Εκμάθηση Lakehouse: Προετοιμασία και μετασχηματισμός δεδομένων στο lakehouse
Σε αυτή την εκμάθηση, χρησιμοποιείτε σημειωματάρια με χρόνο εκτέλεσης Spark για να μετασχηματίζετε και να προετοιμάζετε ανεπεξέργαστα δεδομένα στο lakehouse σας.
Προαπαιτούμενα στοιχεία
Εάν δεν έχετε ένα lakehouse που περιέχει δεδομένα, πρέπει:
Προετοιμασία δεδομένων
Από τα προηγούμενα βήματα εκμάθησης, έχουμε ανεπεξέργαστα δεδομένα που έχουν προσδεθεί από την προέλευση μέχρι το τμήμα Αρχεία του lakehouse. Τώρα μπορείτε να μετασχηματίζετε αυτά τα δεδομένα και να τα προετοιμάζετε για τη δημιουργία πινάκων Delta.
Κάντε λήψη των σημειωματάριων από τον φάκελο Πηγαίος κώδικας εκμάθησης Lakehouse.
Από τον χώρο εργασίας, επιλέξτε Εισαγωγή>Σημειωματάριο>Από αυτόν τον υπολογιστή.
Επιλέξτε Εισαγωγή σημειωματάριου από την ενότητα Δημιουργία στο επάνω μέρος της σελίδας προορισμού.
Επιλέξτε Αποστολή από το τμήμα παραθύρου Κατάσταση εισαγωγής που ανοίγει στη δεξιά πλευρά της οθόνης.
Επιλέξτε όλα τα σημειωματάρια που έχετε λάβει στο πρώτο βήμα αυτής της ενότητας.
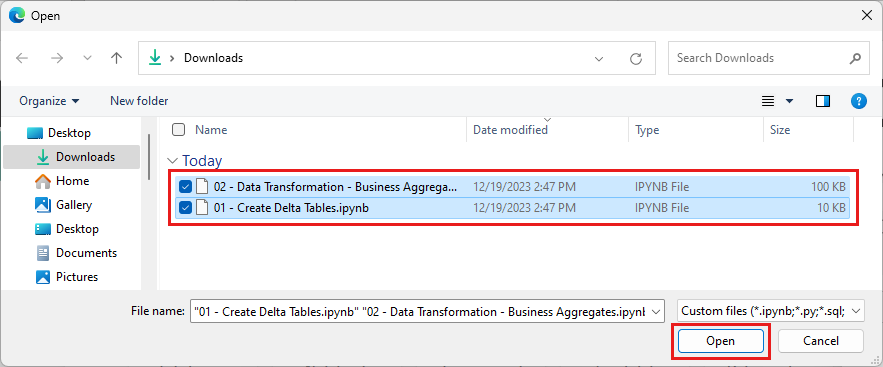
Επιλέξτε Άνοιγμα. Μια ειδοποίηση που υποδεικνύει την κατάσταση της εισαγωγής εμφανίζεται στην επάνω δεξιά γωνία του παραθύρου του προγράμματος περιήγησης.
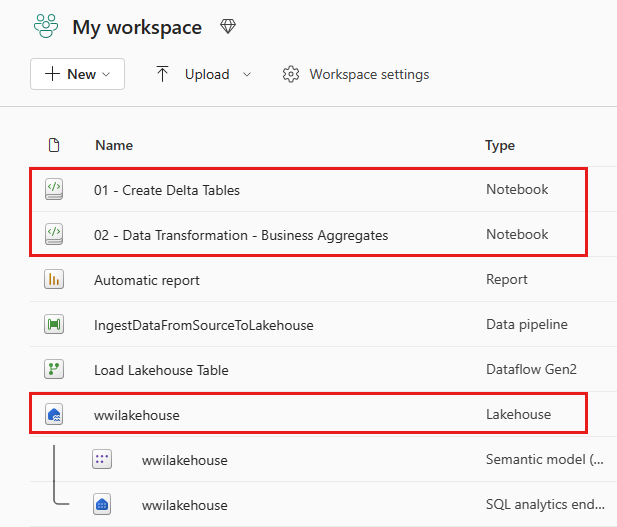
Μετά την επιτυχή εισαγωγή, μεταβείτε στην προβολή στοιχείων του χώρου εργασίας και δείτε τα σημειωματάρια που εισαγάγαν πρόσφατα. Επιλέξτε μια λίμνη wwilakehouse για να την ανοίξετε.
Μόλις ανοίξει η λίμνη wwilakehouse, επιλέξτε > από το επάνω μενού περιήγησης.
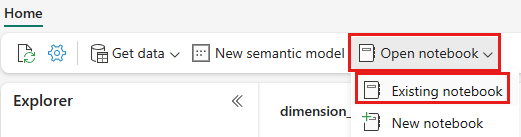
Από τη λίστα των υπαρχόντων σημειωματάριων, επιλέξτε το σημειωματάριο 01 - Δημιουργία πινάκων Delta και επιλέξτε Άνοιγμα.
Στο ανοικτό σημειωματάριο στην Εξερεύνηση λιμνών, βλέπετε ότι το σημειωματάριο είναι ήδη συνδεδεμένο με την ανοιχτή λίμνη σας.
Σημείωμα
Το Fabric παρέχει τη δυνατότητα V-order για τη σύνταξη βελτιστοποιημένων αρχείων λίμνης Delta. Η σειρά V συχνά βελτιώνει τη συμπίεση κατά τρεις έως τέσσερις φορές και έως και 10 φορές την επιτάχυνση των επιδόσεων στα αρχεία Delta Lake που δεν έχουν βελτιστοποιηθεί. Το Spark στο Fabric βελτιστοποιεί δυναμικά τα διαμερίσματα κατά τη δημιουργία αρχείων με προεπιλεγμένο μέγεθος 128 MB. Το μέγεθος του αρχείου προορισμού μπορεί να αλλάξει ανά φόρτο εργασίας χρησιμοποιώντας ρυθμίσεις παραμέτρων.
Με τη δυνατότητα βελτιστοποίησης εγγραφής , ο μηχανισμός Apache Spark μειώνει τον αριθμό των αρχείων που έχουν συνταχθεί και στοχεύει στην αύξηση του μεμονωμένου μεγέθους αρχείων των γραπτών δεδομένων.
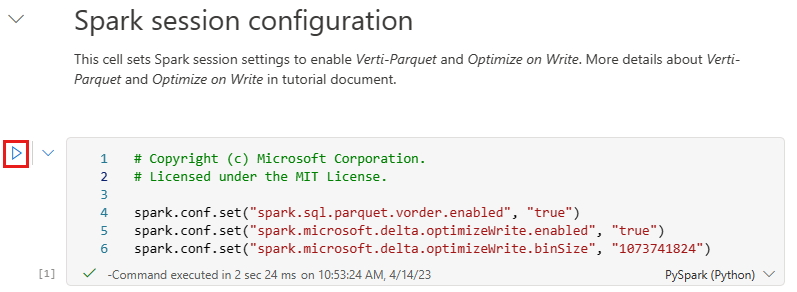
Πριν από την εγγραφή δεδομένων ως πίνακες της λίμνης Delta στο τμήμα Πίνακες του lakehouse, χρησιμοποιείτε δύο δυνατότητες Fabric (V-order και Βελτιστοποίηση εγγραφής) για βελτιστοποιημένη εγγραφή δεδομένων και για βελτιωμένη απόδοση ανάγνωσης. Για να ενεργοποιήσετε αυτές τις δυνατότητες στην περίοδο λειτουργίας σας, ορίστε αυτές τις ρυθμίσεις στο πρώτο κελί του σημειωματάριού σας.
Για να ξεκινήσετε το σημειωματάριο και να εκτελέσετε όλα τα κελιά με τη σειρά, επιλέξτε Εκτέλεση όλων στην επάνω κορδέλα (στην Αρχική σελίδα). Εναλλακτικά, για να εκτελέσετε κώδικα μόνο από ένα συγκεκριμένο κελί, επιλέξτε το εικονίδιο Εκτέλεση που εμφανίζεται στα αριστερά του κελιού κατά την κατάδειξη ή πατήστε SHIFT + ENTER στο πληκτρολόγιό σας ενώ το στοιχείο ελέγχου βρίσκεται στο κελί.
Κατά την εκτέλεση ενός κελιού, δεν χρειαζόταν να καθορίσετε τον υποκείμενο χώρο συγκέντρωσης Spark ή λεπτομέρειες του συμπλέγματος, επειδή το Fabric τα παρέχει μέσω του Live Pool. Κάθε χώρος εργασίας Fabric παρέχεται με μια προεπιλεγμένη ομάδα Spark, που ονομάζεται Live Pool. Αυτό σημαίνει ότι όταν δημιουργείτε σημειωματάρια, δεν χρειάζεται να ανησυχείτε για τον καθορισμό τυχόν ρυθμίσεων παραμέτρων Spark ή λεπτομερειών συμπλέγματος. Όταν εκτελείτε την πρώτη εντολή σημειωματάριου, ο χώρος συγκέντρωσης είναι σε λειτουργία σε λίγα δευτερόλεπτα. Επίσης, δημιουργείται η περίοδος λειτουργίας Spark και ξεκινά την εκτέλεση του κώδικα. Η επόμενη εκτέλεση κώδικα είναι σχεδόν άμεση σε αυτό το σημειωματάριο, ενώ η περίοδος λειτουργίας Spark είναι ενεργή.
Στη συνέχεια, διαβάσατε ανεπεξέργαστα δεδομένα από την ενότητα Αρχεία της λίμνης και προσθέσατε περισσότερες στήλες για διαφορετικά τμήματα ημερομηνίας ως μέρος του μετασχηματισμού. Τέλος, χρησιμοποιείτε το διαμέρισμα Από το Spark API για να διαμερίζετε τα δεδομένα πριν από την εγγραφή τους ως μορφή πίνακα Delta με βάση τις στήλες των τμημάτων δεδομένων που μόλις δημιουργήθηκαν (Έτος και Τρίμηνο).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Μετά τη φόρτωση των πινάκων δεδομένων, μπορείτε να προχωρήσετε στη φόρτωση δεδομένων για τις υπόλοιπες διαστάσεις. Το ακόλουθο κελί δημιουργεί μια συνάρτηση για την ανάγνωση ανεπεξέργαστων δεδομένων από την ενότητα Αρχεία του lakehouse για καθένα από τα ονόματα πινάκων που μεταβιβάζονται ως παράμετρος. Στη συνέχεια, δημιουργεί μια λίστα πινάκων διαστάσεων. Τέλος, περιηγεί τη λίστα πινάκων και δημιουργεί έναν πίνακα Delta για κάθε όνομα πίνακα που διαβάζεται από την παράμετρο εισόδου. Σημειώστε ότι η δέσμη ενεργειών απορρίπτει τη στήλη που ονομάζεται
Photoσε αυτό το παράδειγμα, επειδή η στήλη δεν χρησιμοποιείται.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Για να επικυρώσετε τους πίνακες που δημιουργήθηκαν, κάντε δεξί κλικ και επιλέξτε ανανέωση στο lakehouse wwilakehouse . Εμφανίζονται οι πίνακες.
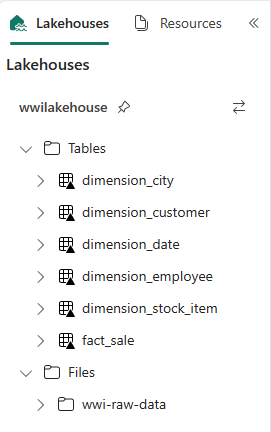
Μεταβείτε ξανά στην προβολή στοιχείων του χώρου εργασίας και επιλέξτε τη λίμνη wwilakehouse για να την ανοίξετε.
Τώρα, ανοίξτε το δεύτερο σημειωματάριο. Στην προβολή lakehouse, επιλέξτε Άνοιγμα σημειωματάριου>Υπάρχον σημειωματάριο από την κορδέλα.
Από τη λίστα των υπαρχόντων σημειωματάριων, επιλέξτε το σημειωματάριο 02 - Μετασχηματισμός δεδομένων - Επιχειρήσεις για να το ανοίξετε.
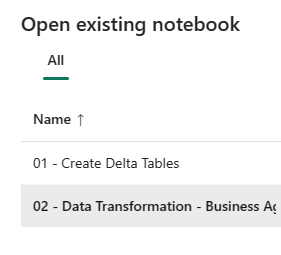
Στο ανοικτό σημειωματάριο στην Εξερεύνηση λιμνών, βλέπετε ότι το σημειωματάριο είναι ήδη συνδεδεμένο με την ανοιχτή λίμνη σας.
Ένας οργανισμός μπορεί να έχει μηχανικούς δεδομένων που εργάζονται με τη Scala/Python και άλλους μηχανικούς δεδομένων που εργάζονται με SQL (Spark SQL ή T-SQL), οι οποίο εργάζονται στο ίδιο αντίγραφο των δεδομένων. Το Fabric δίνει τη δυνατότητα σε αυτές τις διαφορετικές ομάδες, με ποικίλη εμπειρία και προτίμηση, να εργαστούν και να συνεργαστούν. Οι δύο διαφορετικές προσεγγίσεις μετασχηματίζουν και δημιουργούν επιχειρηματικά συγκεντρωτικά αποτελέσματα. Μπορείτε να επιλέξετε αυτό που είναι κατάλληλο για εσάς ή να συνδυάσετε και να αντιστοιχήσετε αυτές τις προσεγγίσεις με βάση την προτίμησή σας χωρίς να διακυβεύεται η απόδοση:
Προσέγγιση #1 - Χρησιμοποιήστε το PySpark για να ενώσετε και συγκεντρώσετε δεδομένα για τη δημιουργία επιχειρηματικών συγκεντρωτικών αποτελεσμάτων. Αυτή η προσέγγιση είναι προτιμότερη από κάποιον με εμπειρία προγραμματισμού (Python ή PySpark).
Προσέγγιση #2 - Χρησιμοποιήστε το Spark SQL για να ενώσετε και συγκεντρώσετε δεδομένα για τη δημιουργία επιχειρηματικών συγκεντρωτικών αποτελεσμάτων. Αυτή η προσέγγιση είναι προτιμότερη από κάποιον με SQL υπόβαθρο, τη μετάβαση στο Spark.
Προσέγγιση #1 (sale_by_date_city) - Χρησιμοποιήστε το PySpark για να συμμετάσχετε και να συγκεντρώσετε δεδομένα για τη δημιουργία επιχειρηματικών συγκεντρώσεων. Με τον παρακάτω κώδικα, δημιουργείτε τρία διαφορετικά πλαίσια δεδομένων Spark, κάθε ένα από τα οποία αναφέρει έναν υπάρχοντα πίνακα Delta. Στη συνέχεια, μπορείτε να ενώσετε αυτούς τους πίνακες χρησιμοποιώντας τα πλαίσια δεδομένων, να κάνετε ομαδοποίηση κατά για να δημιουργήσετε συνάθροιση, να μετονομάσετε μερικές από τις στήλες και, τέλος, να τις γράψετε ως πίνακα Delta στην ενότητα Πίνακες της λίμνης για να διατηρείτε τα δεδομένα.
Σε αυτό το κελί, δημιουργείτε τρία διαφορετικά πλαίσια δεδομένων Spark, κάθε ένα από τα οποία αναφέρει έναν υπάρχοντα πίνακα Delta.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Προσθέστε τον παρακάτω κώδικα στο ίδιο κελί για να ενώσετε αυτούς τους πίνακες χρησιμοποιώντας τα πλαίσια δεδομένων που δημιουργήθηκαν προηγουμένως. Ομαδοποιήστε κατά για να δημιουργήσετε συνάθροιση, μετονομάστε μερικές από τις στήλες και, τέλος, γράψτε τη ως πίνακα Delta στην ενότητα Πίνακες του lakehouse.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Προσέγγιση #2 (sale_by_date_employee) - Χρησιμοποιήστε το Spark SQL για να ενώσετε και να συγκεντρώσετε δεδομένα για τη δημιουργία επιχειρηματικών συγκεντρωτικών αποτελεσμάτων. Με τον παρακάτω κώδικα, δημιουργείτε μια προσωρινή προβολή Spark με τη σύνδεση τριών πινάκων, τη δυνατότητα ομαδοποίησης κατά για τη δημιουργία συνάθροισης και τη μετονομασία μερικών από τις στήλες. Τέλος, διαβάσατε από την προσωρινή προβολή Spark και τέλος την γράψατε ως πίνακα Delta στην ενότητα Πίνακες της λίμνης για να διατηρείτε τα δεδομένα.
Σε αυτό το κελί, δημιουργείτε μια προσωρινή προβολή Spark με τη σύνδεση τριών πινάκων, την ομαδοποίηση κατά για τη δημιουργία συνάθροισης και τη μετονομασία μερικών από τις στήλες.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCΣε αυτό το κελί, διαβάσατε από την προσωρινή προβολή Spark που δημιουργήθηκε στο προηγούμενο κελί και τέλος την γράφετε ως πίνακα Delta στην ενότητα Πίνακες του lakehouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Για να επικυρώσετε τους πίνακες που δημιουργήθηκαν, κάντε δεξί κλικ και επιλέξτε Ανανέωση στο lakehouse wwilakehouse . Εμφανίζονται οι πίνακες συγκεντρωτικών αποτελεσμάτων.
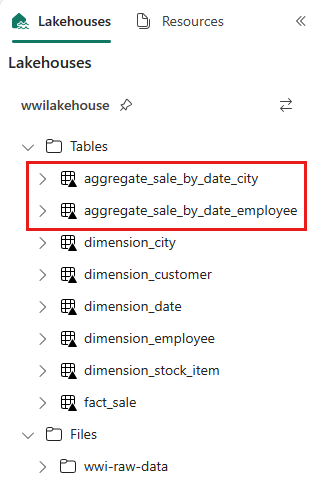
Οι δύο προσεγγίσεις παράγουν ένα παρόμοιο αποτέλεσμα. Για να ελαχιστοποιήσετε την ανάγκη να μάθετε μια νέα τεχνολογία ή συμβιβασμό σχετικά με τις επιδόσεις, επιλέξτε την προσέγγιση που ταιριάζει καλύτερα στο φόντο και τις προτιμήσεις σας.
Μπορεί να παρατηρήσετε ότι γράφετε δεδομένα ως αρχεία της λίμνης Delta. Η δυνατότητα αυτόματης ανακάλυψης και καταχώρησης πίνακα του Fabric τις παίρνει και τις καταχωρεί στο μεταστάθιμο. Δεν χρειάζεται να καλέσετε CREATE TABLE ρητά προτάσεις για να δημιουργήσετε πίνακες για χρήση με το SQL.