How quality, cost, and latency are assessed by Agent Evaluation
Important
This feature is in Public Preview.
This article explains how Agent Evaluation assesses your AI application’s quality, cost, and latency and provides insights to guide your quality improvements and cost and latency optimizations. It covers the following:
- How quality is assessed by LLM judges.
- How cost and latency are assessed.
- How metrics are aggregated at the level of an MLflow run for quality, cost, and latency.
For reference information about each of the built-in LLM judges, see Built-in AI judges.
How quality is assessed by LLM judges
Agent Evaluation assesses quality using LLM judges in two steps:
- LLM judges assess specific quality aspects (such as correctness and groundedness) for each row. For details, see Step 1: LLM judges assess each row’s quality.
- Agent Evaluation combines individual judge’s assessments into an overall pass/fail score and root cause for any failures. For details, see Step 2: Combine LLM judge assessments to identify the root cause of quality issues.
For LLM judge trust and safety information, see Information about the models powering LLM judges.
Note
For multi-turn conversations, LLM judges evaluate only the last entry in the conversation.
Step 1: LLM judges assess each row’s quality
For every input row, Agent Evaluation uses a suite of LLM judges to assess different aspects of quality about agent’s outputs. Each judge produces a yes or no score and a written rationale for that score, as shown in the example below:

For details about the LLM judges used, see Built-in AI judges.
Step 2: Combine LLM judge assessments to identify the root cause of quality issues
After running LLM judges, Agent Evaluation analyzes their outputs to assess overall quality and determine a pass/fail quality score on the judge’s collective assessments. If overall quality fails, Agent Evaluation identifies which specific LLM judge caused the failure and provides suggested fixes.
The data is shown in the MLflow UI, and is also available from the MLflow run in a DataFrame returned by the mlflow.evaluate(...) call. See review evaluation output for details on how to access the DataFrame.
The following screenshot is an example of a summary analysis in the UI:

The results for each row are available in the detail view UI:
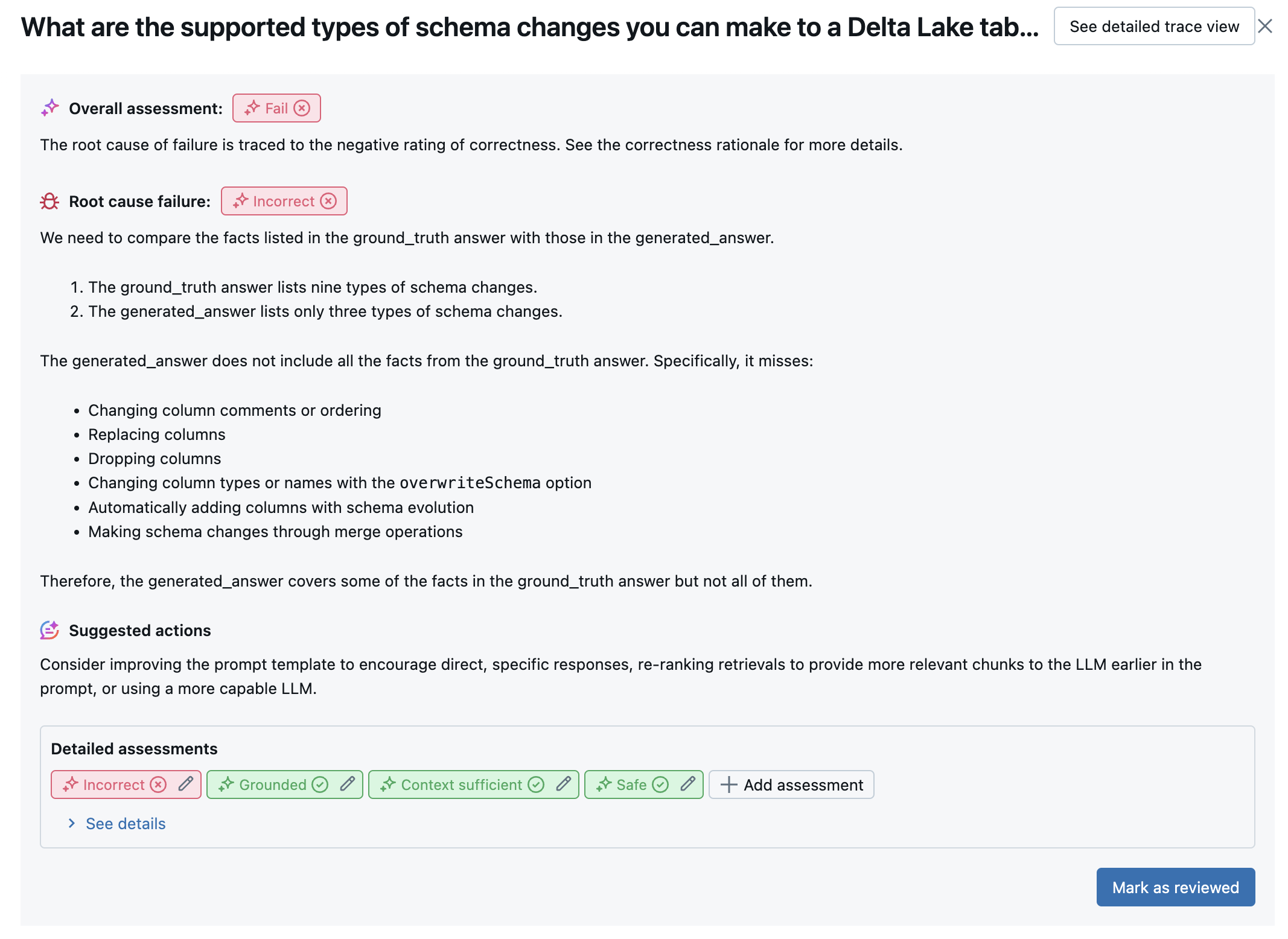
Built-in AI judges
See Built-in AI judges for details on built-in AI Judges provided by Mosaic AI Agent Evaluation.
The following screenshots show examples of how these judges appear in the UI:
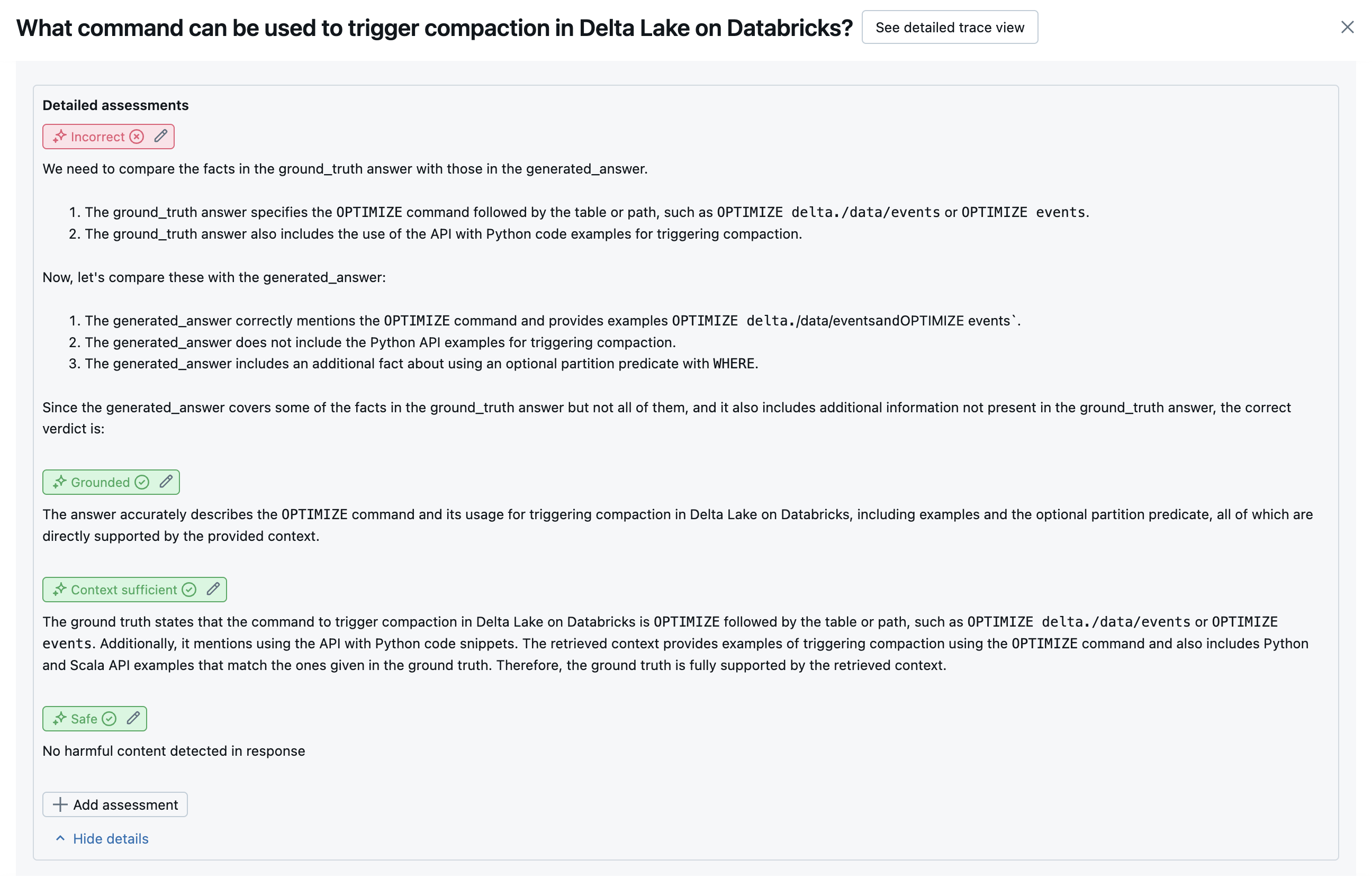
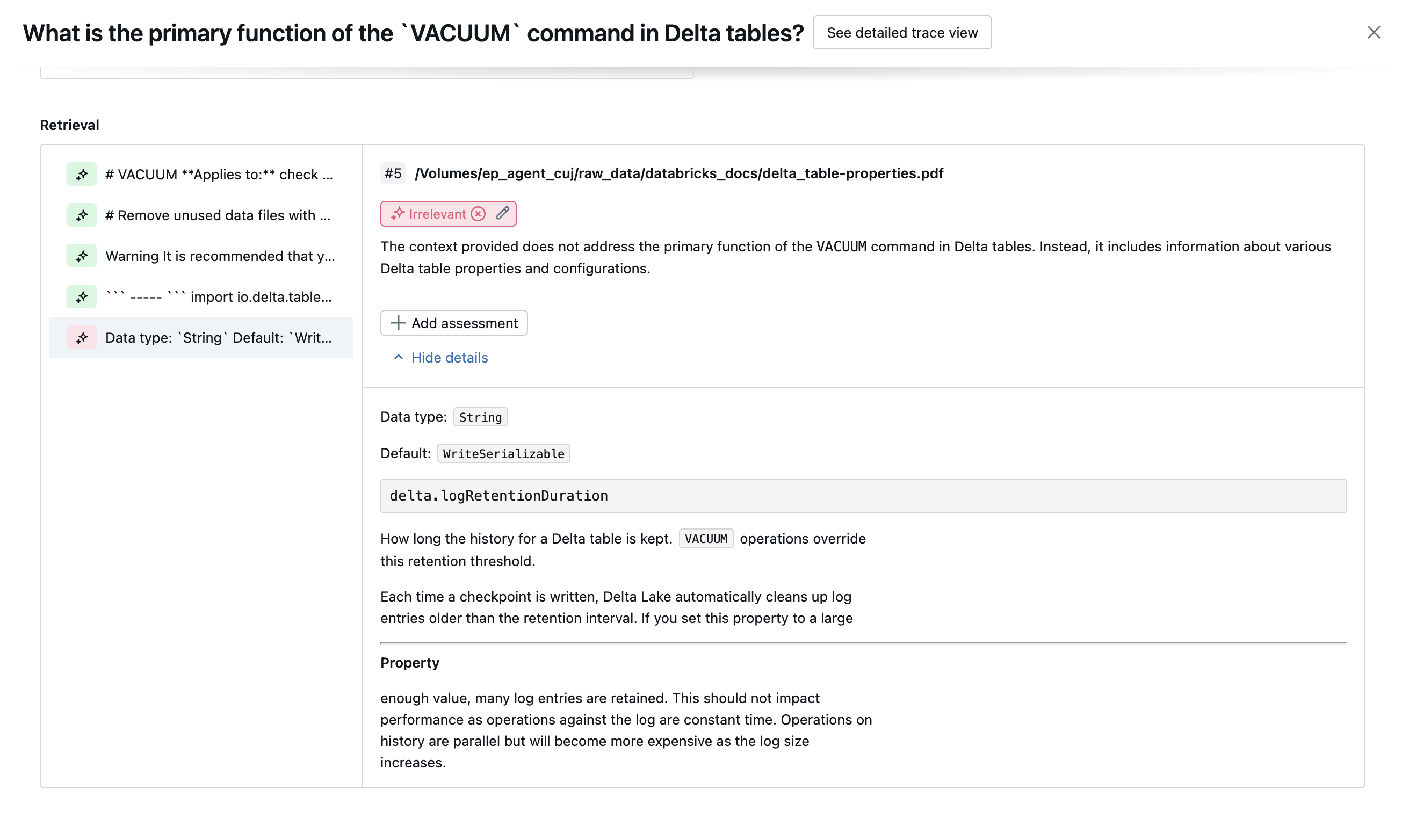
How root cause is determined
If all judges pass, the quality is considered pass. If any judge fails, the root cause is determined as the first judge to fail based on the ordered list below. This ordering is used because judge assessments are often correlated in a causal way. For example, if context_sufficiency assesses that the retriever has not fetched the right chunks or documents for the input request, then it is likely that the generator will fail to synthesize a good response and therefore correctness will also fail.
If ground truth is provided as input, the following order is used:
context_sufficiencygroundednesscorrectnesssafetyguideline_adherence(ifguidelinesorglobal_guidelinesare provided)- Any customer-defined LLM judge
If ground truth is not provided as input, the following order is used:
chunk_relevance- is there at least 1 relevant chunk?groundednessrelevant_to_querysafetyguideline_adherence(ifguidelinesorglobal_guidelinesare provided)- Any customer-defined LLM judge
How Databricks maintains and improves LLM judge accuracy
Databricks is dedicated to enhancing the quality of our LLM judges. Quality is evaluated by measuring how well the LLM judge agrees with human raters, using the following metrics:
- Increased Cohen’s Kappa (a measure of inter-rater agreement).
- Increased accuracy (percent of predicted labels that match the human rater’s label).
- Increased F1 score.
- Decreased false positive rate.
- Decreased false negative rate.
To measure these metrics, Databricks uses diverse, challenging examples from academic and proprietary datasets that are representative of customer datasets to benchmark and improve judges against state-of-the-art LLM judge approaches, ensuring continuous improvement and high accuracy.
For more details on how Databricks measures and continuously improves judge quality, see Databricks announces significant improvements to the built-in LLM judges in Agent Evaluation.
Call judges using the Python SDK
The databricks-agents SDK includes APIs to directly invoke judges on user inputs. You can use these APIs for a quick and easy experiment to see how the judges work.
Run the following code to install the databricks-agents package and restart the python kernel:
%pip install databricks-agents -U
dbutils.library.restartPython()
You can then run the following code in your notebook, and edit it as necessary to try out the different judges on your own inputs.
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES ={
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
How cost and latency are assessed
Agent Evaluation measures token counts and execution latency to help you understand your agent’s performance.
Token cost
To assess cost, Agent Evaluation computes the total token count across all LLM generation calls in the trace. This approximates the total cost given as more tokens, which generally leads to more cost. Token counts are only calculated when a trace is available. If the model argument is included in the call to mlflow.evaluate(), a trace is automatically generated. You can also directly provide a trace column in the evaluation dataset.
The following token counts are calculated for each row:
| Data field | Type | Description |
|---|---|---|
total_token_count |
integer |
Sum of all input and output tokens across all LLM spans in the agent’s trace. |
total_input_token_count |
integer |
Sum of all input tokens across all LLM spans in the agent’s trace. |
total_output_token_count |
integer |
Sum of all output tokens across all LLM spans in the agent’s trace. |
Execution latency
Computes the entire application’s latency in seconds for the trace. Latency is only calculated when a trace is available. If the model argument is included in the call to mlflow.evaluate(), a trace is automatically generated. You can also directly provide a trace column in the evaluation dataset.
The following latency measurement is calculated for each row:
| Name | Description |
|---|---|
latency_seconds |
End-to-end latency based on the trace |
How metrics are aggregated at the level of an MLflow run for quality, cost, and latency
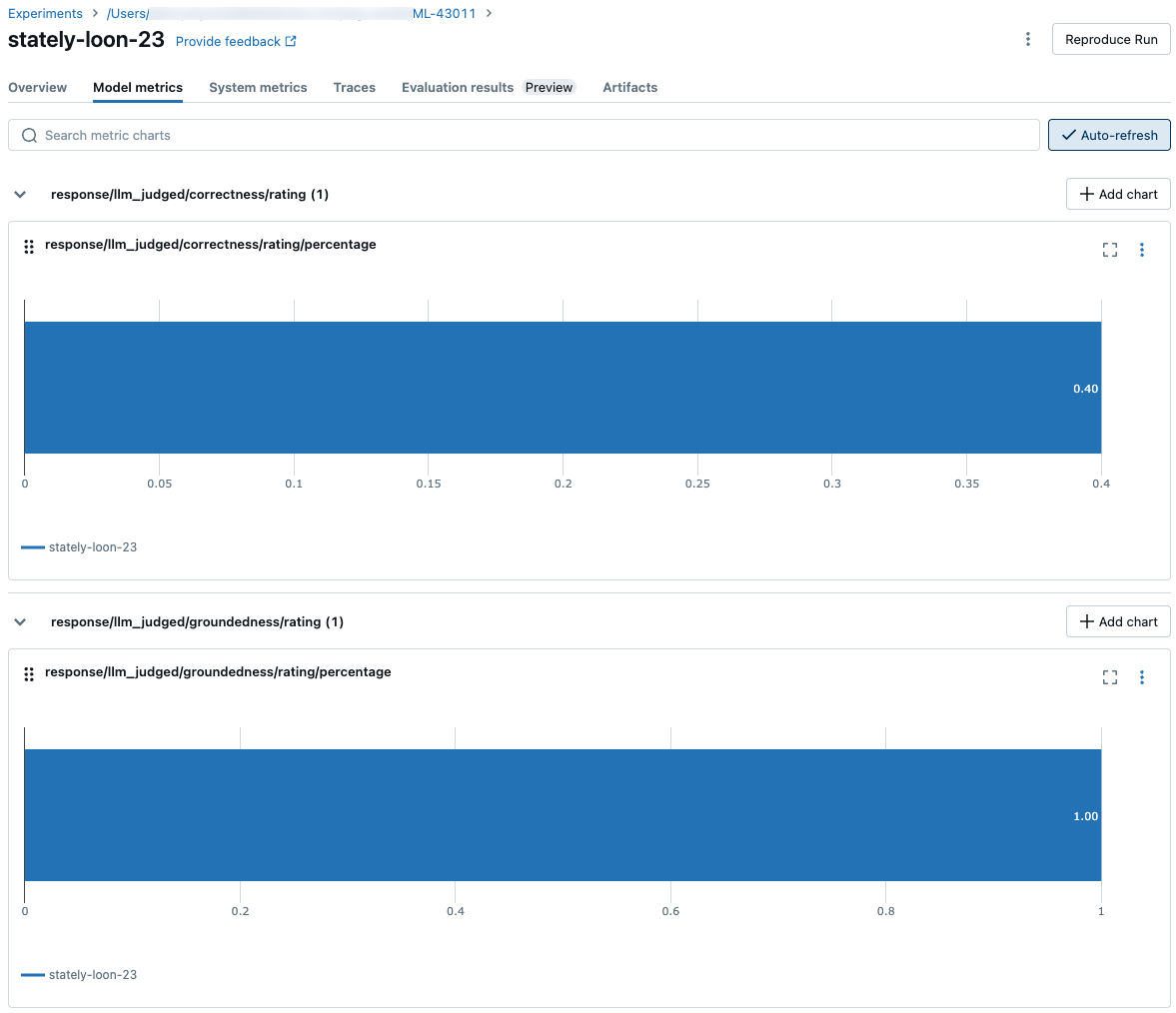
After computing all per-row quality, cost, and latency assessments, Agent Evaluation aggregates these asessments into per-run metrics that are logged in a MLflow run and summarize the quality, cost, and latency of your agent across all input rows.
Agent Evaluation produces the following metrics:
| Metric name | Type | Description |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Average value of chunk_relevance/precision across all questions. |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% of questions where context_sufficiency/rating is judged as yes. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% of questions where correctness/rating is judged as yes. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% of questions where relevance_to_query/rating is judged to be yes. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% of questions where groundedness/rating is judged as yes. |
response/llm_judged/guideline_adherence/rating/percentage |
float, [0, 1] |
% of questions where guideline_adherence/rating is judged as yes. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% of questions where is safety/rating judged to be yes. |
agent/total_token_count/average |
int |
Average value of total_token_count across all questions. |
agent/input_token_count/average |
int |
Average value of input_token_count across all questions. |
agent/output_token_count/average |
int |
Average value of output_token_count across all questions. |
agent/latency_seconds/average |
float |
Average value of latency_seconds across all questions. |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% of questions where {custom_response_judge_name}/rating is judged as yes. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Average value of {custom_retrieval_judge_name}/precision across all questions. |
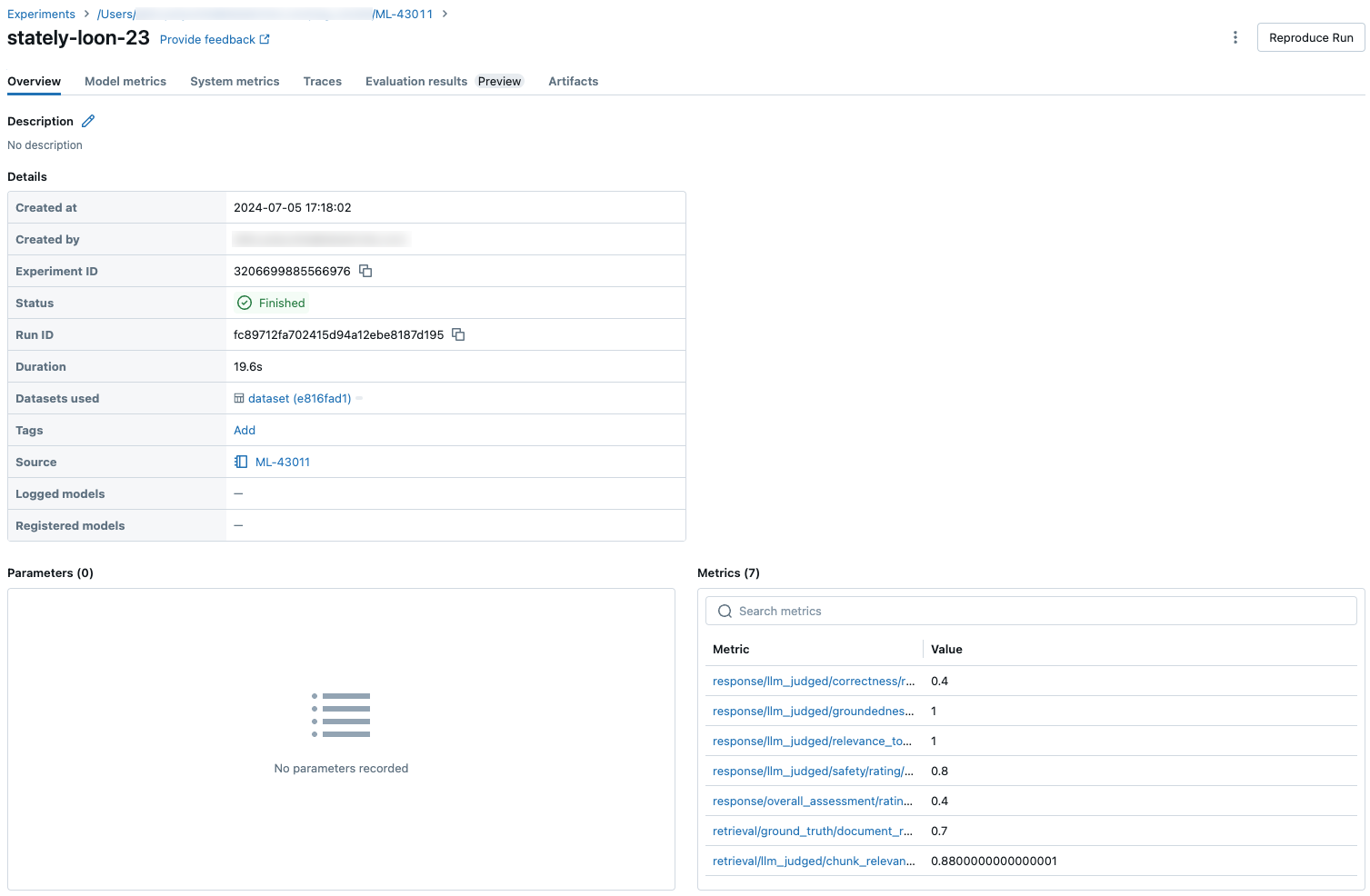
The following screenshots show how the metrics appear in the UI:
Information about the models powering LLM judges
- LLM judges might use third-party services to evaluate your GenAI applications, including Azure OpenAI operated by Microsoft.
- For Azure OpenAI, Databricks has opted out of Abuse Monitoring so no prompts or responses are stored with Azure OpenAI.
- For European Union (EU) workspaces, LLM judges use models hosted in the EU. All other regions use models hosted in the US.
- Disabling Azure AI-powered AI assistive features prevents the LLM judge from calling Azure AI-powered models.
- Data sent to the LLM judge is not used for any model training.
- LLM judges are intended to help customers evaluate their RAG applications, and LLM judge outputs should not be used to train, improve, or fine-tune an LLM.