The scope of the lakehouse platform
A modern data and AI platform framework
To discuss the scope of the Databricks Data intelligence Platform, it is helpful to first define a basic framework for the modern data and AI platform:
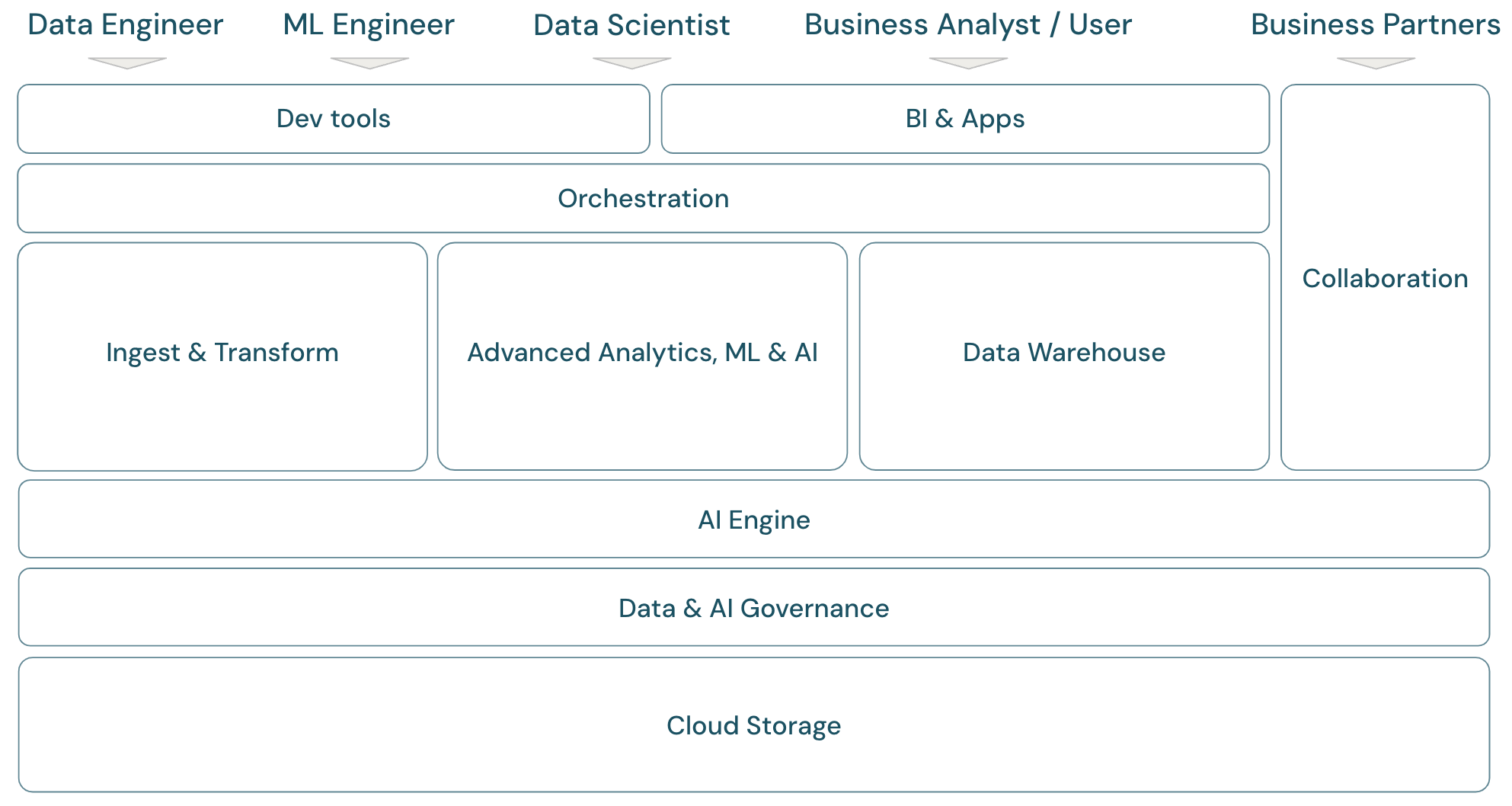
Overview of the lakehouse scope
The Databricks Data Intelligence Platform covers the complete modern data platform framework. It is built on the lakehouse architecture and powered by a data intelligence engine that understands the unique qualities of your data. It is an open and unified foundation for ETL, ML/AI, and DWH/BI workloads, and has Unity Catalog as the central data and AI governance solution.
Personas of the platform framework
The framework covers the primary data team members (personas) working with the applications in the framework:
- Data engineers provide data scientists and business analysts with accurate and reproducible data for timely decision-making and real-time insights. They implement highly consistent and reliable ETL processes to increase user confidence and trust in data. They ensure that data is well integrated with the various pillars of the business and typically follow software engineering best practices.
- Data scientists blend analytical expertise and business understanding to transform data into strategic insights and predictive models. They are adept at translating business challenges into data-driven solutions, be that through retrospective analytical insights or forward-looking predictive modeling. Leveraging data modeling and machine learning techniques, they design, develop, and deploy models that unveil patterns, trends, and forecasts from data. They act as a bridge, converting complex data narratives into comprehensible stories, ensuring business stakeholders not only understand but can also act upon the data-driven recommendations, in turn driving a data-centric approach to problem-solving within an organization.
- ML engineers (machine learning engineers) lead the practical application of data science in products and solutions by building, deploying, and maintaining machine learning models. Their primary focus pivots towards the engineering aspect of model development and deployment. ML Engineers ensure the robustness, reliability, and scalability of machine learning systems in live environments, addressing challenges related to data quality, infrastructure, and performance. By integrating AI and ML models into operational business processes and user-facing products, they facilitate the utilization of data science in solving business challenges, ensuring models don’t just stay in research but drive tangible business value.
- Business analysts and business users: Business analysts provide stakeholders and business teams with actionable data. They often interpret data and create reports or other documentation for management using standard BI tools. They are typically the first point of contact for non-technical business users and operations colleagues for quick analysis questions. Dashboards and business apps delivered on the Databricks platform can be used directly by business users.
- Business partners are important stakeholders in an increasingly networked business world. They are defined as a company or individuals with whom a business has a formal relationship to achieve a common goal, and can include vendors, suppliers, distributors, and other third-party partners. Data sharing is an important aspect of business partnerships, as it enables the transfer and exchange of data to enhance collaboration and data-driven decision-making.
Domains of the platform framework
The platform consists of multiple domains:
- Storage: In the cloud, data is mainly stored in scalable, efficient, and resilient object storage on cloud providers.
- Governance: Capabilities around data governance, such as access control, auditing, metadata management, lineage tracking, and monitoring for all data and AI assets.
- AI engine: The AI engine provides generative AI capabilities for the whole platform.
- Ingest & transform: The capabilities for ETL workloads.
- Advanced analytics, ML, and AI: All capabilities around machine learning, AI, Generative AI, and also streaming analytics.
- Data warehouse: The domain supporting DWH and BI use cases.
- Automation: Workflow management for data processing, machine learning, analytics pipelines, including CI/CD and MLOps support.
- ETL & DS tools: The front-end tools that data engineers, data scientists and ML engineers primarily use for work.
- BI tools: The front-end tools that BI analysts primarily use for work.
- Collaboration: Capabilities for data sharing between two or more parties.
The scope of the Databricks Platform
The Databricks Data Intelligence Platform and its components can be mapped to the framework in the following way:
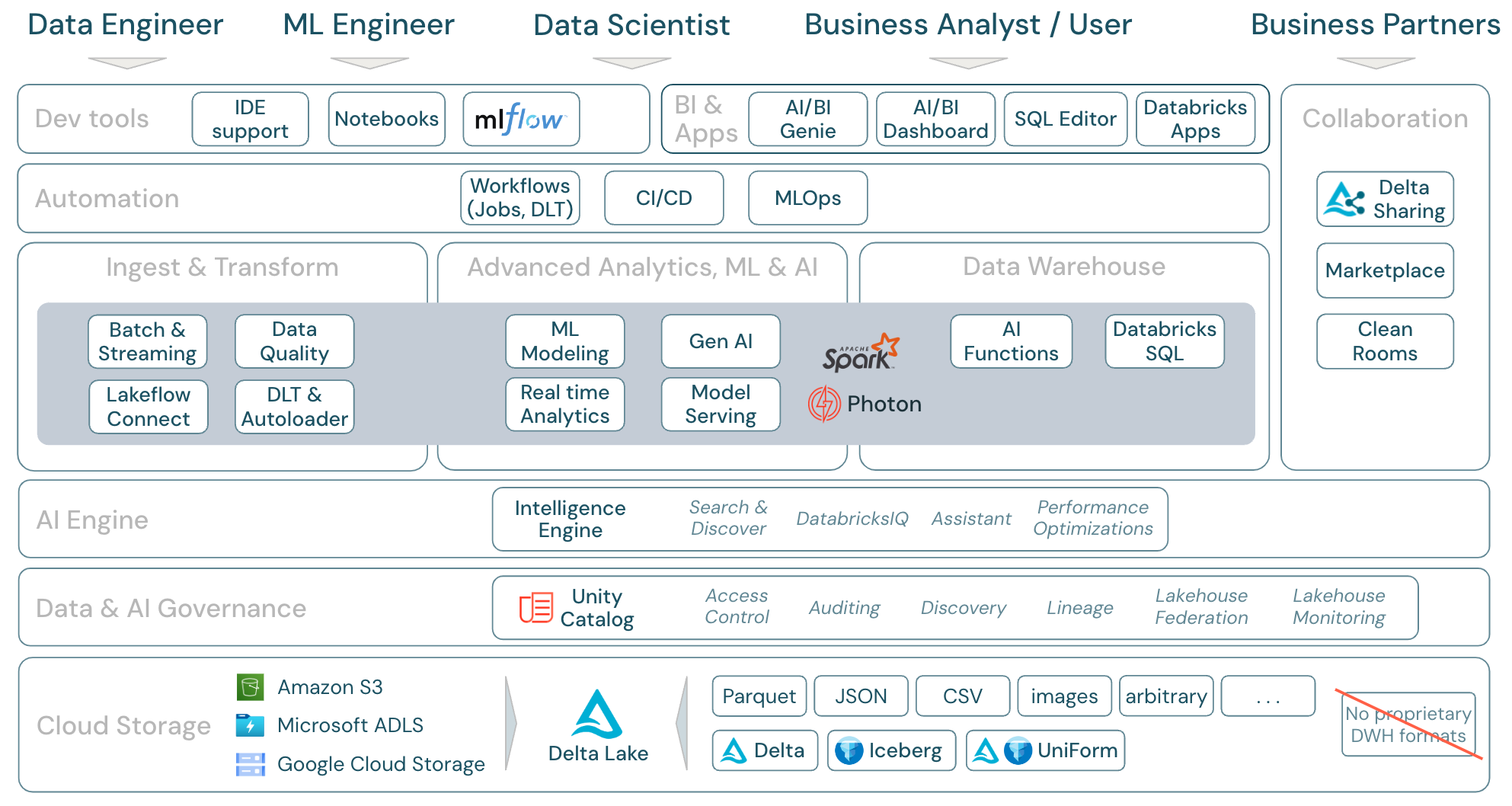 Download: Scope of the lakehouse - Databricks components
Download: Scope of the lakehouse - Databricks components
Data workloads on Azure Databricks
Most importantly, the Databricks Data Intelligence Platform covers all relevant workloads for the data domain in one platform, with Apache Spark/Photon as the engine:
Ingest & transform
Databricks offers several ways of data ingestion:
- Databricks Lakeflow Connect offers built-in connectors for ingestion from enterprise applications and databases. The resulting ingestion pipeline is governed by Unity Catalog and is powered by serverless compute and DLT.
- Auto Loader incrementally and automatically processes files landing in cloud storage in scheduled or continuous jobs - without the need to manage state information. Once ingested, raw data needs to be transformed so it’s ready for BI and ML/AI. Databricks provides powerful ETL capabilities for data engineers, data scientists, and analysts.
DLT (DLT) allows writing ETL jobs in a declarative way, simplifying the entire implementation process. Data quality can be improved by defining data expectations.
Advanced analytics, ML, and AI
The platform includes Databricks Mosaic AI, a set of fully integrated machine learning and AI tools for classic machine and deep learning, as well as generative AI and large language models (LLMs). It covers the entire workflow from preparing data to building machine learning and deep learning models, to Mosaic AI Model Serving.
Spark Structured Streaming and DLT enable real-time analytics.
Data warehouse
The Databricks Data Intelligence Platform also has a complete data warehouse solution with Databricks SQL, centrally governed by Unity Catalog with fine-grained access control.
AI functions are built-in SQL functions that allow you to apply AI on your data directly from SQL. Integrating AI into analysis workflows provides access to information previously inaccessible to analysts, and empowers them to make more informed decisions, manage risks, and sustain a competitive advantage through data-driven innovation and efficiency.
Outline of Azure Databricks feature areas
This is a mapping of the Databricks Data Intelligence Platform features to the other layers of the framework, from bottom to top:
Cloud storage
All data for the lakehouse is stored in the cloud provider’s object storage. Databricks supports three cloud providers: AWS, Azure, and GCP. Files in various structured and semi-structured formats (for example, Parquet, CSV, JSON, and Avro), as well as unstructured formats (such as images and documents), are ingested and transformed using either batch or streaming processes.
Delta Lake is the recommended data format for the lakehouse (file transactions, reliability, consistency, updates, and so on) and is completely open source to avoid lock-in. And Delta Universal Format (UniForm) allows you to read Delta tables with Iceberg reader clients.
No proprietary data formats are used in the Databricks Data Intelligence Platform.
Data and AI governance
On top of the storage layer, Unity Catalog offers a wide range of data and AI governance capabilities, including metadata management in the metastore, access control, auditing, data discovery, and data lineage.
Lakehouse monitoring provides out-of-the-box quality metrics for data and AI assets, and auto-generated dashboards to visualize these metrics.
External SQL sources can be integrated into the lakehouse and Unity Catalog through lakehouse federation.
AI engine
The Data Intelligence Platform is built on the lakehouse architecture and enhanced by the data intelligence engine DatabricksIQ. DatabricksIQ combines generative AI with the unification benefits of the lakehouse architecture to understand the unique semantics of your data. Intelligent Search and the Databricks Assistant are examples of AI powered services that simplify working with the platform for every user.
Orchestration
Databricks Jobs enable you to run diverse workloads for the full data and AI lifecycle on any cloud. They allow you to orchestrate jobs as well as DLT for SQL, Spark, notebooks, DBT, ML models, and more.
ETL & DS tools
At the consumption layer, data engineers and ML engineers typically work with the platform using IDEs. Data scientists often prefer notebooks and use the ML & AI runtimes, and the machine learning workflow system MLflow to track experiments and manage the model lifecycle.
BI tools
Business analysts typically use their preferred BI tool to access the Databricks data warehouse. Databricks SQL can be queried by different Analysis and BI tools, see BI and visualization
In addition, the platform offers query and analysis tools out of the box:
- AI/BI Dashboards to drag-and-drop data visualizations and share insights.
- Domain experts, such as data analysts, configure AI/BI Genie spaces with datasets, sample queries, and text guidelines to help Genie translate business questions into analytical queries. After set up, business users can ask questions and generate visualizations to understand operational data.
- Databricks Apps lets developers create secure data and AI applications on the Databricks platform and share those apps with users.
- SQL editor for SQL analysts to analyze data.
Collaboration
Delta Sharing is an open protocol developed by Databricks for secure data sharing with other organizations regardless of the computing platforms they use.
Databricks Marketplace is an open forum for exchanging data products. It takes advantage of Delta Sharing to give data providers the tools to share data products securely and data consumers the power to explore and expand their access to the data and data services they need.
Clean Rooms use Delta Sharing and serverless compute to provide a secure and privacy-protecting environment where multiple parties can work together on sensitive enterprise data without direct access to each other’s data.