Access Azure Data Lake Storage using Microsoft Entra ID credential passthrough (legacy)
Important
This documentation has been retired and might not be updated.
Credential passthrough is deprecated starting with Databricks Runtime 15.0 and will be removed in future Databricks Runtime versions. Databricks recommends that you upgrade to Unity Catalog. Unity Catalog simplifies security and governance of your data by providing a central place to administer and audit data access across multiple workspaces in your account. See What is Unity Catalog?.
For heightened security and governance posture, contact your Azure Databricks account team to disable credential passthrough in your Azure Databricks account.
Note
This article contains references to the term whitelisted, a term that Azure Databricks does not use. When the term is removed from the software, we’ll remove it from this article.
You can authenticate automatically to Accessing Azure Data Lake Storage Gen1 from Azure Databricks (ADLS Gen1) and ADLS Gen2 from Azure Databricks clusters using the same Microsoft Entra ID identity that you use to log into Azure Databricks. When you enable Azure Data Lake Storage credential passthrough for your cluster, commands that you run on that cluster can read and write data in Azure Data Lake Storage without requiring you to configure service principal credentials for access to storage.
Azure Data Lake Storage credential passthrough is supported with Azure Data Lake Storage Gen1 and Gen2 only. Azure Blob storage does not support credential passthrough.
This article covers:
- Enabling credential passthrough for standard and high-concurrency clusters.
- Configuring credential passthrough and initializing storage resources in ADLS accounts.
- Accessing ADLS resources directly when credential passthrough is enabled.
- Accessing ADLS resources through a mount point when credential passthrough is enabled.
- Supported features and limitations when using credential passthrough.
Notebooks are included to provide examples of using credential passthrough with ADLS Gen1 and ADLS Gen2 storage accounts.
Requirements
- Premium plan. See Upgrade or Downgrade an Azure Databricks Workspace for details on upgrading a standard plan to a premium plan.
- An Azure Data Lake Storage Gen1 or Gen2 storage account. Azure Data Lake Storage Gen2 storage accounts must use the hierarchical namespace to work with Azure Data Lake Storage credential passthrough. See Create a storage account for instructions on creating a new ADLS Gen2 account, including how to enable the hierarchical namespace.
- Properly configured user permissions to Azure Data Lake Storage. An Azure Databricks administrator needs to ensure that users have the correct roles, for example, Storage Blob Data Contributor, to read and write data stored in Azure Data Lake Storage. See Use the Azure portal to assign an Azure role for access to blob and queue data.
- Understand the privileges of workspace admins in workspaces that are enabled for passthrough, and review your existing workspace admin assignments. Workspace admins can manage operations for their workspace including adding users and service principals, creating clusters, and delegating other users to be workspace admins. Workspace management tasks, such as managing job ownership and viewing notebooks, may give indirect access to data registered in Azure Data Lake Storage. Workspace admin is a privileged role that you should distribute carefully.
- You cannot use a cluster configured with ADLS credentials, for example, service principal credentials, with credential passthrough.
Important
You cannot authenticate to Azure Data Lake Storage with your Microsoft Entra ID credentials if you are behind a firewall that has not been configured to allow traffic to Microsoft Entra ID. Azure Firewall blocks Active Directory access by default. To allow access, configure the AzureActiveDirectory service tag. You can find equivalent information for network virtual appliances under the AzureActiveDirectory tag in the Azure IP Ranges and Service Tags JSON file. For more information, see Azure Firewall service tags.
Logging recommendations
You can log identities passed through to ADLS storage in the Azure storage diagnostic logs. Logging identities allows ADLS requests to be tied to individual users from Azure Databricks clusters. Turn on diagnostic logging on your storage account to start receiving these logs:
- Azure Data Lake Storage Gen1: Follow the instructions in Enable diagnostic logging for your Data Lake Storage Gen1 account.
- Azure Data Lake Storage Gen2: Configure using PowerShell with the
Set-AzStorageServiceLoggingPropertycommand. Specify 2.0 as the version, because log entry format 2.0 includes the user principal name in the request.
Enable Azure Data Lake Storage credential passthrough for a High Concurrency cluster
High concurrency clusters can be shared by multiple users. They support only Python and SQL with Azure Data Lake Storage credential passthrough.
Important
Enabling Azure Data Lake Storage credential passthrough for a High Concurrency cluster blocks all ports on the cluster except for ports 44, 53, and 80.
- When you create a cluster, set Cluster Mode to High Concurrency.
- Under Advanced Options, select Enable credential passthrough for user-level data access and only allow Python and SQL commands.

Enable Azure Data Lake Storage credential passthrough for a Standard cluster
Standard clusters with credential passthrough are limited to a single user. Standard clusters support Python, SQL, Scala, and R. On Databricks Runtime 10.4 LTS and above, sparklyr is supported.
You must assign a user at cluster creation, but the cluster can be edited by a user with CAN MANAGE permissions at any time to replace the original user.
Important
The user assigned to the cluster must have at least CAN ATTACH TO permission for the cluster in order to run commands on the cluster. Workspace admins and the cluster creator have CAN MANAGE permissions, but cannot run commands on the cluster unless they are the designated cluster user.
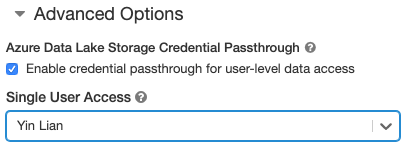
- When you create a cluster, set the Cluster Mode to Standard.
- Under Advanced Options, select Enable credential passthrough for user-level data access and select the user name from the Single User Access drop-down.
Create a container
Containers provide a way to organize objects in an Azure storage account.
Access Azure Data Lake Storage directly using credential passthrough
After configuring Azure Data Lake Storage credential passthrough and creating storage containers, you can access data directly in Azure Data Lake Storage Gen1 using an adl:// path and Azure Data Lake Storage Gen2 using an abfss:// path.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Replace
<storage-account-name>with the ADLS Gen1 storage account name.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Replace
<container-name>with the name of a container in the ADLS Gen2 storage account. - Replace
<storage-account-name>with the ADLS Gen2 storage account name.
Mount Azure Data Lake Storage to DBFS using credential passthrough
You can mount an Azure Data Lake Storage account or a folder inside it to What is DBFS?. The mount is a pointer to a data lake store, so the data is never synced locally.
When you mount data using a cluster enabled with Azure Data Lake Storage credential passthrough, any read or write to the mount point uses your Microsoft Entra ID credentials. This mount point will be visible to other users, but the only users that will have read and write access are those who:
- Have access to the underlying Azure Data Lake Storage storage account
- Are using a cluster enabled for Azure Data Lake Storage credential passthrough
Azure Data Lake Storage Gen1
To mount an Azure Data Lake Storage Gen1 resource or a folder inside it, use the following commands:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Replace
<storage-account-name>with the ADLS Gen2 storage account name. - Replace
<mount-name>with the name of the intended mount point in DBFS.
Azure Data Lake Storage Gen2
To mount an Azure Data Lake Storage Gen2 filesystem or a folder inside it, use the following commands:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Replace
<container-name>with the name of a container in the ADLS Gen2 storage account. - Replace
<storage-account-name>with the ADLS Gen2 storage account name. - Replace
<mount-name>with the name of the intended mount point in DBFS.
Warning
Do not provide your storage account access keys or service principal credentials to authenticate to the mount point. That would give other users access to the filesystem using those credentials. The purpose of Azure Data Lake Storage credential passthrough is to prevent you from having to use those credentials and to ensure that access to the filesystem is restricted to users who have access to the underlying Azure Data Lake Storage account.
Security
It is safe to share Azure Data Lake Storage credential passthrough clusters with other users. You will be isolated from each other and will not be able to read or use each other’s credentials.
Supported features
| Feature | Minimum Databricks Runtime Version | Notes |
|---|---|---|
| Python and SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | Credentials are passed through only if the DBFS path resolves to a location in Azure Data Lake Storage Gen1 or Gen2. For DBFS paths that resolve to other storage systems, use a different method to specify your credentials. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| disk caching | 5.5 | |
| PySpark ML API | 5.5 | The following ML classes are not supported: - org/apache/spark/ml/classification/RandomForestClassifier- org/apache/spark/ml/clustering/BisectingKMeans- org/apache/spark/ml/clustering/GaussianMixture- org/spark/ml/clustering/KMeans- org/spark/ml/clustering/LDA- org/spark/ml/evaluation/ClusteringEvaluator- org/spark/ml/feature/HashingTF- org/spark/ml/feature/OneHotEncoder- org/spark/ml/feature/StopWordsRemover- org/spark/ml/feature/VectorIndexer- org/spark/ml/feature/VectorSizeHint- org/spark/ml/regression/IsotonicRegression- org/spark/ml/regression/RandomForestRegressor- org/spark/ml/util/DatasetUtils |
| Broadcast variables | 5.5 | Within PySpark, there is a limit on the size of the Python UDFs you can construct, since large UDFs are sent as broadcast variables. |
| Notebook-scoped libraries | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6.0 | |
| sparklyr | 10.1 | |
| Orchestrate notebooks and modularize code in notebooks | 6.1 | |
| PySpark ML API | 6.1 | All PySpark ML classes supported. |
| Cluster metrics | 6.1 | |
| Databricks Connect | 7.3 | Passthrough is supported on Standard clusters. |
Limitations
The following features are not supported with Azure Data Lake Storage credential passthrough:
%fs(use the equivalent dbutils.fs command instead).- Databricks Jobs.
- The Databricks REST API Reference.
- Unity Catalog.
- Table access control. The permissions granted by Azure Data Lake Storage credential passthrough could be used to bypass the fine-grained permissions of table ACLs, while the extra restrictions of table ACLs will constrain some of the benefits you get from credential passthrough. In particular:
- If you have Microsoft Entra ID permission to access the data files that underlie a particular table you will have full permissions on that table via the RDD API, regardless of the restrictions placed on them via table ACLs.
- You will be constrained by table ACLs permissions only when using the DataFrame API. You will see warnings about not having permission
SELECTon any file if you try to read files directly with the DataFrame API, even though you could read those files directly via the RDD API. - You will be unable to read from tables backed by filesystems other than Azure Data Lake Storage, even if you have table ACL permission to read the tables.
- The following methods on SparkContext (
sc) and SparkSession (spark) objects:- Deprecated methods.
- Methods such as
addFile()andaddJar()that would allow non-admin users to call Scala code. - Any method that accesses a filesystem other than Azure Data Lake Storage Gen1 or Gen2 (to access other filesystems on a cluster with Azure Data Lake Storage credential passthrough enabled, use a different method to specify your credentials and see the section on trusted filesystems under Troubleshooting).
- The old Hadoop APIs (
hadoopFile()andhadoopRDD()). - Streaming APIs, since the passed-through credentials would expire while the stream was still running.
- DBFS mounts (
/dbfs) are available only in Databricks Runtime 7.3 LTS and above. Mount points with credential passthrough configured are not supported through this path. - Azure Data Factory.
- MLflow on high concurrency clusters.
- azureml-sdk Python package on high concurrency clusters.
- You cannot extend the lifetime of Microsoft Entra ID passthrough tokens using Microsoft Entra ID token lifetime policies. As a consequence, if you send a command to the cluster that takes longer than an hour, it will fail if an Azure Data Lake Storage resource is accessed after the 1 hour mark.
- When using Hive 2.3 and above you can’t add a partition on a cluster with credential passthrough enabled. For more information, see the relevant troubleshooting section.
Example notebooks
The following notebooks demonstrate Azure Data Lake Storage credential passthrough for Azure Data Lake Storage Gen1 and Gen2.
Azure Data Lake Storage Gen1 passthrough notebook
Azure Data Lake Storage Gen2 passthrough notebook
Troubleshooting
py4j.security.Py4JSecurityException: … is not whitelisted
This exception is thrown when you have accessed a method that Azure Databricks has not explicitly marked as safe for Azure Data Lake Storage credential passthrough clusters. In most cases, this means that the method could allow a user on a Azure Data Lake Storage credential passthrough cluster to access another user’s credentials.
org.apache.spark.api.python.PythonSecurityException: Path … uses an untrusted filesystem
This exception is thrown when you have tried to access a filesystem that is not known by the Azure Data Lake Storage credential passthrough cluster to be safe. Using an untrusted filesystem might allow a user on a Azure Data Lake Storage credential passthrough cluster to access another user’s credentials, so we disallow all filesystems that we are not confident are being used safely.
To configure the set of trusted filesystems on a Azure Data Lake Storage credential passthrough cluster, set the Spark conf key spark.databricks.pyspark.trustedFilesystems on that cluster to be a comma-separated list of the class names that are trusted implementations of org.apache.hadoop.fs.FileSystem.
Adding a partition fails with AzureCredentialNotFoundException when credential passthrough is enabled
When using Hive 2.3-3.1, if you try to add a partition on a cluster with credential passthrough enabled, the following exception occurs:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
To work around this issue, add partitions on a cluster without credential passthrough enabled.