Χρήση σημειωματάριου για φόρτωση δεδομένων στο lakehouse σας
Σε αυτό το εκπαιδευτικό βοήθημα, μάθετε πώς μπορείτε να διαβάσετε/γράψετε δεδομένα στο lakehouse Fabric με ένα σημειωματάριο. Το Fabric υποστηρίζει API Spark και API Pandas είναι η επίτευξη αυτού του στόχου.
Φόρτωση δεδομένων με ένα API Apache Spark
Στο κελί κώδικα του σημειωματάριου, χρησιμοποιήστε το παρακάτω παράδειγμα κώδικα για να διαβάσετε δεδομένα από την προέλευση και να τα φορτώσετε σε αρχεία, πίνακες ή και τα δύο τμήματα του lakehouse.
Για να καθορίσετε τη θέση από την οποία θα γίνει η ανάγνωση, μπορείτε να χρησιμοποιήσετε τη σχετική διαδρομή εάν τα δεδομένα προέρχονται από την προεπιλεγμένη λίμνη του τρέχοντος σημειωματάριου σας. Εναλλακτικά, εάν τα δεδομένα προέρχονται από μια διαφορετική λίμνη, μπορείτε να χρησιμοποιήσετε την απόλυτη διαδρομή Συστήματος αρχείων αντικειμένων blob Azure (ABFS). Αντιγράψτε αυτήν τη διαδρομή από το μενού περιβάλλοντος των δεδομένων.
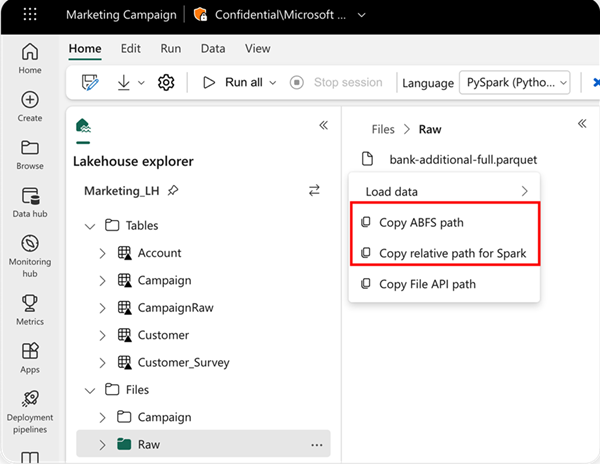
Αντιγραφή διαδρομής ABFS: Αυτή η επιλογή επιστρέφει την απόλυτη διαδρομή του αρχείου.
Αντιγραφή σχετικής διαδρομής για το Spark: Αυτή η επιλογή επιστρέφει τη σχετική διαδρομή του αρχείου στην προεπιλεγμένη λίμνη.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Φόρτωση δεδομένων με το API Pandas
Για την υποστήριξη του API Pandas, η προεπιλεγμένη λίμνη τοποθετείται αυτόματα στο σημειωματάριο. Το σημείο μονταρίσματος είναι '/lakehouse/default/'. Μπορείτε να χρησιμοποιήσετε αυτό το σημείο μονταρίσματος για την ανάγνωση/εγγραφή δεδομένων από/προς την προεπιλεγμένη λίμνη. Η επιλογή "Αντιγραφή διαδρομής API αρχείου" από το μενού περιβάλλοντος επιστρέφει τη διαδρομή API αρχείου από αυτό το σημείο μονταρίσματος. Η διαδρομή που επιστρέφεται από την επιλογή Αντιγραφή διαδρομής ABFS λειτουργεί επίσης για το API Pandas.
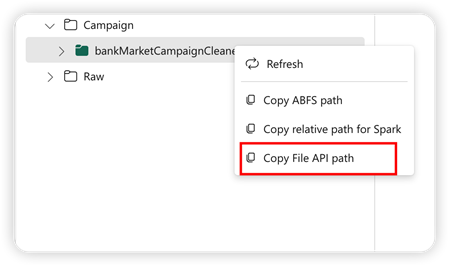
Αντιγραφή διαδρομής API αρχείου: Αυτή η επιλογή επιστρέφει τη διαδρομή κάτω από το σημείο μονταρίσματος της προεπιλεγμένης λίμνης.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Φιλοδώρημα
Για το Spark API, χρησιμοποιήστε την επιλογή Αντιγραφή διαδρομής ABFS ή Αντιγραφή σχετικής διαδρομής για το Spark για να λάβετε τη διαδρομή του αρχείου. Για το API Pandas, χρησιμοποιήστε την επιλογή Αντιγραφή διαδρομής ABFS ή Αντιγραφή διαδρομής API αρχείου για να λάβετε τη διαδρομή του αρχείου.
Ο πιο γρήγορος τρόπος για να έχετε τον κώδικα για να εργαστείτε με το Spark API ή το Pandas API είναι να χρησιμοποιήσετε την επιλογή Φόρτωση δεδομένων και να επιλέξετε το API που θέλετε να χρησιμοποιήσετε. Ο κώδικας δημιουργείται αυτόματα σε ένα νέο κελί κώδικα του σημειωματάριου.
