Ingest data with the Apache log4J 2 connector
Log4J is a popular logging framework for Java applications maintained by the Apache Foundation. Log4J allows developers to control which log statements are output with arbitrary granularity based on the logger's name, logger level, and message pattern. Apache Log4J 2 is an upgrade to Log4J, with significant improvements over the preceding Log4j 1.x. Log4J 2 provides many of the improvements available in Logback, while fixing some inherent problems in Logback's architecture. The Apache log4J 2 sink, also known as an appender, streams your log data to your table in Kusto, where you can analyze and visualize your logs in real time.
For a complete list of data connectors, see Data integrations overview.
Prerequisites
- Apache Maven
- An Azure Data Explorer cluster and database or a KQL database in Microsoft Fabric
Set up your environment
In this section, you prepare your environment to use the Log4J 2 sink.
Install the package
To use the sink in an application, add the following dependencies to your pom.xml Maven file. The sink expects the log4j-core is provided as a dependency in the application.
<dependency>
<groupId>com.microsoft.azure.kusto</groupId>
<artifactId>azure-kusto-log4j</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
Create a Microsoft Entra App registration
Sign in to your Azure subscription via Azure CLI. Then authenticate in the browser.
az loginChoose the subscription to host the principal. This step is needed when you have multiple subscriptions.
az account set --subscription YOUR_SUBSCRIPTION_GUIDCreate the service principal. In this example, the service principal is called
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}From the returned JSON data, copy the
appId,password, andtenantfor future use.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
You've created your Microsoft Entra application and service principal.
Grant the Microsoft Entra app permissions
In your query environment, run the following management command, replacing the placeholders DatabaseName and application ID with the previously saved values. This command grants the app the database ingestor role. For more information, see Manage database security roles.
.add database DatabaseName ingestors ('aadappID=12345-abcd-12a3-b123-ccdd12345a1b') 'App Registration'Note
The last parameter is a string that shows up as notes when you query the roles associated with a database. For more information, see manage database roles.
Create a table and ingestion mapping
Create a target table for the incoming data, mapping the ingested data columns to the columns in the target table. In the following steps, the table schema and mapping correspond to the data sent from the sample app.
In your query editor, run the following table creation command, replacing the placeholder TableName with the name of the target table:
.create table log4jTest (timenanos:long,timemillis:long,level:string,threadid:string,threadname:string,threadpriority:int,formattedmessage:string,loggerfqcn:string,loggername:string,marker:string,thrownproxy:string,source:string,contextmap:string,contextstack:string)Run the following ingestion mapping command, replacing the placeholders TableName with the target table name and TableNameMapping with the name of the ingestion mapping:
.create table log4jTest ingestion csv mapping 'log4jCsvTestMapping' '[{"Name":"timenanos","DataType":"","Ordinal":"0","ConstValue":null},{"Name":"timemillis","DataType":"","Ordinal":"1","ConstValue":null},{"Name":"level","DataType":"","Ordinal":"2","ConstValue":null},{"Name":"threadid","DataType":"","Ordinal":"3","ConstValue":null},{"Name":"threadname","DataType":"","Ordinal":"4","ConstValue":null},{"Name":"threadpriority","DataType":"","Ordinal":"5","ConstValue":null},{"Name":"formattedmessage","DataType":"","Ordinal":"6","ConstValue":null},{"Name":"loggerfqcn","DataType":"","Ordinal":"7","ConstValue":null},{"Name":"loggername","DataType":"","Ordinal":"8","ConstValue":null},{"Name":"marker","DataType":"","Ordinal":"9","ConstValue":null},{"Name":"thrownproxy","DataType":"","Ordinal":"10","ConstValue":null},{"Name":"source","DataType":"","Ordinal":"11","ConstValue":null},{"Name":"contextmap","DataType":"","Ordinal":"12","ConstValue":null},{"Name":"contextstack","DataType":"","Ordinal":"13","ConstValue":null}]'
Add the Log4j 2 sink to your app
Use the following steps to:
- Add the Log4j 2 sink to your app
- Configure the variables used by the sink
- Build and run the app
Add the following code to your app:
package com.microsoft.azure.kusto.log4j.sample; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger;Configure the Log4j 2 sink by adding the
KustoStrategyentry to the log4j2.xml file, replacing placeholders using the information in the table that follows:The log4J 2 connector uses a custom strategy that's used in the RollingFileAppender. Logs are written into the rolling file to prevent any data loss arising out of network failure while connecting to the Kusto cluster. The data is stored in a rolling file and then flushed to the Kusto cluster.
<KustoStrategy clusterIngestUrl = "${env:LOG4J2_ADX_INGEST_CLUSTER_URL}" appId = "${env:LOG4J2_ADX_APP_ID}" appKey = "${env:LOG4J2_ADX_APP_KEY}" appTenant = "${env:LOG4J2_ADX_TENANT_ID}" dbName = "${env:LOG4J2_ADX_DB_NAME}" tableName = "<MyTable>" logTableMapping = "<MyTableCsvMapping>" mappingType = "csv" flushImmediately = "false" />Property Description clusterIngestUrl The ingest URI for your cluster in the format https://ingest-<cluster>.<region>.kusto.windows.net. dbName The case-sensitive name of the target database. tableName The case-sensitive name of an existing target table. For example, Log4jTest is the name of the table created in Create a table and ingestion mapping. appId The application client ID required for authentication. You saved this value in Create a Microsoft Entra App registration. appKey The application key required for authentication. You saved this value in Create a Microsoft Entra App registration. appTenant The ID of the tenant in which the application is registered. You saved this value in Create a Microsoft Entra App registration. logTableMapping The name of the mapping. mappingType The type of mapping to use. The default is csv. flushImmediately If set to true, the sink flushes the buffer after each log event. The default is false. For more options, see Sink Options.
Send data to Kusto using the Log4j 2 sink. For example:
import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; public class MyClass { private static final Logger logger = LogManager.getLogger(KustoLog4JSampleApp.class); public static void main(String[] args) { Runnable loggingTask = () -> { logger.trace(".....read_physical_netif: Home list entries returned = 7"); logger.debug(".....api_reader: api request SENDER"); logger.info(".....read_physical_netif: index #0, interface VLINK1 has address 129.1.1.1, ifidx 0"); logger.warn(".....mailslot_create: setsockopt(MCAST_ADD) failed - EDC8116I Address not available."); logger.error(".....error_policyAPI: APIInitializeError: ApiHandleErrorCode = 98BDFB0, errconnfd = 22"); logger.fatal(".....fatal_error_timerAPI: APIShutdownError: ReadBuffer = 98BDFB0, RSVPGetTSpec = error"); }; ScheduledExecutorService executor = Executors.newScheduledThreadPool(1); executor.scheduleAtFixedRate(loggingTask, 0, 3, TimeUnit.SECONDS); } }Build and run the app.
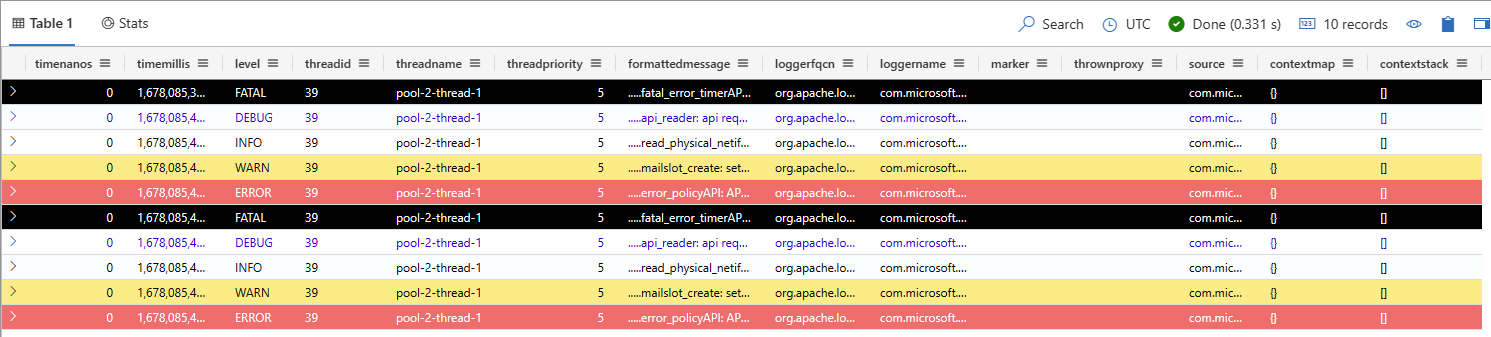
Verify that the data is in your cluster. In your query environment, run the following query replacing the placeholder with the name of the table that used earlier:
<TableName> | take 10
Run the sample app
Clone the log4J 2 git repo using the following git command:
git clone https://github.com/Azure/azure-kusto-log4j.gitSet the following environmental variables to configure the Log4J 2 sink:
Note
In the sample project included in the git repo, the default configuration format is defined in the file log4j2.xml. This configuration file is located under the file path: \azure-kusto-log4j\samples\src\main\resources\log4j2.xml.
In your terminal, navigate to the samples folder of the cloned repo and run the following Maven command:
mvn compile exec:java -Dexec.mainClass="org.example.KustoLog4JSampleApp"In your query environment, select the target database, and run the following query to explore the ingested data, replacing the placeholder TableName with the name of the target table:
<TableName> | take 10Your output should look similar to the following table: