WinMLRunner
WinMLRunner ist ein Tool zum Testen, ob ein Modell erfolgreich ausgeführt wird, wenn es mit den Windows ML-APIs ausgewertet wurde. Sie können auch den Auswertungszeitraum und die Arbeitsspeicherauslastung auf der GPU und/oder CPU erfassen. Modelle im ONNX- oder PB-Format können ausgewertet werden, bei denen die Ein- und Ausgabevariablen Tensoren oder Bilder sind. Es gibt zwei Möglichkeiten, WinMLRunner zu verwenden:
- Laden Sie das Python-Befehlszeilentool herunter.
- Verwenden Sie es im WinML-Dashboard. Weitere Informationen finden Sie in der Dokumentation zum WinML-Dashboard.
Ausführen eines Modells
Öffnen Sie zunächst das heruntergeladene Python-Tool. Navigieren Sie zu dem Ordner, der die Datei „WinMLRunner.exe“ enthält, und führen Sie die ausführbare Datei wie unten gezeigt aus. Stellen Sie sicher, dass Sie den Installationspfad durch den Ihren ersetzen:
.\WinMLRunner.exe -model SqueezeNet.onnx
Sie können auch einen Ordner mit Modellen ausführen, mit einem Befehl wie dem folgenden.
WinMLRunner.exe -folder c:\data -perf -iterations 3 -CPU`\
Ausführen eines guten Modells
Im Folgenden finden Sie ein Beispiel für die erfolgreiche Ausführung eines Modells. Beachten Sie, wie das Modell zunächst Modellmetadaten lädt und ausgibt. Dann wird das Modell getrennt auf der CPU und der GPU ausgeführt sowie der Bindungserfolg, der Auswertungserfolg und die Modellausgabe ausgegeben.
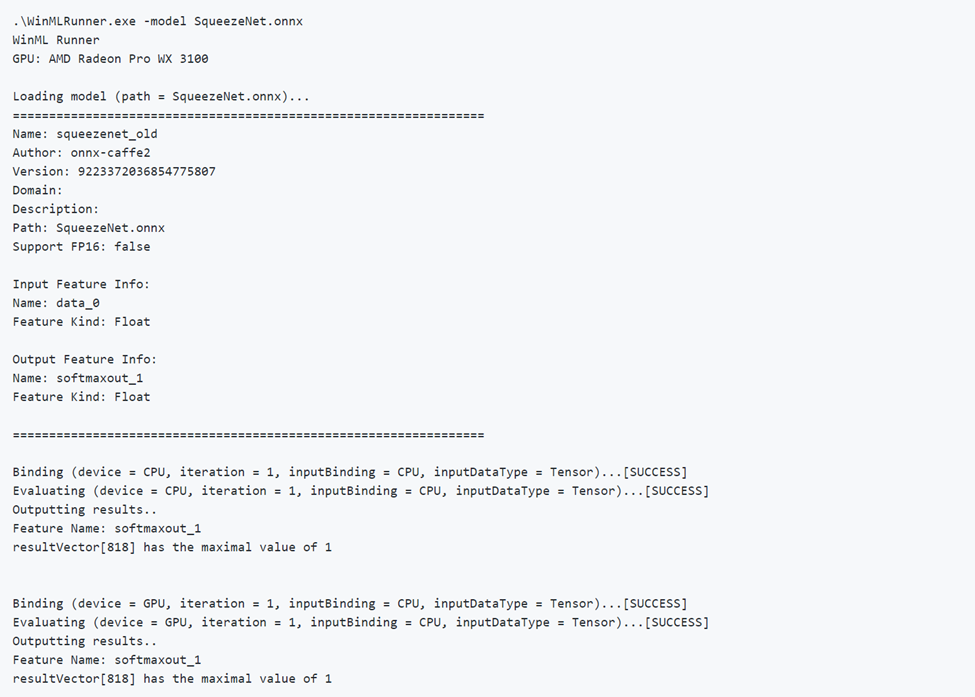
Ausführen eines fehlerhaften Modells
Im Folgenden finden Sie ein Beispiel für die Ausführung eines Modells mit falschen Parametern. Beachten Sie die Ausgabe FAILED (Fehlerhaft) bei der Auswertung über die GPU.
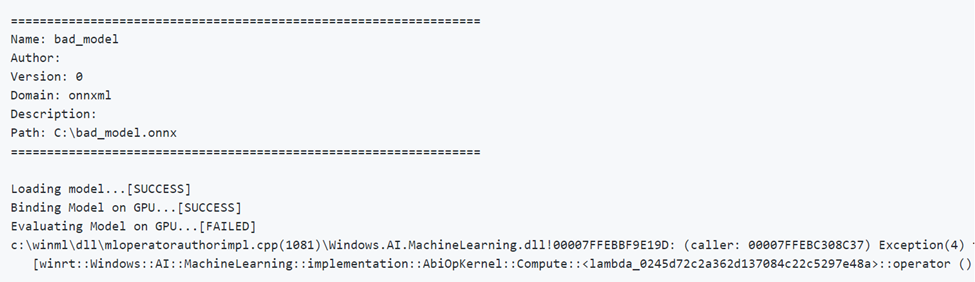
Geräteauswahl und -optimierung
Standardmäßig wird das Modell auf der CPU und GPU separat ausgeführt, aber Sie können ein Gerät mit dem Flag -CPU oder -GPU angeben. Im Folgenden finden Sie ein Beispiel für die dreimalige Ausführung eines Modells, bei dem nur die CPU verwendet wird:
WinMLRunner.exe -model c:\data\concat.onnx -iterations 3 -CPU
Protokollieren der Leistungsdaten
Verwenden Sie das Flag „-perf“, um Leistungsdaten zu erfassen. Im Folgenden finden Sie ein Beispiel für die dreimalige Ausführung aller Modelle im Datenordner auf der CPU und GPU und die Erfassung von Leistungsdaten:
WinMLRunner.exe -folder c:\data iterations 3 -perf
Leistungsmessungen
Die folgenden Leistungsmessungen werden für jeden Lade-, Bindungs- und Auswertungsvorgang in die Befehlszeile und die CSV-Datei ausgegeben:
- Gesamtbetrachtungszeit (ms): Die verstrichene reale Zeit zwischen Beginn und Ende eines Vorgangs.
- GPU-Zeit (ms): Zeit für die Übergabe eines Vorgangs von der CPU an die GPU und die Ausführung auf der GPU (Hinweis: Load() wird nicht auf der GPU ausgeführt).
- CPU-Zeit (ms): Zeit für die Ausführung eines Vorgangs auf der CPU.
- Dedizierte und gemeinsame Arbeitsspeicherauslastung (MB): Die durchschnittliche Kernel- und Arbeitsspeicherauslastung auf Benutzerebene (in MB) während der Auswertung auf der CPU oder GPU.
- Arbeitssatzarbeitsspeicher (MB): Die Menge an DRAM-Arbeitsspeicher, die der Prozess auf der CPU während der Auswertung benötigt hat. Dedizierter Arbeitsspeicher (MB): Die Arbeitsspeichermenge, die im VRAM der dedizierten GPU verwendet wurde.
- Gemeinsamer Arbeitsspeicher (MB): Die Arbeitsspeichermenge, die von der GPU im DRAM verwendet wurde.
Beispielleistungsausgabe:
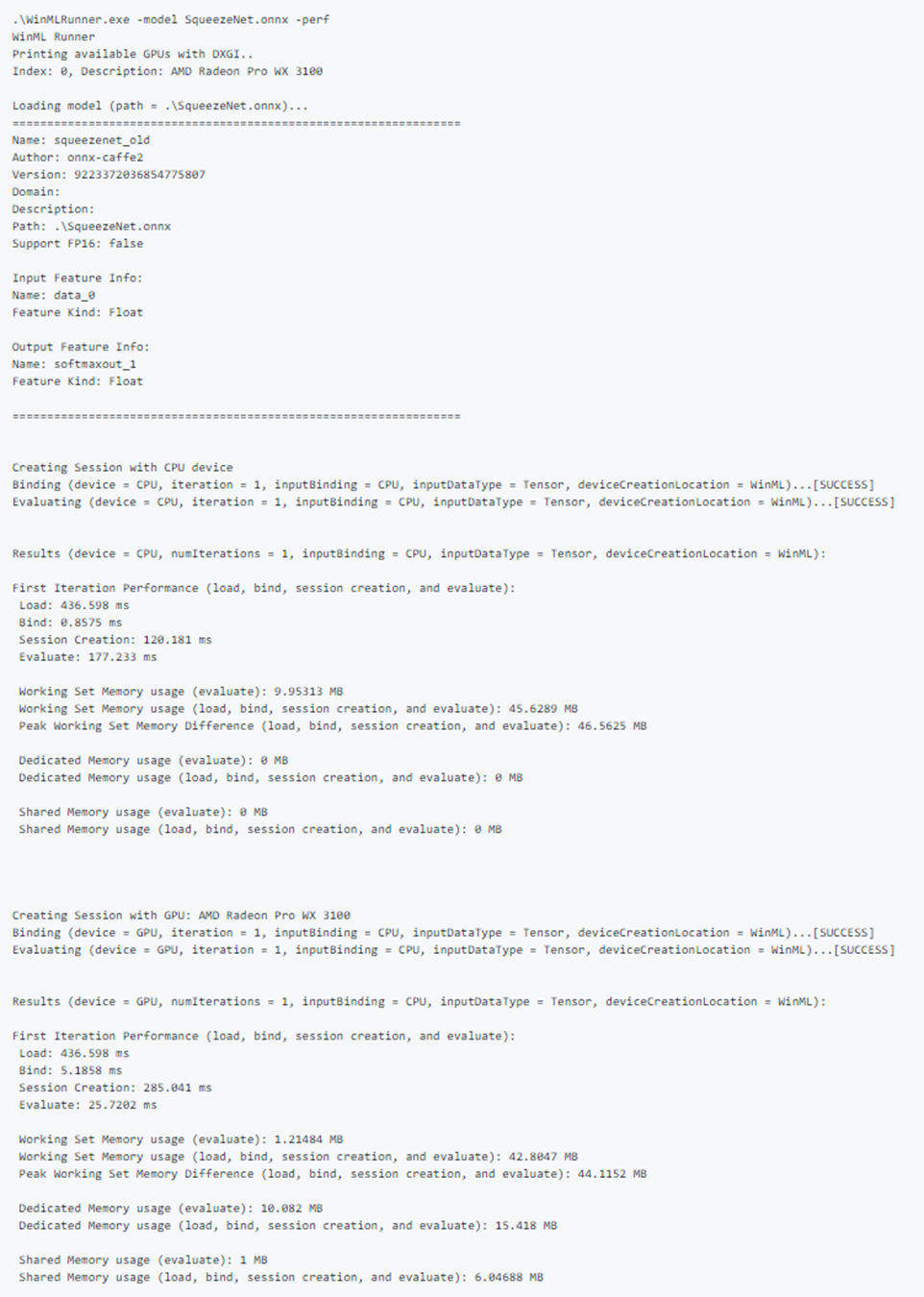
Testbeispieleingaben
Führen Sie ein Modell auf der CPU und GPU separat aus, und binden Sie die Eingabe separat an die CPU und die GPU (insgesamt vier Ausführungen):
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPU -CPUBoundInput -GPUBoundInput
Führen Sie ein Modell auf der CPU aus, bei dem die Eingabe an die GPU gebunden und als RGB-Bild geladen wird:
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPUBoundInput -RGB
Erfassen von Ablaufverfolgungsprotokollen
Wenn Sie Ablaufverfolgungsprotokolle mit dem Tool erfassen möchten, können Sie logman-Befehle in Verbindung mit dem Debugflag verwenden:
logman start winml -ets -o winmllog.etl -nb 128 640 -bs 128logman update trace winml -p {BCAD6AEE-C08D-4F66-828C-4C43461A033D} 0xffffffffffffffff 0xff -ets WinMLRunner.exe -model C:\Repos\Windows-Machine-Learning\SharedContent\models\SqueezeNet.onnx -debuglogman stop winml -ets
Die Datei „winmllog.etl“ wird im gleichen Verzeichnis wie die Datei „WinMLRunner.exe“ angezeigt.
Lesen der Ablaufverfolgungsprotokolle
Verwenden Sie die Datei „traceprt.exe“, und führen Sie den folgenden Befehl in der Befehlszeile aus.
tracerpt.exe winmllog.etl -o logdump.csv -of CSV
Öffnen Sie dann die Datei logdump.csv.
Alternativ können Sie Windows Performance Analyzer (aus Visual Studio) verwenden. Starten Sie Windows Performance Analyzer, und öffnen Sie winmllog.etl.
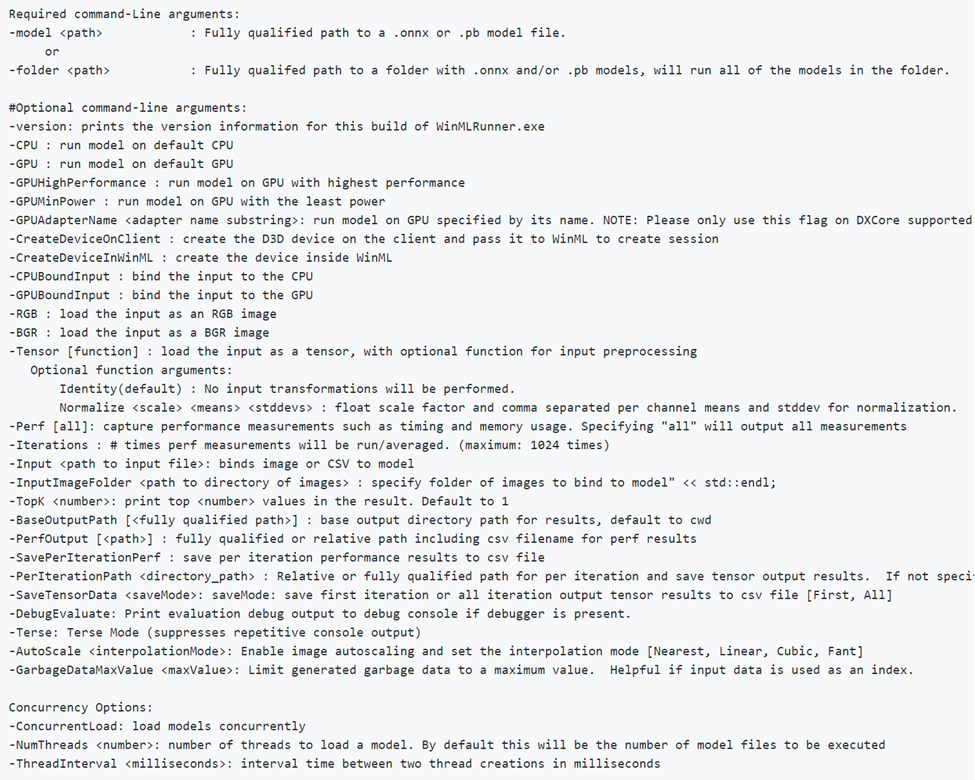
Beachten Sie, dass -CPU, -GPU, -GPUHighPerformance, -GPUMinPower -BGR, -RGB, -tensor, -CPUBoundInput, -GPUBoundInput sich nicht gegenseitig ausschließen (d. h. Sie können sie beliebig kombinieren, um das Modell mit verschiedenen Konfigurationen auszuführen).
Dynamisches Laden von DLLs
Wenn Sie WinMLRunner mit einer anderen Version von WinML ausführen möchten (um z. B. die Leistung mit einer älteren Version zu vergleichen oder eine neuere Version zu testen), speichern Sie einfach die Dateien „windows.ai.machinelearning.dll“ und „directml.dll“ in demselben Ordner wie die Datei „WinMLRunner.exe“. WinMLRunner sucht zuerst nach diesen DLLs und führt einen Fallback auf „C:/Windows/System32“ aus, wenn sie nicht gefunden werden.
Bekannte Probleme
- Sequenz-/Zuordnungseingaben werden noch nicht unterstützt (das Modell wird einfach übersprungen, sodass es andere Modelle in einem Ordner nicht blockiert).
- Wir können nicht zuverlässig mehrere Modelle mit dem Argument „-folder“ mit echten Daten ausführen. Da wir nur eine Eingabe angeben können, würde die Größe der Eingabe mit den meisten Modellen nicht übereinstimmen. Jetzt funktioniert das Verwenden des Arguments „-folder“ nur gut mit Garbagedaten.
- Das Generieren von Garbageeingaben als „Gray“ oder „YUV“ wird derzeit nicht unterstützt. Im Idealfall sollte die Garbagedaten-Pipeline von WinMLRunner alle Eingabetypen unterstützen, die wir an winml übergeben können.