Azure AI Content Understanding video solutions (preview)
Important
- Azure AI Content Understanding is available in preview. Public preview releases provide early access to features that are in active development.
- Features, approaches, and processes can change or have limited capabilities, before General Availability (GA).
- For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Azure AI Content Understanding allows you to extract and customize video metadata. Content Understanding helps efficiently manage, categorize, retrieve, and build workflows for video assets. It enhances your media asset library, supports workflows such as highlight generation, categorizes content, and facilitates applications like retrieval-augmented generation (RAG).
Content understanding for video has broad potential uses. For example, you can customize metadata to tag specific scenes in a training video, making it easier for employees to locate and revisit important sections. You can also use metadata customization to identify product placement in promotional videos, which helps marketing teams analyze brand exposure.
Business use cases
Azure AI Content Understanding provides a range of business use cases, including:
- Broadcast media and entertainment: Manage large libraries of shows, movies, and clips by generating detailed metadata for each asset.
- Education and e*Learning: Index and retrieve specific moments in educational videos or lectures.
- Corporate training: Organize training videos by key topics, scenes, or important moments.
- Marketing and advertising: Analyze promotional videos to extract product placements, brand appearances, and key messages.
Video understanding capabilities
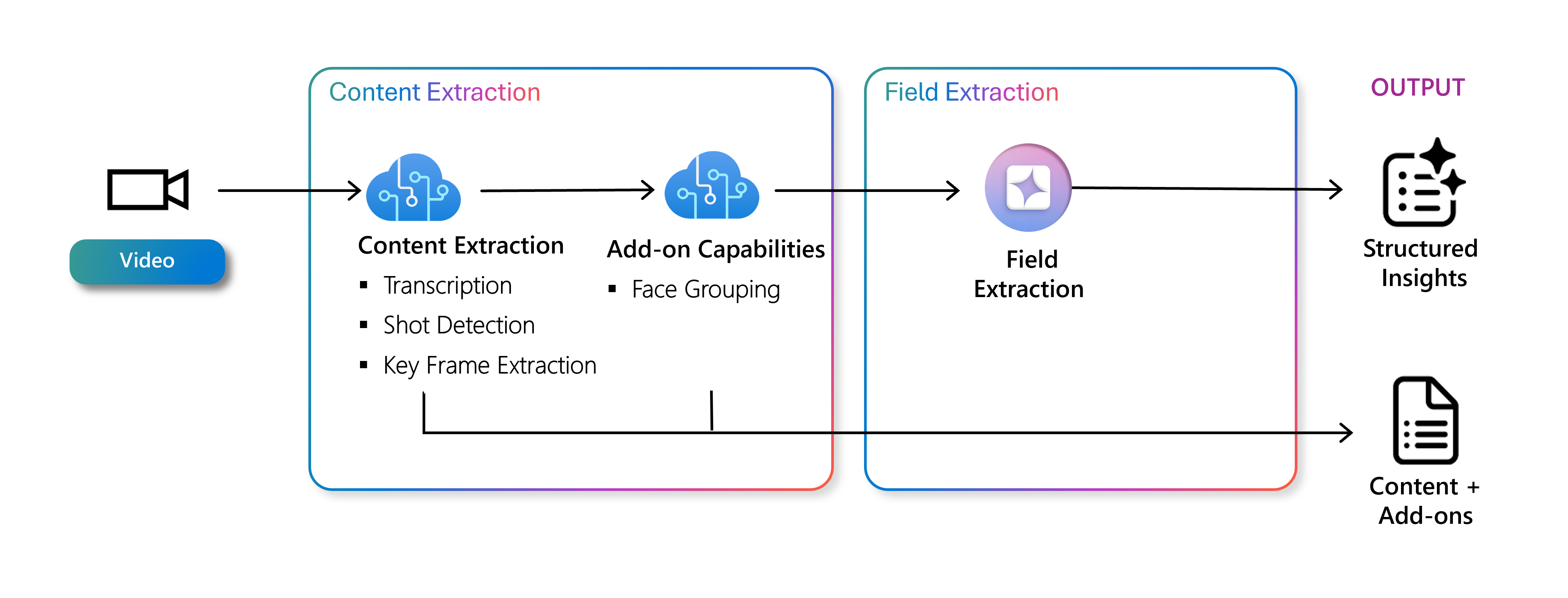
Content Understanding processes video files through a customizable pipeline that can perform both content extraction and field extraction tasks. Content Extraction focuses on analyzing the video to generate foundational metadata, while Field Extraction uses that metadata to create more detailed, custom insights tailored to specific use cases. To follow is an overview of each capability.
Content extraction
Content extraction for video includes transcription, shot detection, key frame extraction, and face grouping. These operations are performed over sampled frames from the entire video and generate a structured text output representing the video. Content extraction also serves as grounding data for generative capabilities of Field Extraction by providing context on what is contained in the video.
Specific capabilities of content extraction:
- Transcription: Converts speech to structured, searchable text via Azure AI Speech, allowing users to specify recognition languages.
- Shot detection: Identifies segments of the video aligned with shot boundaries where possible, allowing for precise editing and repackaging of content with breaks exactly on shot boundaries.
- Key frame extraction: Extracts key frames from videos to represent each shot completely, ensuring each shot has enough key frames to enable Field Extraction to work effectively.
- Face grouping: Grouped faces appearing in a video to extract one representative face image for each person and provides segments where each one is present. The grouped face data is available as metadata and can be used to generate customized metadata fields.
- This feature is limited access and involves face identification and grouping; customers need to register for access at Face Recognition.
Field extraction
Field extraction enables the generation of structured data for each segment of the video, such as tags, categories, or descriptions, using a customizable schema tailored to your specific needs. This structured data makes it easier to organize, search, and automatically process video content efficiently. Field extraction uses a multimodal generative model to extract specific data from the video, using key frames and text output from Content Extraction as input. Field extraction enables the generative model to make detailed insights based on the visual content captured from shots, providing detailed identification.
Examples of fields for different industries:
Media asset management:
- Shot type: Helps editors and producers organize content, simplifying editing, and understanding the visual language of the video. Useful for metadata tagging and quicker scene retrieval.
- Color scheme: Conveys mood and atmosphere, essential for narrative consistency and viewer engagement. Identifying color themes helps in finding matching clips for accelerated video editing.
Advertising:
- Brand: Identifies brand presence, critical for analyzing ad impact, brand visibility, and association with products. This capability allows advertisers to assess brand prominence and ensure compliance with branding guidelines.
- Ad categories: Categorizes ad types by industry, product type, or audience segment, which supports targeted advertising strategies, categorization, and performance analysis.
Key benefits
Content Understanding provides several key benefits when compared to other video analysis solutions:
- Segment-based multi-frame analysis: Identify actions, events, topics, and themes by analyzing multiple frames from each video segment, rather than individual frames.
- Customization: Customize the metadata you generate by modifying the schema in accordance with your specific use case.
- Generative models: Describe in natural language what content you want to extract, and Content Understanding uses generative models to extract that metadata.
- Optimized preprocessing: Perform several content extraction preprocessing steps, such as transcription and scene detection, optimized to provide rich context to AI generative models.
Input requirements
For detailed information on supported input document formats, refer to our Service quotas and limits page.
Supported languages and regions
For a detailed list of supported languages and regions, visit our Language and region support page.
Data privacy and security
As with all the Azure AI services, developers using the Content Understanding service should be aware of Microsoft's policies on customer data. See our Data, protection and privacy page to learn more.
Important
Users of Content Understanding can enable features like Face Grouping for videos, which involved processing Biometric Data. If you're using Microsoft products or services to process Biometric Data, you're responsible for: (i) providing notice to data subjects, including with respect to retention periods and destruction; (ii) obtaining consent from data subjects; and (iii) deleting the Biometric Data, all as appropriate, and required under applicable Data Protection Requirements. "Biometric Data" has the meaning articulated in Article 4 of the GDPR and, if applicable, equivalent terms in other data protection requirements. For related information, see Data and Privacy for Face.
Next steps
- Try processing your video content using Content Understanding in Azure portal.
- Learn to analyze video content analyzer templates.
- Review code sample: video content extraction.
- Review code sample: video search with natural language queries.
- Review code sample: analyzer templates