Ingest data from Azure Cosmos DB into Azure Data Explorer
Azure Data Explorer supports data ingestion from Azure Cosmos DB for NoSql using a change feed. The Cosmos DB change feed data connection is an ingestion pipeline that listens to your Cosmos DB change feed and ingests the data into your Data Explorer table. The change feed listens for new and updated documents but doesn't log deletes. For general information about data ingestion in Azure Data Explorer, see Azure Data Explorer data ingestion overview.
Each data connection listens to a specific Cosmos DB container and ingests data into a specified table (more than one connection can ingest in a single table). The ingestion method supports streaming ingestion (when enabled) and queued ingestion.
The two main scenarios for using the Cosmos DB change feed data connection are:
- Replicating a Cosmos DB container for analytical purposes. For more information, see Get latest versions of Azure Cosmos DB documents.
- Analyzing the document changes in a Cosmos DB container. For more information, see Considerations.
In this article, you'll learn how to set up a Cosmos DB change feed data connection to ingest data into Azure Data Explorer with System Managed Identity. Review the considerations before you start.
Use the following steps to set up a connector:
Step 1: Choose an Azure Data Explorer table and configure its table mapping
Step 2: Create a Cosmos DB data connection
Step 3: Test the data connection
Prerequisites
- An Azure subscription. Create a free Azure account.
- An Azure Data Explorer cluster and database. Create a cluster and database.
- A container from a Cosmos DB account for NoSQL.
- If your Cosmos DB account blocks network access, for example by using a private endpoint, you must create a managed private endpoint to the Cosmos DB account. This is required for your cluster to invoke the change feed API.
Step 1: Choose an Azure Data Explorer table and configure its table mapping
Before you create a data connection, create a table where you'll store the ingested data and apply a mapping that matches schema in the source Cosmos DB container. If your scenario requires more than a simple mapping of fields, you can use update policies to transform and map data ingested from your change feed.
The following shows a sample schema of an item in the Cosmos DB container:
{
"id": "17313a67-362b-494f-b948-e2a8e95e237e",
"name": "Cousteau",
"_rid": "pL0MAJ0Plo0CAAAAAAAAAA==",
"_self": "dbs/pL0MAA==/colls/pL0MAJ0Plo0=/docs/pL0MAJ0Plo0CAAAAAAAAAA==/",
"_etag": "\"000037fc-0000-0700-0000-626a44110000\"",
"_attachments": "attachments/",
"_ts": 1651131409
}
Use the following steps to create a table and apply a table mapping:
In the Azure Data Explorer web UI, from the left navigation menu select Query, and then select the database where you want to create the table.
Run the following command to create a table called TestTable.
.create table TestTable(Id:string, Name:string, _ts:long, _timestamp:datetime)Run the following command to create the table mapping.
The command maps custom properties from a Cosmos DB JSON document to columns in the TestTable table, as follows:
Cosmos DB property Table column Transformation id Id None name Name None _ts _ts None _ts _timestamp Uses DateTimeFromUnixSecondsto transform _ts (UNIX seconds) to _timestamp (datetime))Note
We recommend using the following timestamp columns:
- _ts: Use this column to reconcile data with Cosmos DB.
- _timestamp: Use this column to run efficient time filters in your Kusto queries. For more information, see Query best practice.
.create table TestTable ingestion json mapping "DocumentMapping" ``` [ {"column":"Id","path":"$.id"}, {"column":"Name","path":"$.name"}, {"column":"_ts","path":"$._ts"}, {"column":"_timestamp","path":"$._ts", "transform":"DateTimeFromUnixSeconds"} ] ```
Transform and map data with update policies
If your scenario requires more than a simple mapping of fields, you can use update policies to transform and map data ingested from your change feed.
Update policies are a way to transform data as it's ingested into your table. They're written in Kusto Query Language and are run on the ingestion pipeline. They can be used to transform data from a Cosmos DB change feed ingestion, such as in the following scenarios:
- Your documents contain arrays that would be easier to query if they're transformed in multiple rows using the
mv-expandoperator. - You want to filter out documents. For example, you can filter out documents by type using the
whereoperator. - You have complex logic that can't be represented in a table mapping.
For information on how to create and manage update policies, see Update policy overview.
Step 2: Create a Cosmos DB data connection
You can use the following methods to create the data connector:
In the Azure portal, go to your cluster overview page, and then select the Getting started tab.
On the Data ingestion tile, select Create data connection > Cosmos DB.
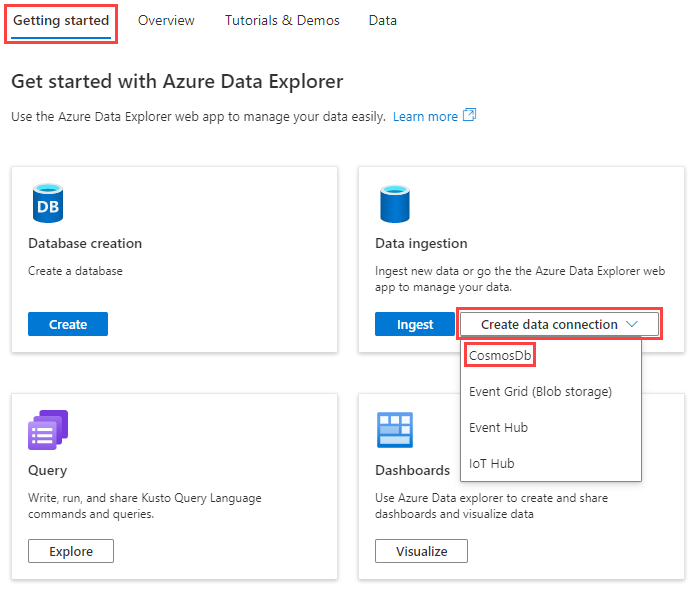
In the Cosmos DB Create data connection pane, fill out the form with the information in the table:
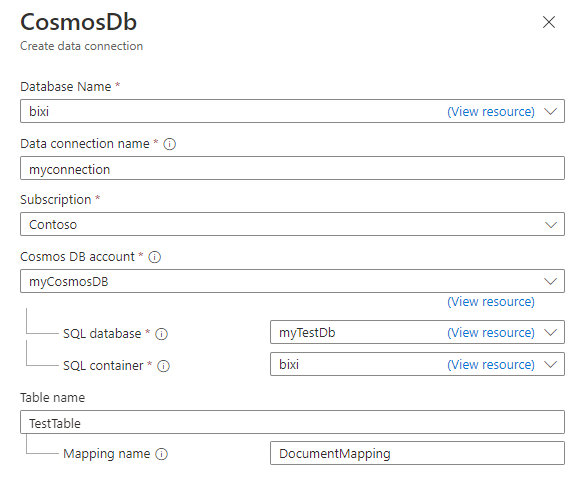
Field Description Database name Choose the Azure Data Explorer database into which you want to ingest data. Data connection name Specify a name for the data connection. Subscription Select the subscription that contains your Cosmos DB NoSQL account. Cosmos DB account Choose the Cosmos DB account from which you want to ingest data. SQL database Choose the Cosmos DB database from which you want to ingest data. SQL container Choose the Cosmos DB container from which you want to ingest data. Table name Specify the Azure Data Explorer table name to which you want to ingest data. Mapping name Optionally, specify the mapping name to use for the data connection. Optionally, under the Advanced settings section, do the following:
Specify the Event retrieval start date. This is the time from which the connector will start ingesting data. If you don't specify a time, the connector will start ingesting data from the time you create the data connection. The recommended date format is the ISO 8601 UTC standard, specified as follows:
yyyy-MM-ddTHH:mm:ss.fffffffZ.Select User-assigned and then select the identity. By Default, the System-assigned managed identity is used by the connection. If necessary, you can use a User-assigned identity.
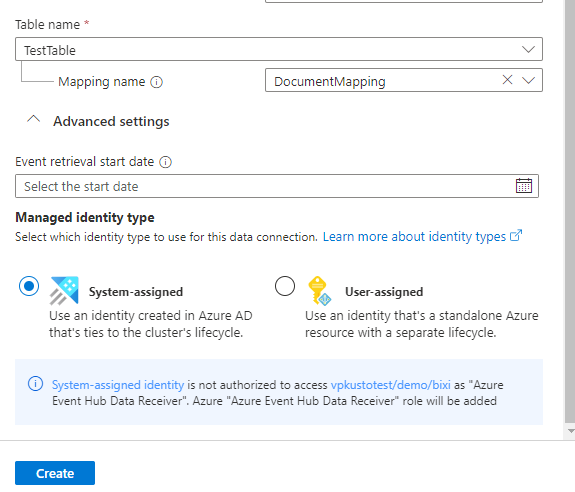
Select Create to crate the data connection.
Step 3: Test the data connection
In the Cosmos DB container, insert the following document:
{ "name":"Cousteau" }In the Azure Data Explorer web UI, run the following query:
TestTableThe result set should look like the following image:

Note
Azure Data Explorer has an aggregation (batching) policy for queued data ingestion designed to optimize the ingestion process. The default batching policy is configured to seal a batch once one of the following conditions is true for the batch: a maximum delay time of 5 minutes, total size of one GB, or 1000 blobs. Therefore, you may experience a latency. For more information, see batching policy. To reduce latency, configure your table to support streaming. See streaming policy.
Considerations
The following considerations apply to the Cosmos DB change feed:
The change feed doesn't expose deletion events.
The Cosmos DB change feed only includes new and updated documents. If you need to know about deleted documents, you can configure your feed use a soft marker to mark a Cosmos DB document as deleted. A property is added to update events that indicate whether a document has been deleted. You can then use the
whereoperator in your queries to filter them out.For example, if you map the deleted property to a table column called IsDeleted, you can filter out deleted documents with the following query:
TestTable | where not(IsDeleted)The change feed only exposes the latest update of a document.
To understand the ramification of the second consideration, examine the following scenario:
A Cosmos DB container contains documents A and B. The changes to a property called foo are shown in the following table:
Document ID Property foo Event Document timestamp (_ts) A Red Creation 10 B Blue Creation 20 A Orange Update 30 A Pink Update 40 B Violet Update 50 A Carmine Update 50 B NeonBlue Update 70 The change feed API is polled by the data connector at regular intervals, typically every few seconds. Each poll contains changes that occurred in the container between calls, but only the latest version of change per document.
To illustrate the issue, consider a sequence of API calls with timestamps 15, 35, 55, and 75 as shown in the following table:
API Call Timestamp Document ID Property foo Document timestamp (_ts) 15 A Red 10 35 B Blue 20 35 A Orange 30 55 B Violet 50 55 A Carmine 60 75 B NeonBlue 70 Comparing the API results to the list of changes made in the Cosmos DB document, you'll notice that they don't match. The update event to document A, highlighted in the change table at timestamp 40, doesn't appear in the results of the API call.
To understand why the event doesn't appear, we'll examine the changes to document A between the API calls at timestamps 35 and 55. Between these two calls, document A changed twice, as follows:
Document ID Property foo Event Document timestamp (_ts) A Pink Update 40 A Carmine Update 50 When the API call at timestamp 55 is made, the change feed API returns the latest version of the document. In this case, the latest version of document A is the update at timestamp 50, which is the update to property foo from Pink to Carmine.
Because of this scenario, the data connector may miss some intermediate document changes. For example, some events may be missed if the data connection service is down for a few minutes, or if the frequency of document changes is higher than the API polling frequency. However, the latest state of each document is captured.
Deleting and recreating a Cosmos DB container isn't supported
Azure Data Explorer keeps track of the change feed by checkpointing the "position" it is at in the feed. This is done using continuation token on each physical partitions of the container. When a container is deleted/recreated, the continuation token is invalid and isn't reset. In this case, you must delete and recreate the data connection.
Estimate cost
How much does using the Cosmos DB data connection impact your Cosmos DB container's Request Units (RUs) usage?
The connector invokes the Cosmos DB Change Feed API on each physical partition of your container, to up to once a second. The following costs are associated with these invocations:
| Cost | Description |
|---|---|
| Fixed costs | Fixed costs are about 2 RUs per physical partition every second. |
| Variable costs | Variable costs are about 2% of the RUs used to write documents, though this may vary depending on your scenario. For example, if you write 100 documents to a Cosmos DB container, the cost of writing those documents is 1,000 RUs. The corresponding cost for using the connector to read those document is about 2% the cost to write them, approximately 20 RUs. |