Μετεγκατάσταση ορισμού εργασίας Spark από Azure Synapse σε Fabric
Για να μετακινήσετε ορισμούς εργασίας Spark (SJD) από το Azure Synapse στο Fabric, έχετε δύο διαφορετικές επιλογές:
- Επιλογή 1: δημιουργήστε τον ορισμό εργασίας Spark με μη αυτόματο τρόπο στο Fabric.
- Επιλογή 2: μπορείτε να χρησιμοποιήσετε μια δέσμη ενεργειών για να εξαγάγετε ορισμούς εργασιών Spark από το Azure Synapse και να τους εισαγάγετε στο Fabric χρησιμοποιώντας το API.
Για ζητήματα ορισμού εργασίας Spark, ανατρέξτε στις διαφορές μεταξύ των Azure Synapse Spark και Fabric.
Προαπαιτούμενα στοιχεία
Εάν δεν έχετε ήδη έναν, δημιουργήστε έναν χώρο εργασίας Fabric στον μισθωτή σας.
Επιλογή 1: Δημιουργία ορισμού εργασίας Spark με μη αυτόματο τρόπο
Για να εξαγάγετε έναν ορισμό εργασίας Spark από το Azure Synapse:
- Ανοίξτε το Synapse Studio: Πραγματοποιήστε είσοδο στο Azure. Μεταβείτε στον χώρο εργασίας σας Azure Synapse και ανοίξτε το Synapse Studio.
- Εντοπίστε την εργασία Python/Scala/R Spark: Εντοπίστε και αναγνωρίστε τον ορισμό εργασίας Python/Scala/R Spark που θέλετε να μετεγκαταστήσετε.
-
Εξαγωγή της ρύθμισης παραμέτρων ορισμού εργασίας:
- Στο Synapse Studio, ανοίξτε τον ορισμό εργασίας Spark.
- Εξαγάγετε ή σημειώστε τις ρυθμίσεις παραμέτρων, συμπεριλαμβανομένης της θέσης του αρχείου δέσμης ενεργειών, των εξαρτήσεων, των παραμέτρων και οποιωνδήποτε άλλων σχετικών λεπτομερειών.
Για να δημιουργήσετε έναν νέο ορισμό εργασίας Spark (SJD) με βάση τις πληροφορίες SJD που έχουν εξαχθεί στο Fabric:
- Πρόσβαση στον χώρο εργασίας Fabric: Εισέλθετε στο Fabric και αποκτήστε πρόσβαση στον χώρο εργασίας σας.
-
Δημιουργήστε έναν νέο ορισμό εργασίας Spark στο Fabric:
- Στο Fabric, μεταβείτε στην αρχική σελίδα Της Μηχανικής δεδομένων.
- Επιλέξτε Ορισμός εργασίας Spark.
- Ρυθμίστε τις παραμέτρους της εργασίας χρησιμοποιώντας τις πληροφορίες που έχετε εξαγάγει από το Synapse, συμπεριλαμβανομένης της θέσης της δέσμης ενεργειών, των εξαρτήσεων, των παραμέτρων και των ρυθμίσεων συμπλέγματος.
- Προσαρμογή και δοκιμή: Κάντε οποιαδήποτε απαραίτητη προσαρμογή στη δέσμη ενεργειών ή τη ρύθμιση παραμέτρων για να ταιριάζει στο περιβάλλον Fabric. Δοκιμάστε την εργασία στο Fabric για να εξασφαλίσετε ότι εκτελείται σωστά.
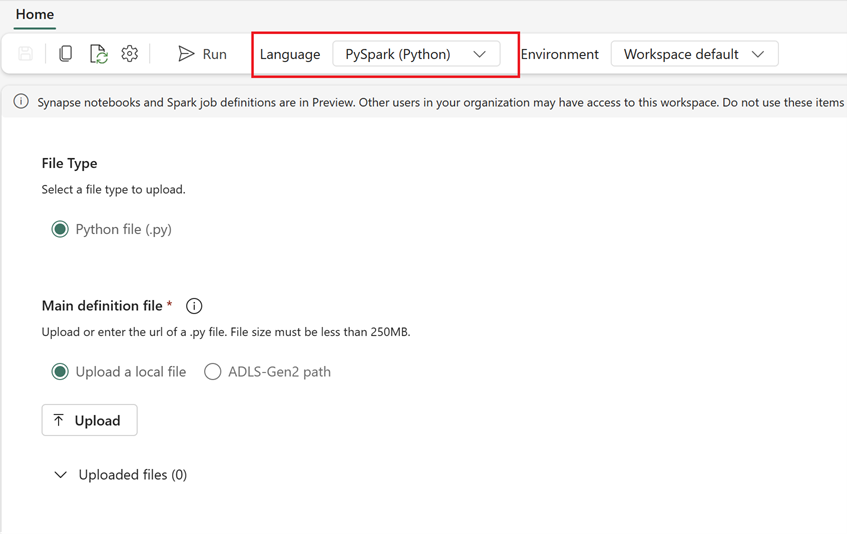
Μετά τη δημιουργία του ορισμού εργασίας Spark, επικυρώστε τις εξαρτήσεις:
- Βεβαιωθείτε ότι χρησιμοποιείτε την ίδια έκδοση Spark.
- Επαληθεύστε την ύπαρξη του αρχείου κύριου ορισμού.
- Επαληθεύστε την ύπαρξη των αρχείων, των εξαρτήσεων και των πόρων στα οποία γίνεται αναφορά.
- Συνδεδεμένες υπηρεσίες, συνδέσεις προέλευσης δεδομένων και σημεία μονταρίσματος.
Μάθετε περισσότερα σχετικά με τον τρόπο δημιουργίας ενός ορισμού εργασίας Apache Spark στο Fabric.
Επιλογή 2: Χρήση του API Fabric
Ακολουθήστε τα παρακάτω βασικά βήματα για τη μετεγκατάσταση:
- Προϋποθέσεις.
- Βήμα 1: Εξαγάγετε τον ορισμό εργασίας Spark από το Azure Synapse σε OneLake (.json).
- Βήμα 2: Εισαγάγετε αυτόματα τον ορισμό εργασίας Spark στο Fabric χρησιμοποιώντας το API Fabric.
Προαπαιτούμενα στοιχεία
Τα προαπαιτούμενα περιλαμβάνουν ενέργειες που πρέπει να εξετάσετε πριν ξεκινήσετε τη μετεγκατάσταση ορισμού εργασίας Spark στο Fabric.
- Ένας χώρος εργασίας Fabric.
- Εάν δεν έχετε ήδη ένα, δημιουργήστε μια λίμνη Fabric στον χώρο εργασίας σας.
Βήμα 1: Εξαγωγή ορισμού εργασίας Spark από τον χώρο εργασίας Azure Synapse
Το Βήμα 1 εστιάζει στην εξαγωγή του ορισμού εργασίας Spark από τον χώρο εργασίας Azure Synapse σε OneLake σε μορφή json. Αυτή η διαδικασία έχει ως εξής:
- 1.1) Εισαγάγετε σημειωματάριο μετεγκατάστασης SJD στον χώρο εργασίας Fabric . Αυτό το σημειωματάριο εξάγει όλους τους ορισμούς εργασίας Spark από έναν δεδομένο χώρο εργασίας Azure Synapse σε έναν ενδιάμεσο κατάλογο στο OneLake. Το API Synapse χρησιμοποιείται για την εξαγωγή SJD.
- 1.2) Ρυθμίστε τις παραμέτρους στην πρώτη εντολή για εξαγωγή του ορισμού εργασίας Spark σε ενδιάμεσο χώρο αποθήκευσης (OneLake). Αυτό εξάγει μόνο το αρχείο μετα-δεδομένων json. Το ακόλουθο τμήμα κώδικα χρησιμοποιείται για τη ρύθμιση των παραμέτρων προέλευσης και προορισμού. Βεβαιωθείτε ότι τις αντικαταστήσετε με τις δικές σας τιμές.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
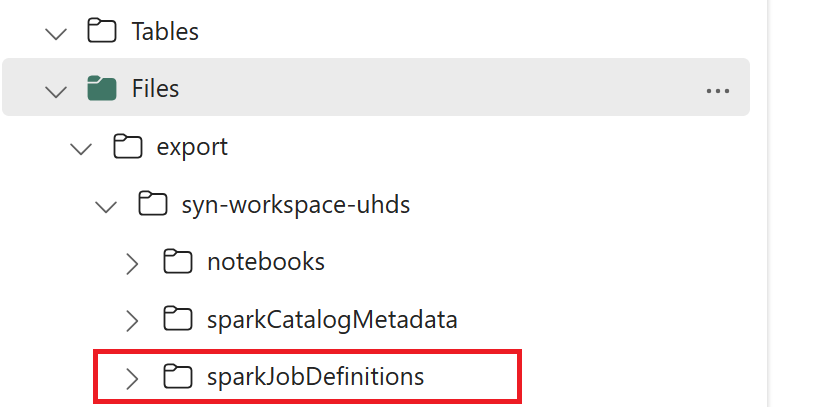
- 1.3) Εκτελέστε τα δύο πρώτα κελιά του σημειωματάριου εξαγωγής/εισαγωγής για να εξαγάγετε μετα-δεδομένα ορισμού εργασίας Spark σε OneLake. Όταν ολοκληρωθούν τα κελιά, δημιουργείται αυτή η δομή φακέλου κάτω από τον ενδιάμεσο κατάλογο εξόδου.
Βήμα 2: Εισαγωγή ορισμού εργασίας Spark στο Fabric
Το βήμα 2 είναι όταν οι ορισμοί εργασίας Spark εισάγονται από τον ενδιάμεσο χώρο αποθήκευσης στον χώρο εργασίας Fabric. Αυτή η διαδικασία έχει ως εξής:
- 2.1) Επαληθεύστε τις ρυθμίσεις παραμέτρων στο 1.2 για να εξασφαλίσετε ότι ο σωστός χώρος εργασίας και το πρόθεμα υποδεικνύονται για την εισαγωγή των ορισμών εργασίας Spark.
- 2.2) Εκτελέστε το τρίτο κελί του σημειωματάριου εξαγωγής/εισαγωγής για να εισαγάγετε όλους τους ορισμούς εργασίας Spark από την ενδιάμεση θέση.
Σημείωμα
Η επιλογή εξαγωγής εξάγει ένα αρχείο μετα-δεδομένων json. Βεβαιωθείτε ότι τα εκτελέσιμα αρχεία ορισμού εργασίας Spark, αρχεία αναφοράς και ορίσματα είναι προσβάσιμα από το Fabric.