Manage prompt flow compute session in Azure Machine Learning studio
A prompt flow compute session provides computing resources that are required for the application to run, including a Docker image that contains all necessary dependency packages. This reliable and scalable environment enables prompt flow to efficiently execute its tasks and functions for a seamless user experience.
Permissions and roles for compute session management
To assign roles, you need to have owner or Microsoft.Authorization/roleAssignments/write permission on the resource.
For users of the compute session, assign the AzureML Data Scientist role in the workspace. To learn more, see Manage access to an Azure Machine Learning workspace.
Role assignment might take several minutes to take effect.
Start a compute session in studio
Before you use Azure Machine Learning studio to start a compute session, make sure that:
- You have the
AzureML Data Scientistrole in the workspace. - The default data store (usually
workspaceblobstore) in your workspace is the blob type. - The working directory (
workspaceworkingdirectory) exists in the workspace. - If you use a virtual network for prompt flow, you understand the considerations in Network isolation in prompt flow.
Start a compute session on a flow page
One flow binds to one compute session. You can start a compute session on a flow page.
Select Start. Start a compute session by using the environment defined in
flow.dag.yamlin the flow folder, it runs on the virtual machine (VM) size of serverless compute which you have enough quota in the workspace.
Select Start with advanced settings. In the advanced settings, you can:
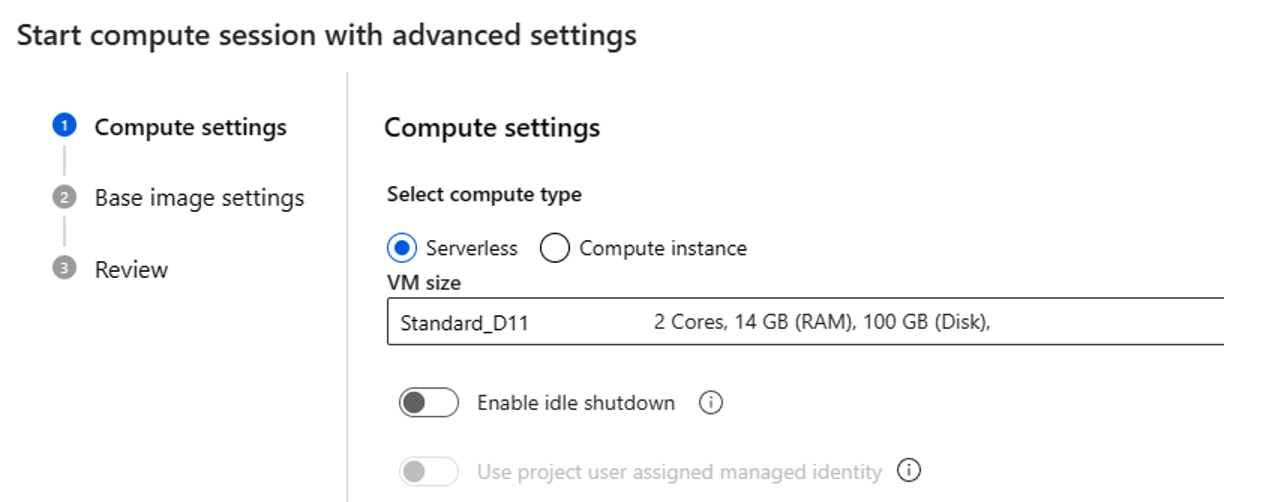
- Select compute type. You can choose between serverless compute and compute instance.
If you choose serverless compute, you can set following settings:
- Customize the VM size that the compute session uses. Opt for VM series D and above. For more information, see the section on Supported VM series and sizes
- Customize the idle time, which deletes the compute session automatically if it isn't in use for a while.
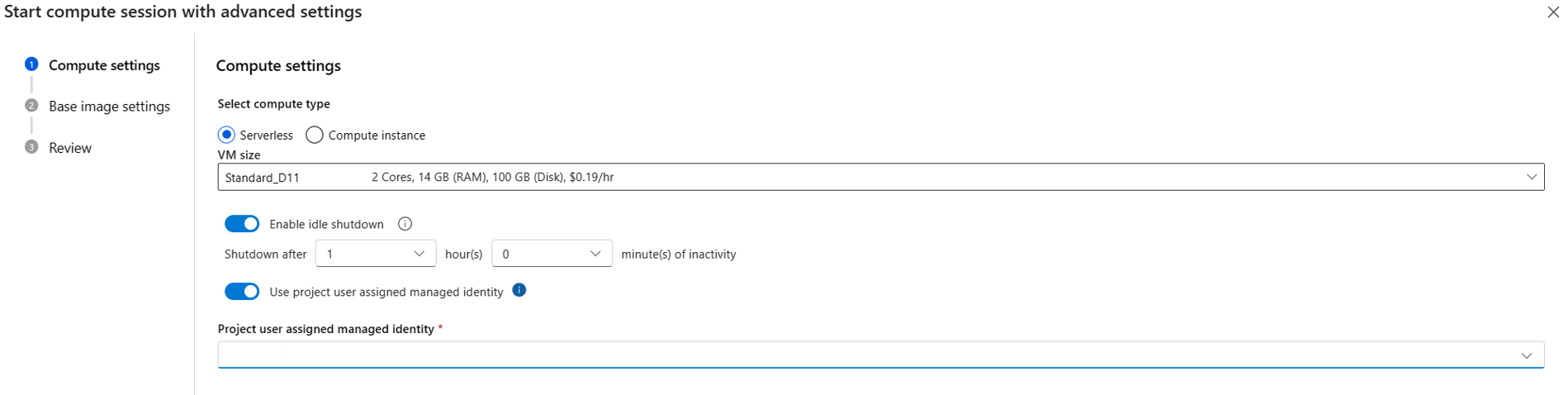
- Set the user-assigned managed identity. The compute session uses this identity to pull a base image, auth with connection and install packages. Make sure that the user-assigned managed identity has enough permission. If you don't set this identity, we use the user identity by default.
- You can use following CLI command to assign user assigned managed identity to workspace. Learn more about how to create and update user-assigned identities for a workspace.
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>Where the contents of workspace_update_with_multiple_UAIs.yml are as follows:
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}Tip
The following Azure RBAC role assignments are required on your user-assigned managed identity for your Azure Machine Learning workspace to access data on the workspace-associated resources.
Resource Permission Azure Machine Learning workspace Contributor Azure Storage Contributor (control plane) + Storage Blob Data Contributor + Storage File Data Privileged Contributor (data plane, consume flow draft in fileshare and data in blob) Azure Key Vault (when using access policies permission model) Contributor + any access policy permissions besides purge operations, this is default mode for linked Azure Key Vault. Azure Key Vault (when using RBAC permission model) Contributor (control plane) + Key Vault Administrator (data plane) Azure Container Registry Contributor Azure Application Insights Contributor Note
The job submitter need have
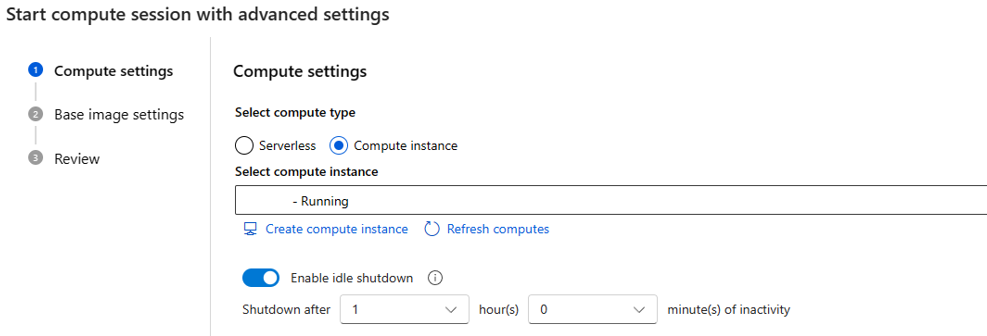
assignpermission on user assigned managed identity, you can assignManaged Identity Operatorrole, as every time create serverless compute session, it will assign user assigned managed identity to compute.If you choose compute instance as compute type, you can only set idle shutdown time.
As it's running on an existing compute instance the VM size is fixed and can't change in session side.
Identity used for this session is also defined in compute instance, by default it uses the user identity. Learn more about how to assign identity to compute instance
For the idle shutdown time it's used to define life cycle of the compute session, if the session is idle for the time you set, it's deleted automatically. And of you have idle shut-down enabled on compute instance, then it takes effect from compute level.
Learn more about how to create and manage compute instance
- Select compute type. You can choose between serverless compute and compute instance.



Use a compute session to submit a flow run in CLI/SDK
Besides studio, you can also specify the compute session in CLI/SDK when you submit a flow run.
You can also specify the instance type or compute instance name under resource part. If you don't specify the instance type or compute instance name, Azure Machine Learning chooses an instance type (VM size) based on factors like quota, cost, performance, and disk size. Learn more about serverless compute.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
Submit this run via CLI:
pfazure run create --file run.yml
Note
The idle shutdown is one hour if you are using CLI/SDK to submit a flow run. You can go to compute page to release compute.
Reference files outside of the flow folder
Sometimes, you might want to reference a requirements.txt file that is outside of the flow folder. For example, you might have complex project that includes multiple flows, and they share the same requirements.txt file. To do this, You can add this field additional_includes into the flow.dag.yaml. The value of this field is a list of the relative file/folder path to the flow folder. For example, if requirements.txt is in the parent folder of the flow folder, you can add ../requirements.txt to the additional_includes field.
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
The requirements.txt file is copied to the flow folder, and use it to start your compute session.
Update a compute session on the studio flow page
On a flow page, you can use the following options to manage a compute session:
- Change compute session settings, you change compute settings like VM size and e user-assigned managed identity for serverless compute, if you're using compute instance you can change to use other instance. You can also change
- can also change the user-assigned managed identity for serverless compute. If you change the VM size, the compute session is reset with the new VM size. If you
- Install packages from requirements.txt Open
requirements.txtin prompt flow UI, you can add packages in it. - View installed packages shows the packages that are installed in the compute session. It includes the packages install to base image and packages specify in the
requirements.txtfile in the flow folder. - Reset compute session deletes the current compute session and creates a new one with the same environment. If you encounter a package conflict issue, you can try this option.
- Stop compute session deletes the current compute session. If there's no active compute session on the underlying compute, the serverless compute resource will also be deleted.

You can also customize the environment that you use to run this flow by adding packages in the requirements.txt file in the flow folder. After you add more packages in this file, you can choose either of these options:
- Save and install triggers
pip install -r requirements.txtin the flow folder. The process can take a few minutes, depending on the packages that you install. - Save only just saves the
requirements.txtfile. You can install the packages later yourself.

Note
You can change the location and even the file name of requirements.txt, but be sure to also change it in the flow.dag.yaml file in the flow folder.
Don't pin the version of promptflow and promptflow-tools in requirements.txt, because we already include them in the session base image.
requirements.txt won't support local wheel files. Build them in your image and update the customized base image in flow.dag.yaml. Learn more about how to build a custom base image.
Add packages in a private feed in Azure DevOps
If you want to use a private feed in Azure DevOps, follow these steps:
Assign managed identity to workspace or compute instance.
Use serverless compute as compute session, you need to assign user-assigned managed identity to workspace.
Create a user-assigned managed identity and add this identity in the Azure DevOps organization. To learn more, see Use service principals and managed identities.
Note
If the Add Users button isn't visible, you probably don't have the necessary permissions to perform this action.
Add or update user-assigned identities to a workspace.
Note
Please make sure the user-assigned managed identity has
Microsoft.KeyVault/vaults/readon the workspace linked keyvault.
Use compute instance as compute session, you need assign a user-assigned managed identity to a compute instance.
Add
{private}to your private feed URL. For example, if you want to installtest_packagefromtest_feedin Azure DevOps, add-i https://{private}@{test_feed_url_in_azure_devops}inrequirements.txt:-i https://{private}@{test_feed_url_in_azure_devops} test_packageSpecify using user-assigned managed identity in the compute session configuration.
If you're using serverless compute, specify the user-assigned managed identity in Start with advanced settings if compute session isn't running, or use the Change compute session settings button if compute session is running.
If you're using compute instance, it uses the user-assigned managed identity that you assigned to the compute instance.

Note
This approach mainly focuses on quick testing in flow develop phase, if you also want to deploy this flow as endpoint please build this private feed in your image and update customize base image in flow.dag.yaml. Learn more how to build custom base image
Change the base image for compute session
By default, we use the latest prompt flow base image. If you want to use a different base image, you can build a custom one.
- In studio, you can change the base image in base image settings under compute session settings.

You can also specify the new base image under
environmentin theflow.dag.yamlfile in the flow folder.
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

To use the new base image, you need to reset the compute session. This process takes several minutes as it pulls the new base image and reinstalls packages.
Manage serverless instance used by compute session
When you use serverless compute as a compute session, you can manage the serverless instance. View the serverless instance in the compute session list tab on the compute page.

You can also access flows and runs running on the compute under the Active flows and runs tab. As delete the instance impacts the flow and runs on it.

Relationship between compute session, compute resource, flow, and user
- One single user can have multiple compute resources (serverless or compute instance). Because of different needs, a single user can have multiple compute resources. For example, one user can have multiple compute resources with different VM size or different user-assigned managed identity.
- One compute resource can only be used by single user. A compute resource is used as private development box of a single user. Multiple users can't share the same compute resources.
- One compute resource can host multiple compute sessions. A compute session is a container running on an underlying compute resource. For example, prompt flow authoring doesn't need too much compute resources, so a single compute resource can host multiple compute sessions from the same user.
- One compute session only belongs to single compute resource at a time. But you can delete or stop a compute session and reallocate it to another compute resource.
- One flow can only have one compute session. Each flow is self-contained and defines the base image and required python packages in the flow folder for the compute session.
Switch runtime to compute session
Compute sessions have the following advantages over compute instance runtimes:
- Automatic manage lifecycle of session and underlying compute. You don't need to manually create and managed them anymore.
- Easily customize packages by adding packages in the
requirements.txtfile in the flow folder, instead of creating a custom environment.
Switch a compute instance runtime to a compute session by using the following steps:
- Prepare your
requirements.txtfile in the flow folder. Make sure that you don't pin the version ofpromptflowandpromptflow-toolsinrequirements.txt, because we already include them in the base image. Compute session installs the packages inrequirements.txtfile when it starts. - If you create a custom environment to create a compute instance runtime, you can get the image from environment detail page, and specify it in the
flow.dag.yamlfile in the flow folder. To learn more, see Change the base image for compute session. Make sure you or the related user assigned managed identity on the workspace hasacr pullpermission for the image.

- For the compute resource, you can continue to use the existing compute instance if you would like to manually manage the lifecycle or you can try serverless compute whose lifecycle is managed by the system.