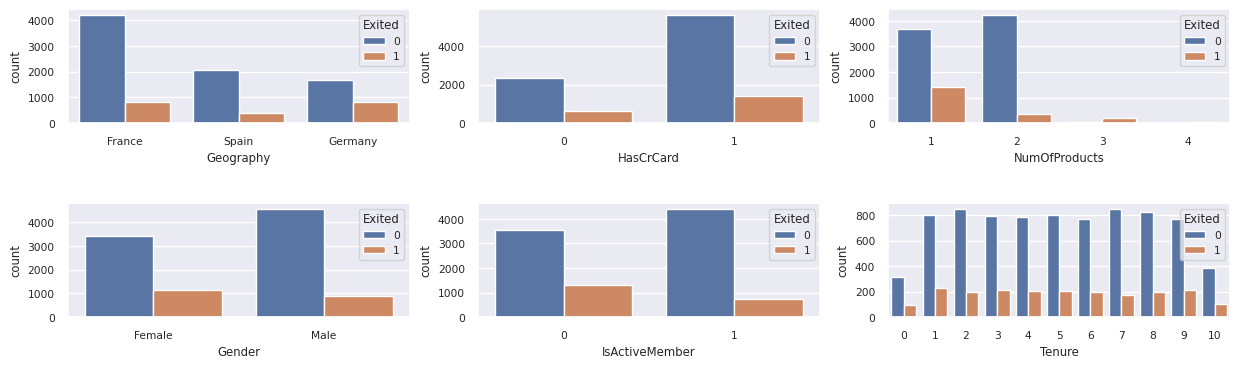
Εμφάνιση της κατανομής αριθμητικών χαρακτηριστικών
Χρησιμοποιήστε ένα ιστόγραμμα για να εμφανίσετε την κατανομή συχνότητας των αριθμητικών χαρακτηριστικών:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
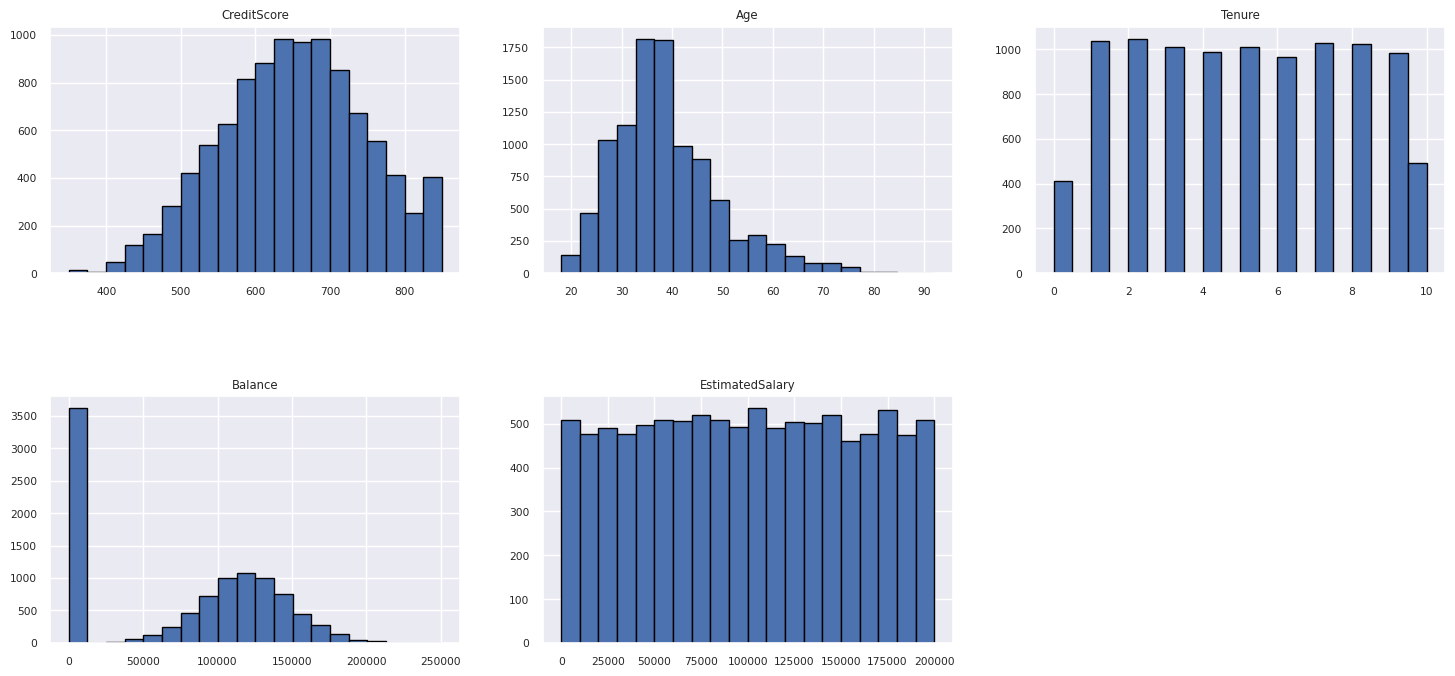
Εκτέλεση μηχανικής δυνατοτήτων
Αυτή η μηχανική δυνατοτήτων δημιουργεί νέα χαρακτηριστικά με βάση τα τρέχοντα χαρακτηριστικά:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Χρήση του Data Wrangler για εκτέλεση κωδικοποίησης μίας χρήσης
Με τα ίδια βήματα για την εκκίνηση του Data Wrangler, όπως αναφέρθηκε παραπάνω, χρησιμοποιήστε το Data Wrangler για να εκτελέσετε κωδικοποίηση μίας χρήσης. Αυτό το κελί εμφανίζει τη δέσμη ενεργειών που δημιουργήθηκε για κωδικοποίηση μίας ώρας:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Δημιουργία πίνακα δέλτα για τη δημιουργία της αναφοράς Power BI
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Σύνοψη παρατηρήσεων από την διερευνητική ανάλυση δεδομένων
- Οι περισσότεροι πελάτες είναι από τη Γαλλία. Η Ισπανία έχει το χαμηλότερο ποσοστό απώλειας, σε σύγκριση με τη Γαλλία και τη Γερμανία.
- Οι περισσότεροι πελάτες έχουν πιστωτικές κάρτες
- Ορισμένοι πελάτες είναι άνω των 60 ετών και έχουν πιστωτικά αποτελέσματα κάτω από 400. Ωστόσο, δεν μπορούν να θεωρηθούν ως έκτοπα
- Πολύ λίγοι πελάτες έχουν περισσότερα από δύο τραπεζικά προϊόντα
- Οι ανενεργοί πελάτες έχουν υψηλότερο ποσοστό απώλειας
- Το φύλο και τα έτη θητείας έχουν μικρό αντίκτυπο στην απόφαση ενός πελάτη να κλείσει έναν τραπεζικό λογαριασμό
Βήμα 4: Εκτέλεση εκπαίδευσης και παρακολούθησης μοντέλου
Έχοντας τα δεδομένα έτοιμα, μπορείτε τώρα να ορίσετε το μοντέλο. Εφαρμογή τυχαίων μοντέλων δασών και lightGBM σε αυτό το σημειωματάριο.
Χρησιμοποιήστε τις βιβλιοθήκες scikit-learn και LightGBM για να υλοποιήσετε τα μοντέλα, με μερικές γραμμές κώδικα. Επιπλέον, χρησιμοποιήστε τα MLfLow και Fabric Autologging για να παρακολουθήσετε τα πειράματα.
Αυτό το δείγμα κώδικα φορτώνει τον πίνακα δέλτα από το lakehouse. Μπορείτε να χρησιμοποιήσετε άλλους πίνακες δέλτα που χρησιμοποιούν οι ίδιοι το lakehouse ως προέλευση.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Δημιουργία πειράματος για την παρακολούθηση και καταγραφή των μοντέλων με χρήση MLflow
Αυτή η ενότητα παρουσιάζει τον τρόπο δημιουργίας ενός πειράματος και καθορίζει τις παραμέτρους μοντέλου και εκπαίδευσης και τα μετρικά βαθμολόγησης. Επιπλέον, δείχνει πώς μπορείτε να εκπαιδεύσετε τα μοντέλα, να τα καταγράψετε και να αποθηκεύσετε τα εκπαιδευμένα μοντέλα για μελλοντική χρήση.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Η αυτόματη καταγραφή καταγράφει αυτόματα τις τιμές παραμέτρων εισόδου και τα μετρικά εξόδου ενός μοντέλου εκμάθησης μηχανής, καθώς αυτό το μοντέλο εκπαιδεύεται. Στη συνέχεια, αυτές οι πληροφορίες καταγράφονται στον χώρο εργασίας σας, όπου τα API MLflow ή το αντίστοιχο πείραμα στον χώρο εργασίας σας μπορούν να έχουν πρόσβαση και να τα απεικονίζουν.
Όταν ολοκληρωθεί, το πείραμά σας μοιάζει με αυτή την εικόνα:

Καταγράφονται όλα τα πειράματα με τα αντίστοιχα ονόματά τους και μπορείτε να παρακολουθείτε τις παραμέτρους και τα μετρικά απόδοσης. Για να μάθετε περισσότερα σχετικά με την αυτόματη καταχώρηση, ανατρέξτε στο θέμα Αυτόματη καταχώρηση στο Microsoft Fabric.
Ορισμός προδιαγραφών πειραμάτων και αυτόματης καταχώρησης σε αρχεία
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Εισαγωγή scikit-learn και LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Προετοιμασία συνόλων δεδομένων εκπαίδευσης και δοκιμής
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Εφαρμογή SMOTE στα δεδομένα εκπαίδευσης
Η μη ισορροπημένη ταξινόμηση έχει ένα πρόβλημα, επειδή έχει πολύ λίγα παραδείγματα της μειονοτικής κλάσης για ένα μοντέλο για να μάθει αποτελεσματικά το όριο απόφασης. Για να το χειριστούμε αυτό, η Τεχνική Υπερπτήσεων Συνθετικής Μειονότητας (SMOTE) είναι η πιο ευρέως χρησιμοποιούμενη τεχνική για τη σύνθεση νέων δειγμάτων για την κλάση μειονότητας. Αποκτήστε πρόσβαση στο SMOTE με τη βιβλιοθήκη imblearn που εγκαταστήσατε στο βήμα 1.
Εφαρμόστε το SMOTE μόνο στο σύνολο δεδομένων εκπαίδευσης. Πρέπει να αφήσετε το σύνολο δεδομένων δοκιμής στην αρχική μη ισορροπημένη κατανομή του, για να λάβετε μια έγκυρη προσέγγιση των επιδόσεων του μοντέλου με τα αρχικά δεδομένα. Αυτό το πείραμα αντιπροσωπεύει την κατάσταση στην παραγωγή.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Για περισσότερες πληροφορίες, ανατρέξτε στα θέματα SMOTE και Από τυχαία υπερβολική δειγματοληψία σε SMOTE και ADASYN. Η τοποθεσία web μη ισορροπημένης εκμάθησης φιλοξενεί αυτούς τους πόρους.
Εκπαίδευση του μοντέλου
Χρησιμοποιήστε το Random Forest για να εκπαιδεύσετε το μοντέλο με μέγιστο βάθος τεσσάρων, καθώς και τέσσερις δυνατότητες:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Χρησιμοποιήστε το Random Forest για να εκπαιδεύσετε το μοντέλο με μέγιστο βάθος οκτώ και έξι δυνατότητες:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Εκπαίδευση του μοντέλου με το LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Προβολή του τεχνουργήματος πειράματος για την παρακολούθηση των επιδόσεων του μοντέλου
Οι εκτελέσεις του πειράματος αποθηκεύονται αυτόματα στο αντικείμενο σχεδίασης πειράματος. Μπορείτε να βρείτε αυτό το αντικείμενο σχεδίασης στον χώρο εργασίας. Ένα όνομα τεχνουργήματος βασίζεται στο όνομα που χρησιμοποιείται για τον ορισμό του πειράματος. Όλα τα εκπαιδευμένα μοντέλα, οι εκτελέσεις τους, τα μετρικά επιδόσεων και οι παράμετροι μοντέλου καταγράφονται στη σελίδα πειράματος.
Για να δείτε τα πειράματά σας:
- Στον αριστερό πίνακα, επιλέξτε τον χώρο εργασίας σας.
- Βρείτε και επιλέξτε το όνομα του πειράματος, σε αυτή την περίπτωση, δείγμα-τράπεζας-απώλειας-πειράματος.
Βήμα 5: Αξιολόγηση και αποθήκευση του τελικού μοντέλου εκμάθησης μηχανής
Ανοίξτε το αποθηκευμένο πείραμα από τον χώρο εργασίας για να επιλέξετε και να αποθηκεύσετε το καλύτερο μοντέλο:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Αξιολόγηση των επιδόσεων των αποθηκευμένων μοντέλων στο σύνολο δεδομένων δοκιμής
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Εμφάνιση αληθώς/ψευδώς θετικών/αρνητικών χρησιμοποιώντας έναν πίνακα σύγχυσης
Για να αξιολογήσετε την ακρίβεια της ταξινόμησης, δημιουργήστε μια δέσμη ενεργειών που σχεδιάζει τη μήτρα σύγχυσης. Μπορείτε επίσης να σχεδιάσετε μια μήτρα σύγχυσης χρησιμοποιώντας εργαλεία SynapseML, όπως φαίνεται στο δείγμα εντοπισμού απάτης .
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
Δημιουργήστε μια μήτρα σύγχυσης για τον τυχαίο αλγόριθμο ταξινόμησης δασών, με μέγιστο βάθος τεσσάρων, με τέσσερις δυνατότητες:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
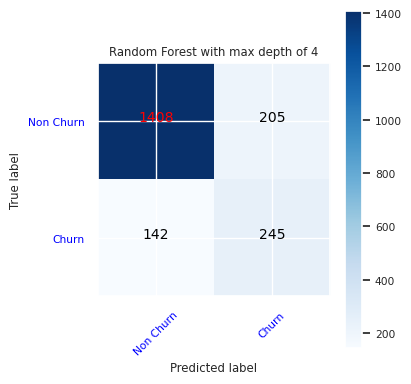
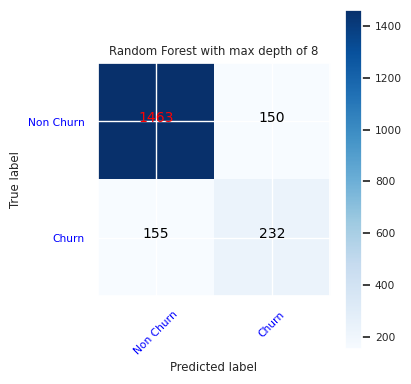
Δημιουργήστε μια μήτρα σύγχυσης για τον τυχαίο αλγόριθμο ταξινόμησης δασών με μέγιστο βάθος οκτώ, με έξι δυνατότητες:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
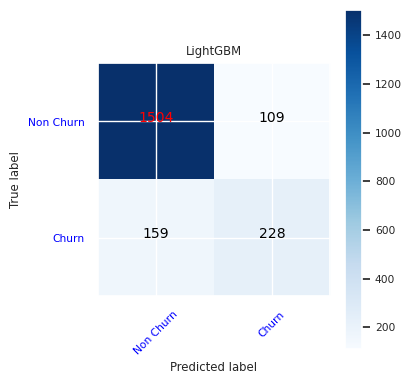
Δημιουργήστε μια μήτρα σύγχυσης για το LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Αποθήκευση αποτελεσμάτων για το Power BI
Αποθηκεύστε το πλαίσιο δέλτα στη λίμνη, για να μετακινήσετε τα αποτελέσματα πρόβλεψης μοντέλου σε μια απεικόνιση Power BI.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Βήμα 6: Πρόσβαση σε απεικονίσεις στο Power BI
Πρόσβαση στον αποθηκευμένο πίνακά σας στο Power BI:
- Στην αριστερή πλευρά, επιλέξτε OneLake.
- Επιλέξτε τη λίμνη που προσθέσατε σε αυτό το σημειωματάριο.
- Στην ενότητα Άνοιγμα αυτού του Lakehouse, επιλέξτε Άνοιγμα.
- Στην κορδέλα, επιλέξτε νέο μοντέλο σημασιολογίας. Επιλέξτε
df_pred_resultsκαι, στη συνέχεια, επιλέξτε Επιβεβαίωση για να δημιουργήσετε ένα νέο σημασιολογικό μοντέλο Power BI που συνδέεται με τις προβλέψεις. - Ανοίξτε το νέο μοντέλο σημασιολογίας. Μπορείτε να το βρείτε στο OneLake.
- Επιλέξτε Δημιουργία νέας αναφοράς στην περιοχή αρχείο από τα εργαλεία στο επάνω μέρος της σελίδας σημασιολογικών μοντέλων, για να ανοίξετε τη σελίδα σύνταξης αναφορών Power BI.
Το παρακάτω στιγμιότυπο οθόνης εμφανίζει ορισμένα παραδείγματα απεικονίσεων. Ο πίνακας δεδομένων εμφανίζει τους πίνακες και τις στήλες δέλτα για επιλογή από έναν πίνακα. Μετά την επιλογή της κατάλληλης κατηγορίας (x) και του άξονα τιμής (y), μπορείτε να επιλέξετε τα φίλτρα και τις συναρτήσεις , για παράδειγμα, άθροισμα ή μέσος όρος της στήλης πίνακα.
Σημείωση
Σε αυτό το στιγμιότυπο οθόνης, το εικονογραφημένο παράδειγμα περιγράφει την ανάλυση των αποθηκευμένων αποτελεσμάτων πρόβλεψης στο Power BI:

Ωστόσο, για μια πραγματική υπόθεση χρήσης που χάνονται από τους πελάτες, ο χρήστης μπορεί να χρειαστεί ένα πιο εμπεριστατωμένη σειρά απαιτήσεων για τις απεικονίσεις για τη δημιουργία, με βάση τις γνώσεις επί του θέματος, καθώς και τι έχουν τυποποιήσει η ομάδα και η εταιρεία εταιρικών αναλύσεων ως μετρικά.
Η αναφορά Power BI δείχνει ότι οι πελάτες που χρησιμοποιούν περισσότερα από δύο από τα προϊόντα της τράπεζας έχουν υψηλότερο ποσοστό απώλειας. Ωστόσο, λίγοι πελάτες είχαν περισσότερα από δύο προϊόντα. (Δείτε τη σχεδίαση στον κάτω αριστερό πίνακα.) Η τράπεζα θα πρέπει να συλλέγει περισσότερα δεδομένα, αλλά θα πρέπει επίσης να διερευνά άλλες δυνατότητες που συσχετίζονται με περισσότερα προϊόντα.
Οι πελάτες τραπεζών στη Γερμανία έχουν υψηλότερο ποσοστό απώλειας σε σύγκριση με τους πελάτες στη Γαλλία και την Ισπανία. (Δείτε τη σχεδίαση στον κάτω δεξιό πίνακα). Με βάση τα αποτελέσματα της αναφοράς, μια έρευνα σχετικά με τους παράγοντες που ενθάρρυναν τους πελάτες να αποχωρήσουν μπορεί να βοηθήσει.
Υπάρχουν περισσότεροι μεσήλικες πελάτες (μεταξύ 25 και 45). Οι πελάτες μεταξύ 45 και 60 τείνουν να εξέρχονται περισσότερο.
Τέλος, οι πελάτες με χαμηλότερα πιστωτικά αποτελέσματα πιθανότατα θα αποχωρήσουν από την τράπεζα για άλλα χρηματοπιστωτικά ιδρύματα. Η τράπεζα θα πρέπει να διερευνήσει τρόπους για να ενθαρρύνει τους πελάτες με χαμηλότερα πιστωτικά αποτελέσματα και υπόλοιπα λογαριασμών να παραμείνουν στην τράπεζα.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")
Σχετικό περιεχόμενο
- μοντέλο εκμάθησης μηχανής στο Microsoft Fabric
- Εκπαίδευση μοντέλων εκμάθησης μηχανής
- πειράματα εκμάθησης μηχανής στο Microsoft Fabric